Co to są ciągłość działalności biznesowej, wysoka dostępność i odzyskiwanie po awarii?
W tym artykule zdefiniowano i opisano ciągłość działania oraz planowanie ciągłości działania w zakresie zarządzania ryzykiem dzięki wysokiej dostępności i projektowi odzyskiwania po awarii. Chociaż ten artykuł nie zawiera wyraźnych wskazówek dotyczących sposobu spełnienia własnych potrzeb związanych z ciągłością działalności biznesowej, ułatwia zrozumienie pojęć, które są używane w ramach wskazówek dotyczących niezawodności firmy Microsoft.
Ciągłość działania to stan, w którym firma może kontynuować operacje podczas awarii, awarii lub awarii. Ciągłość działalności biznesowej wymaga proaktywnego planowania, przygotowania i implementacji odpornych systemów i procesów.
Planowanie ciągłości działania wymaga identyfikowania, zrozumienia, klasyfikowania i zarządzania ryzykiem. Na podstawie ryzyka i ich prawdopodobieństwa należy zaprojektować zarówno pod kątem wysokiej dostępności ,jak i odzyskiwania po awarii (DR).
Wysoka dostępność polega na projektowaniu rozwiązania, które ma być odporne na codzienne problemy i zaspokoić potrzeby biznesowe dotyczące dostępności.
Odzyskiwanie po awarii polega na planowaniu sposobu radzenia sobie z nietypowymi zagrożeniami i katastrofalnymi awariami, które mogą spowodować.
Ciągłość działalności biznesowej
Ogólnie rzecz biorąc, rozwiązania w chmurze są powiązane bezpośrednio z operacjami biznesowymi. Za każdym razem, gdy rozwiązanie w chmurze jest niedostępne lub występuje poważny problem, wpływ na operacje biznesowe może być poważny. Poważny wpływ może przerwać ciągłość działalności biznesowej.
Poważny wpływ na ciągłość działalności biznesowej może obejmować:
- Utrata dochodów z działalności gospodarczej.
- Niezdolność do zapewnienia użytkownikom ważnej usługi.
- Naruszenie zobowiązania, które zostało złożone klientowi lub innej osobie.
Ważne jest, aby zrozumieć i przekazać oczekiwania biznesowe oraz konsekwencje niepowodzeń ważnym uczestnikom projektu, w tym osobom, które projektują, implementują i obsługują obciążenie. Następnie osoby biorące udział w projekcie reagują, dzieląc koszty związane z osiągnięciem tej wizji. Zazwyczaj istnieje proces negocjacji i poprawek tej wizji w oparciu o budżet i inne ograniczenia.
Planowanie ciągłości działania
Aby kontrolować lub całkowicie uniknąć negatywnego wpływu na ciągłość działalności biznesowej, ważne jest, aby aktywnie tworzyć plan ciągłości działania. Plan ciągłości działania opiera się na ocenie ryzyka i opracowywaniu metod kontrolowania tych zagrożeń za pomocą różnych podejść. Konkretne zagrożenia i podejścia do ograniczania ryzyka różnią się w zależności od organizacji i obciążenia.
Plan ciągłości działania nie uwzględnia tylko funkcji odporności samej platformy w chmurze, ale także funkcji aplikacji. Niezawodny plan ciągłości działania obejmuje również wszystkie aspekty wsparcia w firmie, w tym osoby, procesy ręczne lub zautomatyzowane związane z biznesem oraz inne technologie.
Planowanie ciągłości działania powinno obejmować następujące kroki sekwencyjne:
Identyfikacja ryzyka. Identyfikowanie czynników ryzyka związanych z dostępnością lub funkcjonalnością obciążenia. Możliwe zagrożenia mogą być problemami z siecią, awariami sprzętu, błędami ludzkimi, awarią regionu itp. Zrozumienie wpływu każdego ryzyka.
Klasyfikacja ryzyka. Klasyfikuj każde ryzyko jako wspólne ryzyko, które powinno być uwzględniane w planach wysokiej dostępności lub nietypowe ryzyko, które powinno być częścią planowania odzyskiwania po awarii.
Ograniczenie ryzyka. Zaprojektuj strategie ograniczania ryzyka dla wysokiej dostępności lub odzyskiwania po awarii, aby zminimalizować lub ograniczyć ryzyko, takie jak nadmiarowość, replikacja, tryb failover i kopie zapasowe. Należy również rozważyć nietechniczne i oparte na procesie środki zaradcze i mechanizmy kontroli.
Planowanie ciągłości działania jest procesem, a nie jednorazowym zdarzeniem. Każdy utworzony plan ciągłości działania powinien być regularnie przeglądany i aktualizowany w celu zapewnienia, że będzie on odpowiedni i skuteczny oraz że obsługuje bieżące potrzeby biznesowe.
Identyfikacja ryzyka
Początkową fazą planowania ciągłości działania jest zidentyfikowanie ryzyka związanego z dostępnością lub funkcjonalnością obciążenia. Każde ryzyko należy przeanalizować, aby zrozumieć jego prawdopodobieństwo i jego ważność. Ważność musi obejmować wszelkie potencjalne przestoje lub utratę danych, a także to, czy jakiekolwiek aspekty pozostałej części projektu rozwiązania mogą zrekompensować negatywne skutki.
Poniższa tabela to niewyczerpująca lista zagrożeń uporządkowana przez zmniejszenie prawdopodobieństwa:
| Przykładowe ryzyko | opis | Regularność (prawdopodobieństwo) |
|---|---|---|
| Przejściowy problem z siecią | Tymczasowy błąd w składniku stosu sieciowego, który można odzyskać po krótkim czasie (zwykle kilka sekund lub mniej). | Zwykły |
| Ponowne uruchomienie maszyny wirtualnej | Ponowne uruchomienie używanej maszyny wirtualnej lub używanej przez usługę zależną. Mogą wystąpić ponowne rozruchy, ponieważ maszyna wirtualna ulega awarii lub musi zastosować poprawkę. | Zwykły |
| Awaria sprzętu | Awaria składnika w centrum danych, takiego jak węzeł sprzętowy, stojak lub klaster. | Okazjonalne |
| Awaria centrum danych | Awaria, która ma wpływ na większość lub wszystkie centrum danych, takie jak awaria zasilania, problem z łącznością sieciową lub problemy z ogrzewaniem i chłodzeniem. | Niezwykły |
| Awaria regionu | Awaria, która wpływa na cały obszar metropolitalny lub szerszy obszar, taki jak poważna klęska żywiołowa. | Bardzo nietypowe |
Planowanie ciągłości działania nie dotyczy tylko platformy chmury i infrastruktury. Ważne jest, aby wziąć pod uwagę ryzyko błędów ludzkich. Ponadto niektóre zagrożenia, które tradycyjnie mogą być uważane za zabezpieczenia, wydajność lub ryzyko operacyjne, należy również uznać za ryzyko związane z niezawodnością, ponieważ wpływają one na dostępność rozwiązania.
Oto kilka przykładów:
| Przykładowe ryzyko | opis |
|---|---|
| Utrata lub uszkodzenie danych | Dane zostały usunięte, nadpisane lub w inny sposób uszkodzone przez wypadek lub z naruszenia zabezpieczeń, takie jak atak wymuszającego okup. |
| Usterka oprogramowania | Wdrożenie nowego lub zaktualizowanego kodu wprowadza usterkę, która ma wpływ na dostępność lub integralność, pozostawiając obciążenie w stanie awarii. |
| Nieudane wdrożenia | Wdrożenie nowego składnika lub wersji nie powiodło się, pozostawiając rozwiązanie w stanie niespójnym. |
| Ataki typu "odmowa usługi" | System został zaatakowany w celu zapobieżenia uzasadnionemu użyciu rozwiązania. |
| Nieautoryzować administratorów | Użytkownik z uprawnieniami administracyjnymi celowo wykonał szkodliwe działanie względem systemu. |
| Nieoczekiwany napływ ruchu do aplikacji | Gwałtowny wzrost ruchu przytłoczył zasoby systemu. |
Analiza trybu awarii (FMA) to proces identyfikowania potencjalnych sposobów awarii obciążenia lub jego składników oraz sposobu działania rozwiązania w tych sytuacjach. Aby dowiedzieć się więcej, zobacz Zalecenia dotyczące przeprowadzania analizy trybu awarii.
Klasyfikacja ryzyka
Plany ciągłości działania muszą dotyczyć zarówno typowych, jak i nietypowych zagrożeń.
Typowe zagrożenia są planowane i oczekiwane. Na przykład w środowisku chmury często występują przejściowe awarie , w tym krótkie awarie sieci, ponowne uruchomienia sprzętu z powodu poprawek, przekroczenia limitu czasu, gdy usługa jest zajęta itd. Ponieważ te zdarzenia są regularnie wykonywane, obciążenia muszą być odporne na nie.
Strategia wysokiej dostępności musi uwzględniać i kontrolować każde ryzyko tego typu.
Nietypowe zagrożenia są zazwyczaj wynikiem nieprzewidzianego zdarzenia, takiego jak klęska żywiołowa lub poważny atak sieciowy, które mogą prowadzić do katastrofalnego przestoju.
Procesy odzyskiwania po awarii zajmują się tymi rzadkimi zagrożeniami.
Wysoka dostępność i odzyskiwanie po awarii są powiązane, dlatego ważne jest, aby zaplanować strategie obu tych strategii.
Ważne jest, aby zrozumieć, że klasyfikacja ryzyka zależy od architektury obciążenia i wymagań biznesowych, a niektóre zagrożenia mogą być klasyfikowane jako wysoka dostępność dla jednego obciążenia i odzyskiwania po awarii dla innego obciążenia. Na przykład pełna awaria w regionie świadczenia usługi Azure byłaby ogólnie uznawana za ryzyko odzyskiwania po awarii dla obciążeń w tym regionie. Jednak w przypadku obciążeń korzystających z wielu regionów platformy Azure w konfiguracji aktywne-aktywne z pełną replikacją, nadmiarowością i automatycznym trybem failover regionu awaria regionu jest klasyfikowana jako ryzyko wysokiej dostępności.
Ograniczenie ryzyka
Ograniczenie ryzyka polega na opracowywaniu strategii wysokiej dostępności lub odzyskiwania po awarii w celu zminimalizowania lub ograniczenia ryzyka związanego z ciągłością działalności biznesowej. Ograniczenie ryzyka może być oparte na technologii lub na podstawie człowieka.
Ograniczenie ryzyka opartego na technologii
Ograniczenie ryzyka oparte na technologii wykorzystuje mechanizmy kontroli ryzyka oparte na sposobie wdrażania i konfigurowania obciążenia, takich jak:
- Nadmiarowość
- Replikacja danych
- Tryb failover
- Kopie zapasowe
Mechanizmy kontroli ryzyka oparte na technologii muszą być brane pod uwagę w kontekście planu ciągłości działania.
Na przykład:
Wymagania dotyczące małych przestojów. Niektóre plany ciągłości działania nie są w stanie tolerować żadnej formy ryzyka przestoju ze względu na rygorystyczne wymagania dotyczące wysokiej dostępności . Istnieją pewne mechanizmy kontroli oparte na technologii, które mogą wymagać czasu na powiadomienie człowieka, a następnie reagowanie. Mechanizmy kontroli ryzyka opartej na technologii, które obejmują powolne procesy ręczne, mogą nie być dopasowane do włączenia ich do strategii ograniczania ryzyka.
Tolerancja częściowej awarii. Niektóre plany ciągłości działania są w stanie tolerować przepływ pracy uruchamiany w stanie obniżonej wydajności. Gdy rozwiązanie działa w stanie obniżonej wydajności, niektóre składniki mogą być wyłączone lub niefunkcjonalne, ale podstawowe operacje biznesowe mogą być nadal wykonywane. Aby dowiedzieć się więcej, zobacz Zalecenia dotyczące samonaprawiania i samozachowawczego.
Ograniczenie ryzyka opartego na człowieku
Ograniczenie ryzyka opartego na człowieku korzysta z mechanizmów kontroli ryzyka opartych na procesach biznesowych, takich jak:
- Wyzwalanie podręcznika odpowiedzi.
- Powrót do operacji ręcznych.
- Szkolenia i zmiany kulturowe.
Ważne
Osoby projektujące, wdrażające, operacyjne i zmieniające się obciążenie powinny być kompetentne, zachęcane do wypowiadania się, jeśli mają obawy i czują poczucie odpowiedzialności za system.
Ze względu na to, że mechanizmy kontroli ryzyka oparte na człowieku są często wolniejsze niż mechanizmy kontroli oparte na technologii i bardziej podatne na błędy ludzkie, dobry plan ciągłości działania powinien obejmować formalny proces kontroli zmian dla wszystkich elementów, które mogłyby zmienić stan działającego systemu. Rozważ na przykład zaimplementowanie następujących procesów:
- Rygorystycznie przetestuj obciążenia zgodnie z krytycznością obciążenia. Aby zapobiec problemom związanym ze zmianami, należy przetestować wszelkie zmiany wprowadzone w obciążeniu.
- Wprowadzenie strategicznych bram jakości w ramach bezpiecznych praktyk wdrażania obciążenia. Aby dowiedzieć się więcej, zobacz Zalecenia dotyczące bezpiecznych praktyk wdrażania.
- Sformalizuj procedury dostępu do produkcji ad hoc i manipulowania danymi. Te działania, niezależnie od tego, jak niewielkie, mogą stanowić wysokie ryzyko wystąpienia zdarzeń związanych z niezawodnością. Procedury mogą obejmować parowanie z innym inżynierem, używanie list kontrolnych i pobieranie przeglądów równorzędnych przed wykonaniem skryptów lub zastosowaniem zmian.
Wysoka dostępność
Wysoka dostępność to stan, w którym określone obciążenie może utrzymywać niezbędny poziom czasu pracy w ciągu dnia, nawet podczas przejściowych błędów i sporadycznych awarii. Ponieważ te zdarzenia są regularnie wykonywane, ważne jest, aby każde obciążenie zostało zaprojektowane i skonfigurowane pod kątem wysokiej dostępności zgodnie z wymaganiami określonych aplikacji i oczekiwań klientów. Wysoka dostępność każdego obciążenia przyczynia się do planu ciągłości działania.
Wysoka dostępność może się różnić w zależności od obciążenia, dlatego ważne jest, aby zrozumieć wymagania i oczekiwania klientów podczas określania wysokiej dostępności. Na przykład aplikacja używana przez organizację do zamawiania materiałów biurowych może wymagać stosunkowo niskiego poziomu czasu pracy, podczas gdy krytyczna aplikacja finansowa może wymagać znacznie wyższego czasu pracy. Nawet w ramach obciążenia różne przepływy mogą mieć różne wymagania. Na przykład w aplikacji handlu elektronicznego przepływy obsługujące przeglądanie i składanie zamówień mogą być ważniejsze niż przepływy przetwarzania zamówień i zaplecza. Aby dowiedzieć się więcej na temat przepływów, zobacz Zalecenia dotyczące identyfikowania i oceniania przepływów.
Często czas pracy jest mierzony na podstawie liczby "dziewiątek" w procentach czasu pracy. Procent czasu pracy odnosi się do tego, ile przestojów zezwalasz na dany okres czasu. Oto kilka przykładów:
- 99,9% wymaganie czasu pracy (trzy dziewiątki) pozwala na około 43 minuty przestoju w miesiącu.
- 99,95% wymaganie czasu pracy (trzy i pół dziewiątki) pozwala na około 21 minut przestoju w miesiącu.
Im wyższe wymaganie dotyczące czasu pracy, tym mniejsza tolerancja dla przestojów, a im więcej pracy trzeba wykonać, aby osiągnąć ten poziom dostępności. Czas pracy nie jest mierzony przez czas pracy pojedynczego składnika, takiego jak węzeł, ale przez ogólną dostępność całego obciążenia.
Ważne
Nie przesadzaj z rozwiązaniem, aby osiągnąć wyższy poziom niezawodności niż są uzasadnione. Użyj wymagań biznesowych, aby kierować decyzjami.
Elementy projektu o wysokiej dostępności
Aby osiągnąć wymagania dotyczące wysokiej dostępności, obciążenie może zawierać wiele elementów projektowych. Niektóre typowe elementy są wymienione i opisane poniżej w tej sekcji.
Uwaga
Niektóre obciążenia mają krytyczne znaczenie, co oznacza, że wszelkie przestoje mogą mieć poważne konsekwencje dla ludzkiego życia i bezpieczeństwa lub poważnych strat finansowych. Jeśli projektujesz obciążenie o znaczeniu krytycznym, podczas projektowania rozwiązania i zarządzania ciągłością biznesową należy wziąć pod uwagę konkretne kwestie. Aby uzyskać więcej informacji, zobacz Azure Well-Architected Framework: Obciążenia o znaczeniu krytycznym.
Usługi i warstwy platformy Azure, które obsługują wysoką dostępność
Wiele usług platformy Azure jest przeznaczonych do wysokiej dostępności i może służyć do tworzenia obciążeń o wysokiej dostępności. Oto kilka przykładów:
- Zestawy skalowania maszyn wirtualnych platformy Azure zapewniają wysoką dostępność maszyn wirtualnych przez automatyczne tworzenie wystąpień maszyn wirtualnych i zarządzanie nimi oraz dystrybucję tych wystąpień maszyn wirtualnych w celu zmniejszenia wpływu awarii infrastruktury.
- usługa aplikacja systemu Azure zapewnia wysoką dostępność za pośrednictwem różnych metod, w tym automatycznego przenoszenia procesów roboczych z węzła w złej kondycji do węzła w dobrej kondycji oraz zapewniając możliwości samonaprawiania z wielu typowych błędów.
Skorzystaj z każdego przewodnika po niezawodności usługi, aby zrozumieć możliwości usługi, zdecydować, które warstwy mają być używane, i określić, które możliwości uwzględnić w strategii wysokiej dostępności.
Zapoznaj się z umowami dotyczącymi poziomu usług (SLA) dla każdej usługi, aby zrozumieć oczekiwane poziomy dostępności i warunki, które należy spełnić. Może być konieczne wybranie lub uniknięcie określonych warstw usług w celu osiągnięcia określonych poziomów dostępności. Niektóre usługi firmy Microsoft są oferowane ze zrozumieniem, że nie podano umowy SLA, takiej jak warstwa deweloperska lub podstawowa, lub że zasób może zostać odzyskany z uruchomionego systemu, na przykład oferty oparte na spot. Ponadto niektóre warstwy mają dodatkowe funkcje niezawodności, takie jak obsługa stref dostępności.
Odporność na uszkodzenia
Odporność na uszkodzenia to możliwość kontynuowania działania systemu w określonej pojemności w przypadku awarii. Na przykład aplikacja internetowa może być zaprojektowana tak, aby kontynuować działanie, nawet jeśli pojedynczy serwer internetowy ulegnie awarii. Odporność na uszkodzenia można osiągnąć za pomocą nadmiarowości, trybu failover, partycjonowania, łagodnego obniżenia wydajności i innych technik.
Odporność na uszkodzenia wymaga również, aby aplikacje obsługiwały błędy przejściowe. Podczas tworzenia własnego kodu może być konieczne samodzielne włączenie obsługi błędów przejściowych. Niektóre usługi platformy Azure zapewniają wbudowaną obsługę błędów przejściowych w niektórych sytuacjach. Na przykład domyślnie usługa Azure Logic Apps automatycznie ponawia próby żądań do innych usług. Aby dowiedzieć się więcej, zobacz Zalecenia dotyczące obsługi błędów przejściowych.
Nadmiarowość
Nadmiarowość to praktyka duplikowania wystąpień lub danych w celu zwiększenia niezawodności obciążenia.
Nadmiarowość można osiągnąć poprzez dystrybucję replik lub wystąpień nadmiarowych w jeszcze jeden z następujących sposobów:
- Wewnątrz centrum danych (nadmiarowość lokalna)
- Między strefami dostępności w regionie (nadmiarowość strefy)
- Między regionami (nadmiarowość geograficzna).
Oto kilka przykładów sposobu, w jaki niektóre usługi platformy Azure zapewniają opcje nadmiarowości:
- aplikacja systemu Azure Service umożliwia uruchamianie wielu wystąpień aplikacji, aby upewnić się, że aplikacja pozostaje dostępna nawet w przypadku awarii jednego wystąpienia. Jeśli włączysz nadmiarowość strefy, te wystąpienia są rozłożone na wiele stref dostępności w używanym regionie świadczenia usługi Azure.
- Usługa Azure Storage zapewnia wysoką dostępność przez automatyczne replikowanie danych co najmniej trzy razy. Te repliki można dystrybuować w różnych strefach dostępności, włączając magazyn strefowo nadmiarowy (ZRS), a w wielu regionach można również replikować dane magazynu między regionami przy użyciu magazynu geograficznie nadmiarowego (GRS).
- Usługa Azure SQL Database ma wiele replik, aby upewnić się, że dane pozostają dostępne nawet w przypadku awarii jednej repliki.
Aby dowiedzieć się więcej na temat nadmiarowości, zobacz Zalecenia dotyczące projektowania nadmiarowości i zalecenia dotyczące używania stref dostępności i regionów.
Skalowalność i elastyczność
Skalowalność i elastyczność to możliwości systemu do obsługi zwiększonego obciążenia przez dodawanie i usuwanie zasobów (skalowalność) oraz szybkie zmienianie wymagań (elastyczność). Skalowalność i elastyczność mogą pomóc systemowi w utrzymaniu dostępności podczas szczytowych obciążeń.
Wiele usług platformy Azure obsługuje skalowalność. Oto kilka przykładów:
- Zestawy skalowania maszyn wirtualnych platformy Azure, usługa Azure API Management i kilka innych usług obsługują automatyczne skalowanie usługi Azure Monitor. Dzięki funkcji automatycznego skalowania usługi Azure Monitor można określić zasady, takie jak "gdy mój procesor stale przekracza 80%, dodaj kolejne wystąpienie".
- Usługa Azure Functions może dynamicznie aprowizować wystąpienia w celu obsługi żądań.
- Usługa Azure Cosmos DB obsługuje przepływność autoskalowania, w której usługa może automatycznie zarządzać zasobami przypisanymi do baz danych na podstawie podanych zasad.
Skalowalność jest kluczowym czynnikiem, który należy wziąć pod uwagę podczas częściowej lub całkowitej awarii. Jeśli replika lub wystąpienie obliczeniowe jest niedostępne, pozostałe składniki mogą wymagać większego obciążenia, aby obsłużyć obciążenie, które wcześniej obsłużyło uszkodzony węzeł. Rozważ nadmierną aprowizowanie , jeśli system nie może wystarczająco szybko skalować, aby obsłużyć oczekiwane zmiany obciążenia.
Aby uzyskać więcej informacji na temat projektowania skalowalnego i elastycznego systemu, zobacz Zalecenia dotyczące projektowania niezawodnej strategii skalowania.
Techniki wdrażania bez przestojów
Wdrożenia i inne zmiany systemowe powodują znaczne ryzyko przestoju. Ponieważ ryzyko przestoju jest wyzwaniem dla wymagań dotyczących wysokiej dostępności, ważne jest użycie praktyk wdrażania bez przestojów w celu wprowadzania aktualizacji i zmian konfiguracji bez konieczności przestoju.
Techniki wdrażania bez przestojów mogą obejmować:
- Aktualizowanie podzbioru zasobów naraz.
- Kontrolowanie ilości ruchu, który dociera do nowego wdrożenia.
- Monitorowanie dowolnego wpływu na użytkowników lub system.
- Szybkie korygowanie problemu, na przykład przez przywrócenie poprzedniego znanego dobrego wdrożenia.
Aby dowiedzieć się więcej na temat technik wdrażania bez przestojów, zobacz Bezpieczne praktyki wdrażania.
Sama platforma Azure używa metod wdrażania bez przestojów dla naszych własnych usług. Podczas tworzenia własnych aplikacji można wdrażać wdrożenia bez przestojów za pomocą różnych metod, takich jak:
- Usługa Azure Container Apps udostępnia wiele poprawek aplikacji, których można użyć do osiągnięcia wdrożeń bez przestojów.
- Usługa Azure Kubernetes Service (AKS) obsługuje różne techniki wdrażania bez przestojów.
Chociaż wdrożenia bez przestojów są często skojarzone z wdrożeniami aplikacji, należy ich również używać do zmian konfiguracji. Poniżej przedstawiono kilka sposobów bezpiecznego stosowania zmian konfiguracji:
- Usługa Azure Storage umożliwia zmianę kluczy dostępu do konta magazynu na wielu etapach, co zapobiega przestojom podczas operacji rotacji kluczy.
- aplikacja systemu Azure Configuration udostępnia flagi funkcji, migawki i inne funkcje ułatwiające kontrolowanie sposobu stosowania zmian konfiguracji.
Jeśli zdecydujesz się nie implementować wdrożeń bez przestojów, upewnij się, że zdefiniujesz okna obsługi, aby można było wprowadzać zmiany systemu w czasie, gdy użytkownicy tego oczekują.
Testowanie automatyczne
Ważne jest, aby przetestować zdolność rozwiązania do wytrzymania awarii i awarii, które należy wziąć pod uwagę w zakresie wysokiej dostępności. Wiele z tych błędów można symulować w środowiskach testowych. Testowanie możliwości automatycznego tolerowania lub odzyskiwania po różnych typach błędów jest nazywane inżynierią chaosu. Inżynieria chaosu ma kluczowe znaczenie dla dojrzałych organizacji o rygorystycznych standardach dotyczących wysokiej dostępności. Azure Chaos Studio to narzędzie do inżynierii chaosu, które może symulować niektóre typowe typy błędów.
Aby dowiedzieć się więcej, zobacz Zalecenia dotyczące projektowania strategii testowania niezawodności.
Monitorowanie i zgłaszanie alertów
Monitorowanie informuje o kondycji systemu, nawet gdy mają miejsce zautomatyzowane środki zaradcze. Monitorowanie ma kluczowe znaczenie dla zrozumienia, jak działa twoje rozwiązanie, oraz do obserwowania wczesnych sygnałów awarii, takich jak zwiększone współczynniki błędów lub wysokie zużycie zasobów. Dzięki alertom możesz aktywnie otrzymywać ważne zmiany w środowisku.
Platforma Azure oferuje różne funkcje monitorowania i alertów, w tym następujące:
- Usługa Azure Monitor zbiera dzienniki i metryki z zasobów i aplikacji platformy Azure oraz może wysyłać alerty i wyświetlać dane na pulpitach nawigacyjnych.
- Usługa Azure Monitor Application Insights zapewnia szczegółowe monitorowanie aplikacji.
- Usługa Azure Service Health i usługa Azure Resource Health monitorują kondycję platformy Azure i zasobów.
- Zaplanowane zdarzenia doradzają, gdy konserwacja jest planowana dla maszyn wirtualnych.
Aby uzyskać więcej informacji, zobacz Zalecenia dotyczące projektowania niezawodnej strategii monitorowania i zgłaszania alertów.
Odzyskiwanie po awarii
Awaria to odrębne, nietypowe, poważne zdarzenie, które ma większy i długotrwały wpływ, niż aplikacja może ograniczyć poprzez aspekt wysokiej dostępności projektu. Przykłady awarii to:
- Klęski żywiołowe, takie jak huragany, trzęsienia ziemi, powodzie lub pożary.
- Błędy ludzkie, które powodują poważny wpływ, na przykład przypadkowe usunięcie danych produkcyjnych lub nieprawidłowo skonfigurowaną zaporę, która uwidacznia poufne dane.
- Główne zdarzenia zabezpieczeń, takie jak ataki typu "odmowa usługi" lub ataki wymuszające okup, które prowadzą do uszkodzenia danych, utraty danych lub awarii usługi.
Odzyskiwanie po awarii polega na planowaniu sposobu reagowania na tego typu sytuacje.
Uwaga
Należy postępować zgodnie z zalecanymi rozwiązaniami, aby zminimalizować prawdopodobieństwo wystąpienia tych zdarzeń. Jednak nawet po starannym proaktywnym planowaniu rozsądne jest zaplanowanie sposobu reagowania na te sytuacje, jeśli wystąpią.
Wymagania dotyczące odzyskiwania po awarii
Ze względu na rzadkość i ważność zdarzeń awarii planowanie odzyskiwania po awarii przynosi różne oczekiwania dotyczące odpowiedzi. Wiele organizacji akceptuje fakt, że w scenariuszu awarii pewien poziom przestoju lub utraty danych jest nieunikniony. Kompletny plan odzyskiwania po awarii musi określać następujące krytyczne wymagania biznesowe dla każdego przepływu:
Cel punktu odzyskiwania (RPO) to maksymalny czas trwania akceptowalnej utraty danych w przypadku awarii. Cel punktu odzyskiwania jest mierzony w jednostkach czasu, takich jak "30 minut danych" lub "cztery godziny danych".
Cel czasu odzyskiwania (RTO) to maksymalny czas trwania akceptowalnego przestoju w przypadku awarii, w którym "przestój" jest definiowany przez specyfikację. Cel czasu odzyskiwania jest również mierzony w jednostkach czasu, takich jak "osiem godzin przestoju".
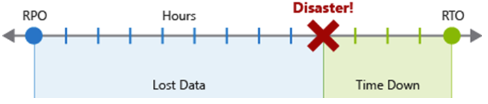
Każdy składnik lub przepływ w obciążeniu mogą mieć poszczególne wartości celu punktu odzyskiwania i celu punktu odzyskiwania. Zapoznaj się z ryzykiem scenariusza awarii i potencjalnymi strategiami odzyskiwania podczas podejmowania decyzji o wymaganiach. Proces określania celu punktu odzyskiwania i celu odzyskiwania skutecznie tworzy wymagania odzyskiwania po awarii dla obciążenia w wyniku unikatowych problemów biznesowych (kosztów, wpływu, utraty danych itp.).
Uwaga
Chociaż kuszące jest dążenie do celu czasu odzyskiwania i celu punktu odzyskiwania zera (bez przestoju i braku utraty danych w przypadku awarii), w praktyce jest trudne i kosztowne wdrożenie. Ważne jest, aby uczestnicy projektu technicznego i biznesowego omawiali te wymagania razem i decydowali o realistycznych wymaganiach. Aby uzyskać więcej informacji, zobacz Zalecenia dotyczące definiowania celów niezawodności.
Plany odzyskiwania po awarii
Niezależnie od przyczyny awarii ważne jest utworzenie dobrze zdefiniowanego i testowalnego planu odzyskiwania po awarii. Ten plan będzie używany jako część projektu infrastruktury i aplikacji, aby aktywnie go obsługiwać. Możesz utworzyć wiele planów odzyskiwania po awarii dla różnych typów sytuacji. Plany odzyskiwania po awarii często polegają na kontrolach procesów i ręcznej interwencji.
Odzyskiwanie po awarii nie jest funkcją automatyczną platformy Azure. Jednak wiele usług udostępnia funkcje i możliwości, których można użyć do obsługi strategii odzyskiwania po awarii. Zapoznaj się z przewodnikami dotyczącymi niezawodności dla każdej usługi platformy Azure, aby zrozumieć, jak działa usługa i jej możliwości, a następnie zamapować te możliwości na plan odzyskiwania po awarii.
W poniższych sekcjach wymieniono niektóre typowe elementy planu odzyskiwania po awarii i opisano, jak platforma Azure może ci pomóc w ich osiągnięciu.
Przechodzenie w tryb failover i powrót po awarii
Niektóre plany odzyskiwania po awarii obejmują aprowizowanie wdrożenia pomocniczego w innej lokalizacji. Jeśli awaria wpłynie na podstawowe wdrożenie rozwiązania, ruch może zostać przełączony w tryb failover do innej lokacji. Tryb failover wymaga starannego planowania i implementacji. Platforma Azure oferuje różne usługi ułatwiające przejście w tryb failover, takie jak:
- Usługa Azure Site Recovery zapewnia automatyczne przechodzenie w tryb failover dla środowisk lokalnych i rozwiązań hostowanych na maszynach wirtualnych na platformie Azure.
- Usługi Azure Front Door i Azure Traffic Manager obsługują automatyczne przełączanie ruchu przychodzącego w tryb failover między różnymi wdrożeniami rozwiązania, na przykład w różnych regionach.
Proces trybu failover zwykle zajmuje trochę czasu, aby wykryć, że wystąpienie podstawowe nie powiodło się i przełączyło się do wystąpienia pomocniczego. Upewnij się, że cel czasu odzyskiwania obciążenia jest zgodny z czasem pracy w trybie failover.
Ważne jest również, aby rozważyć powrót po awarii, czyli proces przywracania operacji w regionie podstawowym po jego odzyskaniu. Powrót po awarii może być złożony do planowania i implementowania. Na przykład dane w regionie podstawowym mogły zostać zapisane po rozpoczęciu pracy w trybie failover. Musisz podjąć staranne decyzje biznesowe dotyczące sposobu obsługi tych danych.
Kopie zapasowe
Kopie zapasowe obejmują pobranie kopii danych i bezpieczne przechowywanie ich przez określony czas. Dzięki kopiom zapasowym można odzyskać dane po awariach, gdy automatyczne przejście w tryb failover do innej repliki nie jest możliwe lub gdy wystąpiło uszkodzenie danych.
W przypadku korzystania z kopii zapasowych w ramach planu odzyskiwania po awarii należy wziąć pod uwagę następujące kwestie:
Lokalizacja magazynu. W przypadku korzystania z kopii zapasowych w ramach planu odzyskiwania po awarii powinny one być przechowywane oddzielnie dla głównych danych. Zazwyczaj kopie zapasowe są przechowywane w innym regionie świadczenia usługi Azure.
Utrata danych. Ponieważ kopie zapasowe są zwykle wykonywane rzadko, przywracanie kopii zapasowych zwykle wiąże się z utratą danych. Z tego powodu odzyskiwanie kopii zapasowej powinno być używane w ostateczności, a plan odzyskiwania po awarii powinien określać sekwencję kroków i prób odzyskiwania, które należy wykonać przed przywróceniem z kopii zapasowej. Ważne jest, aby upewnić się, że cel punktu odzyskiwania obciążenia jest zgodny z interwałem tworzenia kopii zapasowej.
Czas odzyskiwania. Przywracanie kopii zapasowej często zajmuje dużo czasu, dlatego ważne jest przetestowanie kopii zapasowych i procesów przywracania w celu zweryfikowania ich integralności i zrozumienia, jak długo trwa proces przywracania. Upewnij się, że konta celu czasu odzyskiwania obciążenia przez czas potrzebny na przywrócenie kopii zapasowej.
Wiele usług danych i magazynowania platformy Azure obsługuje kopie zapasowe, takie jak:
- Usługa Azure Backup udostępnia automatyczne kopie zapasowe dla dysków maszyn wirtualnych, kont magazynu, usługi AKS i różnych innych źródeł.
- Wiele usług baz danych platformy Azure, w tym usług Azure SQL Database i Azure Cosmos DB, ma funkcję automatycznego tworzenia kopii zapasowych baz danych.
- Usługa Azure Key Vault udostępnia funkcje umożliwiające tworzenie kopii zapasowych wpisów tajnych, certyfikatów i kluczy.
Wdrożenia automatyczne
Aby szybko wdrożyć i skonfigurować wymagane zasoby w przypadku awarii, użyj zasobów infrastruktury jako kodu (IaC), takich jak pliki Bicep, szablony usługi ARM lub plik konfiguracji narzędzia Terraform. Użycie IaC skraca czas odzyskiwania i potencjalne błędy w porównaniu z ręcznym wdrażaniem i konfigurowaniem zasobów.
Testowanie i przechodzenie do szczegółów
Ważne jest, aby rutynowo weryfikować i testować plany odzyskiwania po awarii, a także szerszą strategię niezawodności. Uwzględnij wszystkie procesy ludzkie w ćwiczeniach i nie skupiaj się tylko na procesach technicznych.
Jeśli nie przetestowano procesów odzyskiwania w symulacji awarii, prawdopodobnie wystąpią poważne problemy podczas korzystania z nich w rzeczywistej awarii. Ponadto, testując plany odzyskiwania po awarii i wymagane procesy, można zweryfikować wykonalność celu odzyskiwania.
Aby dowiedzieć się więcej, zobacz Zalecenia dotyczące projektowania strategii testowania niezawodności.
Powiązana zawartość
- Skorzystaj z przewodników dotyczących niezawodności usług platformy Azure, aby dowiedzieć się, jak każda usługa platformy Azure obsługuje niezawodność w projekcie, oraz dowiedzieć się więcej o możliwościach, które można utworzyć w planach wysokiej dostępności i odzyskiwania po awarii.
- Skorzystaj z filaru Azure Well-Architected Framework: Niezawodność, aby dowiedzieć się więcej na temat projektowania niezawodnego obciążenia na platformie Azure.
- Skorzystaj z perspektywy dobrze zaprojektowanej struktury dla usług platformy Azure, aby dowiedzieć się więcej o sposobie konfigurowania każdej usługi platformy Azure w celu spełnienia wymagań dotyczących niezawodności i innych filarów dobrze zaprojektowanej struktury.
- Aby dowiedzieć się więcej na temat planowania odzyskiwania po awarii, zobacz Zalecenia dotyczące projektowania strategii odzyskiwania po awarii.