Aanbevelingen voor de respons op beveiligingsincidenten
Geldt voor de aanbeveling van de Well-Architected Security-checklist: Power Platform
| SE:11 | Definieer en test effectieve incidentresponsprocedures die een spectrum aan incidenten bestrijken, van lokale problemen tot herstel na noodgeval. Bepaal duidelijk welk team of welke individu een procedure uitvoert. |
|---|
In deze gids worden de aanbevelingen beschreven voor het implementeren van een reactie op een beveiligingsincident voor een workload. Als er sprake is van een beveiligingsprobleem in een systeem, helpt een systematische incidentresponsbenadering de tijd te verkorten die nodig is om beveiligingsincidenten te identificeren, beheren en beperken. Deze incidenten kunnen de vertrouwelijkheid, integriteit en beschikbaarheid van softwaresystemen en gegevens bedreigen.
De meeste ondernemingen hebben een centraal beveiligingsteam (ook bekend als Security Operations Center [SOC] of SecOps). De verantwoordelijkheid van het beveiligingsteam is het snel detecteren, prioriteren en beoordelen van potentiële aanvallen. Het team bewaakt ook beveiligingsgerelateerde telemetriegegevens en onderzoekt inbreuken op de beveiliging.
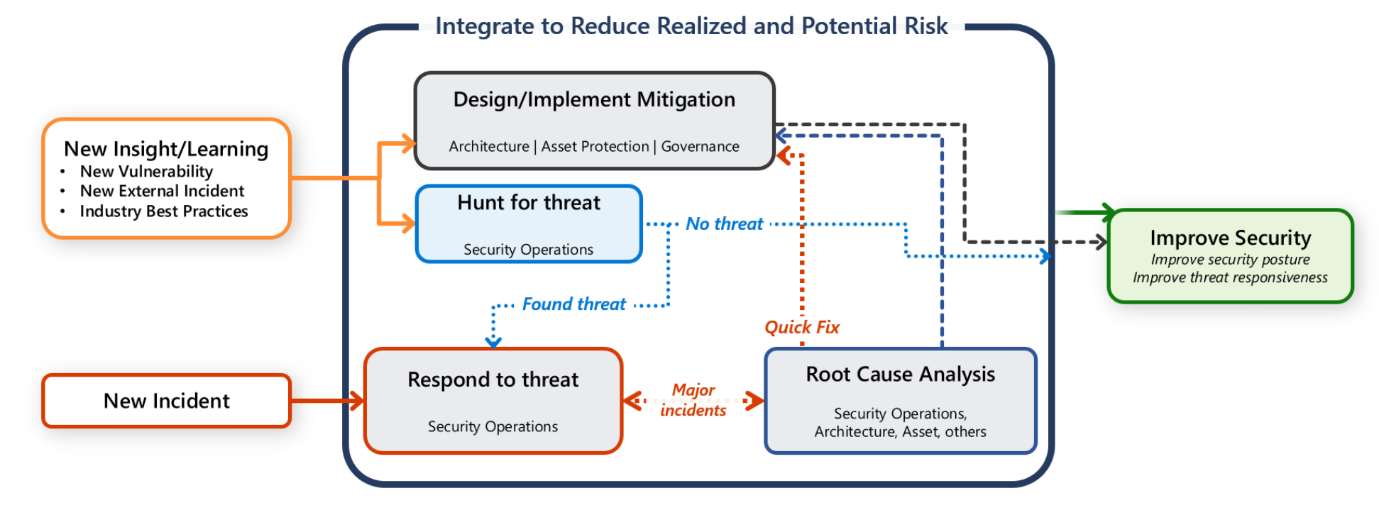
U hebt echter ook de verantwoordelijkheid om uw workload te beschermen. Het is belangrijk dat alle communicatie-, onderzoeks- en opsporingsactiviteiten een gezamenlijke inspanning zijn tussen het workloadteam en het SecOps-team.
Deze gids biedt aanbevelingen voor u en uw workloadteam om u te helpen aanvallen snel te detecteren, te schiften en te onderzoeken.
Definities
| Term | Definitie |
|---|---|
| Waarschuwing | Een melding met informatie over een incident. |
| Waarheidsgetrouwheid | De nauwkeurigheid van de gegevens die een waarschuwing bepalen. Waarschuwingen met een hoge betrouwbaarheid bevatten de beveiligingscontext die nodig is om onmiddellijk actie te ondernemen. Waarschuwingen met een lage betrouwbaarheid bevatten geen informatie of bevatten ruis. |
| Fout-positief | Een waarschuwing die een incident aangeeft dat niet heeft plaatsgevonden. |
| Incident | Een gebeurtenis die ongeautoriseerde toegang tot een systeem aangeeft. |
| Incidentrespons | Een proces dat de risico's die aan een incident zijn verbonden, detecteert, erop reageert en deze beperkt. |
| Triage | Een incidentresponsoperatie die beveiligingsproblemen analyseert en prioriteit geeft aan de beperking ervan. |
Belangrijke ontwerpstrategieën
U en uw team voeren incidentresponsoperaties uit wanneer een signaal of waarschuwing wijst op een mogelijk beveiligingsincident. Waarschuwingen met een hoge betrouwbaarheid bevatten voldoende beveiligingscontext waardoor analisten gemakkelijk beslissingen kunnen nemen. Waarschuwingen met een hoge betrouwbaarheid resulteren in een laag aantal valse positieven. In deze gids wordt ervan uitgegaan dat een waarschuwingssysteem signalen met een lage betrouwbaarheid filtert en zich richt op waarschuwingen met een hoge betrouwbaarheid die op een reëel incident kunnen duiden.
Incidentmeldingen toepwijzen
Beveiligingswaarschuwingen moeten de juiste mensen in uw team en organisatie bereiken. Stel een aangewezen contactpunt in uw workloadteam in om incidentmeldingen te ontvangen. Deze meldingen moeten zoveel mogelijk informatie bevatten over de aangetaste resource en het systeem. De waarschuwing moet de volgende stappen bevatten, zodat uw team acties kan versnellen.
We raden u aan incidentmeldingen en -acties vast te leggen en te beheren met behulp van gespecialiseerde tools die een audittrail bijhouden. Door standaardtools te gebruiken, kunt u bewijsmateriaal bewaren dat nodig kan zijn voor mogelijke juridische onderzoeken. Zoek naar mogelijkheden om automatisering te implementeren die meldingen kan versturen op basis van de verantwoordelijkheden van verantwoordelijke partijen. Zorg voor een duidelijke communicatie- en rapportageketen tijdens een incident.
Profiteer van de SIEM-oplossingen (Security Information Event Management) en SOAR-oplossingen (Security Orchestration Automated Response) die uw organisatie biedt. Als alternatief kunt u hulpmiddelen voor incidentbeheer aanschaffen en uw organisatie aanmoedigen deze voor alle workloadteams te standaardiseren.
Samen met een triageteam onderzoeken
Het teamlid dat een incidentmelding ontvangt, is verantwoordelijk voor het opzetten van een schiftingsproces waarbij de juiste personen worden betrokken op basis van de beschikbare gegevens. Het triageteam, vaak het bridgeteam genoemd, moet het eens worden over de methode en het communicatieproces. Vereist dit incident asynchrone gesprekken of bruggesprekken? Hoe moet het team de voortgang van onderzoeken volgen en communiceren? Waar heeft het team toegang tot incidentassets?
Incidentrespons is een cruciale reden om documentatie up-to-date te houden, zoals de architectonische indeling van het systeem, informatie op componentniveau, privacy- of beveiligingsclassificatie, eigenaren en belangrijke contactpunten. Als de informatie onnauwkeurig of verouderd is, verspilt het brugteam kostbare tijd aan het proberen te begrijpen hoe het systeem werkt, wie verantwoordelijk is voor elk gebied en wat het effect van de gebeurtenis kan zijn.
Betrek voor verder onderzoek de juiste mensen. U kunt hierbij denken aan een incidentmanager, beveiligingsfunctionaris of op workloadgerichte potentiële klanten. Om de triage gefocust te houden, sluit u mensen uit die buiten de reikwijdte van het probleem vallen. Soms onderzoeken afzonderlijke teams het incident. Er kan een team zijn dat het probleem in eerste instantie onderzoekt en het incident probeert te beperken, en een ander gespecialiseerd team dat forensisch onderzoek kan uitvoeren voor een diepgaand onderzoek om grote problemen vast te stellen. U kunt de workloadomgeving in quarantaine plaatsen, zodat het forensisch team onderzoek kan doen. In sommige gevallen kan hetzelfde team het gehele onderzoek afhandelen.
In de beginfase is het triageteam verantwoordelijk voor het bepalen van de potentiële vector en het effect ervan op de vertrouwelijkheid, integriteit en beschikbaarheid (ook wel de CIA genoemd) van het systeem.
Wijs binnen de categorieën van de CIA een initieel ernstniveau toe dat de omvang van de schade en de urgentie van herstel aangeeft. Dit niveau zal naar verwachting in de loop der tijd veranderen naarmate er meer informatie wordt ontdekt in de triageniveaus.
In de ontdekkingsfase is het belangrijk om onmiddellijk een actieplan en communicatieplannen te bepalen. Zijn er wijzigingen in de actieve status van het systeem? Hoe kan de aanval worden ingeperkt om verdere uitbuiting te stoppen? Moet het team interne of externe communicatie versturen, zoals een verantwoorde openbaarmaking? Houd rekening met detectie- en responstijd. Het kan zijn dat u wettelijk verplicht bent om bepaalde soorten inbreuken binnen een bepaalde periode, vaak uren of dagen, te melden aan een regelgevende instantie.
Als u besluit het systeem af te sluiten, leiden de volgende stappen naar het noodherstelproces (DR) van de workload.
Als u het systeem niet afsluit, bepaal dan hoe u het incident kunt verhelpen zonder de functionaliteit van het systeem te beïnvloeden.
Herstellen van een incident
Behandel een beveiligingsincident als een ramp. Als een volledig herstel vereist is, gebruik dan de juiste DR-mechanismen vanuit een beveiligingsperspectief. Het herstelproces moet de kans op herhaling voorkomen. Anders zal het probleem opnieuw optreden bij herstel van een beschadigde back-up. Het opnieuw inzetten van een systeem met dezelfde kwetsbaarheid leidt tot hetzelfde incident. Valideer failover- en failback-stappen en -processen.
Als het systeem blijft functioneren, beoordeel dan het effect op de draaiende delen van het systeem. Blijf het systeem monitoren om ervoor te zorgen dat andere doelstellingen op het gebied van betrouwbaarheid en prestatie worden gehaald of aangepast door de juiste degradatieprocessen te implementeren. Breng de privacy niet in gevaar vanwege beperking.
Diagnose is een interactief proces totdat de vector, en een mogelijke oplossing en fallback, is geïdentificeerd. Na de diagnose werkt het team aan herstel, waarbij binnen een acceptabele termijn de benodigde oplossing wordt geïdentificeerd en toegepast.
Herstelstatistieken meten hoe lang het duurt om een probleem op te lossen. Bij een shutdown kan er sprake zijn van urgentie met betrekking tot de hersteltijden. Om het systeem te stabiliseren, kost het tijd om fixes, patches en tests toe te passen en updates te implementeren. Bepaal inperkingsstrategieën om verdere schade en de verspreiding van het incident te voorkomen. Ontwikkel verdelgingsprocedures om de dreiging uit de omgeving volledig te verwijderen.
Afweging: Er is een afweging tussen betrouwbaarheidsdoelen en hersteltijden. Tijdens een incident is de kans groot dat u niet aan andere niet-functionele of functionele eisen voldoet. Het kan bijvoorbeeld nodig zijn delen van uw systeem uit te schakelen terwijl u het incident onderzoekt, of misschien moet u zelfs het hele systeem offline halen totdat u de omvang van het incident hebt bepaald. Zakelijke besluitvormers moeten expliciet beslissen wat de acceptabele doelen zijn tijdens het incident. Geef duidelijk aan wie verantwoordelijk is voor die beslissing.
Lessen trekken uit een incident
Een incident legt gaten of kwetsbare punten in een ontwerp of implementatie bloot. Het is een kans voor verbetering die wordt aangestuurd door lessen in technische ontwerpaspecten, automatisering en productontwikkelingsprocessen, inclusief testen, en de effectiviteit van het incidentresponsproces. Houd gedetailleerde incidentregistraties bij, inclusief genomen acties, tijdlijnen en bevindingen.
We raden u ten zeerste aan gestructureerde beoordelingen na incidenten uit te voeren, zoals analyse van de hoofdoorzaak en terugblikken. Houd de uitkomsten van deze beoordelingen bij en prioriteer deze, en overweeg om wat u hebt geleerd te gebruiken in toekomstige workloadontwerpen.
Verbeterplannen moeten updates van beveiligingsoefeningen en -tests omvatten, zoals oefeningen voor bedrijfscontinuïteit en noodherstel (BCDR). Gebruik een beveiligingscompromis als scenario voor het uitvoeren van een BCDR-oefening. Drills kunnen valideren hoe de gedocumenteerde processen werken. Er mogen geen meerdere draaiboeken voor incidentrespons zijn. Gebruik één bron die u kunt aanpassen op basis van de omvang van het incident en hoe wijdverspreid of lokaal het effect is. Drills zijn gebaseerd op hypothetische situaties. Voer drills uit in een omgeving met een laag risico en neem de leerfase in de drills op.
Voer post-incidentbeoordelingen of nabeschouwingen uit om zwakke punten in het reactieproces en gebieden voor verbetering te identificeren. Op basis van de lessen die u uit het incident leert, werkt u het incidentresponsplan (IRP) en de beveiligingscontroles bij.
De nodige communicatie versturen
Implementeer een communicatieplan om gebruikers op de hoogte te stellen van een verstoring, en om interne belanghebbenden te informeren over het herstel en de verbeteringen. Andere mensen in uw organisatie moeten op de hoogte worden gesteld van eventuele wijzigingen in de beveiligingsbasislijn van de workload om toekomstige incidenten te voorkomen.
Genereer incidentrapporten voor intern gebruik en, indien nodig, voor naleving van de regelgeving of juridische doeleinden. Gebruik ook een rapport in standaardformaat (een documentsjabloon met gedefinieerde secties) dat het SOC-team voor alle incidenten gebruikt. Zorg ervoor dat aan elk incident een rapport is gekoppeld voordat u het onderzoek afsluit.
Power Platform-facilitering
In de volgende secties worden de mechanismen beschreven die u kunt gebruiken als onderdeel van uw responsprocedures voor beveiligingsincidenten.
Microsoft Sentinel
Met de Microsoft Sentinel-oplossing voor Microsoft Power Platform kunnen klanten verschillende verdachte activiteiten detecteren, waaronder:
- Power Apps-uitvoerbewerking vanuit ongeautoriseerde geografische gebieden
- Verdachte gegevensvernietiging door Power Apps
- Massale verwijdering van Power Apps
- Phishing-aanvallen die via Power Apps worden uitgevoerd
- Power Automate stroomt activiteit op vertrekkende werknemers
- Microsoft Power Platform-connectors die aan een omgeving zijn toegevoegd
- Bijwerken of verwijderen van Microsoft Power Platform-beleid ter voorkoming van gegevensverlies
Voor meer informatie raadpleegt u Overzicht Microsoft Sentinel-oplossing voor Microsoft Power Platform.
Microsoft Purview-activiteitenregistratie
Power Apps-, Power Automate-, Connectors-, Data Loss Prevention- en Power Platform-activiteitenregistratie worden bijgehouden en bekeken vanuit de Microsoft Purview-complianceportal.
Zie voor meer informatie:
- Power Apps activiteitenregistratie
- Power Automate activiteitenregistratie
- Copilot Studio activiteitenregistratie
- Power Pages activiteitenregistratie
- Power Platform connectoractiviteit loggen
- Gegevens verliespreventie activiteitenregistratie
- Power Platform administratieve acties activiteitenregistratie
- Microsoft Dataverse en modelgestuurde apps activiteitenregistratie
Klanten-lockbox
Voor de meeste bewerkingen, ondersteuning en probleemoplossing die worden uitgevoerd door Microsoft-personeel (inclusief subverwerkers) is geen toegang tot klantgegevens vereist. Met Power Platform Klanten-lockbox biedt Microsoft een interface voor de klanten voor het beoordelen en goedkeuren (of afwijzen) van gegevenstoegang in het zeldzame geval dat gegevenstoegang tot klantgegevens nodig is. Het wordt gebruikt in gevallen waarin een Microsoft-technicus toegang nodig heeft tot klantgegevens, of dit nu is als reactie op een door de klant geïnitieerd ondersteuningsticket of een door Microsoft vastgesteld probleem. Zie Veilig toegang krijgen tot klantgegevens met behulp van Klanten-lockbox in Power Platform en Dynamics 365 voor meer informatie.
Beveiligingsupdates
De serviceteams voeren regelmatig het volgende uit om de beveiliging van het systeem te waarborgen:
- Scans van de service om mogelijke zwakke plekken in de beveiliging te detecteren.
- Beoordeling van de service om te garanderen dat essentiële veiligheidscontroles doeltreffend werken.
- Evaluaties van de service om blootstelling van kwetsbare plekken die zijn geïdentificeerd door het Microsoft Security Response Center (MSRC) te bepalen. Het MSRC monitort regelmatig externe sites met betrekking tot kwetsbaarheden op het gebied van beveiliging.
Deze teams identificeren en volgen ook vastgestelde problemen en ondernemen zo nodig direct actie om de risico's te beperken.
Hoe krijg ik informatie over beveiligingsupdates?
Omdat de Serviceteams ernaar steven gevaren te beperken zonder dat dit leidt tot downtime, zien beheerders meestal geen meldingen van het berichtencentrum over beveiligingsupdates. Als een beveiligingsupdate een impact op de service heeft, wordt dit beschouwd als gepland onderhoud en wordt het gemeld met de geschatte impactduur en het tijdsvenster waarbinnen het werk plaatsvindt.
Zie het Microsoft-vertrouwenscentrum voor meer informatie over beveiliging.
Uw onderhoudsvenster beheren
Microsoft voert regelmatig updates en onderhoud uit om de veiligheid, prestaties en beschikbaarheid te garanderen, en om nieuwe functies en functionaliteit te bieden. Dit updateproces levert wekelijks beveiligings- en kleine serviceverbeteringen, waarbij elke update regio per regio wordt uitgerold volgens een veilig implementatieschema, gerangschikt in Stations. Zie voor informatie over uw standaard onderhoudstijdvak voor omgevingen Beleid en communicatie voor service-incidenten. Zie ook Uw onderhoudsvenster beheren.
Zorg ervoor dat de Azure-inschrijvingsportal de contactgegevens van de beheerder bevat, zodat beveiligingsbewerkingen rechtstreeks via een intern proces kunnen worden gemeld. Zie Meldingsinstellingen bijwerken voor meer informatie.
Organisatorische afstemming
Cloud Adoption Framework voor Azure biedt richtlijnen voor de planning van incidentrespons en beveiligingsactiviteiten. Zie Beveiligingsbewerkingen voor meer informatie.
Gerelateerde informatie
- Microsoft Sentinel-oplossing voor Microsoft Power Platform overzicht
- Automatisch incidenten aanmaken vanuit Microsoft beveiligingswaarschuwingen
- Voer end-to-end-dreigingsjacht uit met behulp van de Hunts-functie
- gebruik Hunts om end-to-end proactieve bedreigingsjacht uit te voeren in Microsoft Sentinel
- Overzicht incident respons
Controlelijst voor beveiliging
Raadpleeg de volledige reeks aanbevelingen.