Zelfstudie: Relaties ontdekken in een semantisch model met behulp van een semantische koppeling
In deze zelfstudie ziet u hoe u met Power BI communiceert vanuit een Jupyter-notebook en relaties tussen tabellen detecteert met behulp van de SemPy-bibliotheek.
In deze zelfstudie leert u het volgende:
- Relaties ontdekken in een semantisch model (Power BI-gegevensset), met behulp van de Python-bibliotheek van semantische koppelingen (SemPy).
- Gebruik onderdelen van SemPy die ondersteuning bieden voor integratie met Power BI en helpen bij het automatiseren van analyse van gegevenskwaliteit. Deze onderdelen zijn onder andere:
- FabricDataFrame- een pandas-achtige structuur die is uitgebreid met aanvullende semantische informatie.
- Functies voor het ophalen van semantische modellen uit een Fabric-werkruimte in uw notebook.
- Functies die de evaluatie van hypothesen over functionele afhankelijkheden automatiseren en waarmee schendingen van relaties in uw semantische modellen worden geïdentificeerd.
Voorwaarden
Een Microsoft Fabric-abonnementophalen. Of meld u aan voor een gratis microsoft Fabric-proefversie.
Meld u aan bij Microsoft Fabric-.
Gebruik de ervaringswisselaar aan de linkerkant van de startpagina om over te schakelen naar Fabric.

Selecteer Werkruimten in het linkernavigatiedeelvenster om uw werkruimte te zoeken en te selecteren. Deze werkruimte wordt uw huidige werkruimte.
Download de semantische modelbestanden Customer Profitability Sample.pbix en Customer Profitability Sample (auto).pbix van de GitHub-opslagplaats fabric-samples en upload deze naar uw werkruimte.
Volg mee in het notitieblok
De notebook powerbi_relationships_tutorial.ipynb begeleidt deze zelfstudie.
Als u het bijbehorende notitieblok voor deze zelfstudie wilt openen, volgt u de instructies in Uw systeem voorbereiden op zelfstudies voor gegevenswetenschap om het notebook in uw werkruimte te importeren.
Als u liever de code van deze pagina kopieert en plakt, kunt u een nieuw notitieblok maken.
Zorg ervoor dat u een lakehouse aan het notebook koppelt voordat u begint met het uitvoeren van code.
Het notebook instellen
In deze sectie stelt u een notebookomgeving in met de benodigde modules en gegevens.
Installeer
SemPyvanuit PyPI met behulp van de%pipinline-installatiemogelijkheid in het notebook:%pip install semantic-linkVoer de benodigde importbewerkingen uit van SemPy-modules die u later nodig hebt:
import sempy.fabric as fabric from sempy.relationships import plot_relationship_metadata from sempy.relationships import find_relationships from sempy.fabric import list_relationship_violationsImporteer pandas voor het afdwingen van een configuratieoptie die helpt bij het opmaken van uitvoer:
import pandas as pd pd.set_option('display.max_colwidth', None)
Semantische modellen verkennen
In deze handleiding wordt gebruikgemaakt van een standaard semantisch voorbeeldmodel Customer Profitability Sample.pbix. Zie voorbeeld van klantwinstgevendheid voor Power BIvoor een beschrijving van het semantische model.
Gebruik de functie
list_datasetsvan SemPy om semantische modellen in uw huidige werkruimte te verkennen:fabric.list_datasets()
Voor de rest van dit notitieboekje gebruik je twee versies van het semantische model "Customer Profitability Sample".
- voorbeeld van klantwinstgevendheid: het semantische model dat afkomstig is van Power BI-voorbeelden met vooraf gedefinieerde tabelrelaties
- Voorbeeld van klantwinstgevendheid (automatisch): dezelfde gegevens, maar relaties zijn beperkt tot de gegevens die door Power BI automatisch worden gedetecteerd.
Een semantisch voorbeeldmodel extraheren met het vooraf gedefinieerde semantische model
Laad de relaties die vooraf zijn gedefinieerd en opgeslagen binnen het Customer Profitability Sample semantisch model, met behulp van de functie van SemPy
list_relationships. Deze functie bevat een overzicht van het tabellaire objectmodel:dataset = "Customer Profitability Sample" relationships = fabric.list_relationships(dataset) relationshipsVisualiseer het
relationshipsDataFrame als een grafiek met behulp van deplot_relationship_metadatafunctie van SemPy:plot_relationship_metadata(relationships)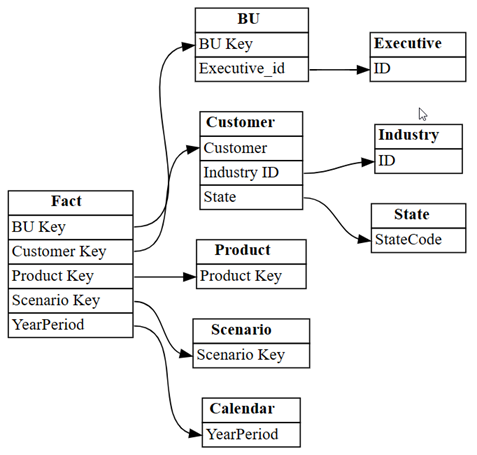

In deze grafiek ziet u de 'grondwaar' voor relaties tussen tabellen in dit semantische model, omdat deze weerspiegelen hoe ze zijn gedefinieerd in Power BI door een expert op het gebied van onderwerp.
Ontdekking van aanvullende relaties
Als u bent begonnen met relaties die automatisch door Power BI zijn gedetecteerd, hebt u een kleinere set.
Visualiseer de relaties die automatisch door Power BI zijn gedetecteerd in het semantische model:
dataset = "Customer Profitability Sample (auto)" autodetected = fabric.list_relationships(dataset) plot_relationship_metadata(autodetected)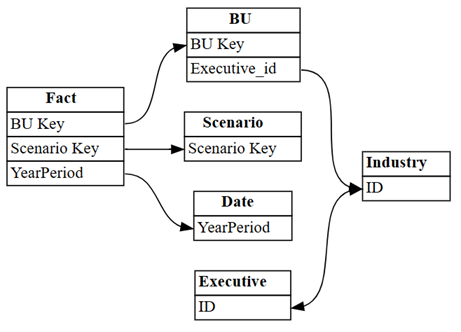
De automatische detectie van Power BI heeft veel relaties niet herkend. Bovendien zijn twee van de automatisch gedetecteerde relaties semantisch onjuist:
-
Executive[ID]->Industry[ID] -
BU[Executive_id]->Industry[ID]
-
De relaties afdrukken als een tabel:
autodetectedOnjuiste relaties met de
Industrytabel worden weergegeven in rijen met index 3 en 4. Gebruik deze informatie om deze rijen te verwijderen.Negeer de onjuist geïdentificeerde relaties.
autodetected.drop(index=[3,4], inplace=True) autodetectedU hebt nu de juiste, maar onvolledige relaties.
Visualiseer deze onvolledige relaties met behulp van
plot_relationship_metadata:plot_relationship_metadata(autodetected)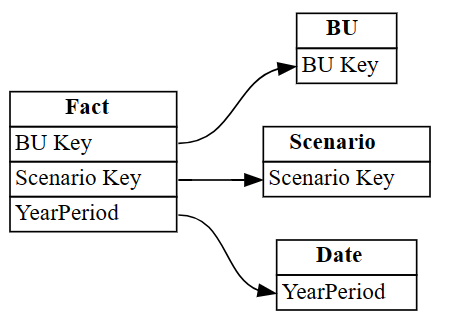
Laad alle tabellen uit het semantische model met behulp van de functies van SemPy
list_tablesenread_table:tables = {table: fabric.read_table(dataset, table) for table in fabric.list_tables(dataset)['Name']} tables.keys()Zoek relaties tussen tabellen met behulp van
find_relationshipsen bekijk de logboekuitvoer om inzicht te krijgen in de werking van deze functie:suggested_relationships_all = find_relationships( tables, name_similarity_threshold=0.7, coverage_threshold=0.7, verbose=2 )Nieuw gedetecteerde relaties visualiseren:
plot_relationship_metadata(suggested_relationships_all)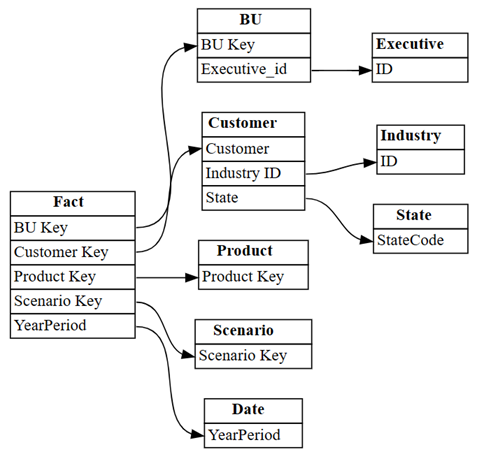
SemPy kon alle relaties detecteren.
Gebruik de parameter
excludeom de zoekopdracht te beperken tot aanvullende relaties die niet eerder zijn geïdentificeerd:additional_relationships = find_relationships( tables, exclude=autodetected, name_similarity_threshold=0.7, coverage_threshold=0.7 ) additional_relationships



De relaties valideren
Laad eerst de gegevens uit het Voorbeeld van klantwinstgevendheid semantisch model:
dataset = "Customer Profitability Sample" tables = {table: fabric.read_table(dataset, table) for table in fabric.list_tables(dataset)['Name']} tables.keys()Controleer op overlapping van primaire en vreemde sleutelwaarden met behulp van de functie
list_relationship_violations. Geef de uitvoer van delist_relationshipsfunctie op als invoer voorlist_relationship_violations:list_relationship_violations(tables, fabric.list_relationships(dataset))De relatieschendingen bieden enkele interessante inzichten. Een van de zeven waarden in
Fact[Product Key]is bijvoorbeeld niet aanwezig inProduct[Product Key]en deze ontbrekende sleutel is50.
Verkennende gegevensanalyse is een spannend proces, en dat geldt ook voor het opschonen van gegevens. Er is altijd iets dat de gegevens verbergen, afhankelijk van hoe u deze bekijkt, wat u wilt vragen, enzovoort. Semantische koppeling biedt u nieuwe hulpprogramma's die u kunt gebruiken om meer te bereiken met uw gegevens.
Verwante inhoud
Bekijk andere handleidingen voor semantische koppeling / SemPy:
- Zelfstudie: Gegevens opschonen met functionele afhankelijkheden
- Zelfstudie: Functionele afhankelijkheden analyseren in een semantisch voorbeeldmodel
- Zelfstudie: Power BI-metingen extraheren en berekenen uit een Jupyter-notebook
- Zelfstudie: Relaties ontdekken in de Synthea--gegevensset met behulp van semantische koppeling
- Zelfstudie: Gegevens valideren met behulp van SemPy en Great Expectations (GX)