End-to-endscenario van Lakehouse: overzicht en architectuur
Microsoft Fabric is een alles-in-één analyseoplossing voor ondernemingen die alles omvat, van gegevensverplaatsing tot gegevenswetenschap, realtime analyses en business intelligence. Het biedt een uitgebreide suite met services, waaronder data lake, data engineering en gegevensintegratie, allemaal op één plek. Zie Wat is Microsoft Fabric voor meer informatie?
Deze zelfstudie begeleidt u door een end-to-end scenario van gegevensverwerving tot gegevensverbruik. Het helpt u een basiskennis van Fabric op te bouwen, waaronder de verschillende ervaringen en hoe ze integreren, evenals de professionele en burgerontwikkelaarservaringen die worden geleverd met het werken op dit platform. Deze zelfstudie is niet bedoeld als referentiearchitectuur, een uitgebreide lijst met functies en functionaliteit of een aanbeveling voor specifieke aanbevolen procedures.
End-to-endscenario van Lakehouse
Traditioneel bouwen organisaties moderne datawarehouses voor hun transactionele en gestructureerde gegevensanalysebehoeften. En data lakehouses voor big data (semi-/ongestructureerde) gegevensanalysebehoeften. Deze twee systemen werden parallel uitgevoerd, waardoor silo's, gegevensduplicatie werden gemaakt en de totale eigendomskosten werden verhoogd.
Fabric met een eenwording van gegevensopslag en standaardisatie in Delta Lake-indeling maakt het mogelijk om silo's te elimineren, gegevensduplicatie te verwijderen en de totale eigendomskosten drastisch te verlagen.
Met de flexibiliteit van Fabric kunt u lakehouse- of datawarehouse-architecturen implementeren of deze combineren om het beste van beide te krijgen met eenvoudige implementatie. In deze zelfstudie gaat u een voorbeeld nemen van een retailorganisatie en het lakehouse van begin tot eind bouwen. Hierbij wordt gebruikgemaakt van de medaille-architectuur waarbij de bronslaag de onbewerkte gegevens bevat, de zilveren laag de gevalideerde en ontdubbelde gegevens bevat en de gouden laag zeer verfijnde gegevens bevat. U kunt dezelfde benadering gebruiken om een lakehouse te implementeren voor elke organisatie vanuit elke branche.
In deze zelfstudie wordt uitgelegd hoe een ontwikkelaar van het fictieve Wide World Importers-bedrijf vanuit het retaildomein de volgende stappen uitvoert:
Meld u aan bij uw Power BI-account en meld u aan voor de gratis proefversie van Microsoft Fabric. Als u geen Power BI-licentie hebt, meld u zich aan voor een gratis Fabric-licentie zodat u de proefversie van Fabric kunt starten.
Bouw en implementeer een end-to-end lakehouse voor uw organisatie:
- Maak een Fabric-werkruimte.
- Maak een lakehouse.
- Gegevens opnemen, gegevens transformeren en laden in lakehouse. U kunt ook OneLake verkennen, één kopie van uw gegevens in de lakehouse-modus en de eindpuntmodus van SQL Analytics.
- Maak verbinding met uw lakehouse met behulp van het SQL-analyse-eindpunt en maak een Power BI-rapport met behulp van DirectLake om verkoopgegevens in verschillende dimensies te analyseren.
- U kunt desgewenst gegevensopname en transformatiestroom organiseren en plannen met een pijplijn.
Schoon resources op door de werkruimte en andere items te verwijderen.
Architectuur
In de volgende afbeelding ziet u de end-to-end-architectuur van Lakehouse. De betrokken onderdelen worden beschreven in de volgende lijst.
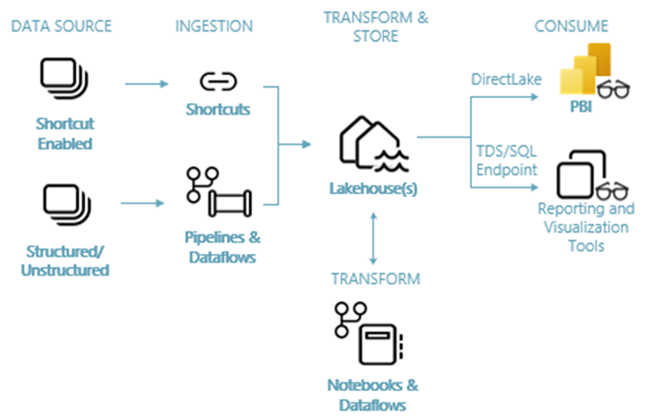
Gegevensbronnen: Met Fabric kunt u snel en eenvoudig verbinding maken met Azure Data Services, evenals andere cloudplatforms en on-premises gegevensbronnen, voor gestroomlijnde gegevensopname.
Opname: U kunt snel inzichten bouwen voor uw organisatie met meer dan 200 systeemeigen connectors. Deze connectors zijn geïntegreerd in de Infrastructuurpijplijn en maken gebruik van de gebruiksvriendelijke gegevenstransformatie voor slepen en neerzetten met gegevensstroom. Daarnaast kunt u met de functie Snelkoppeling in Fabric verbinding maken met bestaande gegevens, zonder deze te hoeven kopiëren of verplaatsen.
Transformeren en opslaan: Fabric standaardiseert in Delta Lake-indeling. Dit betekent dat alle Fabric-engines toegang hebben tot en bewerken van dezelfde gegevensset die is opgeslagen in OneLake zonder gegevens te dupliceren. Dit opslagsysteem biedt de flexibiliteit om lakehouses te bouwen met behulp van een medalsight-architectuur of een data mesh, afhankelijk van uw organisatievereiste. U kunt kiezen tussen een ervaring met weinig code of geen code voor gegevenstransformatie, waarbij u pijplijnen/gegevensstromen of notebook/Spark gebruikt voor een code-first-ervaring.
Verbruik: Power BI kan gegevens uit Lakehouse gebruiken voor rapportage en visualisatie. Elk Lakehouse heeft een ingebouwd TDS-eindpunt dat het SQL-analyse-eindpunt wordt genoemd voor eenvoudige connectiviteit en het opvragen van gegevens in de Lakehouse-tabellen vanuit andere rapportagehulpprogramma's. Het EINDPUNT van SQL Analytics biedt gebruikers de functionaliteit van de SQL-verbinding.
Voorbeeldgegevensset
In deze zelfstudie wordt gebruikgemaakt van de WWI-voorbeelddatabase (Wide World Importers), die u in de volgende zelfstudie gaat importeren in het lakehouse. Voor het end-to-endscenario van Lakehouse hebben we voldoende gegevens gegenereerd om de schaal- en prestatiemogelijkheden van het Fabric-platform te verkennen.
Wide World Importers (WWI) is een groothandel nieuwe goederenimporteur en distributeur die werkt vanuit de regio San Francisco Bay. Als groothandel omvatten WWI's klanten meestal bedrijven die verkopen aan particulieren. WWI verkoopt aan retailklanten in de Verenigde Staten waaronder speciaalzaken, supermarkten, rekenwinkels, toeristische attractiewinkels en sommige personen. WWI verkoopt ook aan andere groothandels via een netwerk van agenten die de producten namens WWI promoten. Zie Wide World Importers-voorbeelddatabases voor Microsoft SQL voor meer informatie over hun bedrijfsprofiel en -werking.
Over het algemeen worden gegevens afkomstig van transactionele systemen of line-of-business-toepassingen in een lakehouse. Voor het gemak in deze zelfstudie gebruiken we echter het dimensionale model dat door WWI wordt geleverd als onze initiële gegevensbron. We gebruiken deze als bron om de gegevens op te nemen in een lakehouse en deze te transformeren door verschillende fasen (Brons, Zilver en Goud) van een medaille-architectuur.
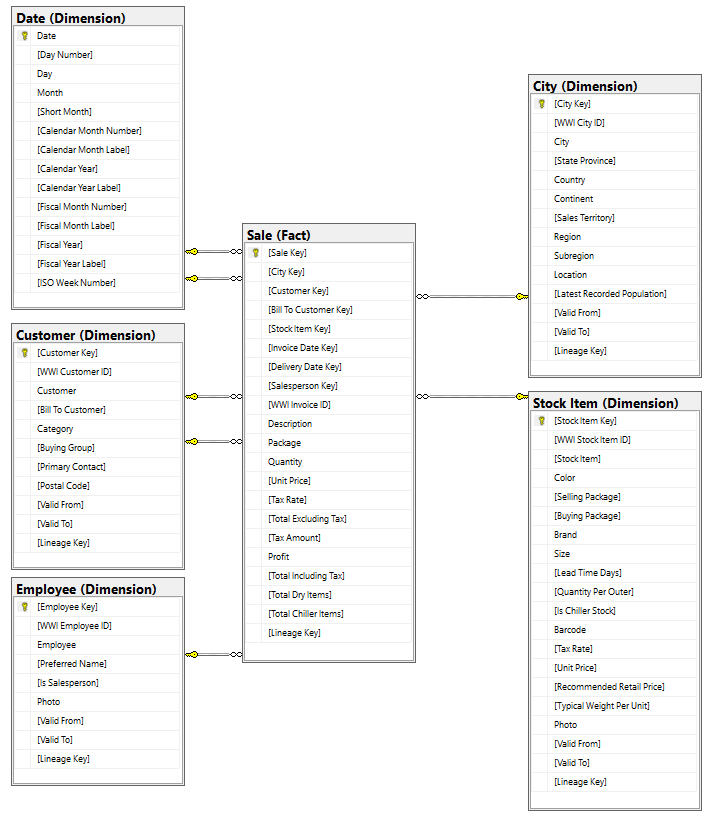
Gegevensmodel
Hoewel het WWI-dimensionale model talloze feitentabellen bevat, gebruiken we voor deze zelfstudie de feitentabel Sale en de gecorreleerde dimensies. In het volgende voorbeeld ziet u het WWI-gegevensmodel:
Gegevens- en transformatiestroom
Zoals eerder beschreven, gebruiken we de voorbeeldgegevens uit WWI-voorbeeldgegevens (Wide World Importers) om dit end-to-end lakehouse te bouwen. In deze implementatie worden de voorbeeldgegevens opgeslagen in een Azure Data Storage-account in Parquet-bestandsindeling voor alle tabellen. In praktijkscenario's zijn gegevens echter meestal afkomstig uit verschillende bronnen en in diverse indelingen.
In de volgende afbeelding ziet u de bron-, doel- en gegevenstransformatie:
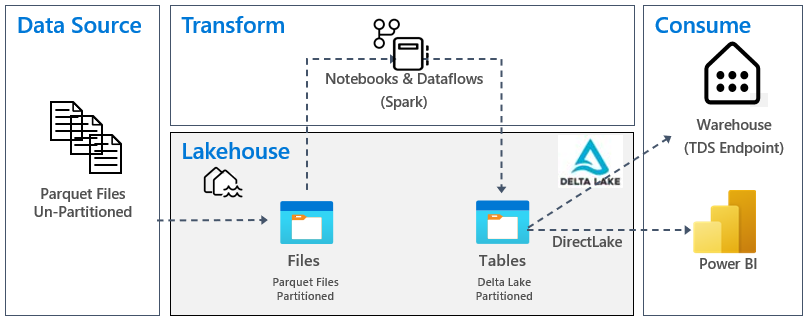
Gegevensbron: de brongegevens hebben de Parquet-bestandsindeling en hebben een niet-gepartitioneerde structuur. Het wordt opgeslagen in een map voor elke tabel. In deze zelfstudie hebben we een pijplijn ingesteld voor het opnemen van de volledige historische of eenmalige gegevens naar het lakehouse.
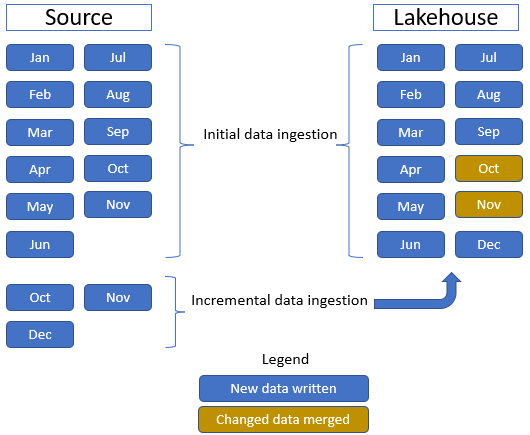
In deze zelfstudie gebruiken we de feitentabel Sale , met één bovenliggende map met historische gegevens voor 11 maanden (met één submap voor elke maand) en een andere map met incrementele gegevens voor drie maanden (één submap voor elke maand). Tijdens de initiële gegevensopname worden 11 maanden aan gegevens opgenomen in de lakehouse-tabel. Wanneer de incrementele gegevens echter binnenkomen, bevatten deze bijgewerkte gegevens voor oct en nov, en nieuwe gegevens voor dec.oct- en novgegevens worden samengevoegd met de bestaande gegevens en worden de nieuwe dec-gegevens naar de lakehouse-tabel geschreven, zoals wordt weergegeven in de volgende afbeelding:
Lakehouse: In deze zelfstudie maakt u een lakehouse, neemt u gegevens op in de bestandensectie van het lakehouse en maakt u vervolgens Delta Lake-tabellen in de sectie Tabellen van het lakehouse.
Transformatie: Voor gegevensvoorbereiding en -transformatie ziet u twee verschillende benaderingen. We demonstreren het gebruik van Notebooks/Spark voor gebruikers die de voorkeur geven aan een code-first-ervaring en pijplijnen/gegevensstroom gebruiken voor gebruikers die de voorkeur geven aan een ervaring met weinig code of geen code.
Verbruik: Als u het gegevensverbruik wilt demonstreren, ziet u hoe u de DirectLake-functie van Power BI kunt gebruiken om rapporten, dashboards te maken en rechtstreeks query's uit te voeren op gegevens uit lakehouse. Daarnaast laten we zien hoe u uw gegevens beschikbaar kunt maken voor rapportagehulpprogramma's van derden met behulp van het TDS-/SQL-analyse-eindpunt. Met dit eindpunt kunt u verbinding maken met het magazijn en SQL-query's uitvoeren voor analyse.