Wat is de architectuur van medallion lakehouse?
In de medallayer-architectuur wordt een reeks gegevenslagen beschreven die duiden op de kwaliteit van gegevens die zijn opgeslagen in het lakehouse. Azure Databricks raadt u aan een aanpak met meerdere lagen te gebruiken voor het bouwen van één bron van waarheid voor zakelijke gegevensproducten.
Deze architectuur garandeert atomiciteit, consistentie, isolatie en duurzaamheid wanneer gegevens meerdere lagen validaties en transformaties doorlopen voordat ze worden opgeslagen in een indeling die is geoptimaliseerd voor efficiënte analyses. De termen brons (onbewerkt), zilver (gevalideerd) en goud (verrijkt) beschrijven de kwaliteit van de gegevens in elk van deze lagen.
Medaille-architectuur als een gegevensontwerppatroon
Een medaillonarchitectuur is een gegevensontwerppatroon dat wordt gebruikt om gegevens logisch te ordenen. Het doel is om de structuur en kwaliteit van gegevens stapsgewijs te verbeteren terwijl deze door elke laag van de architectuur loopt (van Bronze ⇒ Silver ⇒ Gold-laagtabellen). Medalillon architecturen worden soms ook wel multihop architecturen genoemd.
Door gegevens door deze lagen te doorlopen, kunnen organisaties de gegevenskwaliteit en betrouwbaarheid incrementeel verbeteren, waardoor deze beter geschikt zijn voor business intelligence- en machine learning-toepassingen.
Het volgen van de medallion-architectuur is een aanbevolen beste praktijk, maar geen vereiste.
| Vraag | Brons | Zilver | Goud |
|---|---|---|---|
| Wat gebeurt er in deze laag? | Onbewerkte gegevensopname | Gegevens opschonen en valideren | Dimensionaal modelleren en aggregeren |
| Wie is de beoogde gebruiker? |
|
|
|
Voorbeeld van medaillonarchitectuur
In dit voorbeeld van een medaille-architectuur ziet u brons-, zilver- en gouden lagen voor gebruik door een business operations-team. Elke laag wordt opgeslagen in een ander schema van de ops-catalogus.
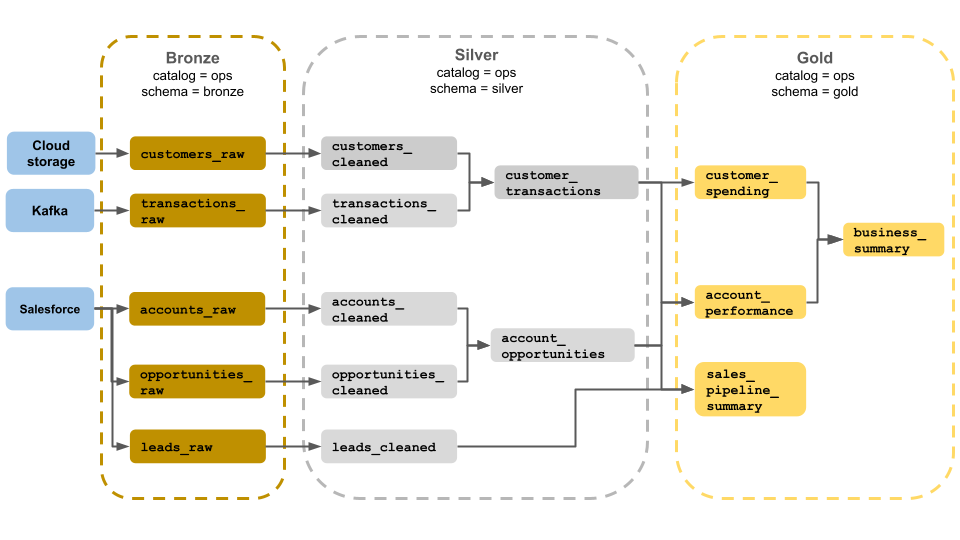
-
Bronslaag (
ops.bronze): neemt onbewerkte gegevens op uit cloudopslag, Kafka en Salesforce. Er wordt hier geen gegevensopruiming of validatie uitgevoerd. -
Silver Layer (
ops.silver): Gegevensopschoning en -validatie worden uitgevoerd in deze laag.- Gegevens over klanten en transacties worden opgeschoond door null-waarden te verwijderen en ongeldige records te quarantieren. Deze gegevenssets worden toegevoegd aan een nieuwe gegevensset met de naam
customer_transactions. Gegevenswetenschappers kunnen deze gegevensset gebruiken voor predictive analytics. - Evenzo worden accounts en verkoopkansdatasets uit Salesforce samengevoegd om
account_opportunitieste creëren, dat wordt verbeterd met accountinformatie. - De
leads_rawgegevens worden opgeschoond in een gegevensset met de naamleads_cleaned.
- Gegevens over klanten en transacties worden opgeschoond door null-waarden te verwijderen en ongeldige records te quarantieren. Deze gegevenssets worden toegevoegd aan een nieuwe gegevensset met de naam
-
Gouden laag (
ops.gold): Deze laag is ontworpen voor zakelijke gebruikers. Het bevat minder gegevenssets dan zilver en goud.-
customer_spending: Gemiddelde en totale uitgaven voor elke klant. -
account_performance: Dagelijkse prestaties voor elk account. -
sales_pipeline_summary: Informatie over het volledige verkooptraject. -
business_summary: Zeer geaggregeerde informatie voor het leidinggevend personeel.
-
Onbewerkte gegevens opnemen in de bronslaag
De bronslaag bevat onbewerkte, niet-gevalideerde gegevens. Gegevens die in de bronslaag worden opgenomen, hebben doorgaans de volgende kenmerken:
- Bevat en onderhoudt de ruwe vorm van de gegevensbron in de oorspronkelijke formaten.
- Wordt incrementeel toegevoegd en groeit in de loop van de tijd.
- Bedoeld voor gebruik door workloads die gegevens verrijken voor zilvertabellen, en niet voor toegang door analisten en gegevenswetenschappers.
- Fungeert als de enige bron van waarheid, waarbij de betrouwbaarheid van de gegevens behouden blijft.
- Hiermee schakelt u herverwerking en controle in door alle historische gegevens te behouden.
- Kan elke combinatie zijn van streaming- en batchtransacties uit bronnen, waaronder cloudobjectopslag (bijvoorbeeld S3, GCS, ADLS), berichtbussen (bijvoorbeeld Kafka, Kinesis, enzovoort) en federatieve systemen (bijvoorbeeld Lakehouse Federation).
Gegevens opschonen of valideren beperken
Minimale gegevensvalidatie wordt uitgevoerd in de bronslaag. Om te voorkomen dat gegevens verloren gaan, raadt Azure Databricks aan om de meeste velden op te slaan als tekenreeks, VARIANT of binair, ter bescherming tegen onverwachte schemawijzigingen. Metagegevenskolommen kunnen worden toegevoegd, zoals de herkomst of bron van de gegevens (bijvoorbeeld _metadata.file_name ).
Gegevens valideren en ontdubbelen in de zilveren laag
Gegevens opschonen en valideren worden uitgevoerd in de zilveren laag.
Zilveren tabellen bouwen van de bronslaag
Als u de zilveren laag wilt bouwen, leest u gegevens uit een of meer bronzen of zilveren tabellen en schrijft u gegevens naar zilveren tabellen.
Azure Databricks raadt niet aan om rechtstreeks vanuit data-invoer in zilveren tabellen te schrijven. Als u rechtstreeks vanuit opname schrijft, introduceert u fouten vanwege schemawijzigingen of beschadigde records in gegevensbronnen. Uitgaande van de veronderstelling dat alle bronnen alleen toegevoegde gegevens bevatten, configureert u de meeste lezingen van de bronslaag als streaming-lezingen. Batchlezen moet worden voorbehouden aan kleine gegevenssets (bijvoorbeeld kleine dimensionale tabellen).
De zilveren laag vertegenwoordigt gevalideerde, opgeschoonde en verrijkte versies van de gegevens. De zilveren laag:
- Moet altijd ten minste één gevalideerde, niet-geaggregeerde weergave van elke record bevatten. Als geaggregeerde representaties veel downstreamworkloads stimuleren, bevinden deze representaties zich mogelijk in de zilveren laag, maar meestal in de gouden laag.
- Is waar u gegevens opschonen, ontdubbelen en normaliseren uitvoert.
- Verbetert de gegevenskwaliteit door fouten en inconsistenties te corrigeren.
- Structureert gegevens in een bruikbaar formaat voor verwerking stroomafwaarts.
Gegevenskwaliteit afdwingen
De volgende bewerkingen worden uitgevoerd in zilveren tabellen:
- Afdwingen van schema
- Verwerking van null- en ontbrekende waarden
- Gegevensontdubbeling
- Oplossing van problemen met niet op volgorde en laat binnenkomende gegevens.
- Controles en afdwinging van gegevenskwaliteit
- Ontwikkeling van schema's
- Type-conversie
- Samenvoegingen
Modelleringsgegevens starten
Het is gebruikelijk om gegevensmodellering uit te voeren in de zilveren laag, waaronder het kiezen van hoe sterk geneste of semi-gestructureerde gegevens te vertegenwoordigen.
- Gegevenstype gebruiken
VARIANT. - Gebruik
JSONtekenreeksen. - Maak structs, kaarten en matrices.
- Vereenvoudig het schema of normaliseer de gegevens in meerdere tabellen.
Power Analytics met de gouden laag
De gouden laag vertegenwoordigt uiterst verfijnde weergaven van de gegevens die downstreamanalyse, dashboards, ML en toepassingen stimuleren. Goudlaaggegevens worden vaak sterk geaggregeerd en gefilterd op specifieke perioden of geografische regio's. Het bevat semantisch zinvolle gegevenssets die zijn toegewezen aan bedrijfsfuncties en -behoeften.
De gouden laag:
- Bestaat uit geaggregeerde gegevens die zijn afgestemd op analyse en rapportage.
- Is afgestemd op bedrijfslogica en -vereisten.
- Is geoptimaliseerd voor prestaties in query's en dashboards.
Afstemmen op bedrijfslogica en vereisten
In de gouden laag gaat u uw gegevens modelleren voor rapportage en analyses met behulp van een dimensional model door relaties tot stand te brengen en metingen te definiëren. Analisten met toegang tot gegevens in goud moeten domeinspecifieke gegevens kunnen vinden en vragen kunnen beantwoorden.
Omdat de gouden laag een bedrijfsdomein modelleert, maken sommige klanten meerdere gouden lagen om te voldoen aan verschillende zakelijke behoeften, zoals HR, financiën en IT.
Aggregaties maken die zijn afgestemd op analyse en rapportage
Organisaties moeten vaak statistische functies maken voor metingen zoals gemiddelden, aantallen, maximumwaarden en minimumwaarden. Als uw bedrijf bijvoorbeeld vragen moet beantwoorden over de totale wekelijkse verkoop, kunt u een gerealiseerde weergave weekly_sales maken die deze gegevens vooraf samenvoegt, zodat analisten en anderen veelgebruikte gerealiseerde weergaven niet opnieuw hoeven te maken.
CREATE OR REPLACE MATERIALIZED VIEW weekly_sales AS
SELECT week,
prod_id,
region,
SUM(units) AS total_units,
SUM(units * rate) AS total_sales
FROM orders
GROUP BY week, prod_id, region
Optimaliseren voor prestaties in query's en dashboards
Het optimaliseren van tabellen met gouden lagen voor prestaties is een best practice omdat deze gegevenssets vaak worden opgevraagd. Grote hoeveelheden historische gegevens worden doorgaans toegankelijk gemaakt in de sliver-laag en niet gematerialiseerd in de goudlaag.
Kosten beheren door de frequentie van gegevensopname aan te passen
Beheer de kosten door te bepalen hoe vaak gegevens moeten worden opgenomen.
| Frequentie van gegevensopname | Kosten | Latentie | Declaratieve voorbeelden | Procedurele voorbeelden |
|---|---|---|---|---|
| Voortdurende incrementele opname | Hoger | Lager |
|
|
| Geactiveerde incrementele gegevensinvoer | Lager | Hoger |
|
|
| Batchverwerking met handmatige incrementele gegevensinvoer | Lager | De hoogste, vanwege sporadische uitvoeringen. |
|