De Livy-API gebruiken om sessietaken te verzenden en uit te voeren
Notitie
De Livy-API voor Fabric Data-engineer ing is in preview.
Van toepassing op:✅ Data-engineer ing en Datawetenschap in Microsoft Fabric
Verzend Spark-batchtaken met behulp van de Livy-API voor Fabric Data-engineer ing.
Vereisten
Fabric Premium - of proefcapaciteit met een Lakehouse.
Een externe client zoals Visual Studio Code met Jupyter Notebooks, PySpark en de Microsoft Authentication Library (MSAL) voor Python.
Er is een Microsoft Entra-app-token vereist voor toegang tot de Fabric Rest API. Registreer een toepassing bij het Microsoft Identity Platform.
Sommige gegevens in uw lakehouse, in dit voorbeeld worden NYC Taxi & Limousine Commission green_tripdata_2022_08 een parquet-bestand geladen in het lakehouse.
De Livy-API definieert een uniform eindpunt voor bewerkingen. Vervang de tijdelijke aanduidingen {Entra_TenantID}, {Entra_ClientID}, {Fabric_WorkspaceID} en {Fabric_LakehouseID} door de juiste waarden wanneer u de voorbeelden in dit artikel volgt.
Visual Studio Code configureren voor uw Livy API-sessie
Selecteer Lakehouse-instellingen in uw Fabric Lakehouse.

Navigeer naar de sectie Livy-eindpunt .
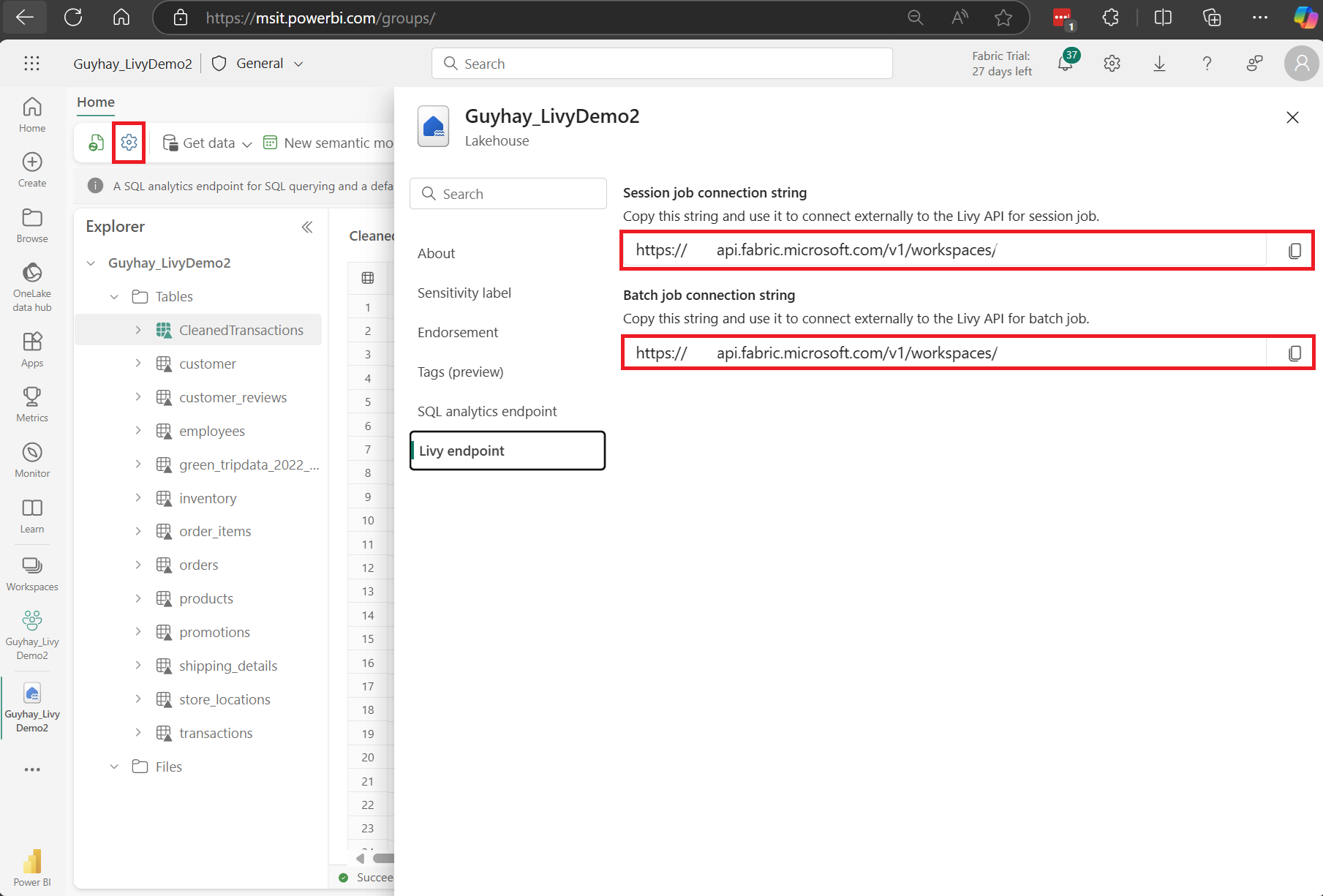
Kopieer de sessietaak verbindingsreeks (eerste rood vak in de afbeelding) naar uw code.
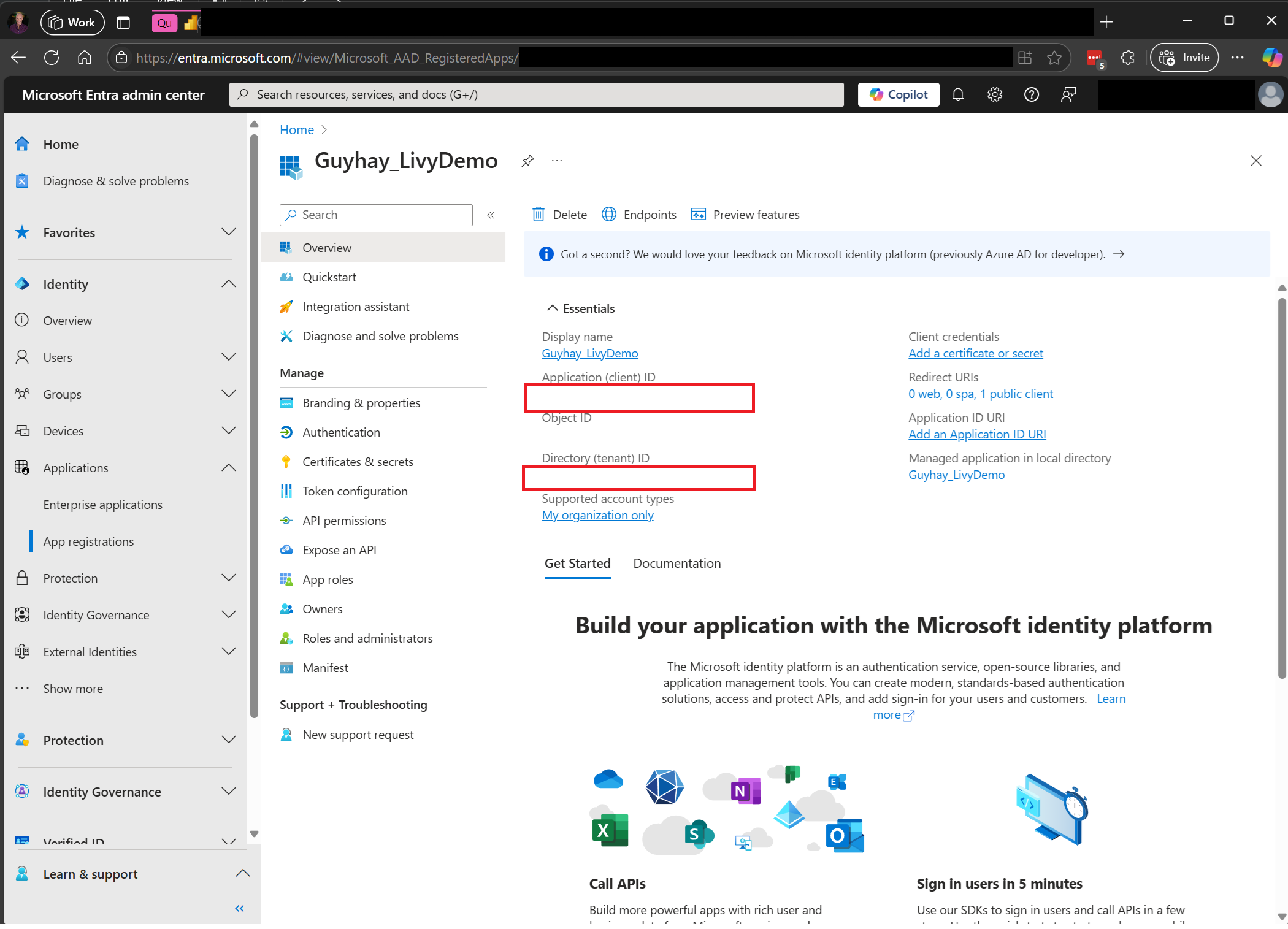
Navigeer naar het Microsoft Entra-beheercentrum en kopieer zowel de toepassings-id (client-id) als de map-id (tenant) naar uw code.



Een Livy API Spark-sessie maken
Maak een
.ipynbnotebook in Visual Studio Code en voeg de volgende code in.from msal import PublicClientApplication import requests import time tenant_id = "Entra_TenantID" client_id = "Entra_ClientID" workspace_id = "Fabric_WorkspaceID" lakehouse_id = "Fabric_LakehouseID" app = PublicClientApplication( client_id, authority="https://login.microsoftonline.com/43a26159-4e8e-442a-9f9c-cb7a13481d48" ) result = None # If no cached tokens or user interaction needed, acquire tokens interactively if not result: result = app.acquire_token_interactive(scopes=["https://api.fabric.microsoft.com/Lakehouse.Execute.All", "https://api.fabric.microsoft.com/Lakehouse.Read.All", "https://api.fabric.microsoft.com/Item.ReadWrite.All", "https://api.fabric.microsoft.com/Workspace.ReadWrite.All", "https://api.fabric.microsoft.com/Code.AccessStorage.All", "https://api.fabric.microsoft.com/Code.AccessAzureKeyvault.All", "https://api.fabric.microsoft.com/Code.AccessAzureDataExplorer.All", "https://api.fabric.microsoft.com/Code.AccessAzureDataLake.All", "https://api.fabric.microsoft.com/Code.AccessFabric.All"]) # Print the access token (you can use it to call APIs) if "access_token" in result: print(f"Access token: {result['access_token']}") else: print("Authentication failed or no access token obtained.") if "access_token" in result: access_token = result['access_token'] api_base_url_mist='https://api.fabric.microsoft.com/v1' livy_base_url = api_base_url_mist + "/workspaces/"+workspace_id+"/lakehouses/"+lakehouse_id +"/livyApi/versions/2023-12-01/sessions" headers = {"Authorization": "Bearer " + access_token}Voer de notebookcel uit. Er moet een pop-up worden weergegeven in uw browser, zodat u de identiteit kunt kiezen waarmee u zich kunt aanmelden.
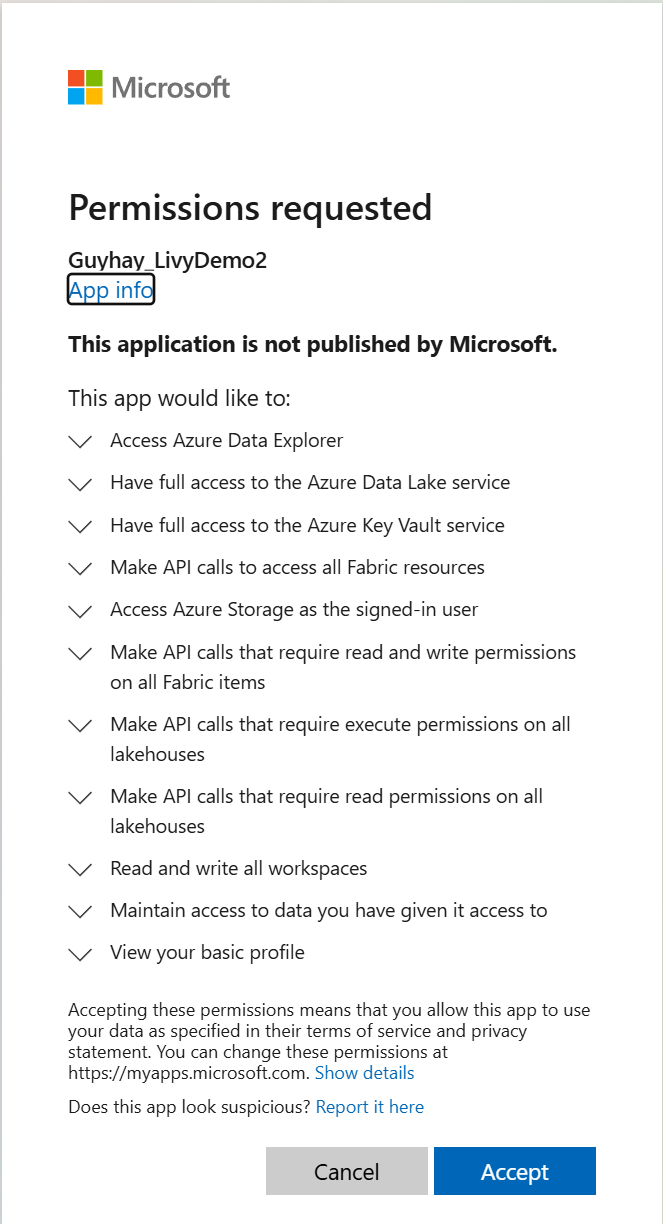
Nadat u de identiteit hebt gekozen waarmee u zich wilt aanmelden, wordt u ook gevraagd om de API-machtigingen voor de registratie-API voor Microsoft Entra-apps goed te keuren.
Sluit het browservenster nadat u de verificatie hebt voltooid.

In Visual Studio Code zou het Microsoft Entra-token moeten worden geretourneerd.
Voeg nog een notebookcel toe en voeg deze code in.
create_livy_session = requests.post(livy_base_url, headers=headers, json={}) print('The request to create the Livy session is submitted:' + str(create_livy_session.json())) livy_session_id = create_livy_session.json()['id'] livy_session_url = livy_base_url + "/" + livy_session_id get_session_response = requests.get(livy_session_url, headers=headers) print(get_session_response.json())Voer de notebookcel uit. U ziet dat er één regel wordt afgedrukt terwijl de Livy-sessie wordt gemaakt.

U kunt controleren of de Livy-sessie is gemaakt met behulp van de [Uw taken weergeven in de Bewakingshub](#View uw taken in de Monitoring Hub).





Een spark.sql-instructie verzenden met behulp van de Spark-sessie van de Livy-API
Voeg nog een notebookcel toe en voeg deze code in.
# call get session API livy_session_id = create_livy_session.json()['id'] livy_session_url = livy_base_url + "/" + livy_session_id get_session_response = requests.get(livy_session_url, headers=headers) print(get_session_response.json()) while get_session_response.json()["state"] != "idle": time.sleep(5) get_session_response = requests.get(livy_session_url, headers=headers) execute_statement = livy_session_url + "/statements" payload_data = { "code": "spark.sql(\"SELECT * FROM green_tripdata_2022_08 where fare_amount = 60\").show()", "kind": "spark" } execute_statement_response = requests.post(execute_statement, headers=headers, json=payload_data) print('the statement code is submitted as: ' + str(execute_statement_response.json())) statement_id = str(execute_statement_response.json()['id']) get_statement = livy_session_url+ "/statements/" + statement_id get_statement_response = requests.get(get_statement, headers=headers) while get_statement_response.json()["state"] != "available": # Sleep for 5 seconds before making the next request time.sleep(5) print('the statement code is submitted and running : ' + str(execute_statement_response.json())) # Make the next request get_statement_response = requests.get(get_statement, headers=headers) rst = get_statement_response.json()['output']['data']['text/plain'] print(rst)Voer de notebookcel uit. U ziet dat er meerdere incrementele regels worden afgedrukt terwijl de taak wordt verzonden en de geretourneerde resultaten.
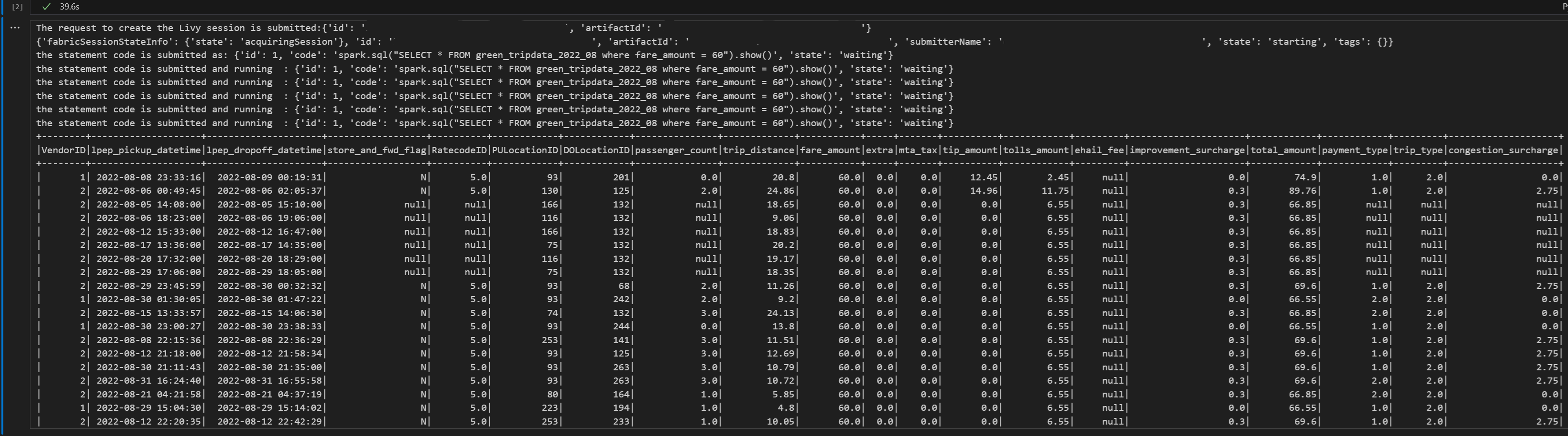

Een tweede spark.sql-instructie verzenden met behulp van de Spark-sessie van de Livy-API
Voeg nog een notebookcel toe en voeg deze code in.
# call get session API livy_session_id = create_livy_session.json()['id'] livy_session_url = livy_base_url + "/" + livy_session_id get_session_response = requests.get(livy_session_url, headers=headers) print(get_session_response.json()) while get_session_response.json()["state"] != "idle": time.sleep(5) get_session_response = requests.get(livy_session_url, headers=headers) execute_statement = livy_session_url + "/statements" payload_data = { "code": "spark.sql(\"SELECT * FROM green_tripdata_2022_08 where tip_amount = 10\").show()", "kind": "spark" } execute_statement_response = requests.post(execute_statement, headers=headers, json=payload_data) print('the statement code is submitted as: ' + str(execute_statement_response.json())) statement_id = str(execute_statement_response.json()['id']) get_statement = livy_session_url+ "/statements/" + statement_id get_statement_response = requests.get(get_statement, headers=headers) while get_statement_response.json()["state"] != "available": # Sleep for 5 seconds before making the next request time.sleep(5) print('the statement code is submitted and running : ' + str(execute_statement_response.json())) # Make the next request get_statement_response = requests.get(get_statement, headers=headers) rst = get_statement_response.json()['output']['data']['text/plain'] print(rst)Voer de notebookcel uit. U ziet dat er meerdere incrementele regels worden afgedrukt terwijl de taak wordt verzonden en de geretourneerde resultaten.
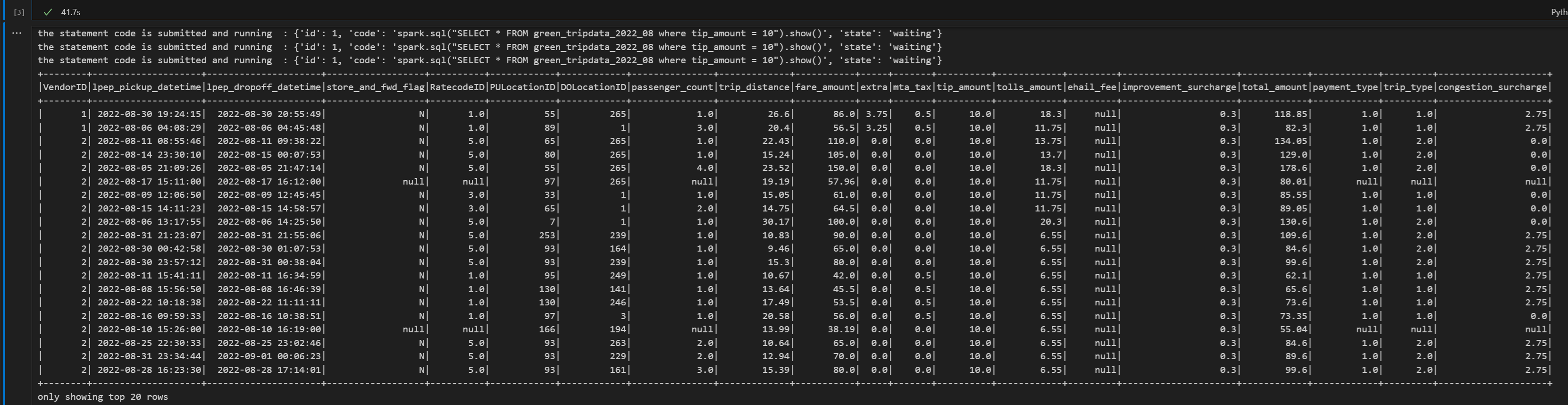

Sluit de Livy-sessie met een derde instructie
Voeg nog een notebookcel toe en voeg deze code in.
# call get session API with a delete session statement get_session_response = requests.get(livy_session_url, headers=headers) print('Livy statement URL ' + livy_session_url) response = requests.delete(livy_session_url, headers=headers) print (response)
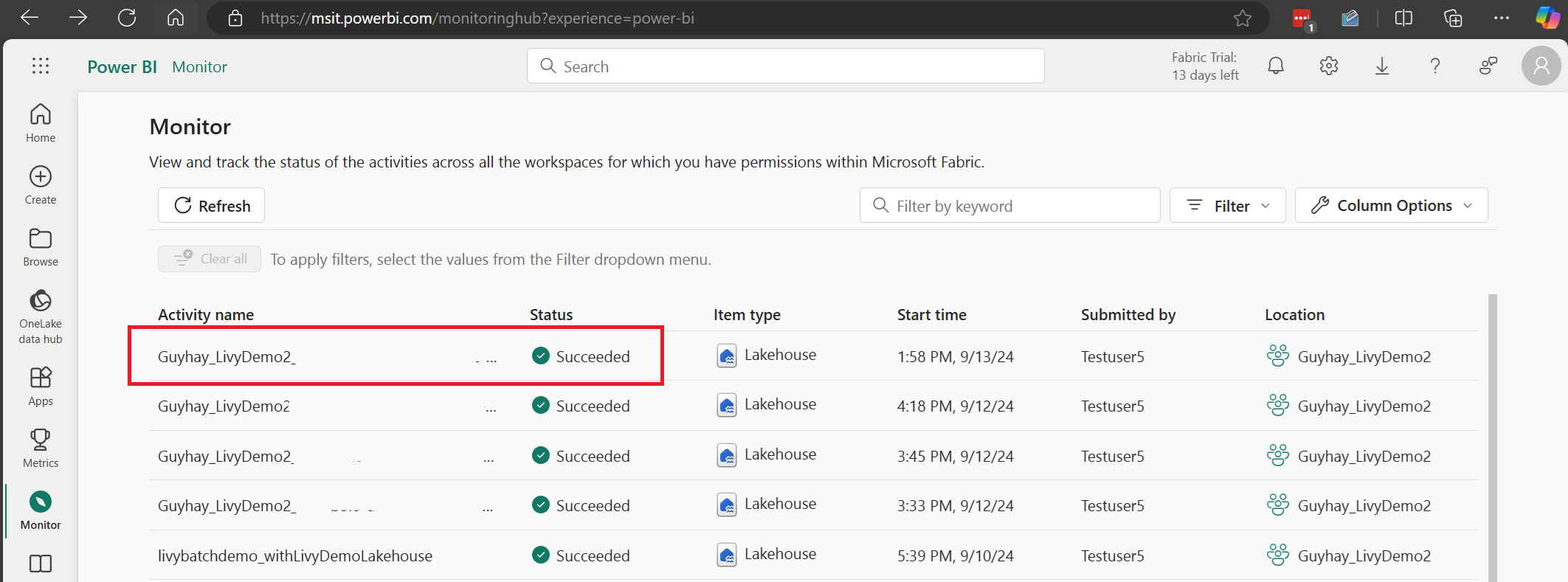
Uw taken weergeven in de Bewakingshub
U hebt toegang tot de Bewakingshub om verschillende Apache Spark-activiteiten weer te geven door Monitor te selecteren in de navigatiekoppelingen aan de linkerkant.
Wanneer de sessie wordt uitgevoerd of de voltooide status heeft, kunt u de sessiestatus bekijken door naar Monitor te navigeren.
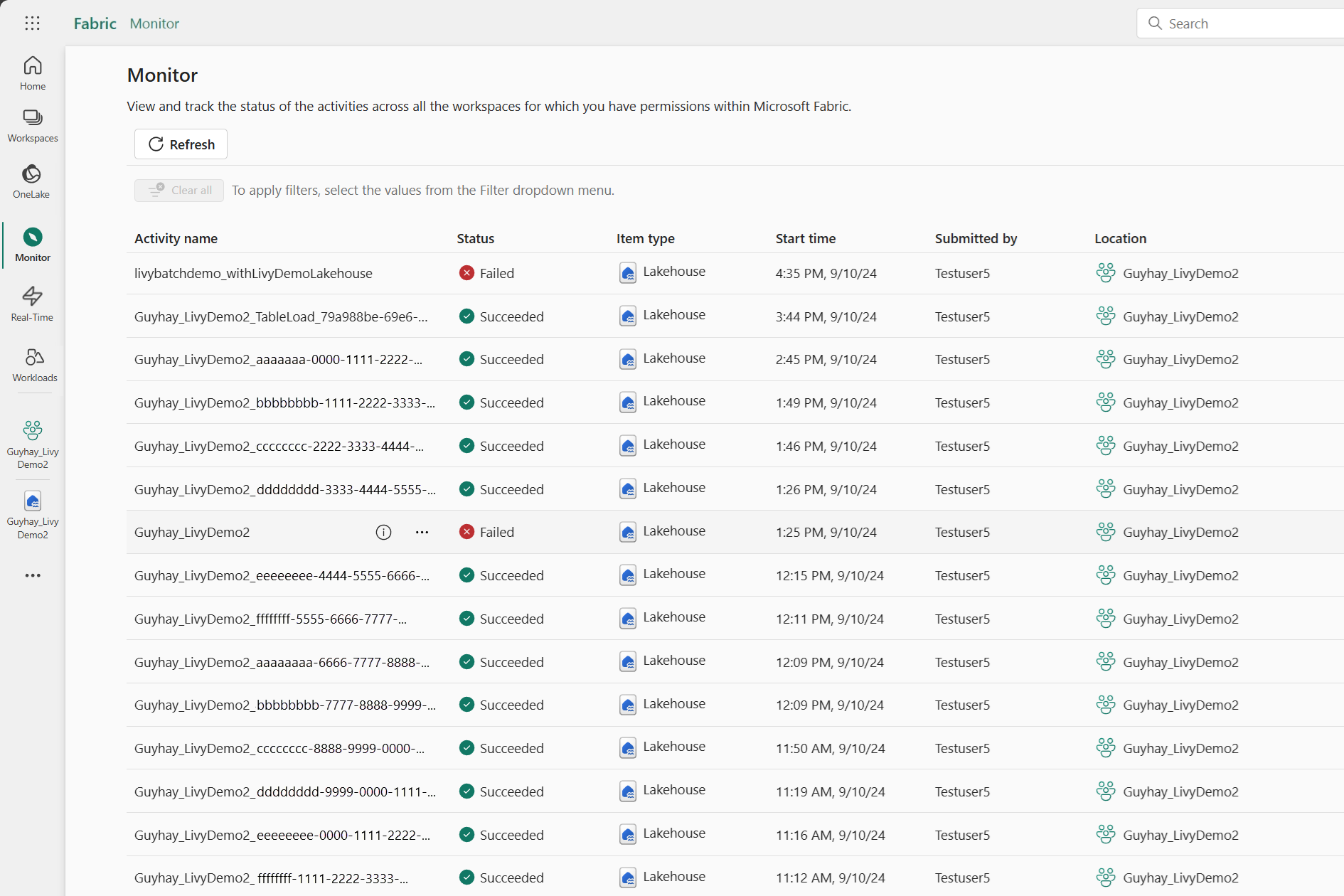
Selecteer en open de naam van de meest recente activiteit.
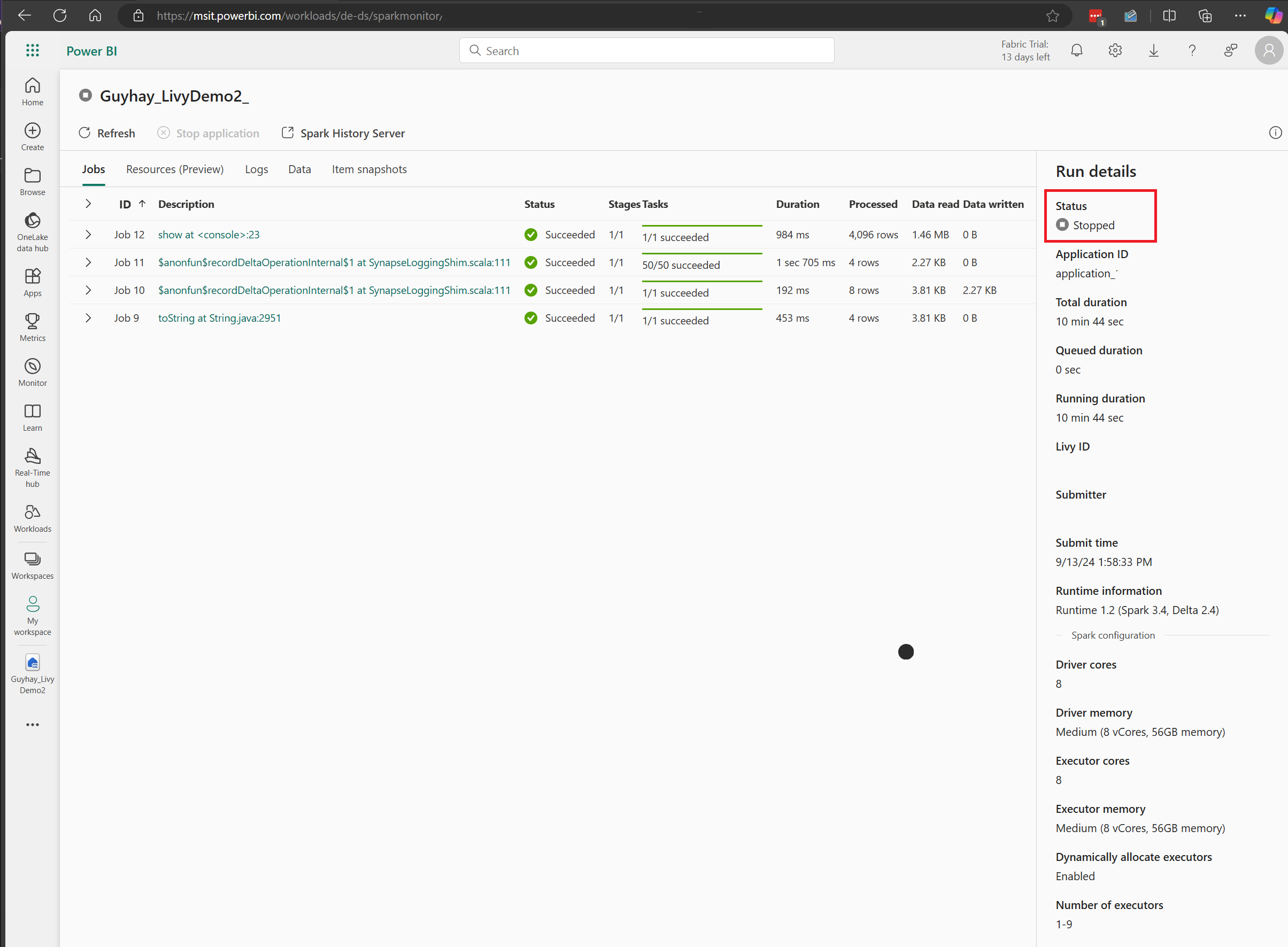
In dit geval van livy-API-sessie kunt u uw eerdere sessies zien, details uitvoeren, Spark-versies en configuratie. Let op de gestopte status rechtsboven.

Als u het hele proces wilt invatten, hebt u een externe client nodig, zoals Visual Studio Code, een Token van de Microsoft Entra-app, de URL van het Livy API-eindpunt, verificatie voor uw Lakehouse en ten slotte een Session Livy-API.