De Livy-API gebruiken om Livy-batchtaken te verzenden en uit te voeren
Notitie
De Livy-API voor Fabric Data-engineer ing is in preview.
Van toepassing op:✅ Data-engineer ing en Datawetenschap in Microsoft Fabric
Verzend Spark-batchtaken met behulp van de Livy-API voor Fabric Data-engineer ing.
Vereisten
Fabric Premium - of proefcapaciteit met een Lakehouse.
Een externe client zoals Visual Studio Code met Jupyter Notebooks, PySpark en de Microsoft Authentication Library (MSAL) voor Python.
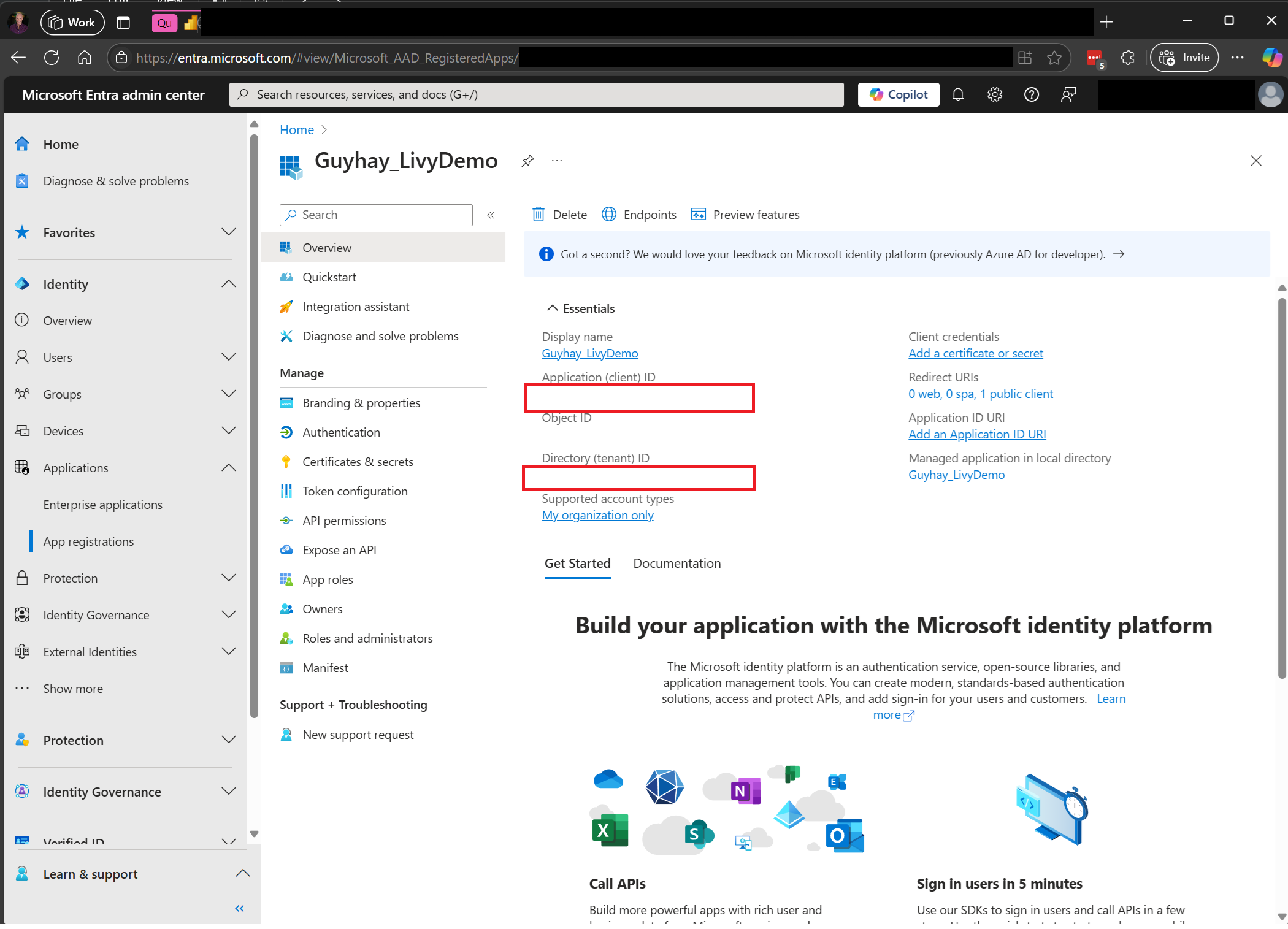
Er is een Microsoft Entra-app-token vereist voor toegang tot de Fabric Rest API. Registreer een toepassing bij het Microsoft Identity Platform.
Sommige gegevens in uw lakehouse, in dit voorbeeld worden NYC Taxi & Limousine Commission green_tripdata_2022_08 een parquet-bestand geladen in het lakehouse.
De Livy-API definieert een uniform eindpunt voor bewerkingen. Vervang de tijdelijke aanduidingen {Entra_TenantID}, {Entra_ClientID}, {Fabric_WorkspaceID} en {Fabric_LakehouseID} door de juiste waarden wanneer u de voorbeelden in dit artikel volgt.
Visual Studio Code configureren voor uw Livy API Batch
Selecteer Lakehouse-instellingen in uw Fabric Lakehouse.

Navigeer naar de sectie Livy-eindpunt .
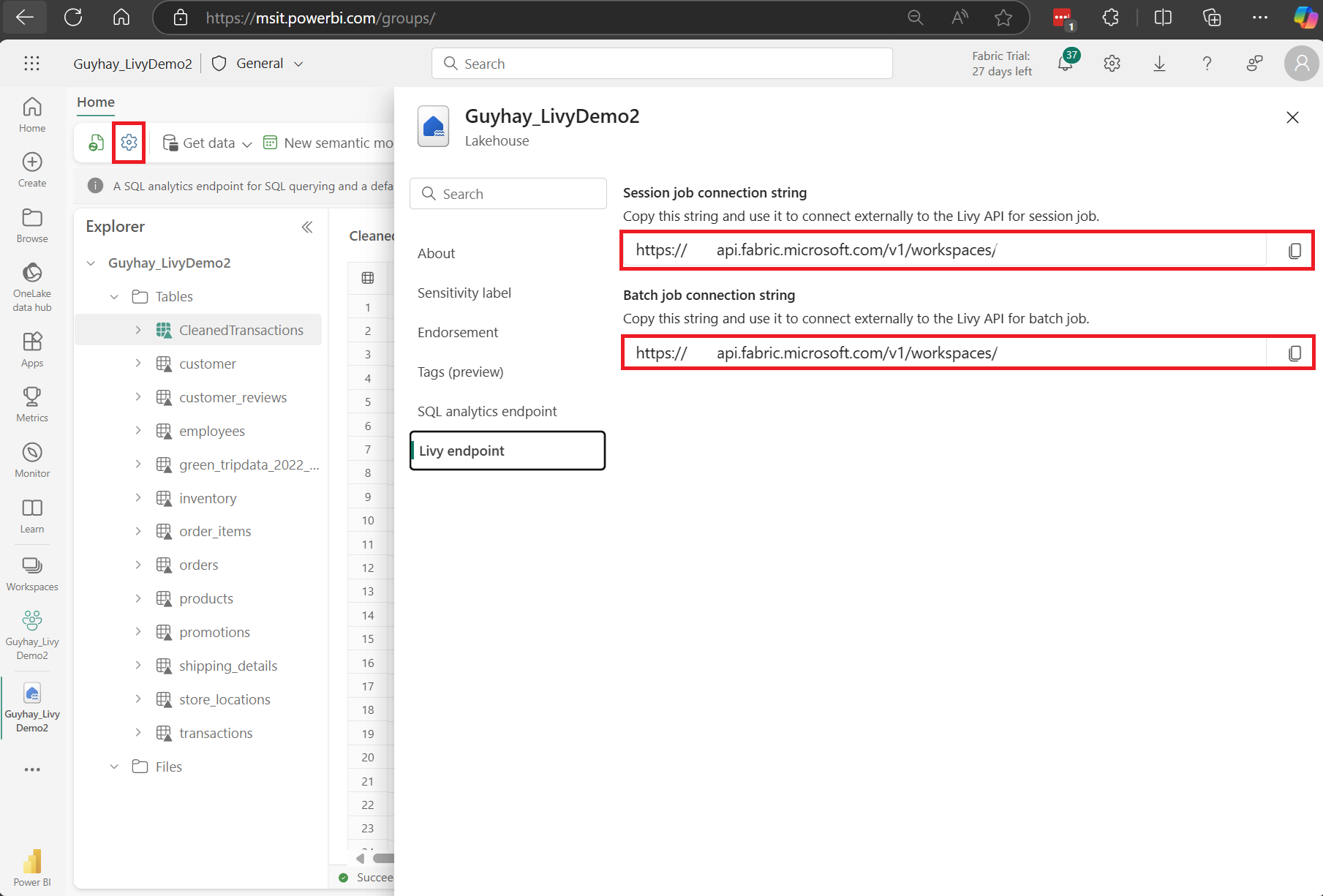
Kopieer de Batch-taak verbindingsreeks (tweede rood vak in de afbeelding) naar uw code.
Navigeer naar het Microsoft Entra-beheercentrum en kopieer zowel de toepassings-id (client-id) als de map-id (tenant) naar uw code.



Een Spark-nettolading maken en uploaden naar uw Lakehouse
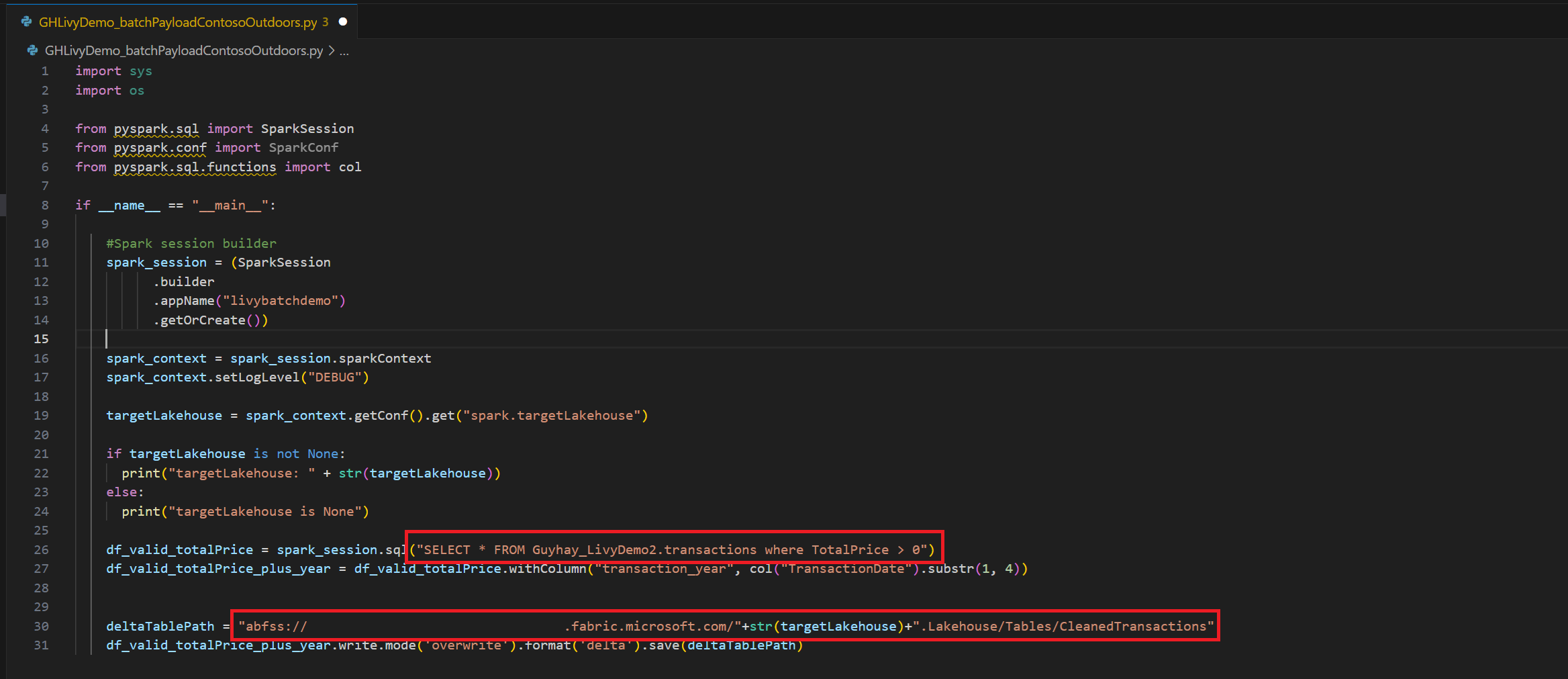
.ipynbEen notebook maken in Visual Studio Code en de volgende code invoegenimport sys import os from pyspark.sql import SparkSession from pyspark.conf import SparkConf from pyspark.sql.functions import col if __name__ == "__main__": #Spark session builder spark_session = (SparkSession .builder .appName("livybatchdemo") .getOrCreate()) spark_context = spark_session.sparkContext spark_context.setLogLevel("DEBUG") targetLakehouse = spark_context.getConf().get("spark.targetLakehouse") if targetLakehouse is not None: print("targetLakehouse: " + str(targetLakehouse)) else: print("targetLakehouse is None") df_valid_totalPrice = spark_session.sql("SELECT * FROM <YourLakeHouseDataTableName>.transactions where TotalPrice > 0") df_valid_totalPrice_plus_year = df_valid_totalPrice.withColumn("transaction_year", col("TransactionDate").substr(1, 4)) deltaTablePath = "abfss:<YourABFSSpath>"+str(targetLakehouse)+".Lakehouse/Tables/CleanedTransactions" df_valid_totalPrice_plus_year.write.mode('overwrite').format('delta').save(deltaTablePath)Sla het Python-bestand lokaal op. Deze Python-codepayload bevat twee Spark-instructies die werken aan gegevens in een Lakehouse en moeten worden geüpload naar uw Lakehouse. U hebt het ABFS-pad van de payload nodig om te verwijzen naar in uw Livy API-batchtaak in Visual Studio Code, en de naam van uw Lakehouse-tabel in de SQL SELECT-instructie.
Upload de Python-nettolading naar de bestandssectie van uw Lakehouse. > Download bestanden > uploaden > klik in het vak Bestanden/invoer.
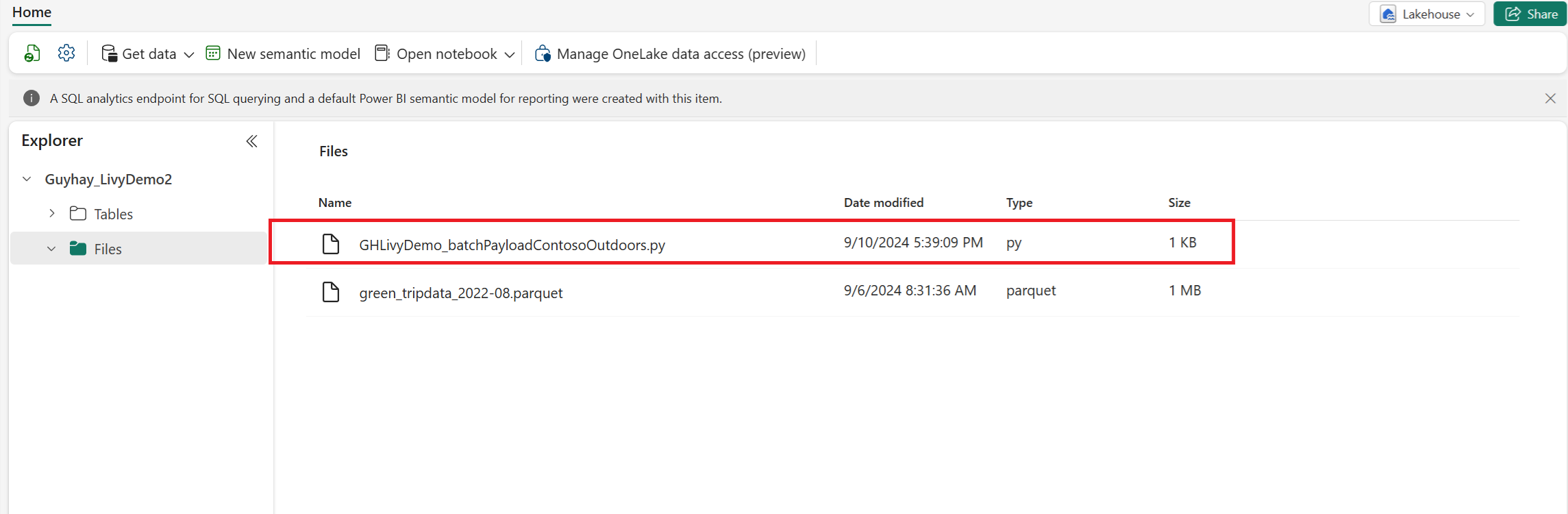
Nadat het bestand zich in de sectie Bestanden van uw Lakehouse bevindt, klikt u op de drie puntjes rechts van de bestandsnaam van de nettolading en selecteert u Eigenschappen.
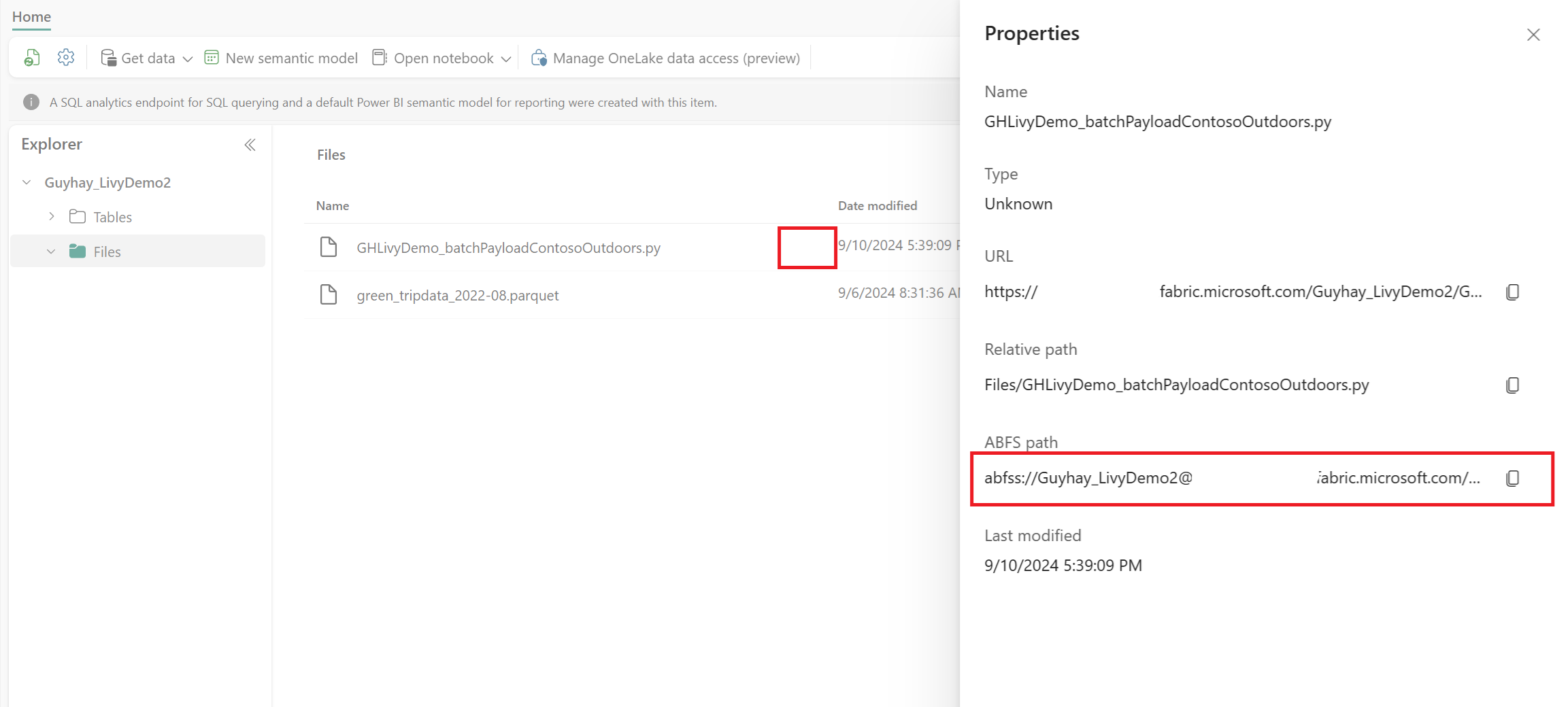
Kopieer dit ABFS-pad naar uw notebookcel in stap 1.



Een Livy API Spark-batchsessie maken
Maak een
.ipynbnotebook in Visual Studio Code en voeg de volgende code in.from msal import PublicClientApplication import requests import time tenant_id = "<Entra_TenantID>" client_id = "<Entra_ClientID>" workspace_id = "<Fabric_WorkspaceID>" lakehouse_id = "<Fabric_LakehouseID>" app = PublicClientApplication( client_id, authority="https://login.microsoftonline.com/43a26159-4e8e-442a-9f9c-cb7a13481d48" ) result = None # If no cached tokens or user interaction needed, acquire tokens interactively if not result: result = app.acquire_token_interactive(scopes=["https://api.fabric.microsoft.com/Lakehouse.Execute.All", "https://api.fabric.microsoft.com/Lakehouse.Read.All", "https://api.fabric.microsoft.com/Item.ReadWrite.All", "https://api.fabric.microsoft.com/Workspace.ReadWrite.All", "https://api.fabric.microsoft.com/Code.AccessStorage.All", "https://api.fabric.microsoft.com/Code.AccessAzureKeyvault.All", "https://api.fabric.microsoft.com/Code.AccessAzureDataExplorer.All", "https://api.fabric.microsoft.com/Code.AccessAzureDataLake.All", "https://api.fabric.microsoft.com/Code.AccessFabric.All"]) # Print the access token (you can use it to call APIs) if "access_token" in result: print(f"Access token: {result['access_token']}") else: print("Authentication failed or no access token obtained.") if "access_token" in result: access_token = result['access_token'] api_base_url_mist='https://api.fabric.microsoft.com/v1' livy_base_url = api_base_url_mist + "/workspaces/"+workspace_id+"/lakehouses/"+lakehouse_id +"/livyApi/versions/2023-12-01/batches" headers = {"Authorization": "Bearer " + access_token}Voer de notebookcel uit. Er moet een pop-up worden weergegeven in uw browser, zodat u de identiteit kunt kiezen waarmee u zich kunt aanmelden.
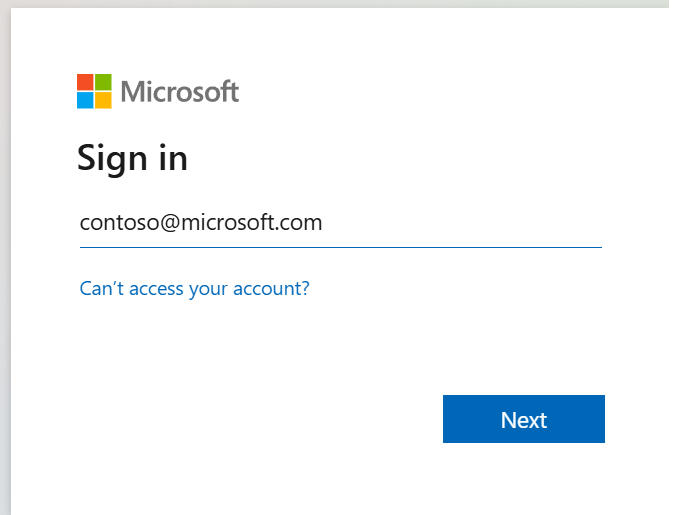
Nadat u de identiteit hebt gekozen waarmee u zich wilt aanmelden, wordt u ook gevraagd om de API-machtigingen voor de registratie-API voor Microsoft Entra-apps goed te keuren.
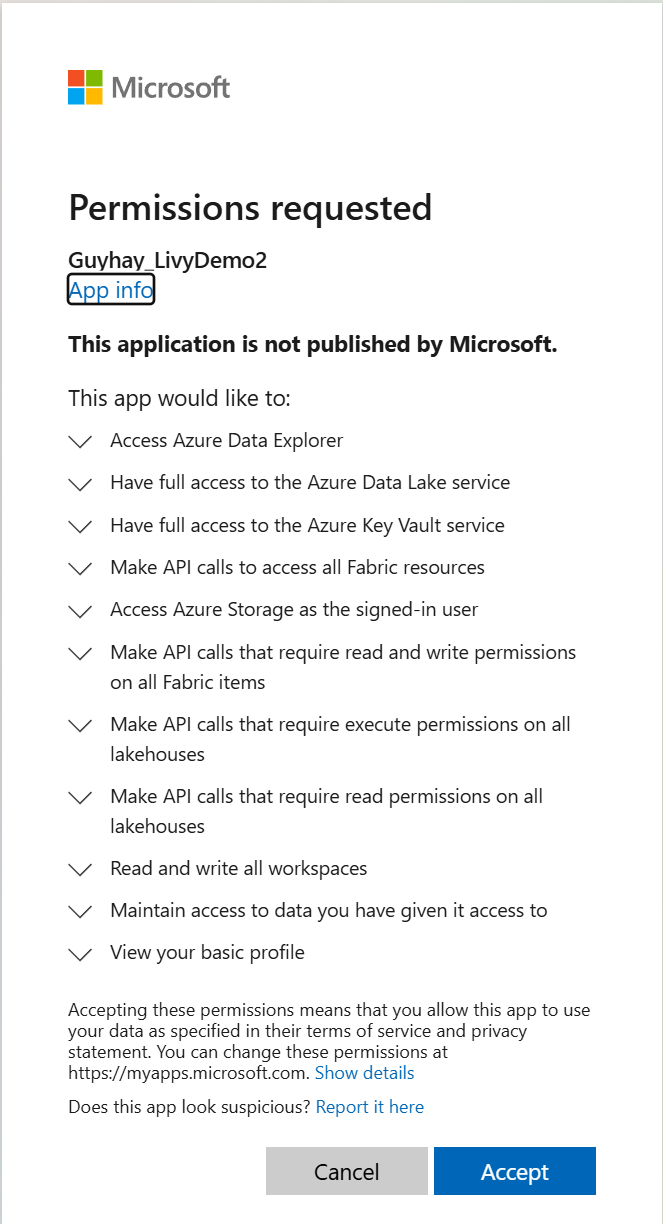
Sluit het browservenster nadat u de verificatie hebt voltooid.

In Visual Studio Code zou het Microsoft Entra-token moeten worden geretourneerd.
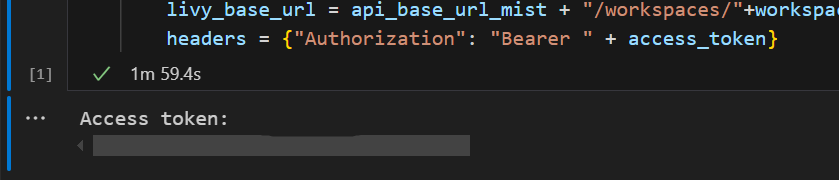
Voeg nog een notebookcel toe en voeg deze code in.
# call get batch API get_livy_get_batch = livy_base_url get_batch_response = requests.get(get_livy_get_batch, headers=headers) if get_batch_response.status_code == 200: print("API call successful") print(get_batch_response.json()) else: print(f"API call failed with status code: {get_batch_response.status_code}") print(get_batch_response.text)Voer de notebookcel uit. U ziet dat er twee regels worden afgedrukt terwijl de Livy-batchtaak wordt gemaakt.






Een spark.sql-instructie verzenden met behulp van de Livy API-batchsessie
Voeg nog een notebookcel toe en voeg deze code in.
# submit payload to existing batch session print('Submit a spark job via the livy batch API to ') newlakehouseName = "YourNewLakehouseName" create_lakehouse = api_base_url_mist + "/workspaces/" + workspace_id + "/items" create_lakehouse_payload = { "displayName": newlakehouseName, "type": 'Lakehouse' } create_lakehouse_response = requests.post(create_lakehouse, headers=headers, json=create_lakehouse_payload) print(create_lakehouse_response.json()) payload_data = { "name":"livybatchdemo_with"+ newlakehouseName, "file":"abfss://YourABFSPathToYourPayload.py", "conf": { "spark.targetLakehouse": "Fabric_LakehouseID" } } get_batch_response = requests.post(get_livy_get_batch, headers=headers, json=payload_data) print("The Livy batch job submitted successful") print(get_batch_response.json())Voer de notebookcel uit. U ziet dat er verschillende regels worden afgedrukt terwijl de Livy Batch-taak wordt gemaakt en uitgevoerd.

Ga terug naar uw Lakehouse om de wijzigingen te bekijken.

Uw taken weergeven in de Bewakingshub
U hebt toegang tot de Bewakingshub om verschillende Apache Spark-activiteiten weer te geven door Monitor te selecteren in de navigatiekoppelingen aan de linkerkant.
Wanneer de batchtaak is voltooid, kunt u de sessiestatus bekijken door naar Monitor te navigeren.
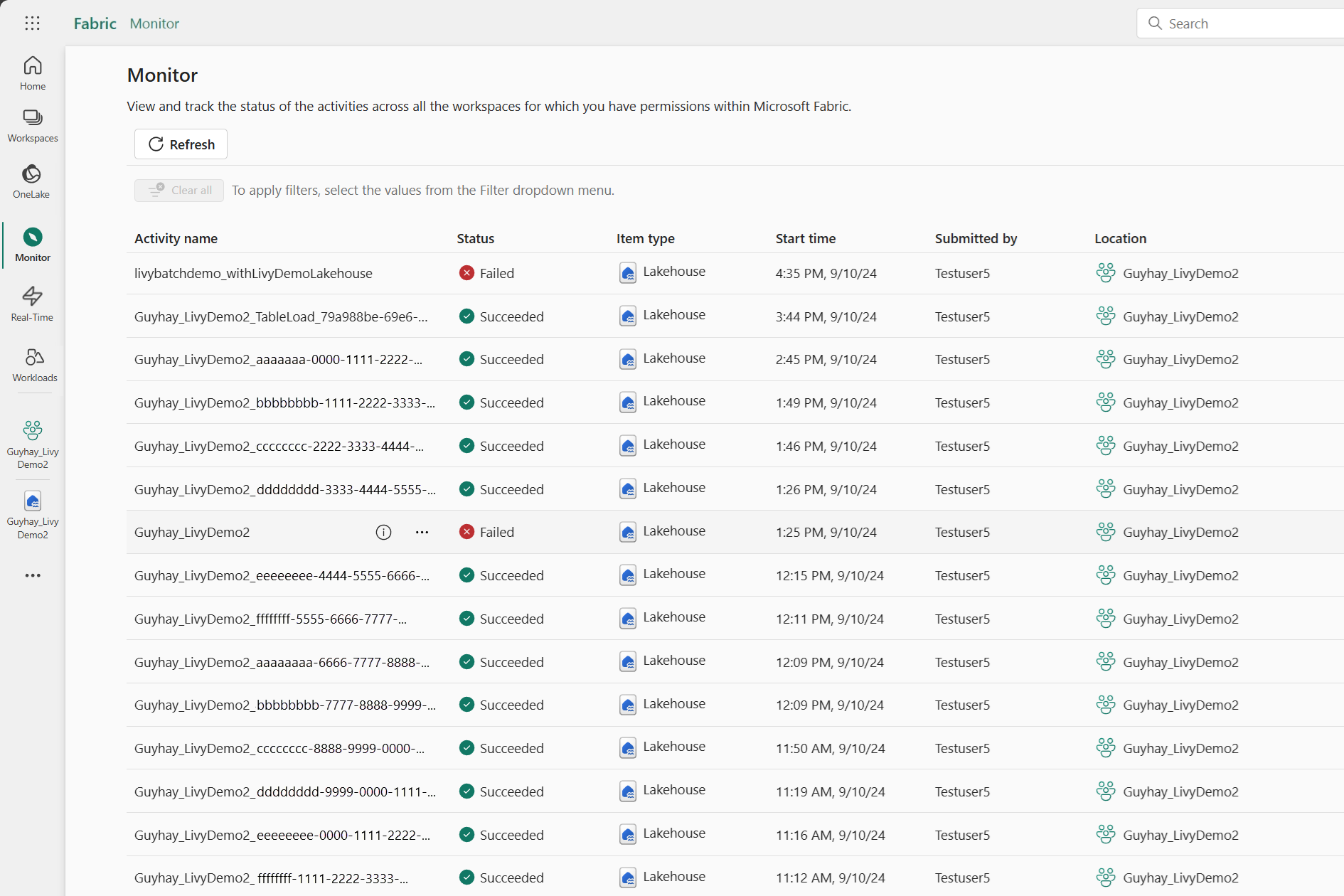
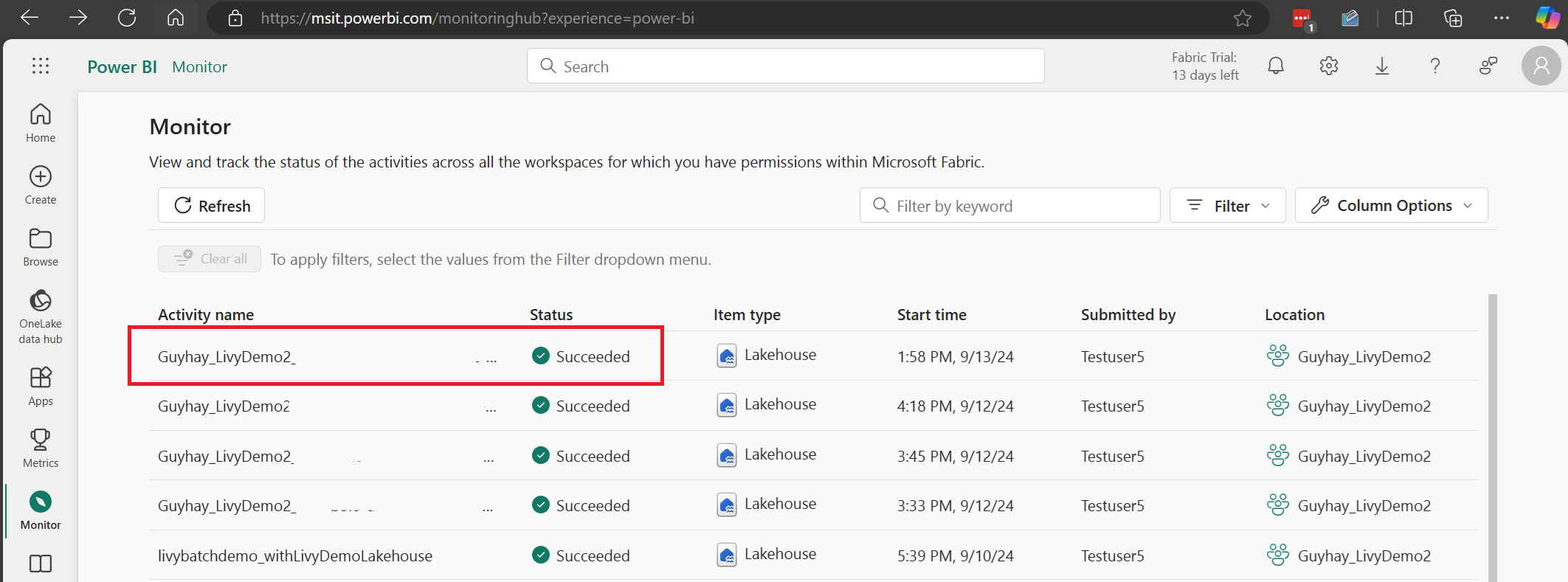
Selecteer en open de naam van de meest recente activiteit.
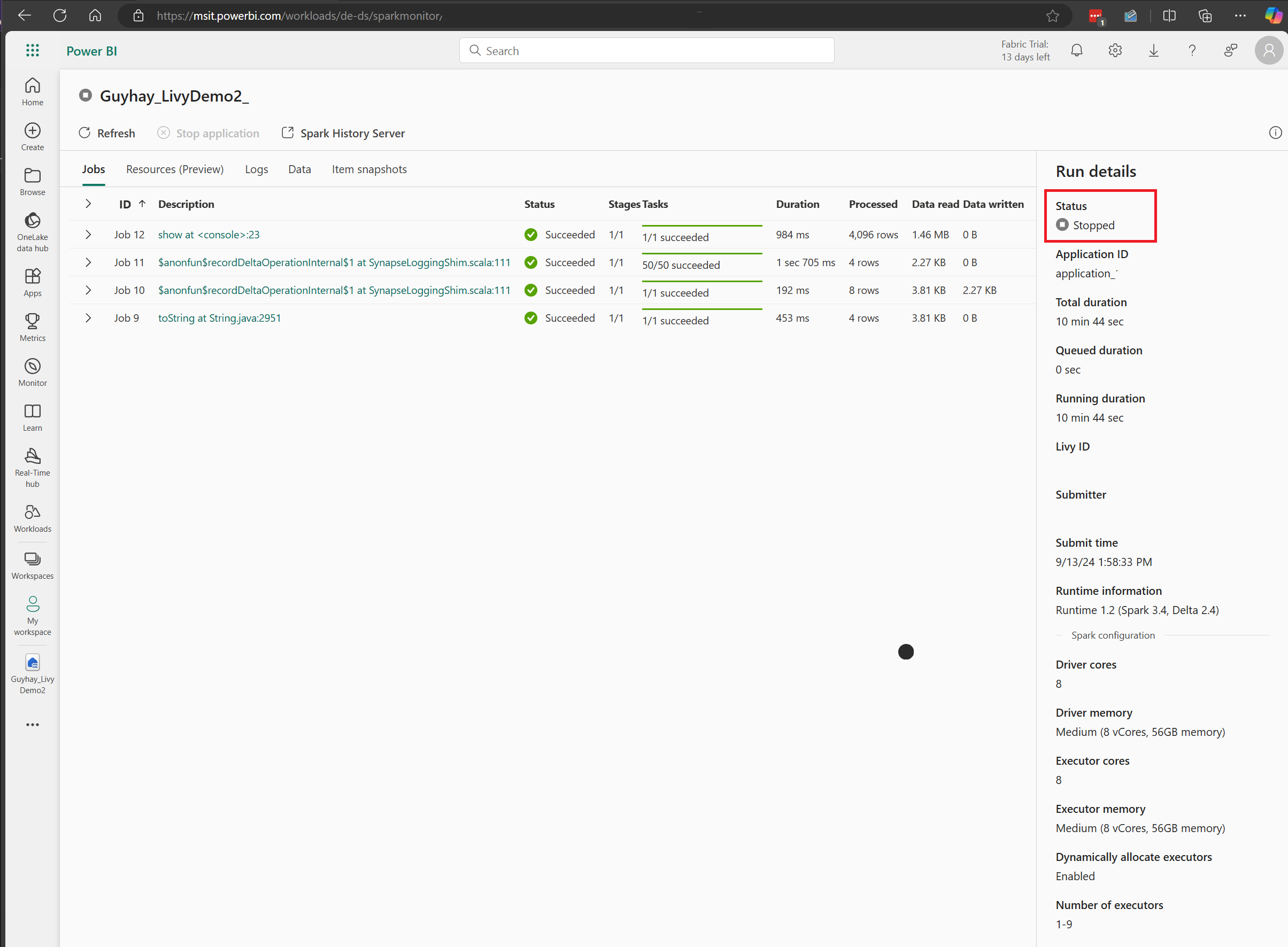
In dit geval van livy-API-sessie kunt u uw vorige batchinzending zien, details uitvoeren, Spark-versies en configuratie. Let op de gestopte status rechtsboven.



Als u het hele proces wilt terugvatten, hebt u een externe client nodig, zoals Visual Studio Code, een Microsoft Entra-app-token, de URL van het Livy API-eindpunt, verificatie voor uw Lakehouse, een Spark-nettolading in uw Lakehouse en ten slotte een batch-Livy API-sessie.