Taken en invoergegevens voor batcheindpunten maken
Met Batch-eindpunten kunt u lange batchbewerkingen uitvoeren op grote hoeveelheden gegevens. De gegevens kunnen zich op verschillende plaatsen bevinden, zoals over verspreide regio's. Bepaalde typen batcheindpunten kunnen ook letterlijke parameters ontvangen als invoer.
In dit artikel wordt beschreven hoe u parameterinvoer voor batch-eindpunten opgeeft en implementatietaken maakt. Het proces ondersteunt het werken met verschillende typen gegevens. Zie Invoer en uitvoer begrijpen voor enkele voorbeelden.
Vereisten
Als u een batch-eindpunt wilt aanroepen en taken wilt maken, moet u de volgende vereisten voltooien:
Een batch-eindpunt en -implementatie. Als u deze resources niet hebt, raadpleegt u Modellen implementeren voor scoren in batch-eindpunten om een implementatie te maken.
Machtigingen voor het uitvoeren van een batch-eindpuntimplementatie. De rollen AzureML Datawetenschapper, Inzender en Eigenaar kunnen worden gebruikt om een implementatie uit te voeren. Zie Autorisatie voor batcheindpunten voor aangepaste roldefinities om de specifieke vereiste machtigingen te controleren.
Een geldig Microsoft Entra ID-token dat een beveiligingsprincipal vertegenwoordigt om het eindpunt aan te roepen. Deze principal kan een gebruikers-principal of een service-principal zijn. Nadat u een eindpunt hebt aangeroepen, maakt Azure Machine Learning een batchimplementatietaak onder de identiteit die is gekoppeld aan het token. U kunt uw eigen referenties gebruiken voor de aanroep, zoals beschreven in de volgende procedures.
Gebruik de Azure CLI om u aan te melden met interactieve verificatie of apparaatcode:
az loginZie Taken uitvoeren met behulp van verschillende typen referenties voor meer informatie over het starten van batchimplementatietaken.
Het rekencluster waar het eindpunt is geïmplementeerd, heeft toegang om de invoergegevens te lezen.
Tip
Als u een gegevensarchief met minder referenties of een extern Azure Storage-account gebruikt als gegevensinvoer, moet u rekenclusters configureren voor gegevenstoegang. De beheerde identiteit van het rekencluster wordt gebruikt voor het koppelen van het opslagaccount. De identiteit van de taak (invoker) wordt nog steeds gebruikt om de onderliggende gegevens te lezen, zodat u gedetailleerd toegangsbeheer kunt bereiken.
Basisbeginselen van taken maken
Als u een taak wilt maken op basis van een batch-eindpunt, roept u het eindpunt aan. U kunt aanroepen doen met behulp van de Azure CLI, de Azure Machine Learning SDK voor Python of een REST API-aanroep. In de volgende voorbeelden ziet u de basisbeginselen van aanroepen voor een batch-eindpunt dat één invoergegevensmap ontvangt voor verwerking. Zie Invoer en uitvoer begrijpen voor voorbeelden met verschillende invoer- en uitvoerwaarden.
Gebruik de invoke bewerking onder batch-eindpunten:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data
Een specifieke implementatie aanroepen
Batch-eindpunten kunnen meerdere implementaties hosten onder hetzelfde eindpunt. Het standaardeindpunt wordt gebruikt, tenzij de gebruiker anders opgeeft. U kunt de implementatie wijzigen voor gebruik met de volgende procedures.
Gebruik het argument --deployment-name of -d geef de naam van de implementatie op:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--deployment-name $DEPLOYMENT_NAME \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data
Taakeigenschappen configureren
U kunt enkele eigenschappen in de gemaakte taak configureren tijdens het aanroepen.
Notitie
De mogelijkheid om taakeigenschappen te configureren, is momenteel alleen beschikbaar in batch-eindpunten met pijplijnonderdeelimplementaties.
Experimentnaam configureren
Gebruik de volgende procedures om de naam van het experiment te configureren.
Gebruik het argument --experiment-name om de naam van het experiment op te geven:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--experiment-name "my-batch-job-experiment" \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data
Inzicht in invoer en uitvoer
Batch-eindpunten bieden een duurzame API die consumenten kunnen gebruiken om batchtaken te maken. Dezelfde interface kan worden gebruikt om de invoer en uitvoer op te geven die uw implementatie verwacht. Gebruik invoer om informatie door te geven die uw eindpunt nodig heeft om de taak uit te voeren.
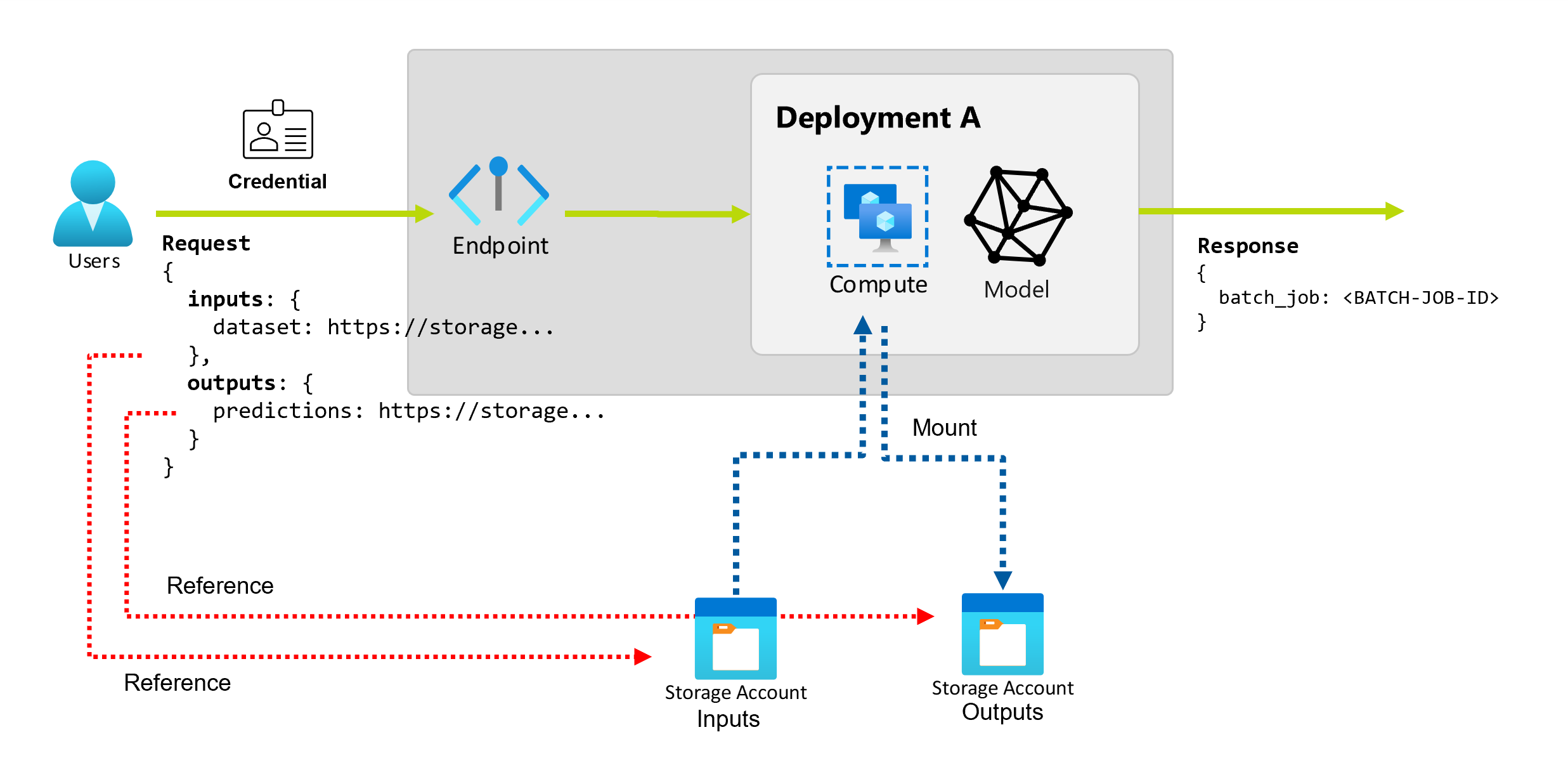
Batch-eindpunten ondersteunen twee typen invoer:
- Gegevensinvoer: verwijst naar een specifieke opslaglocatie of Azure Machine Learning-asset.
- Letterlijke invoer: Letterlijke waarden, zoals getallen of tekenreeksen die u aan de taak wilt doorgeven.
Het aantal en het type invoer en uitvoer zijn afhankelijk van het type batchimplementatie. Modelimplementaties vereisen altijd één gegevensinvoer en produceren één gegevensuitvoer. Letterlijke invoer wordt niet ondersteund. Implementaties van pijplijnonderdelen bieden echter een algemenere constructie voor het bouwen van eindpunten en bieden u de mogelijkheid om een willekeurig aantal invoer (gegevens en letterlijke waarden) en uitvoer op te geven.
De volgende tabel bevat een overzicht van de invoer en uitvoer voor batchimplementaties:
| Implementatietype | Aantal invoergegevens | Ondersteunde invoertypen | Aantal uitvoer | Ondersteunde uitvoertypen |
|---|---|---|---|---|
| Modelimplementatie | 1 | Gegevensinvoer | 1 | Gegevensuitvoer |
| Implementatie van pijplijnonderdelen | [0..N] | Gegevensinvoer en letterlijke invoer | [0..N] | Gegevensuitvoer |
Tip
Invoer en uitvoer hebben altijd de naam. De namen fungeren als sleutels om de gegevens te identificeren en de werkelijke waarde door te geven tijdens het aanroepen. Omdat modelimplementaties altijd één invoer en uitvoer vereisen, wordt de naam tijdens het aanroepen genegeerd. U kunt de naam toewijzen die het beste uw gebruiksscenario beschrijft, zoals 'sales_estimation'.
Gegevensinvoer verkennen
Gegevensinvoer verwijst naar invoer die verwijst naar een locatie waar gegevens worden geplaatst. Omdat batcheindpunten meestal grote hoeveelheden gegevens verbruiken, kunt u de invoergegevens niet doorgeven als onderdeel van de aanroepaanvraag. In plaats daarvan geeft u de locatie op waar het batch-eindpunt naar de gegevens moet zoeken. Invoergegevens worden gekoppeld en gestreamd op de doel-rekenkracht om de prestaties te verbeteren.
Batch-eindpunten ondersteunen het lezen van bestanden in de volgende opslagopties:
- Azure Machine Learning-gegevensassets, waaronder map (
uri_folder) en bestand (uri_file). - Azure Machine Learning-gegevensarchieven, waaronder Azure Blob Storage, Azure Data Lake Storage Gen1 en Azure Data Lake Storage Gen2.
- Azure Storage-accounts, waaronder Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2 en Azure Blob Storage.
- Lokale gegevensmappen/bestanden (Azure Machine Learning CLI of Azure Machine Learning SDK voor Python). Deze bewerking resulteert echter in het uploaden van de lokale gegevens naar de standaard Azure Machine Learning-gegevensopslag van de werkruimte waaraan u werkt.
Belangrijk
Afschaffingsmelding: Gegevenssets van het type FileDataset (V1) zijn afgeschaft en worden in de toekomst buiten gebruik gesteld. Bestaande batcheindpunten die afhankelijk zijn van deze functionaliteit, blijven werken. Batch-eindpunten die zijn gemaakt met GA CLIv2 (2.4.0 en hoger) of GA REST API (2022-05-01 en hoger) bieden geen ondersteuning voor V1-gegevenssets.
Letterlijke invoer verkennen
Letterlijke invoer verwijst naar invoer die kan worden weergegeven en omgezet tijdens aanroeptijd, zoals tekenreeksen, getallen en booleaanse waarden. Doorgaans gebruikt u letterlijke invoer om parameters door te geven aan uw eindpunt als onderdeel van een implementatie van een pijplijnonderdeel. Batch-eindpunten ondersteunen de volgende letterlijke typen:
stringbooleanfloatinteger
Letterlijke invoer wordt alleen ondersteund in implementaties van pijplijnonderdelen. Zie Taken maken met letterlijke invoer voor meer informatie over het opgeven van taken.
Gegevensuitvoer verkennen
Gegevensuitvoer verwijst naar de locatie waar de resultaten van een batchtaak moeten worden geplaatst. Elke uitvoer heeft een identificeerbare naam en Azure Machine Learning wijst automatisch een uniek pad toe aan elke benoemde uitvoer. U kunt desgewenst een ander pad opgeven.
Belangrijk
Batch-eindpunten ondersteunen alleen schrijfuitvoer in Azure Blob Storage-gegevensarchieven. Als u naar een opslagaccount wilt schrijven waarvoor hiërarchische naamruimten zijn ingeschakeld (ook wel Azure Datalake Gen2 of ADLS Gen2 genoemd), kunt u de opslagservice registreren als een Azure Blob Storage-gegevensarchief omdat de services volledig compatibel zijn. Op deze manier kunt u uitvoer van batcheindpunten schrijven naar ADLS Gen2.
Taken maken met gegevensinvoer
In de volgende voorbeelden ziet u hoe u taken maakt, gegevensinvoer neemt van gegevensassets, gegevensarchieven en Azure Storage-accounts.
Invoergegevens van gegevensasset gebruiken
Azure Machine Learning-gegevensassets (voorheen gegevenssets genoemd) worden ondersteund als invoer voor taken. Volg deze stappen om een batch-eindpunttaak uit te voeren met behulp van gegevens die zijn opgeslagen in een geregistreerde gegevensasset in Azure Machine Learning.
Waarschuwing
Gegevensassets van het type Tabel (MLTable) worden momenteel niet ondersteund.
Maak eerst de gegevensasset. Deze gegevensasset bestaat uit een map met meerdere CSV-bestanden die u parallel verwerkt met behulp van batcheindpunten. U kunt deze stap overslaan als uw gegevens al zijn geregistreerd als gegevensasset.
Een gegevensassetdefinitie maken in
YAML:heart-dataset-unlabeled.yml
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json name: heart-dataset-unlabeled description: An unlabeled dataset for heart classification. type: uri_folder path: heart-classifier-mlflow/dataMaak vervolgens de gegevensasset:
az ml data create -f heart-dataset-unlabeled.ymlMaak de invoer of aanvraag:
Voer het eindpunt uit:
Gebruik het
--setargument om de invoer op te geven:az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_dataset.type="uri_folder" inputs.heart_dataset.path=$DATASET_IDVoor een eindpunt dat een modelimplementatie dient, kunt u het
--inputargument gebruiken om de gegevensinvoer op te geven, omdat voor een modelimplementatie altijd slechts één gegevensinvoer is vereist.az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $DATASET_IDHet argument
--setproduceert meestal lange opdrachten wanneer meerdere invoerwaarden worden opgegeven. In dergelijke gevallen plaatst u uw invoer in eenYAMLbestand en gebruikt u het--fileargument om de invoer op te geven die u nodig hebt voor de aanroep van het eindpunt.inputs.yml
inputs: heart_dataset: azureml:/<datasset_name>@latestVoer de volgende opdracht uit:
az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.yml
Invoergegevens uit gegevensarchieven gebruiken
U kunt rechtstreeks verwijzen naar gegevens uit geregistreerde Azure Machine Learning-gegevensarchieven met batchimplementatietaken. In dit voorbeeld uploadt u eerst enkele gegevens naar het standaardgegevensarchief in de Azure Machine Learning-werkruimte en voert u er vervolgens een batchimplementatie op uit. Volg deze stappen om een batch-eindpunttaak uit te voeren met behulp van gegevens die zijn opgeslagen in een gegevensarchief.
Open het standaardgegevensarchief in de Azure Machine Learning-werkruimte. Als uw gegevens zich in een ander archief bevinden, kunt u die opslag gebruiken. U hoeft het standaardgegevensarchief niet te gebruiken.
DATASTORE_ID=$(az ml datastore show -n workspaceblobstore | jq -r '.id')De id van de gegevensarchieven ziet er als volgt
/subscriptions/<subscription>/resourceGroups/<resource-group>/providers/Microsoft.MachineLearningServices/workspaces/<workspace>/datastores/<data-store>uit.Tip
Het standaard-blobgegevensarchief in een werkruimte heet workspaceblobstore. U kunt deze stap overslaan als u de resource-id van het standaardgegevensarchief in uw werkruimte al kent.
Upload enkele voorbeeldgegevens naar het gegevensarchief.
In dit voorbeeld wordt ervan uitgegaan dat u de voorbeeldgegevens die zijn opgenomen in de opslagplaats in de map
sdk/python/endpoints/batch/deploy-models/heart-classifier-mlflow/datain de mapheart-disease-uci-unlabeledin het Blob Storage-account al hebt geüpload. Zorg ervoor dat u deze stap voltooit voordat u doorgaat.Maak de invoer of aanvraag:
Plaats het bestandspad in de
INPUT_PATHvariabele:DATA_PATH="heart-disease-uci-unlabeled" INPUT_PATH="$DATASTORE_ID/paths/$DATA_PATH"U ziet hoe de
pathsvariabele voor het pad wordt toegevoegd aan de resource-id van het gegevensarchief. Deze indeling geeft aan dat de volgende waarde een pad is.Tip
U kunt ook de indeling
azureml://datastores/<data-store>/paths/<data-path>gebruiken om de invoer op te geven.Voer het eindpunt uit:
Gebruik het
--setargument om de invoer op te geven:az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_dataset.type="uri_folder" inputs.heart_dataset.path=$INPUT_PATHVoor een eindpunt dat een modelimplementatie dient, kunt u het
--inputargument gebruiken om de gegevensinvoer op te geven, omdat voor een modelimplementatie altijd slechts één gegevensinvoer is vereist.az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $INPUT_PATH --input-type uri_folderHet argument
--setproduceert meestal lange opdrachten wanneer meerdere invoerwaarden worden opgegeven. In dergelijke gevallen plaatst u uw invoer in eenYAMLbestand en gebruikt u het--fileargument om de invoer op te geven die u nodig hebt voor de aanroep van het eindpunt.inputs.yml
inputs: heart_dataset: type: uri_folder path: azureml://datastores/<data-store>/paths/<data-path>Voer de volgende opdracht uit:
az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.ymlAls uw gegevens een bestand zijn, gebruikt u in plaats daarvan het
uri_filetype voor de invoer.
Invoergegevens van Azure Storage-accounts gebruiken
Azure Machine Learning-batcheindpunten kunnen gegevens lezen uit cloudlocaties in Azure Storage-accounts, zowel openbaar als privé. Gebruik de volgende stappen om een batch-eindpunttaak uit te voeren met gegevens die zijn opgeslagen in een opslagaccount.
Zie Rekenclusters configureren voor gegevenstoegang voor meer informatie over extra vereiste configuratie voor het lezen van gegevens uit opslagaccounts.
Maak de invoer of aanvraag:
Stel de
INPUT_DATAvariabele in:INPUT_DATA = "https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data"Als uw gegevens een bestand zijn, stelt u de variabele in met de volgende indeling:
INPUT_DATA = "https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data/heart.csv"Voer het eindpunt uit:
Gebruik het
--setargument om de invoer op te geven:az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_dataset.type="uri_folder" inputs.heart_dataset.path=$INPUT_DATAVoor een eindpunt dat een modelimplementatie dient, kunt u het
--inputargument gebruiken om de gegevensinvoer op te geven, omdat voor een modelimplementatie altijd slechts één gegevensinvoer is vereist.az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $INPUT_DATA --input-type uri_folderHet
--setargument produceert meestal lange opdrachten wanneer meerdere invoerwaarden worden opgegeven. In dergelijke gevallen plaatst u uw invoer in eenYAMLbestand en gebruikt u het--fileargument om de invoer op te geven die u nodig hebt voor de aanroep van het eindpunt.inputs.yml
inputs: heart_dataset: type: uri_folder path: https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/dataVoer de volgende opdracht uit:
az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.ymlAls uw gegevens een bestand zijn, gebruikt u in plaats daarvan het
uri_filetype voor de invoer.
Taken maken met letterlijke invoer
Implementaties van pijplijnonderdelen kunnen letterlijke invoer aannemen. In het volgende voorbeeld ziet u hoe u een invoer met de naam score_mode, van het type string, met de waarde :append
Plaats uw invoer in een YAML bestand en gebruik --file deze om de invoer op te geven die u nodig hebt voor de aanroep van het eindpunt.
inputs.yml
inputs:
score_mode:
type: string
default: append
Voer de volgende opdracht uit:
az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.yml
U kunt ook het --set argument gebruiken om de waarde op te geven. Deze benadering produceert echter vaak lange opdrachten wanneer meerdere invoerwaarden zijn opgegeven:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--set inputs.score_mode.type="string" inputs.score_mode.default="append"
Taken maken met gegevensuitvoer
In het volgende voorbeeld ziet u hoe u de locatie wijzigt waar een uitvoer met de naam score wordt geplaatst. Voor volledigheid configureren deze voorbeelden ook een invoer met de naam heart_dataset.
Sla de uitvoer op met behulp van het standaardgegevensarchief in de Azure Machine Learning-werkruimte. U kunt elk ander gegevensarchief in uw werkruimte gebruiken zolang het een Blob Storage-account is.
DATASTORE_ID=$(az ml datastore show -n workspaceblobstore | jq -r '.id')De id van de gegevensarchieven ziet er als volgt
/subscriptions/<subscription>/resourceGroups/<resource-group>/providers/Microsoft.MachineLearningServices/workspaces/<workspace>/datastores/<data-store>uit.Een gegevensuitvoer maken:
Stel de
OUTPUT_PATHvariabele in:DATA_PATH="batch-jobs/my-unique-path" OUTPUT_PATH="$DATASTORE_ID/paths/$DATA_PATH"Maak voor volledigheid ook een gegevensinvoer:
INPUT_PATH="https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data"Notitie
U ziet hoe de
pathsvariabele voor het pad wordt toegevoegd aan de resource-id van het gegevensarchief. Deze indeling geeft aan dat de volgende waarde een pad is.Voer de implementatie uit: