Batch-eindpunten uitvoeren vanuit Azure Data Factory
VAN TOEPASSING OP: Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
Voor big data is een service nodig die het organiseren en het operationeel maken van processen mogelijk maakt om deze enorme hoeveelheden onbewerkte gegevens om te zetten naar bruikbare zakelijke inzichten. De beheerde Azure Data Factory-cloudservice verwerkt deze complexe projecten voor hybride extract-transform-load (ETL), extract-load-transform (ELT) en gegevensintegratieprojecten.
Met Azure Data Factory kunt u pijplijnen maken waarmee u meerdere gegevenstransformaties kunt organiseren en deze als één eenheid kunt beheren. Batch-eindpunten zijn een uitstekende kandidaat om een stap te worden in een dergelijke verwerkingswerkstroom.
In dit artikel leert u hoe u batch-eindpunten gebruikt in Azure Data Factory-activiteiten door te vertrouwen op de web-aanroepactiviteit en de REST API.
Tip
Wanneer u gegevenspijplijnen in Fabric gebruikt, kunt u het batch-eindpunt rechtstreeks aanroepen met behulp van de Azure Machine Learning-activiteit. We raden u aan fabric te gebruiken voor gegevensindeling, indien mogelijk, om te profiteren van de nieuwste mogelijkheden. De Azure Machine Learning-activiteit in Azure Data Factory kan alleen werken met assets van Azure Machine Learning V1. Zie Azure Machine Learning-modellen uitvoeren vanuit Fabric met behulp van batcheindpunten (preview) voor meer informatie.
Vereisten
Een model dat is geïmplementeerd als een batch-eindpunt. Gebruik de heart condition-classificatie die is gemaakt in MLflow-modellen gebruiken in batchimplementaties.
Een Azure Data Factory-resource. Als u een data factory wilt maken, volgt u de stappen in quickstart: Een gegevensfactory maken met behulp van Azure Portal.
Nadat u uw data factory hebt gemaakt, bladert u ernaar in Azure Portal en selecteert u Launch Studio:


Verifiëren op basis van batch-eindpunten
Azure Data Factory kan de REST API's van batcheindpunten aanroepen met behulp van de web-aanroepactiviteit . Batch-eindpunten ondersteunen Microsoft Entra-id voor autorisatie en de aanvraag die aan de API's wordt gedaan, vereisen een juiste verificatieafhandeling. Zie Webactiviteit in Azure Data Factory en Azure Synapse Analytics voor meer informatie.
U kunt een service-principal of een beheerde identiteit gebruiken om te verifiëren bij batch-eindpunten. U wordt aangeraden een beheerde identiteit te gebruiken, omdat het gebruik van geheimen wordt vereenvoudigd.
U kunt de beheerde identiteit van Azure Data Factory gebruiken om te communiceren met batch-eindpunten. In dit geval hoeft u alleen te controleren of uw Azure Data Factory-resource is geïmplementeerd met een beheerde identiteit.
Als u geen Azure Data Factory-resource hebt of als deze al is geïmplementeerd zonder een beheerde identiteit, volgt u deze procedure om deze te maken: Door het systeem toegewezen beheerde identiteit.
Let op
Het is niet mogelijk om na de implementatie de resource-id in Azure Data Factory te wijzigen. Als u de identiteit van een resource wilt wijzigen nadat u deze hebt gemaakt, moet u de resource opnieuw maken.
Na de implementatie verleent u toegang tot de beheerde identiteit van de resource die u hebt gemaakt voor uw Azure Machine Learning-werkruimte. Zie Toegang verlenen. In dit voorbeeld is voor de service-principal het volgende vereist:
- Machtiging in de werkruimte om batchimplementaties te lezen en acties uit te voeren.
- Machtigingen voor lezen/schrijven in gegevensarchieven.
- Machtigingen voor het lezen in een cloudlocatie (opslagaccount) die worden aangegeven als gegevensinvoer.
Over de pijplijn
In dit voorbeeld maakt u een pijplijn in Azure Data Factory waarmee een bepaald batcheindpunt kan worden aangeroepen voor bepaalde gegevens. De pijplijn communiceert met Azure Machine Learning-batcheindpunten met behulp van REST. Zie Taken en invoergegevens maken voor batch-eindpunten voor batcheindpunten voor meer informatie over het gebruik van de REST API van batcheindpunten.
De pijplijn ziet er als volgt uit:

De pijplijn bevat de volgende activiteiten:
Batch-eindpunt uitvoeren: een webactiviteit die gebruikmaakt van de batch-eindpunt-URI om deze aan te roepen. De invoergegevens-URI wordt doorgegeven waar de gegevens zich bevinden en het verwachte uitvoerbestand.
Wacht op taak: het is een lusactiviteit die de status van de gemaakte taak controleert en wacht totdat de taak is voltooid, hetzij als Voltooid of Mislukt. Deze activiteit gebruikt op zijn beurt de volgende activiteiten:
- Status controleren: een webactiviteit die de status van de taakresource opvraagt die is geretourneerd als reactie op de activiteit Batch-eindpunt uitvoeren.
- Wacht: Een wachtactiviteit waarmee de pollingfrequentie van de status van de taak wordt beheerd. We stellen een standaardwaarde van 120 (2 minuten) in.
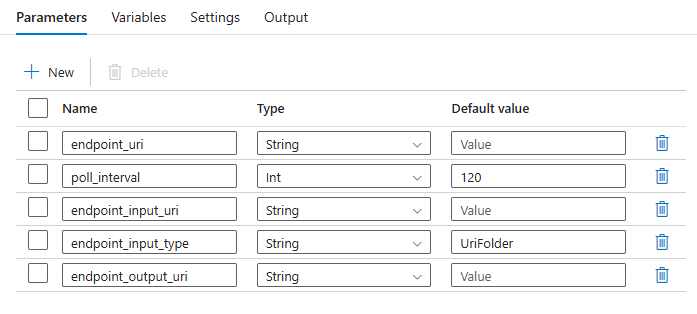
Voor de pijplijn moet u de volgende parameters configureren:
| Parameter | Description | Voorbeeldwaarde |
|---|---|---|
endpoint_uri |
De score-URI voor eindpunten | https://<endpoint_name>.<region>.inference.ml.azure.com/jobs |
poll_interval |
Het aantal seconden dat moet worden gewacht voordat de taakstatus wordt gecontroleerd op voltooiing. Standaard ingesteld op 120. |
120 |
endpoint_input_uri |
De invoergegevens van het eindpunt. Er worden meerdere typen gegevensinvoer ondersteund. Zorg ervoor dat de beheerde identiteit die u gebruikt om de taak uit te voeren, toegang heeft tot de onderliggende locatie. Als u gegevensarchieven gebruikt, moet u er ook voor zorgen dat de referenties daar worden aangegeven. | azureml://datastores/.../paths/.../data/ |
endpoint_input_type |
Het type invoergegevens dat u oplevert. Momenteel ondersteunen batch-eindpunten mappen (UriFolder) en Bestand (UriFile). Standaard ingesteld op UriFolder. |
UriFolder |
endpoint_output_uri |
Het uitvoergegevensbestand van het eindpunt. Het moet een pad naar een uitvoerbestand zijn in een gegevensarchief dat is gekoppeld aan de Machine Learning-werkruimte. Er wordt geen ander type URI's ondersteund. U kunt het standaardgegevensarchief van Azure Machine Learning, met de naam workspaceblobstore. |
azureml://datastores/workspaceblobstore/paths/batch/predictions.csv |

Waarschuwing
Vergeet niet dat dit endpoint_output_uri het pad naar een bestand moet zijn dat nog niet bestaat. Anders mislukt de taak met de fout dat het pad al bestaat.
Maak de pijplijn
Volg deze stappen om deze pijplijn te maken in uw bestaande Azure Data Factory en batcheindpunten aan te roepen:
Zorg ervoor dat de berekening waarop het batch-eindpunt wordt uitgevoerd, machtigingen heeft om de gegevens te koppelen die Azure Data Factory als invoer biedt. De entiteit die het eindpunt aanroept, verleent nog steeds toegang.
In dit geval is het Azure Data Factory. De berekening waarin het batch-eindpunt wordt uitgevoerd, moet echter zijn gemachtigd om het opslagaccount te koppelen dat uw Azure Data Factory biedt. Zie Toegang tot opslagservices voor meer informatie.
Open Azure Data Factory Studio. Selecteer het potloodpictogram om het deelvenster Auteur te openen en selecteer onder Factory-resources het plusteken.
Selecteer Pijplijn>importeren uit pijplijnsjabloon.
Selecteer een .zip-bestand .
- Als u beheerde identiteiten wilt gebruiken, selecteert u dit bestand.
- Als u een service-principe wilt gebruiken, selecteert u dit bestand.
Er wordt een voorbeeld van de pijplijn weergegeven in de portal. Selecteer Deze sjabloon gebruiken.
De pijplijn wordt voor u gemaakt met de naam Run-BatchEndpoint.
Configureer de parameters van de batchimplementatie:
Waarschuwing
Zorg ervoor dat uw batch-eindpunt een standaardimplementatie heeft geconfigureerd voordat u een taak naar het eindpunt verzendt. De gemaakte pijplijn roept het eindpunt aan. Er moet een standaardimplementatie worden gemaakt en geconfigureerd.
Tip
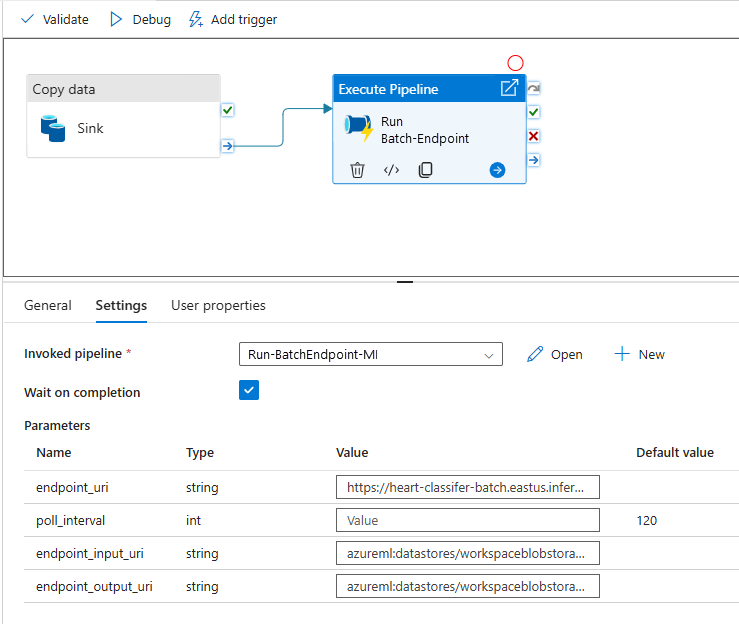
Voor de beste herbruikbaarheid gebruikt u de gemaakte pijplijn als sjabloon en roept u deze aan vanuit andere Azure Data Factory-pijplijnen met behulp van de pijplijnactiviteit Uitvoeren. In dat geval configureert u de parameters in de binnenste pijplijn niet, maar geeft u ze door als parameters van de buitenste pijplijn, zoals wordt weergegeven in de volgende afbeelding:
Uw pijplijn is klaar voor gebruik.
Beperkingen
Houd rekening met de volgende beperkingen wanneer u Azure Machine Learning-batchimplementaties gebruikt:
Gegevensinvoer
- Alleen Azure Machine Learning-gegevensarchieven of Azure Storage-accounts (Azure Blob Storage, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2) worden ondersteund als invoer. Als uw invoergegevens zich in een andere bron bevinden, gebruikt u de Azure Data Factory-Copy-activiteit voordat u de batchtaak uitvoert om de gegevens naar een compatibel archief te sinken.
- Batch-eindpunttaken verkennen geen geneste mappen. Ze kunnen niet werken met geneste mapstructuren. Als uw gegevens in meerdere mappen worden gedistribueerd, moet u de structuur platmaken.
- Zorg ervoor dat uw scorescript dat is opgegeven in de implementatie de gegevens kan verwerken zoals verwacht wordt ingevoerd in de taak. Als het model MLflow is, raadpleegt u MLflow-modellen implementeren in batchimplementaties voor de beperkingen voor ondersteunde bestandstypen.
Gegevensuitvoer
- Alleen geregistreerde Azure Machine Learning-gegevensarchieven worden ondersteund. U wordt aangeraden het opslagaccount te registreren dat uw Azure Data Factory gebruikt als een gegevensarchief in Azure Machine Learning. Op die manier kunt u terugschrijven naar hetzelfde opslagaccount waar u leest.
- Alleen Azure Blob Storage-accounts worden ondersteund voor uitvoer. Azure Data Lake Storage Gen2 wordt bijvoorbeeld niet ondersteund als uitvoer in batchimplementatietaken. Als u de gegevens naar een andere locatie of sink wilt uitvoeren, gebruikt u de Azure Data Factory-Copy-activiteit nadat u de batchtaak hebt uitgevoerd.