Autorisatie op batch-eindpunten
Batch-eindpunten ondersteunen Microsoft Entra-verificatie of aad_token. Dit betekent dat de gebruiker een batch-eindpunt moet aanroepen door een geldig Microsoft Entra-verificatietoken te presenteren aan de URI van het batch-eindpunt. Autorisatie wordt afgedwongen op eindpuntniveau. In het volgende artikel wordt uitgelegd hoe u correct kunt communiceren met batch-eindpunten en de beveiligingsvereisten hiervoor.
Hoe autorisatie werkt
Als u een batch-eindpunt wilt aanroepen, moet de gebruiker een geldig Microsoft Entra-token presenteren dat een beveiligingsprincipal vertegenwoordigt. Deze principal kan een gebruikers-principal of een service-principal zijn. Wanneer een eindpunt is aangeroepen, wordt er in elk geval een batchimplementatietaak gemaakt onder de identiteit die is gekoppeld aan het token. De identiteit heeft de volgende machtigingen nodig om een taak te kunnen maken:
- Batch-eindpunten/implementaties lezen.
- Taken maken in batchdeductie-eindpunten/-implementatie.
- Experimenten/uitvoeringen maken.
- Lezen en schrijven van/naar gegevensarchieven.
- Een lijst met geheimen voor het gegevensarchief.
Zie RBAC configureren voor aanroepen van batcheindpunten voor een gedetailleerde lijst met RBAC-machtigingen.
Belangrijk
De identiteit die wordt gebruikt voor het aanroepen van een batch-eindpunt, kan niet worden gebruikt om de onderliggende gegevens te lezen, afhankelijk van de configuratie van het gegevensarchief. Zie Rekenclusters configureren voor gegevenstoegang voor meer informatie.
Taken uitvoeren met verschillende typen referenties
In de volgende voorbeelden ziet u verschillende manieren om batchimplementatietaken te starten met behulp van verschillende typen referenties:
Belangrijk
Wanneer u werkt aan werkruimten met private link-functionaliteit, kunnen batcheindpunten niet worden aangeroepen vanuit de gebruikersinterface in Azure Machine Learning-studio. Gebruik in plaats daarvan de Azure Machine Learning CLI v2 voor het maken van taken.
Vereisten
- In dit voorbeeld wordt ervan uitgegaan dat u een model correct hebt geïmplementeerd als een batch-eindpunt. In het bijzonder gebruiken we de classificatie heart condition die is gemaakt in de zelfstudie MLflow-modellen gebruiken in batchimplementaties.
Taken uitvoeren met de referenties van de gebruiker
In dit geval willen we een batch-eindpunt uitvoeren met behulp van de identiteit van de gebruiker die momenteel is aangemeld. Volg vervolgens deze stappen:
Gebruik de Azure CLI om u aan te melden met behulp van interactieve verificatie of verificatie van apparaatcode:
az loginNadat de verificatie is uitgevoerd, gebruikt u de volgende opdracht om een batchimplementatietaak uit te voeren:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci
Taken uitvoeren met behulp van een service-principal
In dit geval willen we een batch-eindpunt uitvoeren met behulp van een service-principal die al is gemaakt in Microsoft Entra-id. Als u de verificatie wilt voltooien, moet u een geheim maken om de verificatie uit te voeren. Volg vervolgens deze stappen:
Maak een geheim dat moet worden gebruikt voor verificatie, zoals wordt uitgelegd bij optie 3: Een nieuw clientgeheim maken.
Gebruik de volgende opdracht om te verifiëren met behulp van een service-principal. Zie Aanmelden met Azure CLI voor meer informatie.
az login --service-principal \ --tenant <tenant> \ -u <app-id> \ -p <password-or-cert>Nadat de verificatie is uitgevoerd, gebruikt u de volgende opdracht om een batchimplementatietaak uit te voeren:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/
Taken uitvoeren met een beheerde identiteit
U kunt beheerde identiteiten gebruiken om batcheindpunten en implementaties aan te roepen. U ziet dat deze beheerde identiteit niet tot het batch-eindpunt behoort, maar het is de identiteit die wordt gebruikt om het eindpunt uit te voeren en daarom een batchtaak te maken. In dit scenario kunnen zowel door de gebruiker toegewezen identiteiten als door het systeem toegewezen identiteiten worden gebruikt.
U kunt u bij resources die zijn geconfigureerd voor beheerde identiteiten voor Azure-resources, aanmelden met behulp van de beheerde identiteit. Aanmelden via de identiteit van de resource verloopt via de vlag --identity. Zie Aanmelden met Azure CLI voor meer informatie.
az login --identity
Nadat de verificatie is uitgevoerd, gebruikt u de volgende opdracht om een batchimplementatietaak uit te voeren:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci
RBAC configureren voor aanroepen van Batch-eindpunten
Batch-eindpunten maken een duurzame API-gebruikers beschikbaar voor het genereren van taken. De aanroeper vraagt de juiste machtiging aan om deze taken te kunnen genereren. U kunt een van de ingebouwde beveiligingsrollen gebruiken of u kunt een aangepaste rol maken voor de doeleinden.
Als u een batcheindpunt wilt aanroepen, hebt u de volgende expliciete acties nodig die zijn verleend aan de identiteit die wordt gebruikt om de eindpunten aan te roepen. Zie Stappen voor het toewijzen van een Azure-rol voor instructies om deze toe te wijzen.
"actions": [
"Microsoft.MachineLearningServices/workspaces/read",
"Microsoft.MachineLearningServices/workspaces/data/versions/write",
"Microsoft.MachineLearningServices/workspaces/datasets/registered/read",
"Microsoft.MachineLearningServices/workspaces/datasets/registered/write",
"Microsoft.MachineLearningServices/workspaces/datasets/unregistered/read",
"Microsoft.MachineLearningServices/workspaces/datasets/unregistered/write",
"Microsoft.MachineLearningServices/workspaces/datastores/read",
"Microsoft.MachineLearningServices/workspaces/datastores/write",
"Microsoft.MachineLearningServices/workspaces/datastores/listsecrets/action",
"Microsoft.MachineLearningServices/workspaces/listStorageAccountKeys/action",
"Microsoft.MachineLearningServices/workspaces/batchEndpoints/read",
"Microsoft.MachineLearningServices/workspaces/batchEndpoints/write",
"Microsoft.MachineLearningServices/workspaces/batchEndpoints/deployments/read",
"Microsoft.MachineLearningServices/workspaces/batchEndpoints/deployments/write",
"Microsoft.MachineLearningServices/workspaces/batchEndpoints/deployments/jobs/write",
"Microsoft.MachineLearningServices/workspaces/batchEndpoints/jobs/write",
"Microsoft.MachineLearningServices/workspaces/computes/read",
"Microsoft.MachineLearningServices/workspaces/computes/listKeys/action",
"Microsoft.MachineLearningServices/workspaces/metadata/secrets/read",
"Microsoft.MachineLearningServices/workspaces/metadata/snapshots/read",
"Microsoft.MachineLearningServices/workspaces/metadata/artifacts/read",
"Microsoft.MachineLearningServices/workspaces/metadata/artifacts/write",
"Microsoft.MachineLearningServices/workspaces/experiments/read",
"Microsoft.MachineLearningServices/workspaces/experiments/runs/submit/action",
"Microsoft.MachineLearningServices/workspaces/experiments/runs/read",
"Microsoft.MachineLearningServices/workspaces/experiments/runs/write",
"Microsoft.MachineLearningServices/workspaces/metrics/resource/write",
"Microsoft.MachineLearningServices/workspaces/modules/read",
"Microsoft.MachineLearningServices/workspaces/models/read",
"Microsoft.MachineLearningServices/workspaces/endpoints/pipelines/read",
"Microsoft.MachineLearningServices/workspaces/endpoints/pipelines/write",
"Microsoft.MachineLearningServices/workspaces/environments/read",
"Microsoft.MachineLearningServices/workspaces/environments/write",
"Microsoft.MachineLearningServices/workspaces/environments/build/action",
"Microsoft.MachineLearningServices/workspaces/environments/readSecrets/action"
]
Rekenclusters configureren voor gegevenstoegang
Batch-eindpunten zorgen ervoor dat alleen geautoriseerde gebruikers batchimplementaties kunnen aanroepen en taken kunnen genereren. Afhankelijk van hoe de invoergegevens zijn geconfigureerd, kunnen andere referenties echter worden gebruikt om de onderliggende gegevens te lezen. Gebruik de volgende tabel om te begrijpen welke referenties worden gebruikt:
| Gegevensinvoertype | Referenties in het archief | Gebruikte referenties | Toegang verleend door |
|---|---|---|---|
| Gegevensopslag | Ja | De referenties van het gegevensarchief in de werkruimte | Toegangssleutel of SAS |
| Gegevensasset | Ja | De referenties van het gegevensarchief in de werkruimte | Toegangssleutel of SAS |
| Gegevensopslag | Nee | Identiteit van de taak + beheerde identiteit van het rekencluster | RBAC |
| Gegevensasset | Nee | Identiteit van de taak + beheerde identiteit van het rekencluster | RBAC |
| Azure Blob-opslag | Niet van toepassing | Identiteit van de taak + beheerde identiteit van het rekencluster | RBAC |
| Azure Data Lake Storage Gen1 | Niet van toepassing | Identiteit van de taak + beheerde identiteit van het rekencluster | POSIX |
| Azure Data Lake Storage Gen2 | Niet van toepassing | Identiteit van de taak + beheerde identiteit van het rekencluster | POSIX en RBAC |
Voor items in de tabel waarin de identiteit van de taak en beheerde identiteit van het rekencluster wordt weergegeven, wordt de beheerde identiteit van het rekencluster gebruikt voor het koppelen en configureren van opslagaccounts. De identiteit van de taak wordt echter nog steeds gebruikt om de onderliggende gegevens te lezen, zodat u gedetailleerd toegangsbeheer kunt bereiken. Dit betekent dat om gegevens uit de opslag te kunnen lezen, de beheerde identiteit van het rekencluster waarop de implementatie wordt uitgevoerd, ten minste toegang tot opslagblobgegevenslezer moet hebben tot het opslagaccount.
Voer de volgende stappen uit om het rekencluster voor gegevenstoegang te configureren:
Ga naar Azure Machine Learning-studio.
Navigeer naar Compute, vervolgens Compute-clusters en selecteer het rekencluster dat uw implementatie gebruikt.
Wijs een beheerde identiteit toe aan het rekencluster:
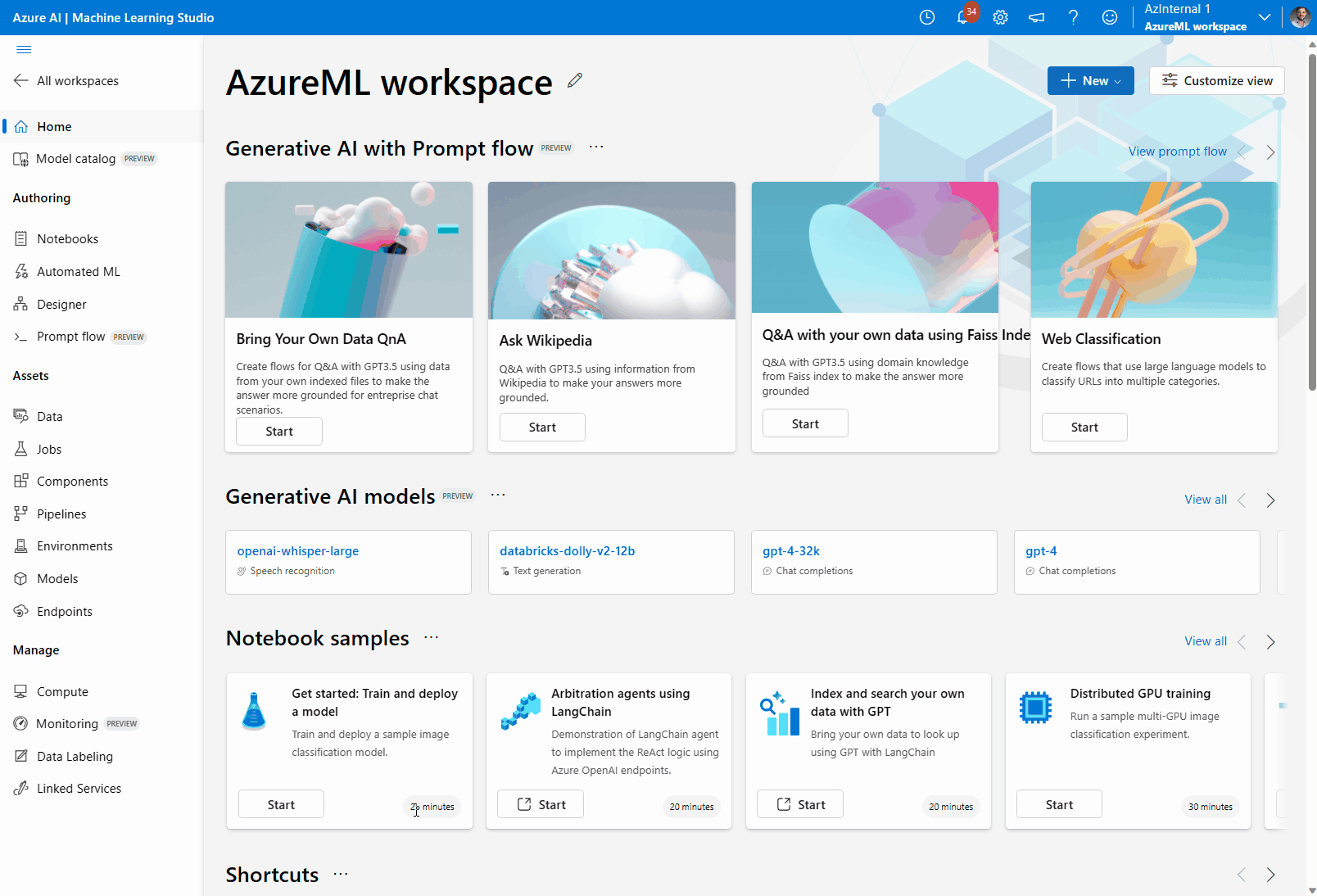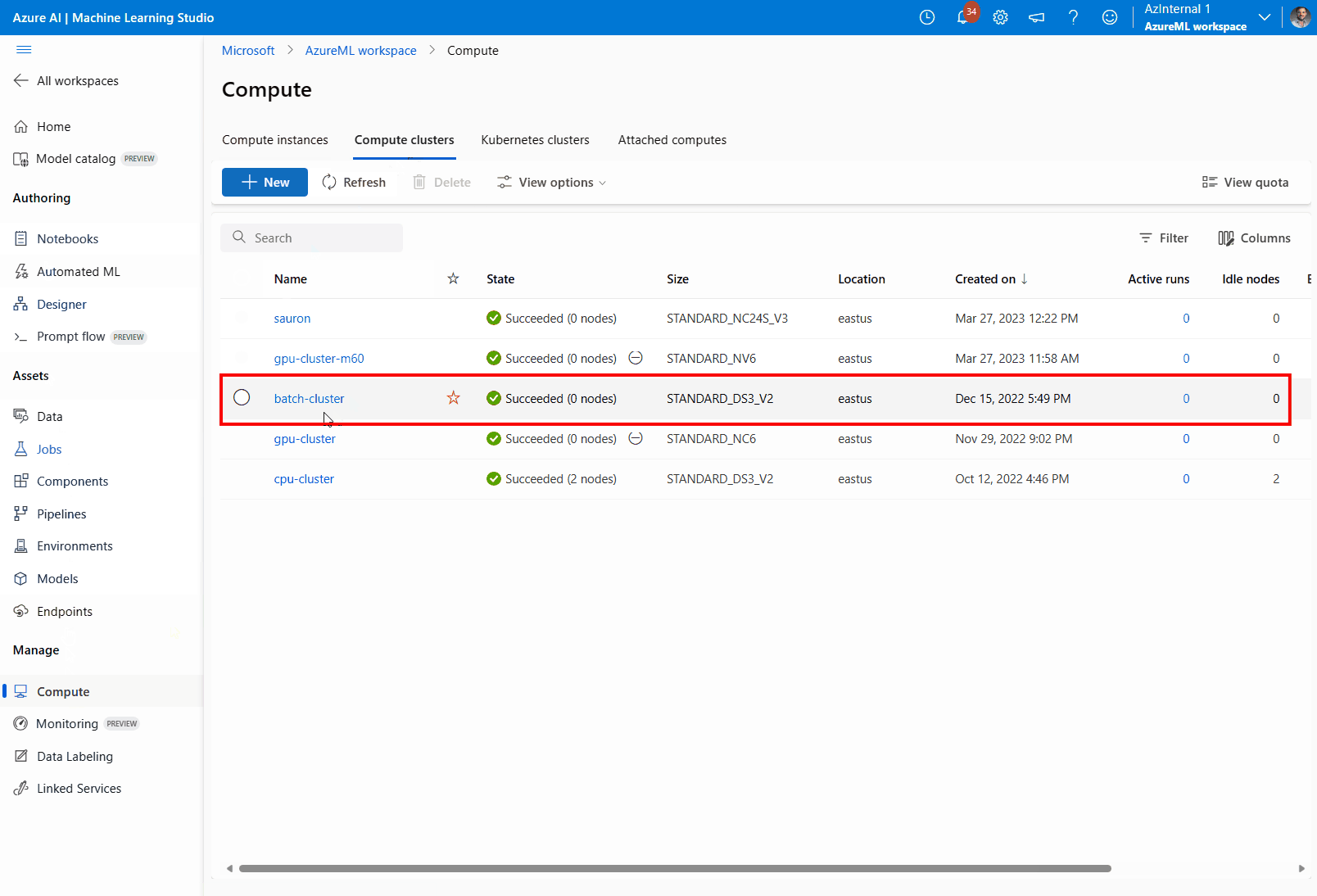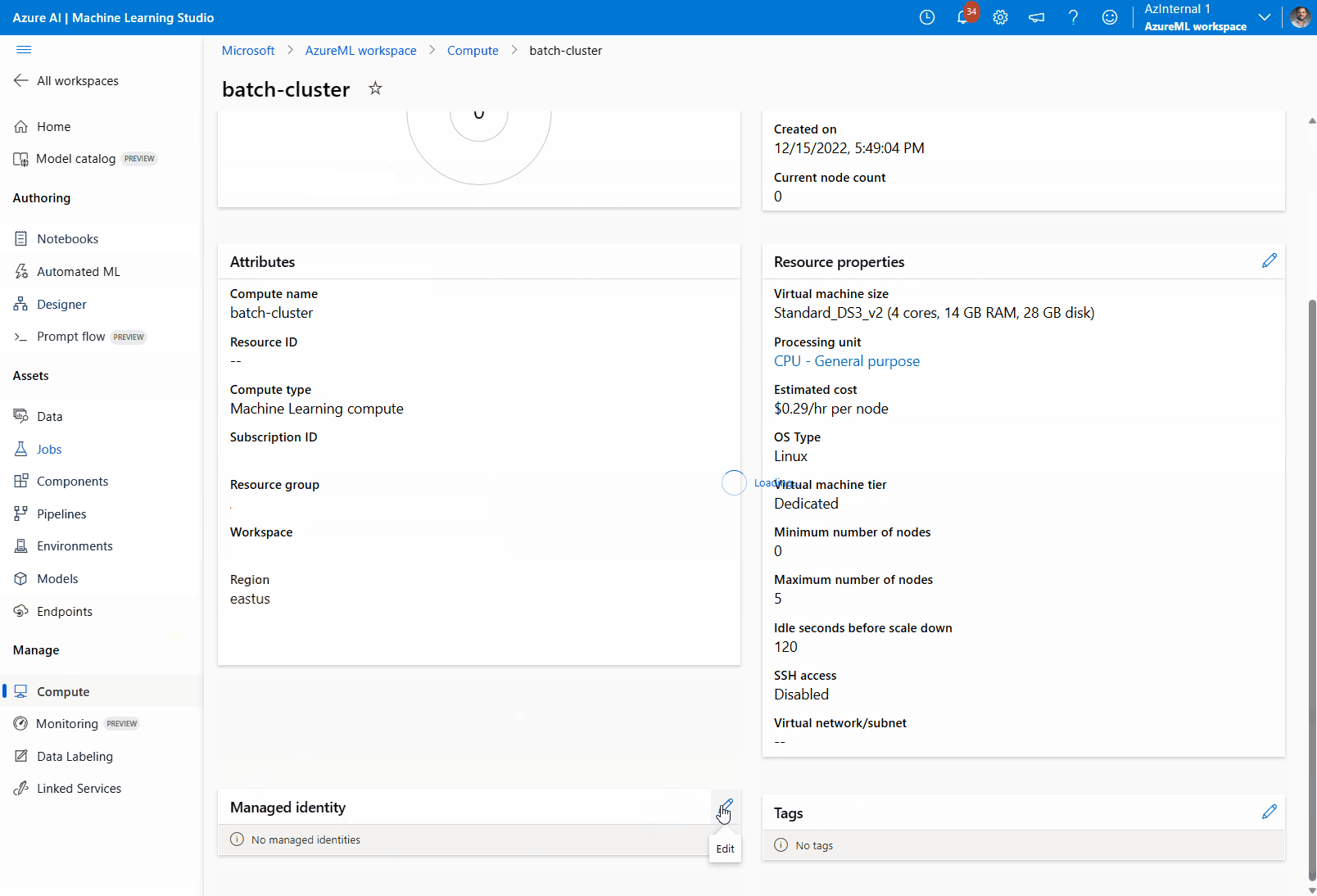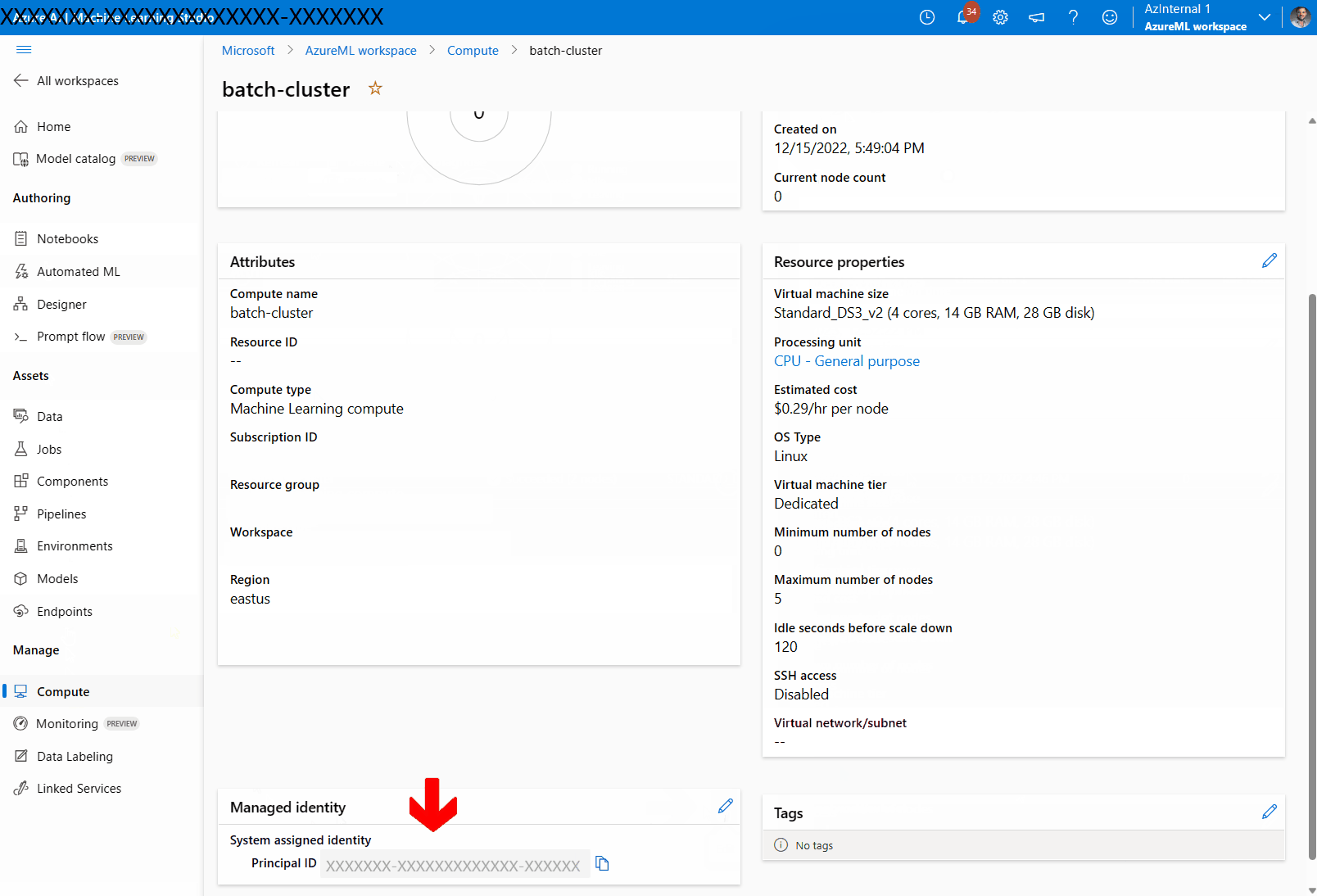
Controleer in de sectie Beheerde identiteit of aan de berekening een beheerde identiteit is toegewezen. Als dat niet het is, selecteert u de optie Bewerken.
Selecteer Een beheerde identiteit toewijzen en configureer deze indien nodig. U kunt een door het systeem toegewezen beheerde identiteit of een door de gebruiker toegewezen beheerde identiteit gebruiken. Als u een door het systeem toegewezen beheerde identiteit gebruikt, krijgt deze de naam [werkruimtenaam]/computes/[naam van het rekencluster]".
De wijzigingen opslaan.
Ga naar Azure Portal en navigeer naar het gekoppelde opslagaccount waar de gegevens zich bevinden. Als uw gegevensinvoer een gegevensasset of een gegevensarchief is, zoekt u naar het opslagaccount waarin deze assets worden geplaatst.
Toegangsniveau opslagblobgegevenslezer toewijzen in het opslagaccount:
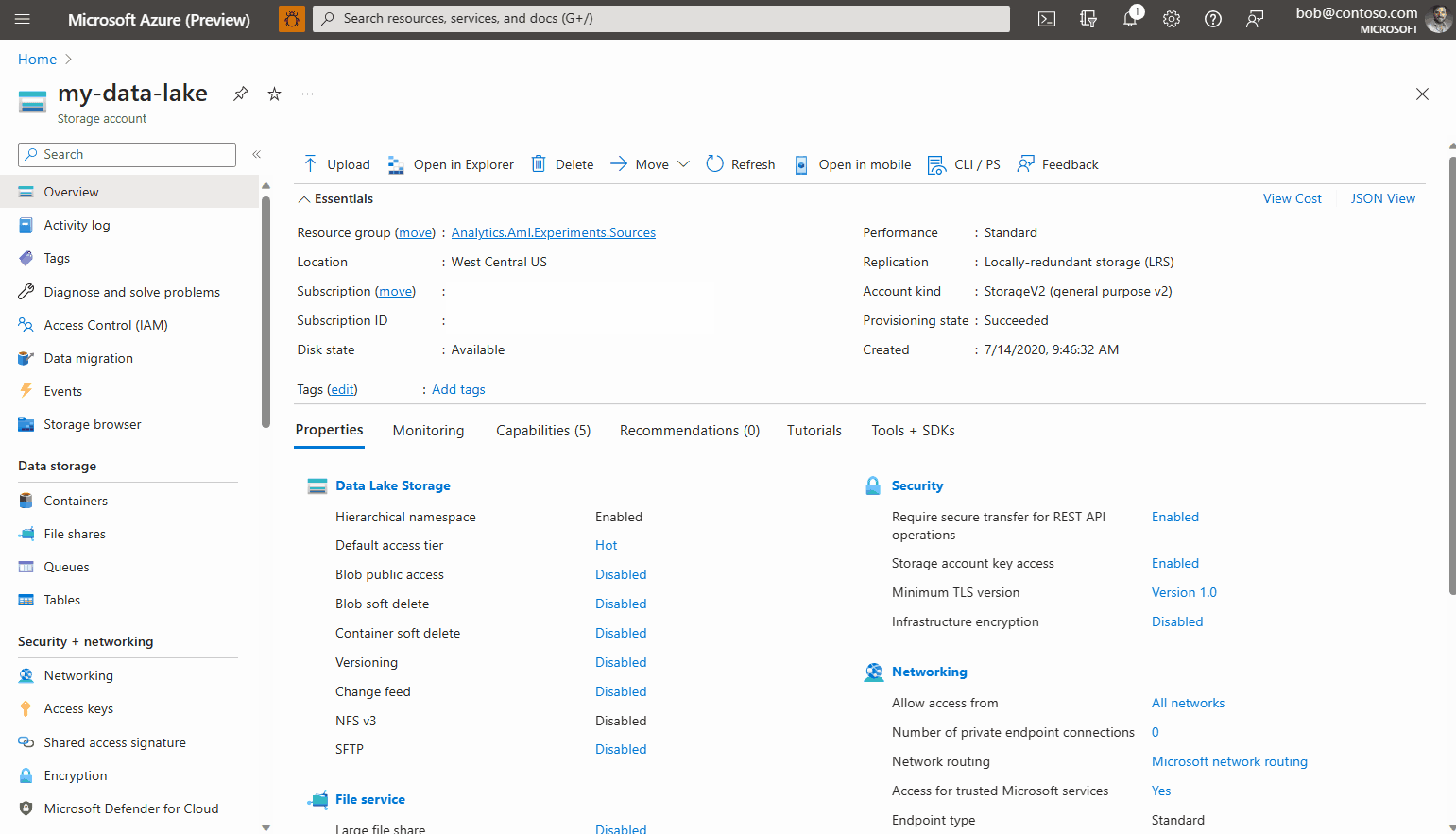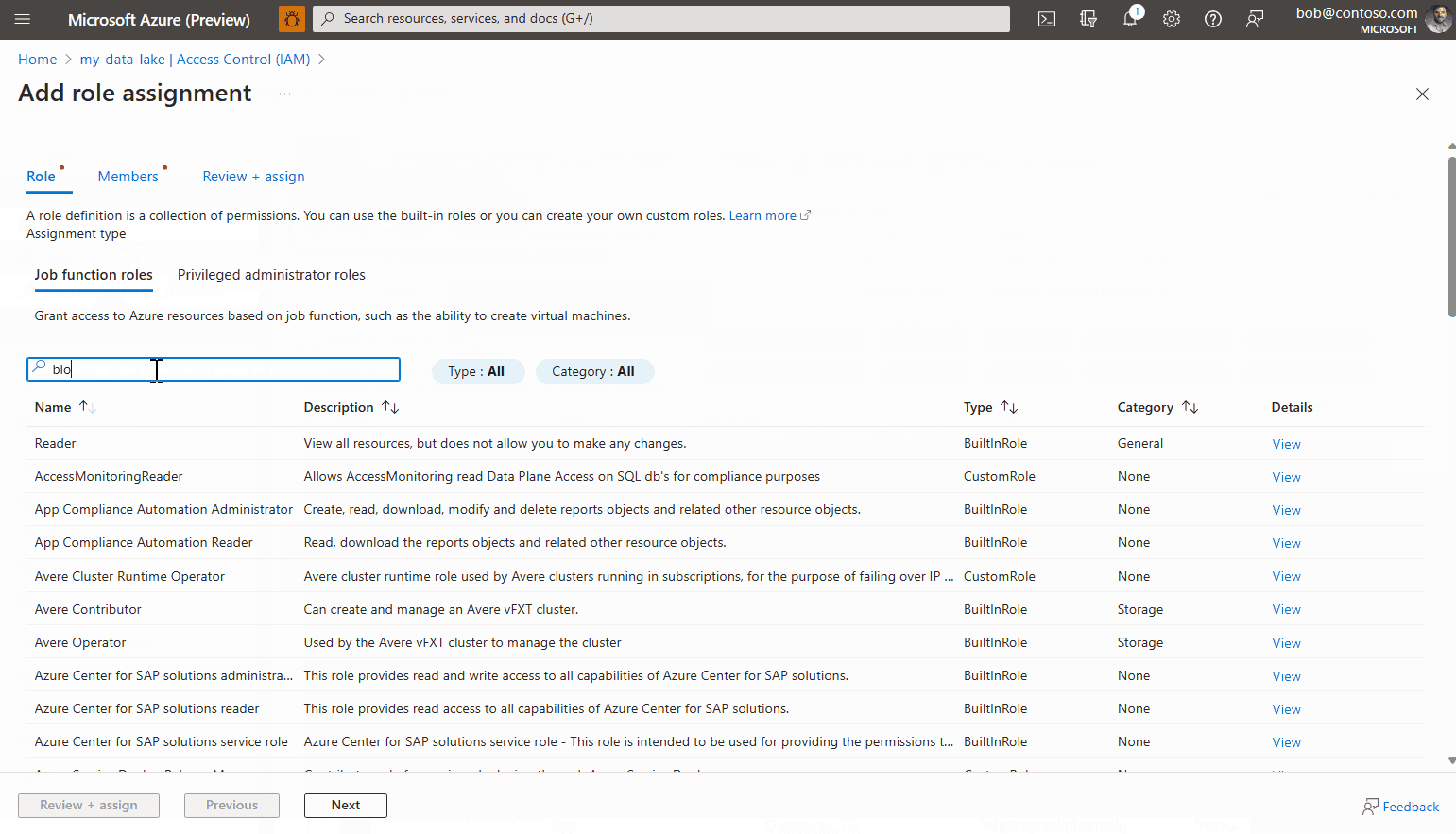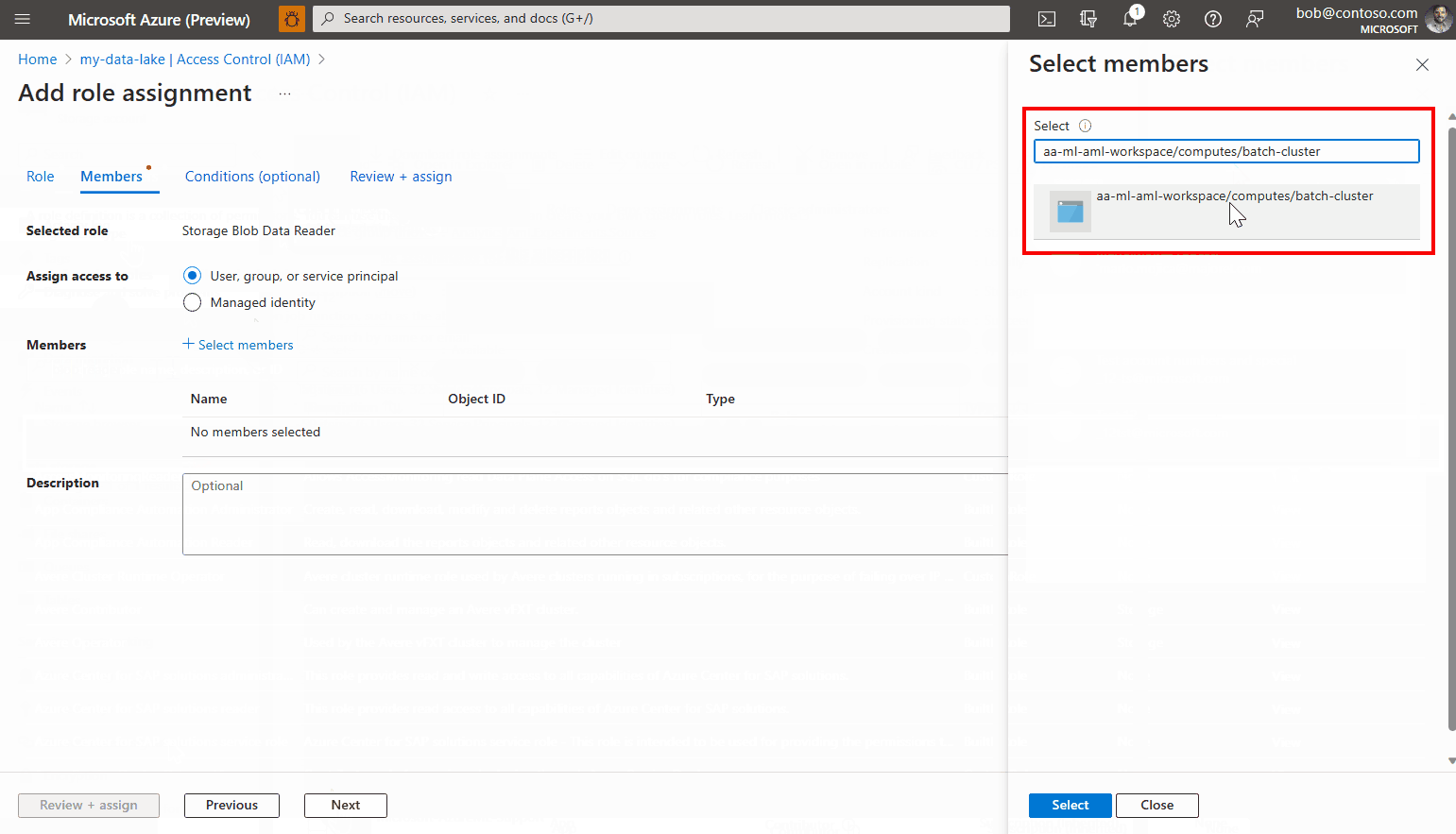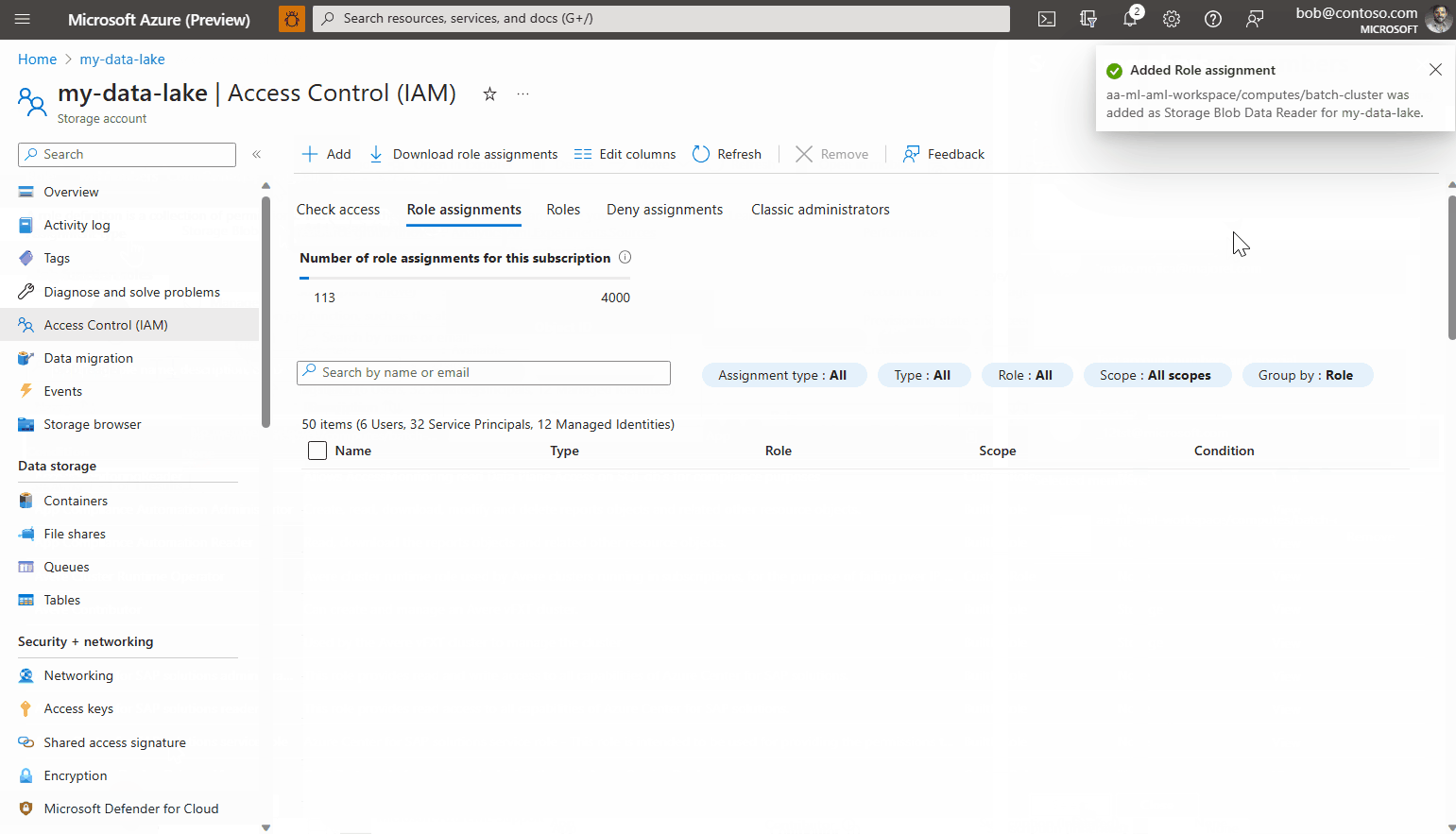
Ga naar de sectie Toegangsbeheer (IAM).
Selecteer het tabblad Roltoewijzing en klik vervolgens op Roltoewijzing toevoegen>.
Zoek de rol met de naam Storage Blob Data Reader, selecteer deze en klik op Volgende.
Klik op Leden selecteren.
Zoek naar de beheerde identiteit die u hebt gemaakt. Als u een door het systeem toegewezen beheerde identiteit gebruikt, krijgt deze de naam [werkruimtenaam]/computes/[naam van het rekencluster]".
Voeg het account toe en voltooi de wizard.
Uw eindpunt is klaar voor het ontvangen van taken en invoergegevens van het geselecteerde opslagaccount.