Rekenresources voor notebooks
In dit artikel worden de opties voor rekenresources van notebooks beschreven. U kunt een notebook uitvoeren op een rekenresource voor alle doeleinden, serverloze berekeningen of, voor SQL-opdrachten, kunt u een SQL-warehouse gebruiken, een type rekenproces dat is geoptimaliseerd voor SQL-analyses. Zie Computevoor meer informatie over rekentypen.
Serverloze rekenkracht voor notebooks
Met serverloze computing kunt u uw notebook snel verbinden met on-demand computingresources.
Als u wilt koppelen aan de serverloze berekening, klikt u op de vervolgkeuzelijst Verbinden in het notitieblok en selecteert u serverloze.
Zie Serverloze compute voor notebooks voor meer informatie.
een notebook koppelen aan een rekenresource voor alle doeleinden
Als u een notebook wilt koppelen aan een rekenresource voor alle doeleinden, hebt u de KAN KOPPELEN AAN machtiging voor de rekenresource.
Belangrijk
Zolang een notebook is gekoppeld aan een rekenresource, heeft elke gebruiker met de machtiging KAN UITVOEREN op het notebook impliciete machtigingen om toegang te krijgen tot de rekenresource.
Als u een notebook wilt koppelen aan een rekenresource, klikt u op de rekenkiezer op de werkbalk van het notitieblok en selecteert u de resource in de vervolgkeuzelijst.
In het menu ziet u een selectie van alle reken- en SQL-warehouses die u onlangs hebt gebruikt of die momenteel worden uitgevoerd.
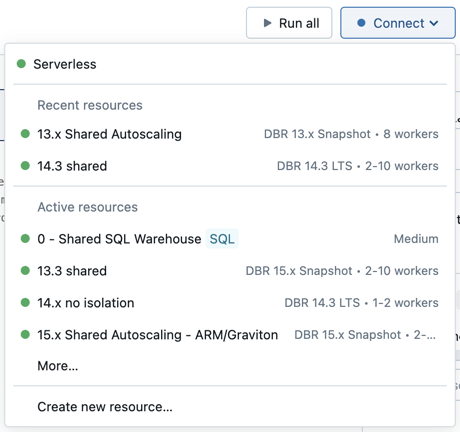
Als u een keuze wilt maken uit alle beschikbare berekeningen, klikt u op Meer.... Selecteer een van de beschikbare algemene reken- of SQL-magazijnen.
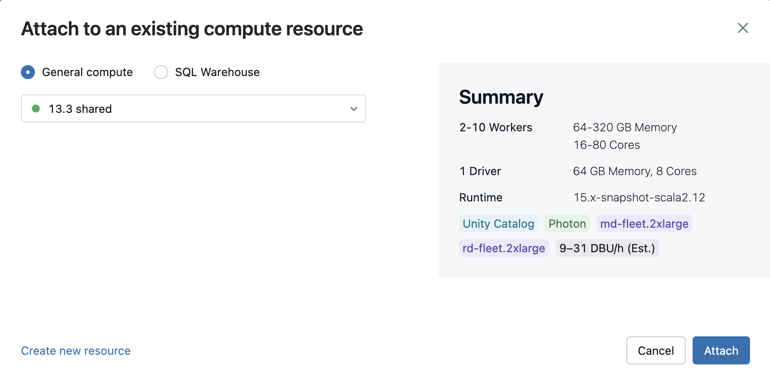
U kunt ook een nieuwe rekenresource voor alle doeleinden maken door Nieuwe resource maken te selecteren... in de vervolgkeuzelijst.
Belangrijk
Voor een gekoppeld notebook zijn de volgende Apache Spark-variabelen gedefinieerd.
| Klas | Variabelenaam |
|---|---|
SparkContext |
sc |
SQLContext/HiveContext |
sqlContext |
SparkSession (Spark 2.x) |
spark |
Maak SparkSessiongeen , SparkContextof SQLContext. Dit leidt tot inconsistent gedrag.
Een notebook gebruiken met een SQL-warehouse
Wanneer een notebook is gekoppeld aan een SQL-warehouse, kunt u SQL- en Markdown-cellen uitvoeren. Als u een cel uitvoert in een andere taal (zoals Python of R), treedt er een fout op. SQL-cellen die worden uitgevoerd op een SQL-magazijn, worden weergegeven in de querygeschiedenis van het SQL-warehouse. De gebruiker die een query heeft uitgevoerd, kan het queryprofiel uit het notebook bekijken door te klikken op het verstreken tijdstip onderaan de uitvoer.
Voor het uitvoeren van een notebook is een pro- of serverloze SQL Warehouse vereist. U moet toegang hebben tot de werkruimte en het SQL-warehouse.
Ga als volgt te werk om een notebook toe te voegen aan een SQL Warehouse :
Klik op de rekenkiezer op de werkbalk van het notitieblok. In de vervolgkeuzelijst ziet u rekenresources die momenteel worden uitgevoerd of die u onlangs hebt gebruikt. SQL-magazijnen zijn gemarkeerd met
 .
.Selecteer een SQL Warehouse in het menu.
Als u alle beschikbare SQL-magazijnen wilt zien, selecteert u Meer... in de vervolgkeuzelijst. Er wordt een dialoogvenster weergegeven met rekenresources die beschikbaar zijn voor het notebook. Selecteer SQL Warehouse-, kies het magazijn dat u wilt gebruiken en klik op koppelen.
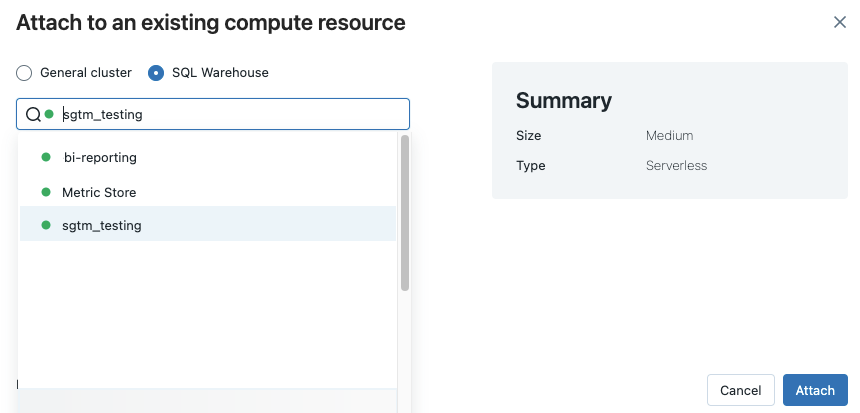
U kunt ook een SQL Warehouse selecteren als de rekenresource voor een SQL-notebook wanneer u een werkstroom of geplande taak maakt.
Beperkingen van SQL Warehouse
Zie Bekende beperkingen voor Databricks-notebooks voor meer informatie.
Een notitieblok loskoppelen
Als u een notebook wilt loskoppelen van een rekenresource, klikt u op de rekenkiezer op de werkbalk van het notitieblok en beweegt u de muisaanwijzer over de gekoppelde berekening in de lijst om een zijmenu weer te geven. In het zijmenu selecteer loskoppelen.
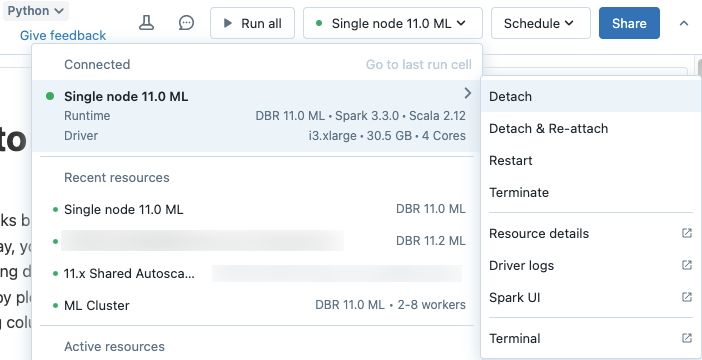
U kunt notebooks ook loskoppelen van een rekenresource voor alle doeleinden met behulp van het tabblad Notebooks op de detailpagina van de berekening.
Tip
Azure Databricks raadt u aan ongebruikte notebooks los te maken van rekenkracht. Hierdoor wordt geheugenruimte op het stuurprogramma vrijgemaakt.