Databricks Runtime voor Machine Learning
In dit artikel wordt Databricks Runtime voor Machine Learning beschreven en vindt u richtlijnen voor het maken van een cluster waarin het wordt gebruikt.
Wat is Databricks Runtime voor Machine Learning?
Databricks Runtime voor Machine Learning (Databricks Runtime ML) automatiseert het maken van een cluster met vooraf gebouwde machine learning- en deep learning-infrastructuur, waaronder de meest voorkomende ML- en DL-bibliotheken.
Bibliotheken die zijn opgenomen in Databricks Runtime ML
Databricks Runtime ML bevat een verscheidenheid aan populaire ML-bibliotheken. De bibliotheken worden bijgewerkt met elke release om nieuwe functies en oplossingen op te nemen.
Databricks heeft een subset van de ondersteunde bibliotheken aangewezen als bibliotheken met de hoogste laag. Voor deze bibliotheken biedt Databricks een snellere updatefrequentie, waarbij naar de nieuwste pakketreleases wordt bijgewerkt met elke runtimerelease, zolang er geen afhankelijkheidsconflicten zijn. Databricks biedt ook geavanceerde ondersteuning, testen en ingesloten optimalisaties voor bibliotheken van topklasse. Bibliotheken van het hoogste niveau worden alleen toegevoegd of verwijderd bij belangrijke releases.
- Zie de release-opmerkingen van Databricks Runtime ML voor een volledige lijst van topkwaliteit en andere beschikbare bibliotheken.
- Zie Databricks Runtime ML-onderhoudsbeleidvoor informatie over hoe vaak bibliotheken worden bijgewerkt en wanneer bibliotheken worden afgeschaft.
U kunt extra bibliotheken installeren om een aangepaste omgeving te maken voor uw notebook of cluster.
- Als u een bibliotheek beschikbaar wilt maken voor alle notebooks die op een cluster worden uitgevoerd, maakt u een clusterbibliotheek. U kunt ook een init-script gebruiken om bibliotheken op clusters te installeren bij het maken.
- Als u een bibliotheek wilt installeren die alleen beschikbaar is voor een specifieke notebooksessie, gebruikt u Python-bibliotheken met een notebookscope.
Rekenresources instellen voor Databricks Runtime ML
Het proces voor het creëren van rekenprocessen op basis van Databricks Runtime ML hangt af van of uw werkruimte is ingeschakeld voor de Openbare Preview van het toegewezen groepscluster of niet. Werkruimten die zijn ingeschakeld voor de preview hebben een nieuwe vereenvoudigde rekeninterface.
Een cluster maken met Databricks Runtime ML
Wanneer u een cluster maakt, selecteert u een Databricks Runtime ML-versie in de vervolgkeuzelijst Databricks Runtime-versie. ML-runtimes voor zowel CPU als GPU zijn beschikbaar.
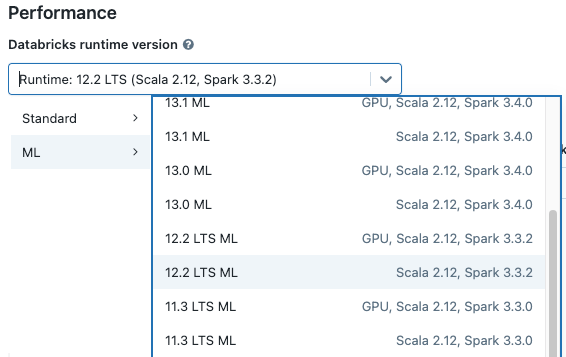 selecteren
selecteren
Als u een cluster in de vervolgkeuzelijst in het notebook selecteert, wordt de Databricks Runtime-versie weergegeven rechts van de clusternaam.
Als u een ML-runtime met GPU selecteert, wordt u gevraagd om een compatibel stuurprogrammatype en Worker-typete selecteren. Incompatibele exemplaartypen worden grijs weergegeven in de vervolgkeuzelijst. Exemplaartypen met GPU worden vermeld onder het GPU-versnelde label. Voor meer informatie over het maken van GPU-clusters in Azure Databricks, zie GPU-ondersteunde rekenkracht. Databricks Runtime ML bevat stuurprogramma's voor GPU-hardware en NVIDIA-bibliotheken, zoals CUDA.
Een nieuw cluster maken met de nieuwe vereenvoudigde rekeninterface
Gebruik de stappen in deze sectie alleen als uw werkruimte is ingeschakeld voor de preview-versie van het toegewezen groepscluster.
Als u de machine learning-versie van Databricks Runtime wilt gebruiken, schakelt u het selectievakje Machine learning- in.
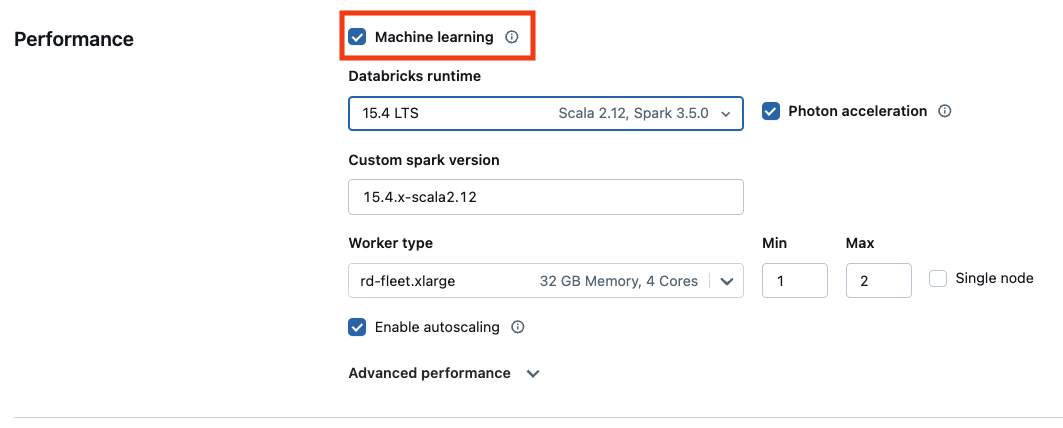
Selecteer een GPU-ingeschakeld exemplaartype voor GPU-gebaseerde rekenkracht. Zie Ondersteunde exemplaartypenvoor de volledige lijst met ondersteunde GPU-typen.
Photon en Databricks Runtime ML
Wanneer u een CPU-cluster met Databricks Runtime 15.2 ML of hoger maakt, kunt u ervoor kiezen om Photon in te schakelen. Photon verbetert de prestaties voor toepassingen met behulp van Spark SQL, Spark DataFrames, kenmerkengineering, GraphFrames en xgboost4j. Het is niet verwacht dat de prestaties voor toepassingen worden verbeterd met behulp van Spark RDD's, Pandas UDF's en niet-JVM-talen zoals Python. Python-pakketten zoals XGBoost, PyTorch en TensorFlow zien dus geen verbetering met Photon.
Spark RDD-API's en Spark MLlib hebben beperkte compatibiliteit met Photon. Wanneer u grote gegevenssets verwerkt met behulp van Spark RDD of Spark MLlib, kunnen er problemen met Spark-geheugen optreden. Bekijk problemen met Spark-geheugen.
Toegangsmodus voor Databricks Runtime ML-clusters
Als u toegang wilt krijgen tot gegevens in Unity Catalog op een cluster met Databricks Runtime ML, moet de toegangsmodus zijn ingesteld op Dedicated (voorheen de toegangsmodus voor één gebruiker).
Wanneer een rekenresource Exclusieve toegang heeft, kan de resource worden toegewezen aan een enkele gebruiker of een groep. Wanneer deze is toegewezen aan een groep (een groepscluster), worden de machtigingen van de gebruiker automatisch beperkt tot de machtigingen van de groep, zodat de gebruiker de resource veilig kan delen met andere leden van de groep.
Wanneer u de toegewezen toegangsmodus gebruikt, zijn de volgende functies alleen beschikbaar in Databricks Runtime 15.4 LTS ML en hoger: