Fijnmazig toegangsbeheer voor rekenkracht van één gebruiker
In dit artikel wordt de functionaliteit voor gegevensfiltering geïntroduceerd waarmee gedetailleerd toegangsbeheer mogelijk is voor query's die worden uitgevoerd op berekeningen van één gebruiker (alle doeleinden of taken die zijn geconfigureerd met de toegangsmodus voor één gebruiker ). Zie Access-modi.
Deze gegevensfiltering wordt achter de schermen uitgevoerd met serverloze berekeningen.
Waarom zijn voor sommige query's op rekenkracht van één gebruiker gegevensfiltering vereist?
Met Unity Catalog kunt u de toegang tot gegevens in tabelvorm beheren op column- en rijniveau (ook wel fijnmazig toegangsbeheer genoemd) met behulp van de volgende functies:
Wanneer gebruikers query's uitvoeren op views die gegevens uitsluiten van tables of query-tables die filters en maskers toepassen, kunnen ze een van de volgende rekenresources zonder beperkingen gebruiken:
- SQL-magazijnen
- Gedeelde rekenkracht
Als u echter rekenkracht van één gebruiker gebruikt om dergelijke query's uit te voeren, moeten berekeningen en uw werkruimte voldoen aan specifieke vereisten:
De rekenresource voor één gebruiker moet zich in Databricks Runtime 15.4 LTS of hoger hebben.
De werkruimte moet worden ingeschakeld voor serverloze computercapaciteit ten behoeve van opdrachten, notebooks en Delta Live Tables.
Zie Functies met beperkte regionale beschikbaarheid om te bevestigen dat uw werkruimteregio serverloze berekeningen ondersteunt.
Als uw rekenresource en werkruimte voor één gebruiker aan deze vereisten voldoen, wordt gegevensfiltering automatisch uitgevoerd wanneer u een query uitvoert op een weergave of table die gebruikmaakt van gedetailleerd toegangsbeheer.
Ondersteuning voor gematerialiseerde views, streaming tablesen standaard views
Naast dynamische views, rijfilters en column maskers, schakelt gegevensfilters ook query's in op de volgende views en tables die niet worden ondersteund op berekeningen van één gebruiker waarop Databricks Runtime 15.3 en hieronder wordt uitgevoerd:
-
Op berekeningen van één gebruiker waarop Databricks Runtime 15.3 en lager wordt uitgevoerd, moet de gebruiker die de query uitvoert in de weergave
SELECThebben op de tables en views waarnaar wordt verwezen door de weergave. Dit betekent dat u views niet kunt gebruiken om gedetailleerd toegangsbeheer te bieden. In Databricks Runtime 15.4 met gegevensfiltering heeft de gebruiker die de weergave opvraagt geen toegang nodig tot de tables en viewswaarnaar wordt verwezen.
Hoe werkt het filteren van gegevens op rekenkracht van één gebruiker?
Wanneer een query toegang heeft tot de volgende databaseobjecten, geeft de rekenresource van één gebruiker de query door aan serverloze berekeningen om gegevensfiltering uit te voeren:
-
Views gebouwd op tables waarop de gebruiker niet over de bevoegdheid
SELECTbeschikt - Dynamische views
- Tables met rijfilters of column maskers gedefinieerd
- Gerealiseerde views en streaming-tables
In het volgende diagram heeft SELECT een gebruiker op table_1, view_2en table_w_rls, waarop rijfilters zijn toegepast. De gebruiker heeft geen SELECT toegang tot table_2, waarnaar wordt verwezen door view_2.

De query table_1 wordt volledig verwerkt door de rekenresource voor één gebruiker, omdat er geen filters vereist zijn. De query's op view_2 en table_w_rls vereisen gegevensfiltering om de gegevens te retourneren waartoe de gebruiker toegang heeft. Deze query's worden verwerkt door de mogelijkheid voor gegevensfiltering op serverloze berekeningen.
Welke kosten worden er gemaakt?
Klanten worden in rekening gebracht voor de serverloze rekenresources die worden gebruikt om gegevensfilterbewerkingen uit te voeren. Zie Platformlagen en invoegtoepassingen voor prijsinformatie.
U kunt een query uitvoeren op het gebruik van systeemfacturering table om te zien hoeveel er in rekening is gebracht. Met de volgende query worden bijvoorbeeld de rekenkosten per gebruiker opgesplitst:
SELECT usage_date,
sku_name,
identity_metadata.run_as,
SUM(usage_quantity) AS `DBUs consumed by FGAC`
FROM system.billing.usage
WHERE usage_date BETWEEN '2024-08-01' AND '2024-09-01'
AND billing_origin_product = 'FINE_GRAINED_ACCESS_CONTROL'
GROUP BY 1, 2, 3 ORDER BY 1;
Queryprestaties weergeven wanneer gegevensfiltering is ingeschakeld
In de Spark-gebruikersinterface voor rekenkracht van één gebruiker worden metrische gegevens weergegeven die u kunt gebruiken om inzicht te hebben in de prestaties van uw query's. Voor elke query die u uitvoert op de rekenresource, wordt op het tabblad SQL/Dataframe de weergave van de querygrafiek weergegeven. Als een query betrokken was bij het filteren van gegevens, geeft de gebruikersinterface een RemoteSparkConnectScan-operatorknooppunt onder aan de grafiek weer. In dat knooppunt worden metrische gegevens weergegeven die u kunt gebruiken om queryprestaties te onderzoeken. Zie Compute-informatie weergeven in de Apache Spark-gebruikersinterface.
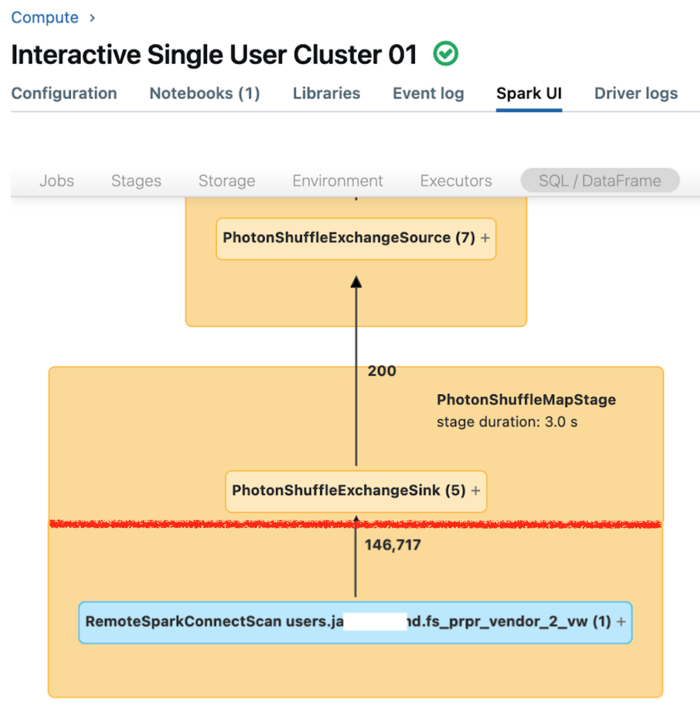
Vouw het operatorknooppunt RemoteSparkConnectScan uit om metrische gegevens weer te geven die betrekking hebben op vragen als de volgende:
- Hoeveel tijd kost het filteren van gegevens? 'Totale uitvoeringstijd voor externe uitvoering'.
- Hoeveel rijen bleef er na het filteren van gegevens? Weergave 'rijenuitvoer'.
- Hoeveel gegevens (in bytes) zijn geretourneerd na het filteren van gegevens? De uitvoergrootte van rijen weergeven.
- Hoeveel gegevensbestanden zijn partitionuitgedund en hoefden daardoor niet uit de opslag te worden gelezen? Bekijk 'Bestanden verwijderd' en 'Grootte van bestanden verwijderd'.
- Hoeveel gegevensbestanden kunnen niet worden verwijderd en moeten worden gelezen uit de opslag? Bekijk 'Bestanden gelezen' en 'Grootte van bestanden gelezen'.
- Van de bestanden die moeten worden gelezen, hoeveel waren er al in de cache? Bekijk 'Cachetreffergrootte' en 'Cache misses size'.
Beperkingen
Er is geen ondersteuning voor schrijf- of refreshtable-bewerkingen op tables waarop rijfilters of column maskers zijn toegepast.
DML-bewerkingen, zoals
INSERT,DELETE,UPDATE,REFRESH TABLEenMERGE, worden niet ondersteund. U kunt alleen (SELECT) lezen van deze tables.Self-joins worden standaard geblokkeerd wanneer gegevensfiltering wordt aangeroepen, maar u kunt ze toestaan door in te stellen
spark.databricks.remoteFiltering.blockSelfJoinsop onwaar bij berekening waarvoor u deze opdrachten uitvoert.Voordat u zelf-joins inschakelt voor een rekenresource van een enkele gebruiker, moet u er rekening mee houden dat een zelf-join query die wordt verwerkt door de gegevensfiltermogelijkheid verschillende momentopnamen van dezelfde externe tablekan opleveren.