De kwaliteit van RAG-gegevenspijplijnen verbeteren
In dit artikel wordt beschreven hoe u kunt experimenteren met gegevenspijplijnkeuzes vanuit een praktisch oogpunt bij het implementeren van wijzigingen in de gegevenspijplijn.
Belangrijkste onderdelen van de gegevenspijplijn
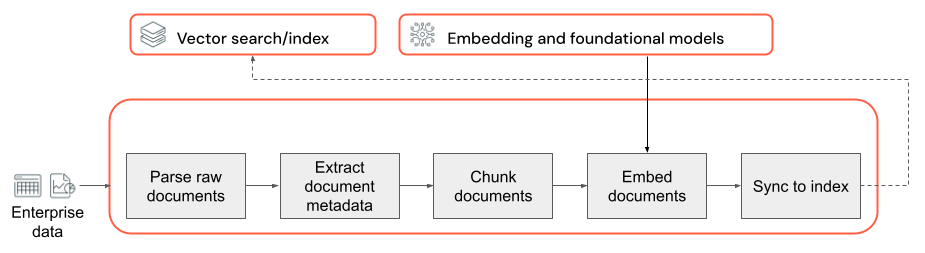
De basis van een RAG-toepassing met ongestructureerde gegevens is de gegevenspijplijn. Deze pijplijn is verantwoordelijk voor het voorbereiden van de ongestructureerde gegevens in een indeling die effectief kan worden gebruikt door de RAG-toepassing. Hoewel deze gegevenspijplijn willekeurig complex kan worden, zijn het volgende de belangrijkste onderdelen die u moet bedenken bij het bouwen van uw RAG-toepassing:
- Inhoudssamenstelling: De juiste gegevensbronnen en inhoud selecteren op basis van de specifieke use case.
- Parseren: relevante informatie extraheren uit de onbewerkte gegevens met behulp van de juiste parseringstechnieken.
- Segmentering: De geparseerde gegevens opsplitsen in kleinere, beheerbare segmenten voor efficiënt ophalen.
- Insluiten: de gesegmenteerde tekstgegevens converteren naar een numerieke vectorweergave die de semantische betekenis vastlegt.
Corpus samenstelling
Zonder de juiste gegevens kan uw RAG-toepassing de informatie die nodig is om een gebruikersquery te beantwoorden, niet ophalen. De juiste gegevens zijn volledig afhankelijk van de specifieke vereisten en doelstellingen van uw toepassing, waardoor het cruciaal is om tijd te besteden aan het begrijpen van de nuances van gegevens die beschikbaar zijn (zie de sectie Vereisten verzamelen voor richtlijnen hierover).
Als u bijvoorbeeld een klantondersteuningsbot bouwt, kunt u overwegen het volgende te doen:
- Knowledge Base-documenten
- Veelgestelde vragen (FAQ's)
- Producthandleidingen en specificaties
- Handleidingen voor probleemoplossing
Betrek domeinexperts en belanghebbenden vanaf het begin van elk project om relevante inhoud te identificeren en te cureren die de kwaliteit en dekking van uw gegevensverzameling kan verbeteren. Ze kunnen inzicht krijgen in de typen query's die gebruikers waarschijnlijk zullen indienen en helpen prioriteit te geven aan de belangrijkste informatie die moet worden opgenomen.
Parseren
Nadat u de gegevensbronnen voor uw RAG-toepassing hebt geïdentificeerd, wordt in de volgende stap de vereiste informatie uit de onbewerkte gegevens geëxtraheerd. Dit proces, ook wel parseren genoemd, omvat het transformeren van de ongestructureerde gegevens in een indeling die effectief kan worden gebruikt door de RAG-toepassing.
De specifieke parseringstechnieken en hulpprogramma's die u gebruikt, zijn afhankelijk van het type gegevens waarmee u werkt. Voorbeeld:
- Tekstdocumenten (PDF's, Word-documenten): Bibliotheken buiten de plank, zoals ongestructureerde en PyPDF2 , kunnen verschillende bestandsindelingen verwerken en opties bieden voor het aanpassen van het parseringsproces.
- HTML-documenten: HTML-parseringsbibliotheken zoals BeautifulSoup kunnen worden gebruikt om relevante inhoud van webpagina's te extraheren. Met deze elementen kunt u door de HTML-structuur navigeren, specifieke elementen selecteren en de gewenste tekst of kenmerken extraheren.
- Afbeeldingen en gescande documenten: OCR-technieken (Optical Character Recognition) zijn doorgaans vereist om tekst uit afbeeldingen te extraheren. Populaire OCR-bibliotheken zijn Tesseract, Amazon Textract, Azure AI Vision OCR en Google Cloud Vision-API.
Aanbevolen procedures voor het parseren van gegevens
Houd bij het parseren van uw gegevens rekening met de volgende aanbevolen procedures:
- Gegevens opschonen: de geëxtraheerde tekst vooraf verwerken om irrelevante of luidruchtige informatie te verwijderen, zoals kopteksten, voetteksten of speciale tekens. Wees cognizant van het verminderen van de hoeveelheid onnodige of onjuiste informatie die uw RAG-keten moet verwerken.
- Afhandeling van fouten en uitzonderingen: Implementeer foutafhandeling en logboekregistratiemechanismen om eventuele problemen te identificeren en op te lossen tijdens het parseringsproces. Dit helpt u snel problemen te identificeren en op te lossen. Dit wijst vaak op upstream-problemen met de kwaliteit van de brongegevens.
- Aanpassing van parseringslogica: afhankelijk van de structuur en opmaak van uw gegevens, moet u mogelijk de parseringslogica aanpassen om de meest relevante informatie te extraheren. Hoewel er mogelijk vooraf extra inspanning nodig is, investeert u de tijd om dit te doen, indien nodig. Dit voorkomt vaak veel problemen met downstreamkwaliteit.
- De parseringskwaliteit evalueren: beoordeel regelmatig de kwaliteit van de geparseerde gegevens door handmatig een voorbeeld van de uitvoer te controleren. Dit kan u helpen bij het identificeren van eventuele problemen of gebieden voor verbetering in het parseringsproces.
Chunking
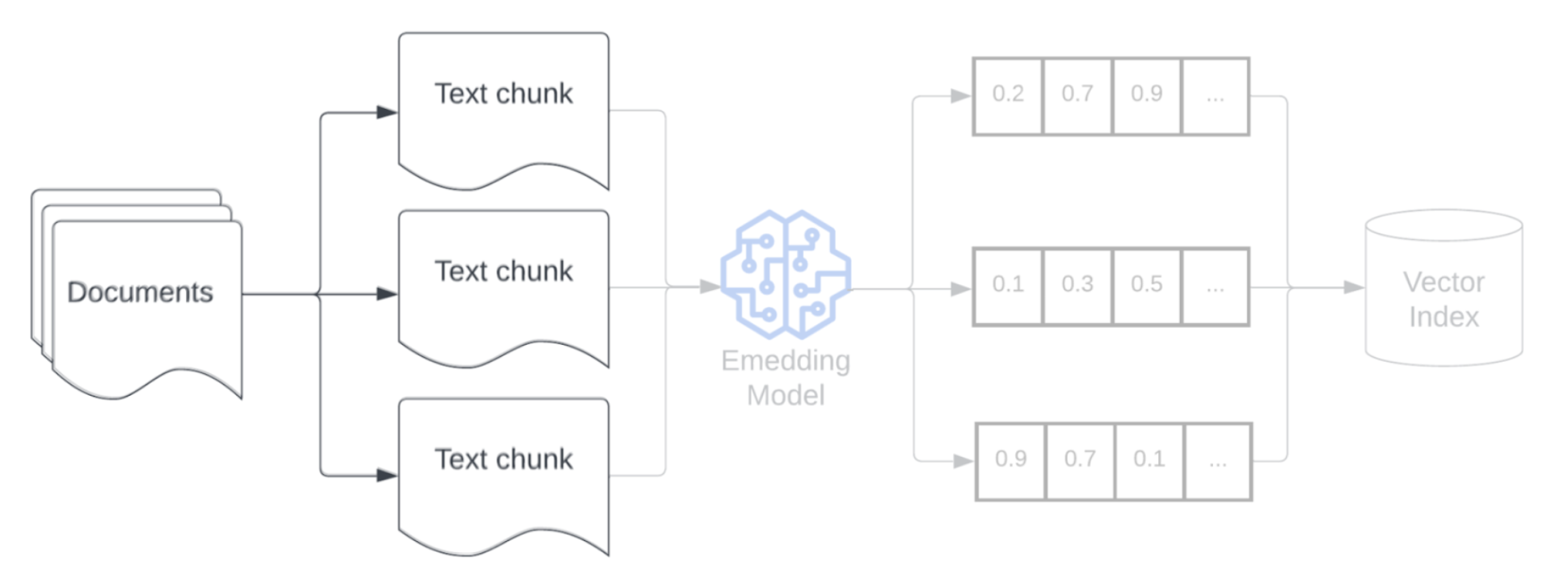
Na het parseren van de onbewerkte gegevens in een meer gestructureerde indeling, is de volgende stap het opsplitsen in kleinere, beheerbare eenheden die segmenten worden genoemd. Door grote documenten te segmenteren in kleinere, semantisch geconcentreerde segmenten, zorgt u ervoor dat opgehaalde gegevens in de context van de LLM passen, terwijl de opname van afleidende of irrelevante informatie wordt geminimaliseerd. De keuzes die zijn gemaakt bij segmentering hebben rechtstreeks invloed op de opgehaalde gegevens die de LLM biedt, waardoor deze een van de eerste lagen van optimalisatie in een RAG-toepassing is.
Houd rekening met de volgende factoren bij het segmenteren van uw gegevens:
- Segmenteringsstrategie: de methode die u gebruikt om de oorspronkelijke tekst te verdelen in segmenten. Dit kan betrekking hebben op basistechnieken, zoals splitsen op zinnen, alinea's of specifieke tekens/tokentellingen, tot geavanceerdere documentspecifieke splitsingsstrategieën.
- Segmentgrootte: kleinere segmenten kunnen zich richten op specifieke details, maar enige omringende informatie verliezen. Grotere segmenten kunnen meer context vastleggen, maar kunnen ook irrelevante informatie bevatten.
- Overlapping tussen segmenten: Om ervoor te zorgen dat belangrijke informatie niet verloren gaat bij het splitsen van de gegevens in segmenten, kunt u overwegen om enige overlapping tussen aangrenzende segmenten op te nemen. Overlappend kan zorgen voor continuïteit en contextbehoud tussen segmenten.
- Semantische samenhang: probeer, indien mogelijk, segmenten te creëren die semantisch coherent zijn, wat betekent dat ze verwante informatie bevatten en zelfstandig kunnen staan als een zinvolle teksteenheid. Dit kan worden bereikt door rekening te houden met de structuur van de oorspronkelijke gegevens, zoals alinea's, secties of onderwerpgrenzen.
- Metagegevens: Met inbegrip van relevante metagegevens binnen elk segment, zoals de naam van het brondocument, de sectiekop of productnamen, kan het ophaalproces worden verbeterd. Deze aanvullende informatie in het segment kan helpen bij het ophalen van query's naar segmenten.
Strategieën voor gegevenssegmentering
Het vinden van de juiste segmenteringsmethode is zowel iteratief als contextafhankelijk. Er is geen benadering die in één grootte past; de optimale segmentgrootte en -methode zijn afhankelijk van de specifieke use case en de aard van de gegevens die worden verwerkt. In grote lijnen kunnen segmenteringsstrategieën als volgt worden bekeken:
- Segmentering met vaste grootte: Splits de tekst in segmenten van een vooraf bepaalde grootte, zoals een vast aantal tekens of tokens (bijvoorbeeld LangChain CharacterTextSplitter). Hoewel splitsen op basis van een willekeurig aantal tekens of tokens snel en eenvoudig kan worden ingesteld, resulteert dit meestal niet in consistent semantisch samenhangende segmenten.
- Op alinea's gebaseerde segmenten: gebruik de natuurlijke alineagrenzen in de tekst om segmenten te definiëren. Deze methode kan helpen de semantische samenhang van de segmenten te behouden, omdat alinea's vaak gerelateerde informatie bevatten (bijvoorbeeld LangChain RecursiveCharacterTextSplitter).
- Indelingsspecifieke segmentering: indelingen zoals markdown of HTML hebben een inherente structuur die kan worden gebruikt om segmentgrenzen te definiëren (bijvoorbeeld Markdown-headers). Hulpprogramma's zoals MarkdownHeaderTextSplitter of splitters op basis van HTML-headers/ kunnen hiervoor worden gebruikt.
- Semantische segmentering: Technieken zoals onderwerpmodellering kunnen worden toegepast om semantisch coherente secties in de tekst te identificeren. Deze benaderingen analyseren de inhoud of structuur van elk document om de meest geschikte segmentgrenzen te bepalen op basis van verschuivingen in onderwerp. Hoewel meer betrokken zijn dan meer basismethoden, kan semantische segmentering helpen bij het maken van segmenten die meer zijn afgestemd op de natuurlijke semantische delen in de tekst (zie LangChain SemanticChunker voor een voorbeeld hiervan).
Voorbeeld: Segmentering met een fix-grootte
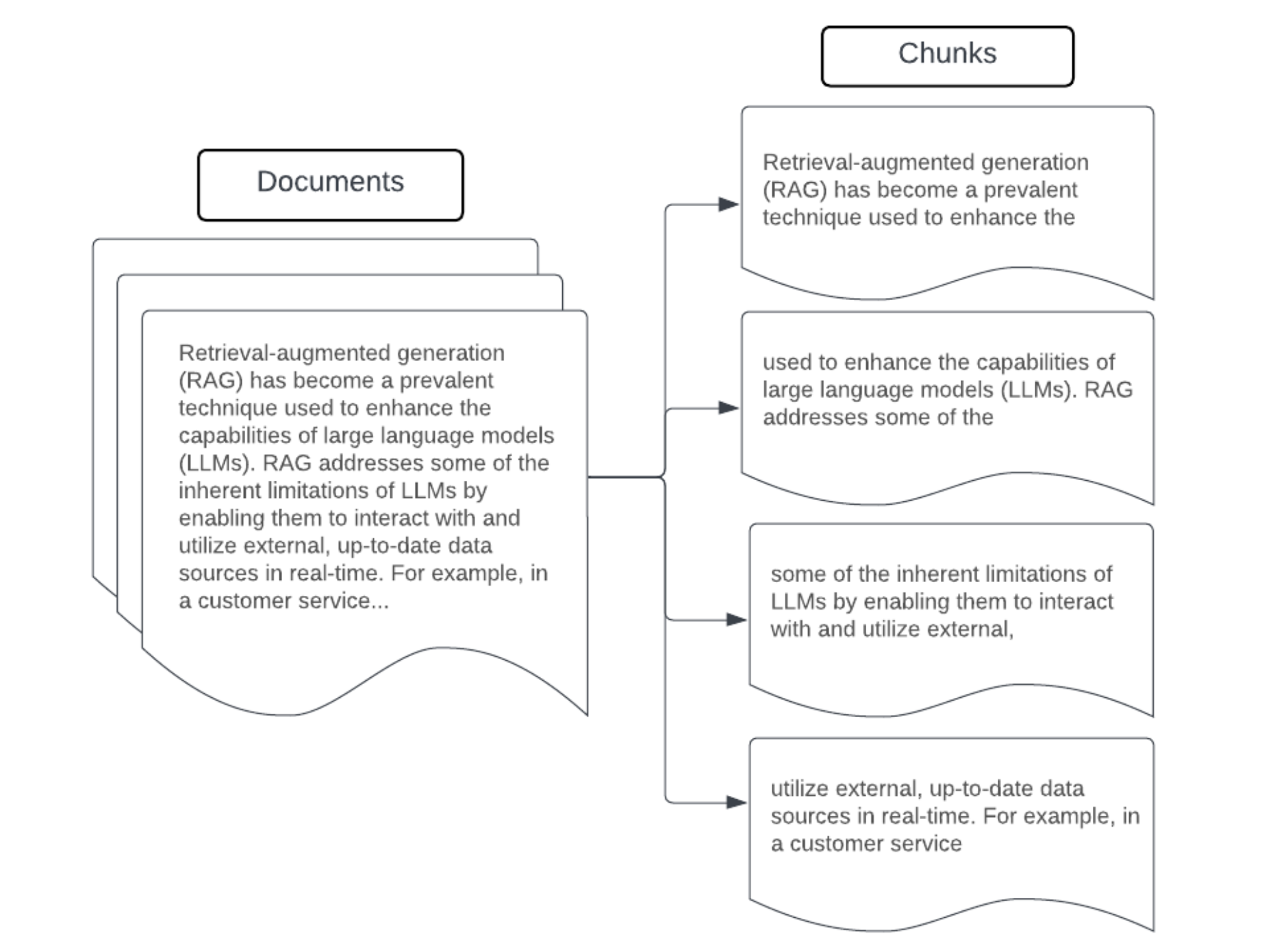
Voorbeeld van segmentering met vaste grootte met behulp van RecursiveCharacterTextSplitter van LangChain met chunk_size=100 en chunk_overlap=20.
ChunkViz biedt een interactieve manier om te visualiseren hoe verschillende chunk grootte- en grootte overlapwaarden met Langchain’s karaktersplitsers resulterende chunks beïnvloeden.
Model insluiten
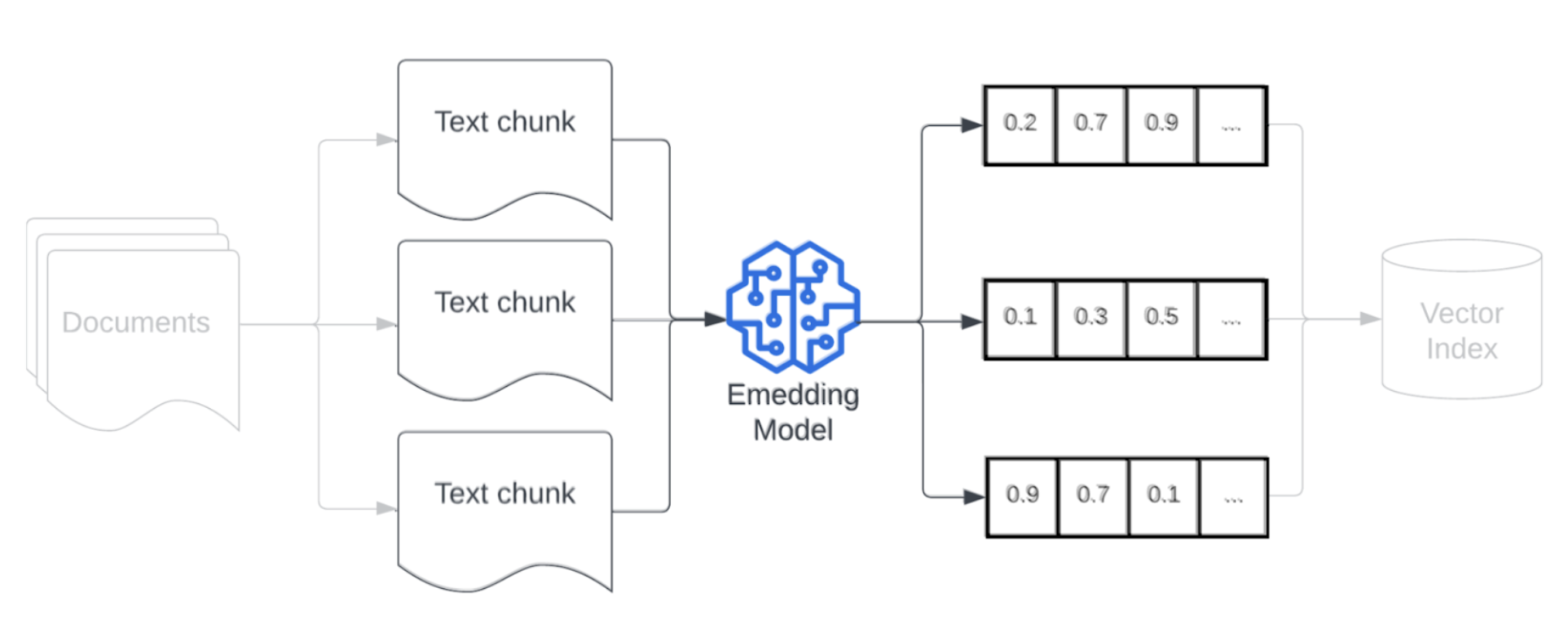
Na het segmenteren van uw gegevens is de volgende stap het converteren van de tekstsegmenten naar een vectorweergave met behulp van een insluitmodel. Een insluitmodel wordt gebruikt om elk tekstsegment te converteren naar een vectorweergave die de semantische betekenis vastlegt. Door segmenten weer te geven als dichte vectoren, kunnen insluitingen snel en nauwkeurig de meest relevante segmenten ophalen op basis van hun semantische gelijkenis met een ophaalquery. Tijdens de query wordt de ophaalquery getransformeerd met hetzelfde insluitingsmodel dat is gebruikt voor het insluiten van segmenten in de gegevenspijplijn.
Houd rekening met de volgende factoren bij het selecteren van een insluitmodel:
- Modelkeuze: elk insluitmodel heeft de nuances en de beschikbare benchmarks leggen mogelijk niet de specifieke kenmerken van uw gegevens vast. Experimenteer met verschillende kant-en-klare insluitingsmodellen, zelfs modellen die lager kunnen worden gerangschikt op standaard leaderboards zoals MTEB. Enkele voorbeelden om rekening mee te houden zijn:
- Maximumtokens: Houd rekening met de maximale tokenlimiet voor het gekozen insluitingsmodel. Als u segmenten doorgeeft die deze limiet overschrijden, worden ze afgekapt, waardoor belangrijke informatie mogelijk verloren gaat. bge-large-en-v1.5 heeft bijvoorbeeld een maximumtokenlimiet van 512.
- Modelgrootte: Grotere insluitingsmodellen bieden over het algemeen betere prestaties, maar vereisen meer rekenresources. Zorg voor een balans tussen prestaties en efficiëntie op basis van uw specifieke use case en beschikbare resources.
- Fine-tuning: Als uw RAG-toepassing te maken heeft met domeinspecifieke taal (bijvoorbeeld interne bedrijfsacroniemen of terminologie), kunt u overwegen het insluitingsmodel af te stemmen op domeinspecifieke gegevens. Dit kan het model helpen de nuances en terminologie van uw specifieke domein beter vast te leggen en kan vaak leiden tot verbeterde ophaalprestaties.