Vereiste: Vereisten verzamelen
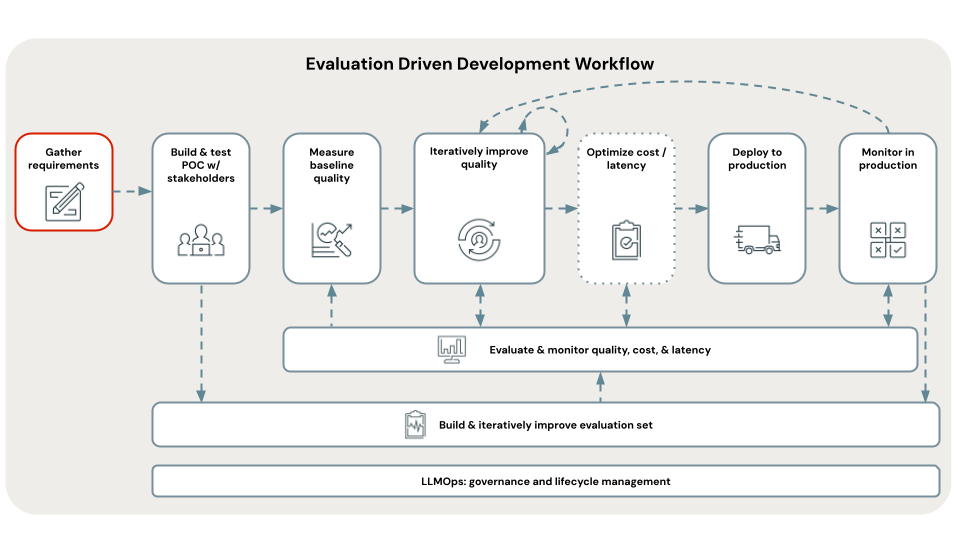
Het definiëren van duidelijke en uitgebreide use-casevereisten is een kritieke eerste stap bij het ontwikkelen van een geslaagde RAG-toepassing. Deze vereisten dienen twee primaire doeleinden. Ten eerste helpen ze te bepalen of RAG de meest geschikte benadering is voor de opgegeven use-case. Als RAG inderdaad goed past, zijn deze vereisten geschikt voor het ontwerpen, implementeren en evalueren van oplossingen. Investeren in tijd aan het begin van een project om gedetailleerde vereisten te verzamelen, kan aanzienlijke uitdagingen en tegenslagen later in het ontwikkelingsproces voorkomen en zorgt ervoor dat de resulterende oplossing voldoet aan de behoeften van eindgebruikers en belanghebbenden. Goed gedefinieerde vereisten bieden de basis voor de volgende fasen van de ontwikkelingslevenscyclus die we zullen doorlopen.
Zie de GitHub-opslagplaats voor de voorbeeldcode in deze sectie. U kunt de opslagplaatscode ook gebruiken als sjabloon waarmee u uw eigen AI-toepassingen kunt maken.
Is de use case geschikt voor RAG?
Het eerste wat u moet vaststellen, is of RAG zelfs de juiste aanpak is voor uw use-case. Gezien de hype rond RAG, is het verleidelijk om het als een mogelijke oplossing voor elk probleem te bekijken. Er zijn echter nuances over wanneer RAG geschikt is versus niet.
RAG is geschikt wanneer:
- Redeneren over opgehaalde informatie (zowel ongestructureerd als gestructureerd) die niet volledig binnen het contextvenster van de LLM past
- Informatie uit meerdere bronnen synthetiseren (bijvoorbeeld het genereren van een samenvatting van de belangrijkste punten uit verschillende artikelen in een onderwerp)
- Dynamisch ophalen op basis van een gebruikersquery is nodig (bijvoorbeeld wanneer u een gebruikersquery opvraagt, bepaalt u uit welke gegevensbron moet worden opgehaald)
- De use case vereist het genereren van nieuwe inhoud op basis van opgehaalde informatie (bijvoorbeeld het beantwoorden van vragen, het verstrekken van uitleg, het aanbieden van aanbevelingen)
RAG is mogelijk niet de beste keuze wanneer:
- Voor de taak is geen queryspecifieke ophaalbewerking vereist. Bijvoorbeeld het genereren van samenvattingen van aanroeptranscripties; zelfs als afzonderlijke transcripties worden verstrekt als context in de LLM-prompt, blijven de opgehaalde gegevens hetzelfde voor elke samenvatting.
- De volledige set informatie die moet worden opgehaald, kan binnen het contextvenster van de LLM passen
- Er zijn extreem lage latentiereacties vereist (bijvoorbeeld wanneer reacties in milliseconden vereist zijn)
- Eenvoudige antwoorden op basis van regels of sjablonen zijn voldoende (bijvoorbeeld een chatbot voor klantondersteuning die vooraf gedefinieerde antwoorden biedt op basis van trefwoorden)
Vereisten om te detecteren
Nadat u hebt vastgesteld dat RAG geschikt is voor uw use-case, moet u rekening houden met de volgende vragen om concrete vereisten vast te leggen. De vereisten worden als volgt gerangschikt:
🟢 P0: Moet deze vereiste definiëren voordat u uw POC start.
🟡 P1: Moet definiëren voordat u naar productie gaat, maar kan iteratief verfijnen tijdens de POC.
⚪ P2: Leuk om vereiste te hebben.
Dit is geen volledige lijst met vragen. Het moet echter een solide basis bieden voor het vastleggen van de belangrijkste vereisten voor uw RAG-oplossing.
Gebruikerservaring
Definiëren hoe gebruikers communiceren met het RAG-systeem en wat voor soort reacties er worden verwacht
🟢 [P0] Hoe ziet een typische aanvraag voor de RAG-keten eruit? Vraag belanghebbenden om voorbeelden van mogelijke gebruikersquery's.
🟢 [P0] Wat voor soort antwoorden verwachten gebruikers (korte antwoorden, langformulieruitleg, een combinatie of iets anders)?
🟡 [P1] Hoe communiceren gebruikers met het systeem? Via een chatinterface, zoekbalk of een andere modaliteit?
🟡 [P1] Hoedtoon of stijl moet gegenereerde reacties nemen? (formeel, conversationeel, technisch?)
🟡 [P1] Hoe moet de toepassing ambigu, onvolledige of irrelevante query's verwerken? Moet er in dergelijke gevallen enige vorm van feedback of richtlijnen worden gegeven?
⚪ [P2] Zijn er specifieke opmaak- of presentatievereisten voor de gegenereerde uitvoer? Moet de uitvoer naast het antwoord van de keten metagegevens bevatten?
Gegevens
Bepaal de aard, de bron(en) en de kwaliteit van de gegevens die in de RAG-oplossing worden gebruikt.
🟢 [P0] Wat zijn de beschikbare bronnen die u wilt gebruiken?
Voor elke gegevensbron:
- 🟢 [P0] Zijn gegevens gestructureerd of ongestructureerd?
- 🟢 [P0] Wat is de bronindeling van de ophaalgegevens (bijvoorbeeld PDF's, documentatie met afbeeldingen/tabellen, gestructureerde API-antwoorden)?
- 🟢 [P0] Waar bevinden die gegevens zich?
- 🟢 [P0] Hoeveel gegevens zijn er beschikbaar?
- 🟡 [P1] Hoe vaak worden de gegevens bijgewerkt? Hoe moeten deze updates worden verwerkt?
- 🟡 [P1] Zijn er bekende problemen met de kwaliteit van gegevens of inconsistenties voor elke gegevensbron?
Overweeg om een inventaristabel te maken om deze informatie samen te voegen, bijvoorbeeld:
| Gegevensbron | Bron | Bestandstype(s) | Tekengrootte | Updatefrequentie |
|---|---|---|---|---|
| Gegevensbron 1 | Unity Catalog-volume | JSON | 10 GB | Dagelijks |
| Gegevensbron 2 | Openbare API | XML | NA (API) | Real-time |
| Gegevensbron 3 | SharePoint | PDF, .docx | 500 MB | Maandelijks |
Prestatiebeperkingen
Prestatie- en resourcevereisten vastleggen voor de RAG-toepassing.
🟡 [P1] Wat is de maximaal acceptabele latentie voor het genereren van de antwoorden?
🟡 [P1] Wat is de maximaal acceptabele tijd voor het eerste token?
🟡 [P1] Als de uitvoer wordt gestreamd, is een hogere totale latentie acceptabel?
🟡 [P1] Zijn er kostenbeperkingen voor rekenresources beschikbaar voor deductie?
🟡 [P1] Wat zijn de verwachte gebruikspatronen en piekbelastingen?
🟡 [P1] Hoeveel gelijktijdige gebruikers of aanvragen moet het systeem kunnen verwerken? Databricks verwerkt dergelijke schaalbaarheidsvereisten standaard door de mogelijkheid om automatisch te schalen met Model Serving.
Beoordeling
Bepalen hoe de RAG-oplossing in de loop van de tijd wordt geëvalueerd en verbeterd.
🟢 [P0] Wat is het bedrijfsdoel/KPI dat u wilt beïnvloeden? Wat is de basislijnwaarde en wat is het doel?
🟢 [P0] Welke gebruikers of belanghebbenden geven initiële en doorlopende feedback?
🟢 [P0] Welke metrische gegevens moeten worden gebruikt om de kwaliteit van gegenereerde antwoorden te beoordelen? Mosaic AI Agent Evaluation biedt een aanbevolen set van metrieken om te gebruiken.
🟡 [P1] Wat is de set vragen waar de RAG-app goed in moet zijn om naar productie te gaan?
🟡 [P1] Bestaat er een [evaluatieset]? Is het mogelijk om een evaluatieset van gebruikersquery's op te halen, samen met waarheidsgetrouwe antwoorden en (optioneel) de juiste ondersteunende documenten die moeten worden opgehaald?
🟡 [P1] Hoe worden gebruikersfeedback verzameld en opgenomen in het systeem?
Beveiliging
Identificeer beveiligings- en privacyoverwegingen.
🟢 [P0] Zijn er gevoelige/vertrouwelijke gegevens die zorgvuldig moeten worden afgehandeld?
🟡 [P1] Moeten toegangsbeheer worden geïmplementeerd in de oplossing (een bepaalde gebruiker kan bijvoorbeeld alleen ophalen uit een beperkte set documenten)?
Implementatie
Begrijpen hoe de RAG-oplossing wordt geïntegreerd, geïmplementeerd en onderhouden.
🟡 Hoe moet de RAG-oplossing worden geïntegreerd met bestaande systemen en werkstromen?
🟡 Hoe moet het model worden geïmplementeerd, geschaald en versiebeheer? In deze zelfstudie wordt beschreven hoe de end-to-end levenscyclus op Databricks kan worden verwerkt met behulp van MLflow, Unity Catalog, Agent SDK en Model Serving.
Opmerking
Denk bijvoorbeeld na over hoe deze vragen van toepassing zijn op deze voorbeeld-RAG-toepassing die wordt gebruikt door een Databricks-klantondersteuningsteam:
| Gebied | Overwegingen | Vereisten |
|---|---|---|
| Gebruikerservaring | - Modaliteit van interactie. - Typische voorbeelden van gebruikersquery's. - Verwachte antwoordindeling en -stijl. - Het verwerken van dubbelzinnige of irrelevante query's. |
- Chatinterface geïntegreerd met Slack. - Voorbeeldquery's: 'Hoe kan ik de opstarttijd van het cluster verminderen?' "Wat voor soort ondersteuningsplan heb ik?" - Duidelijke, technische antwoorden met codefragmenten en koppelingen naar relevante documentatie, indien van toepassing. - Geef contextuele suggesties en escaleer naar ondersteuningstechnici wanneer dat nodig is. |
| Gegevens | - Het aantal en het type gegevensbronnen. - Gegevensindeling en -locatie. - Gegevensgrootte en updatefrequentie. - Kwaliteit en consistentie van gegevens. |
- Drie gegevensbronnen. - Bedrijfsdocumentatie (HTML, PDF). - Opgeloste ondersteuningstickets (JSON). - Community forumposten (Delta-tabel). - Gegevens die zijn opgeslagen in Unity Catalog en wekelijks bijgewerkt. - Totale gegevensgrootte: 5 GB. - Consistente gegevensstructuur en kwaliteit onderhouden door toegewezen documenten en ondersteuningsteams. |
| Prestaties | - Maximale acceptabele latentie. - Kostenbeperkingen. - Verwacht gebruik en gelijktijdigheid. |
- Maximale latentievereiste. - Kostenbeperkingen. - Verwachte piekbelasting. |
| Beoordeling | - Beschikbaarheid van evaluatiegegevenssets. - Metrische gegevens over kwaliteit. - Gebruikersfeedbackverzameling. |
- Deskundigen van elk productgebied helpen bij het beoordelen van de uitvoer en het aanpassen van onjuiste antwoorden om de evaluatiegegevensset te maken. - Zakelijke KPI's. - Verhoging van de resolutiesnelheid van ondersteuningstickets. - Afname van de gebruikerstijd die per ondersteuningsticket is besteed. - Metrische gegevens over kwaliteit. - De juistheid en relevantie van het antwoord door LLM beoordeeld. - LLM beoordeelt de precisie van het ophalen. - Gebruiker upvote of downvote. - Feedbackverzameling. - Slack wordt geïnstrueerd om een duim omhoog/omlaag te geven. |
| Beveiliging | - Verwerking van gevoelige gegevens. - Vereisten voor toegangsbeheer. |
- Er moeten geen gevoelige klantgegevens in de bron voor het ophalen staan. - Gebruikersverificatie via Databricks Community SSO. |
| Implementatie | - Integratie met bestaande systemen. - Implementatie en versiebeheer. |
- Integratie met ondersteuningsticketsysteem. - Keten geïmplementeerd als een Databricks Model Serving-eindpunt. |
Volgende stap
Aan de slag met stap 1. Kloon de codeopslagplaats en maak compute-.