Gegevens transformeren in de cloud met behulp van een Spark-activiteit in Azure Data Factory
VAN TOEPASSING OP:  Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Tip
Probeer Data Factory uit in Microsoft Fabric, een alles-in-één analyseoplossing voor ondernemingen. Microsoft Fabric omvat alles, van gegevensverplaatsing tot gegevenswetenschap, realtime analyses, business intelligence en rapportage. Meer informatie over het gratis starten van een nieuwe proefversie .
In deze zelfstudie gebruikt u Azure Portal om een pijplijn voor Azure Data Factory te maken. Deze pijplijn transformeert gegevens met behulp van een Spark-activiteit en een gekoppelde Azure HDInsight-service op aanvraag.
In deze zelfstudie voert u de volgende stappen uit:
- Een data factory maken.
- Een pijplijn maken die een Spark-activiteit gebruikt.
- Een pijplijnuitvoering activeren.
- Controleer de pijplijnuitvoering.
Als u geen Azure-abonnement hebt, maakt u een gratis account voordat u begint.
Vereisten
Notitie
Het wordt aanbevolen de Azure Az PowerShell-module te gebruiken om te communiceren met Azure. Zie Azure PowerShell installeren om aan de slag te gaan. Raadpleeg Azure PowerShell migreren van AzureRM naar Az om te leren hoe u naar de Azure PowerShell-module migreert.
- Azure-opslagaccount. U maakt een Python-script en een invoerbestand, en upload deze naar Azure Storage. De uitvoer van het Spark-programma wordt opgeslagen in dit opslagaccount. Het Spark-cluster op aanvraag gebruikt hetzelfde opslagaccount als de primaire opslag.
Notitie
HdInsight ondersteunt alleen algemene opslagaccounts met de catogorie Standard. Zorg ervoor dat het account niet een premium of alleen-blob opslagaccount is.
- Azure PowerShell. Volg de instructies in How to install and configure Azure PowerShell (Azure PowerShell installeren en configureren).
Het Python-script uploaden naar het Blob-opslagaccount
Maak een Python-bestand met de naam WordCount_Spark.py met de volgende inhoud:
import sys from operator import add from pyspark.sql import SparkSession def main(): spark = SparkSession\ .builder\ .appName("PythonWordCount")\ .getOrCreate() lines = spark.read.text("wasbs://adftutorial@<storageaccountname>.blob.core.windows.net/spark/inputfiles/minecraftstory.txt").rdd.map(lambda r: r[0]) counts = lines.flatMap(lambda x: x.split(' ')) \ .map(lambda x: (x, 1)) \ .reduceByKey(add) counts.saveAsTextFile("wasbs://adftutorial@<storageaccountname>.blob.core.windows.net/spark/outputfiles/wordcount") spark.stop() if __name__ == "__main__": main()Vervang <storageAccountName> door de naam van uw Azure-opslagaccount. Sla het bestand vervolgens op.
Maak in Azure Blob-opslag een container met de naam adftutorial als deze nog niet bestaat.
Maak een map met de naam spark.
Maak in de map spark een submap met de naam script.
Upload het bestand WordCount_Spark.py naar de submap script.
Invoerbestand uploaden
- Maak een bestand met de naam minecraftstory.txt met wat tekst. Het Spark-programma telt het aantal woorden in deze tekst.
- Maak in de map spark een submap met de naam inputfiles.
- Upload het bestand minecraftstory.txt naar de submap inputfiles.
Een data factory maken
Volg de stappen in de quickstart van het artikel : Een gegevensfactory maken met behulp van Azure Portal om een data factory te maken als u er nog geen hebt om mee te werken.
Gekoppelde services maken
In deze sectie maakt u twee gekoppelde services:
- Een gekoppelde Azure Storage-service waarmee een Azure-opslagaccount wordt gekoppeld aan de gegevensfactory. Deze opslag wordt gebruikt voor het HDInsight-cluster op aanvraag. De service bevat ook het Spark-script dat moet worden uitgevoerd.
- Een gekoppelde HDInsight-service op aanvraag. Azure Data Factory maakt automatisch een HDInsight-cluster en voert het Spark-programma uit. Het HDInsight-cluster wordt vervolgens verwijderd als het cluster gedurende een vooraf geconfigureerde tijd inactief is geweest.
Een gekoppelde Azure Storage-service maken
Ga op de startpagina naar het tabblad Beheren in het linkerdeelvenster.
Selecteer Verbindingen onder aan het venster en selecteer + Nieuw.
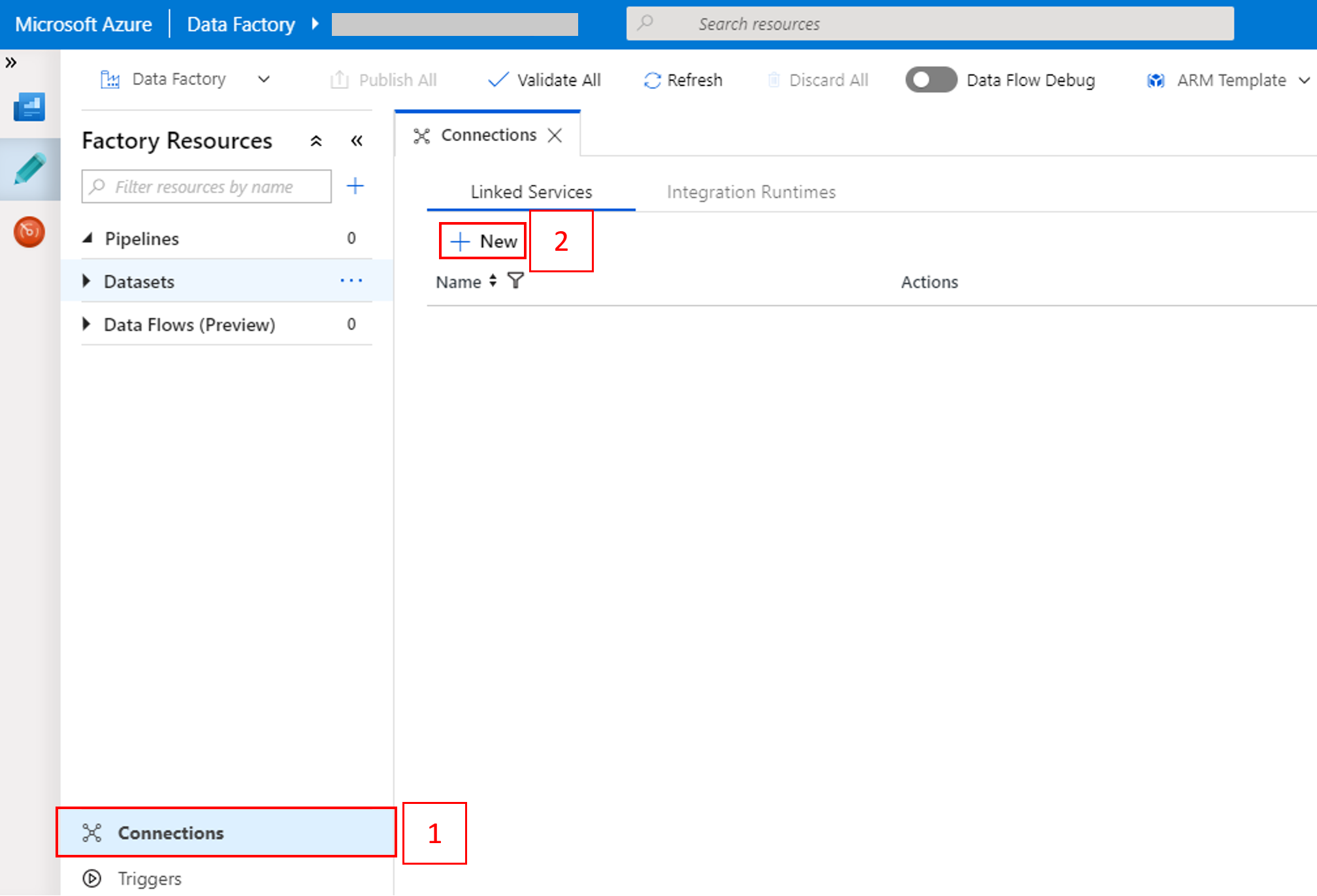
Selecteer in het venster Nieuwe gekoppelde service de optie Gegevensarchief>Azure Blob-opslag en selecteer vervolgens Doorgaan.

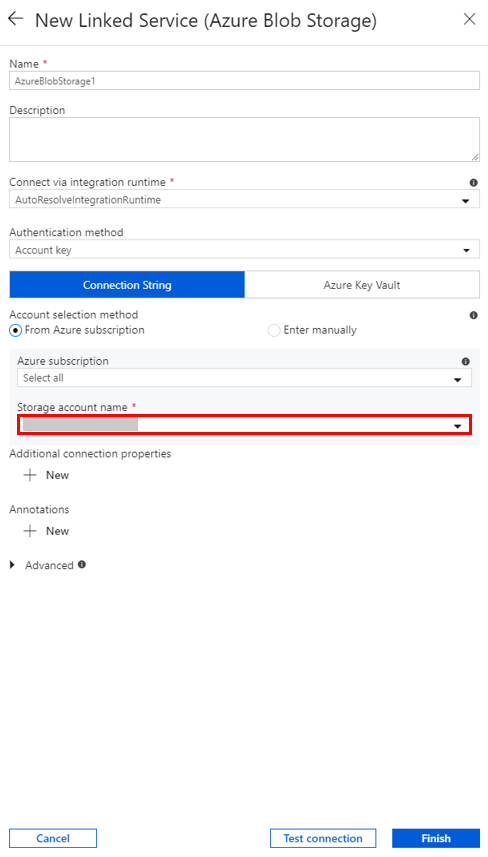
Selecteer bij Naam van opslagaccount de naam in de lijst en selecteer vervolgens Opslaan.
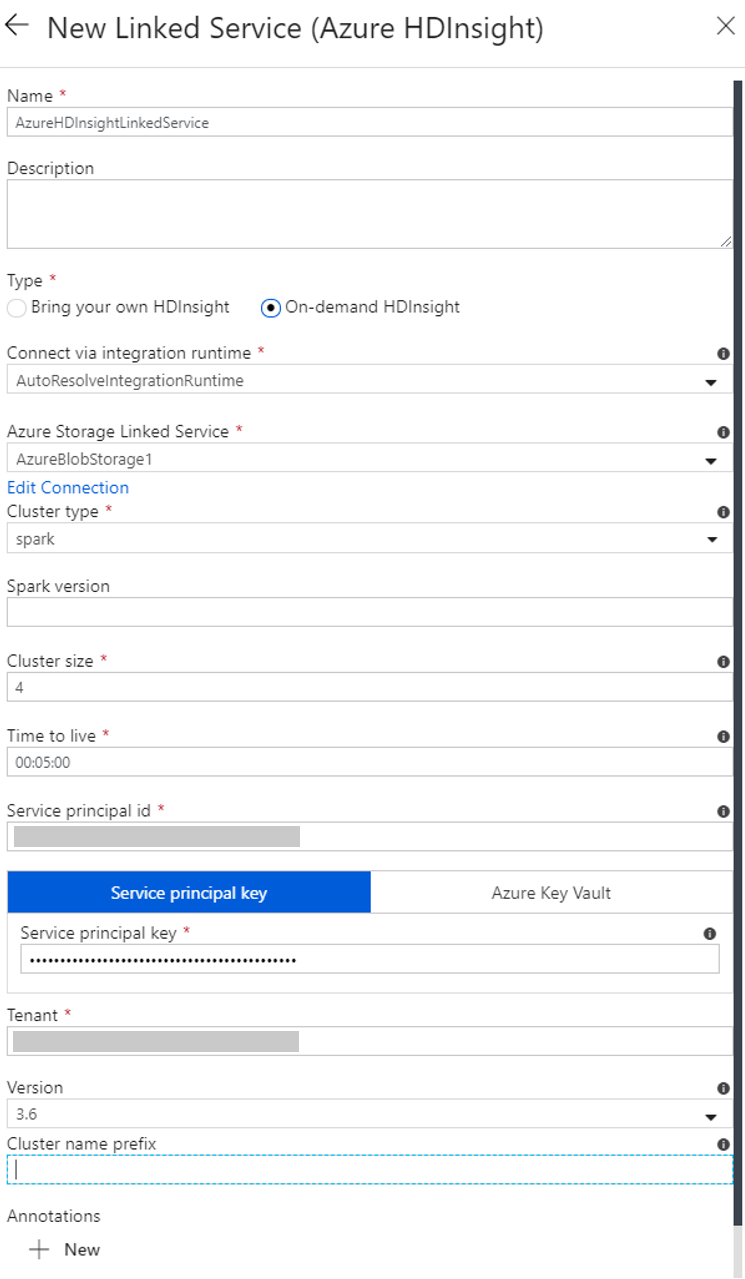
Een gekoppelde HDInsight-service op aanvraag maken
Selecteer nogmaals de knop + Nieuw om een andere gekoppelde service te maken.
Selecteer in het venster Nieuwe gekoppelde serviceCompute>Azure HDInsight en selecteer vervolgens Doorgaan.

Voer in het venster Nieuwe gekoppelde service de volgende stappen uit:
a. Voer bij NaamAzureHDInsightLinkedService in.
b. Controleer of On-demand HDInsight is geselecteerd bij Type.
c. Selecteer AzureBlobStorage1 bij Gekoppelde Azure Storage-service. U hebt deze gekoppelde service al eerder gemaakt. Als u een andere naam hebt gebruikt, geeft u hier de juiste naam op.
d. Selecteer spark bij Clustertype.
e. Voer bij Service-principal-id de id in van de service-principal die gemachtigd is om een HDInsight-cluster te maken.
Deze service-principal moet lid zijn van de rol Inzender van het abonnement of de resourcegroep waarin het cluster is gemaakt. Zie Een Microsoft Entra-toepassing en service-principal maken voor meer informatie. De service-principal-id is gelijk aan de toepassings-id en een service-principalsleutel is gelijk aan de waarde voor een clientgeheim.
f. Geef bij Sleutel van service-principal de sleutel op.
g. Selecteer bij Resourcegroep dezelfde resourcegroep die u hebt gebruikt bij het maken van de gegevensfactory. Het Spark-cluster wordt in deze resourcegroep gemaakt.
h. Vouw OS type uit.
i. Voer een naam in voor de gebruikersnaam van het cluster.
j. Voer het clusterwachtwoord voor de gebruiker in.
k. Selecteer Voltooien.
Notitie
Voor Azure HDInsight geldt een beperking voor het totale aantal kernen dat u kunt gebruiken in elke Azure-regio die wordt ondersteund. Het HDInsight-cluster voor de gekoppelde HDInsight-service op aanvraag wordt op dezelfde locatie in de Azure Storage gemaakt die wordt gebruikt als primaire opslag. Zorg ervoor dat u voldoende kerngeheugen hebt om het cluster goed te maken. Zie Clusters instellen in HDInsight met Hadoop, Spark, Kafka en meer voor meer informatie.
Een pipeline maken
Selecteer de knop + (plusteken) en selecteer vervolgens Pijplijn in het menu.
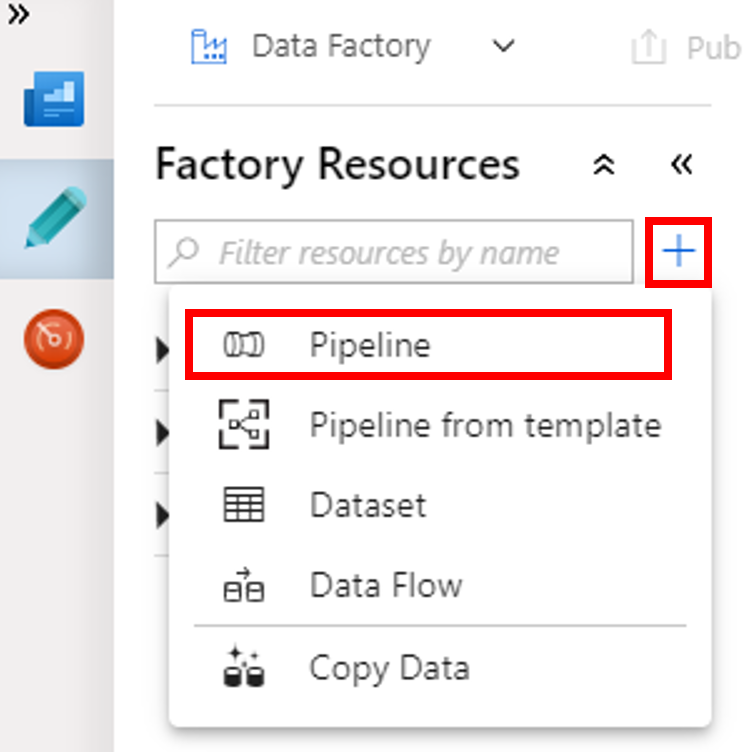
Vouw in de werkset ActiviteitenHDInsight uit. Sleep de activiteit Spark vanuit de werkset Activities naar het ontwerpoppervlak voor pijplijnen.
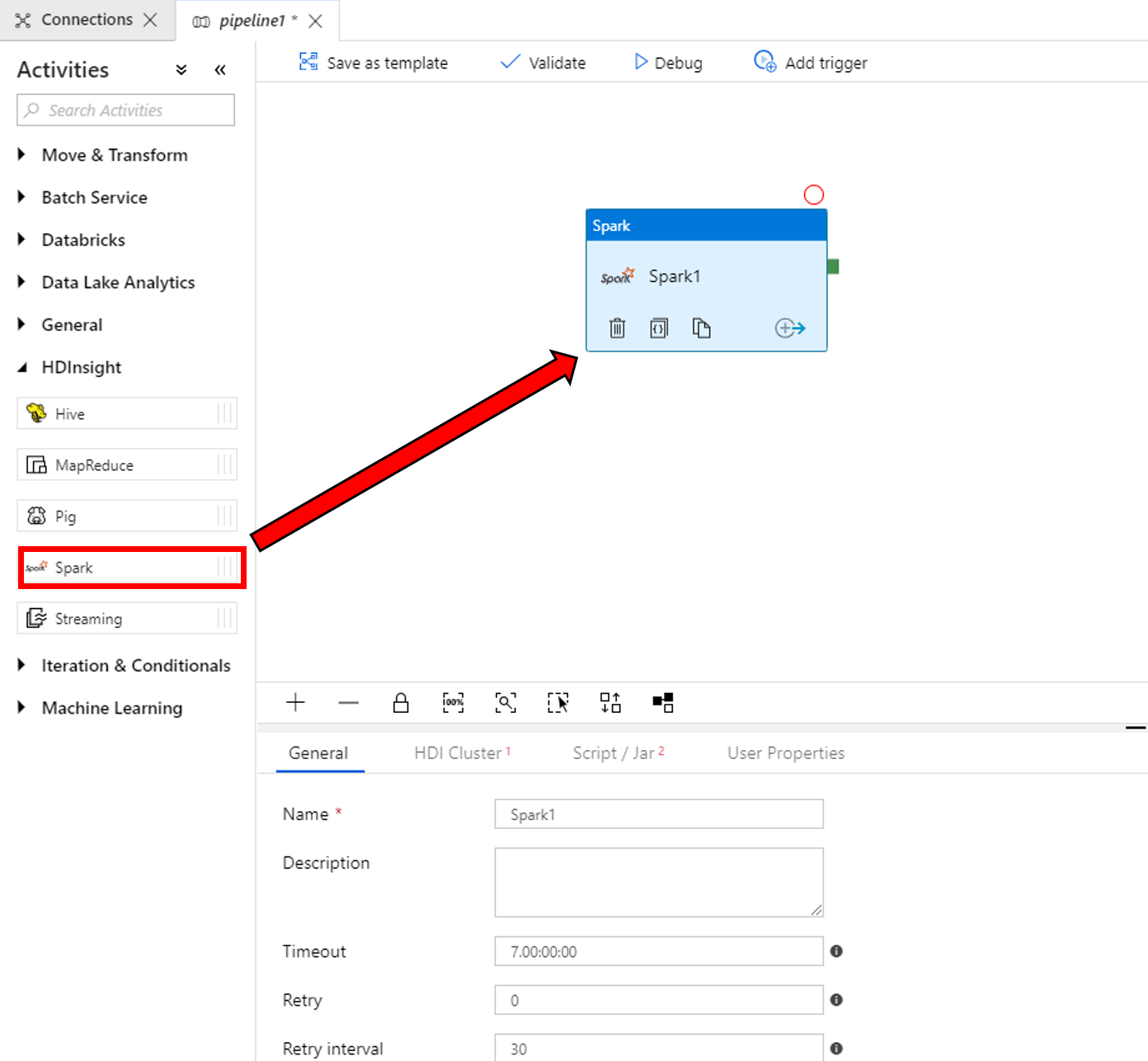
Voer de volgende stappen uit in de eigenschappen voor het Spark-activiteitvenster onderaan:
a. Ga naar het tabblad HDI-cluster.
b. Selecteer AzureHDInsightLinkedService (gemaakt in de vorige procedure).
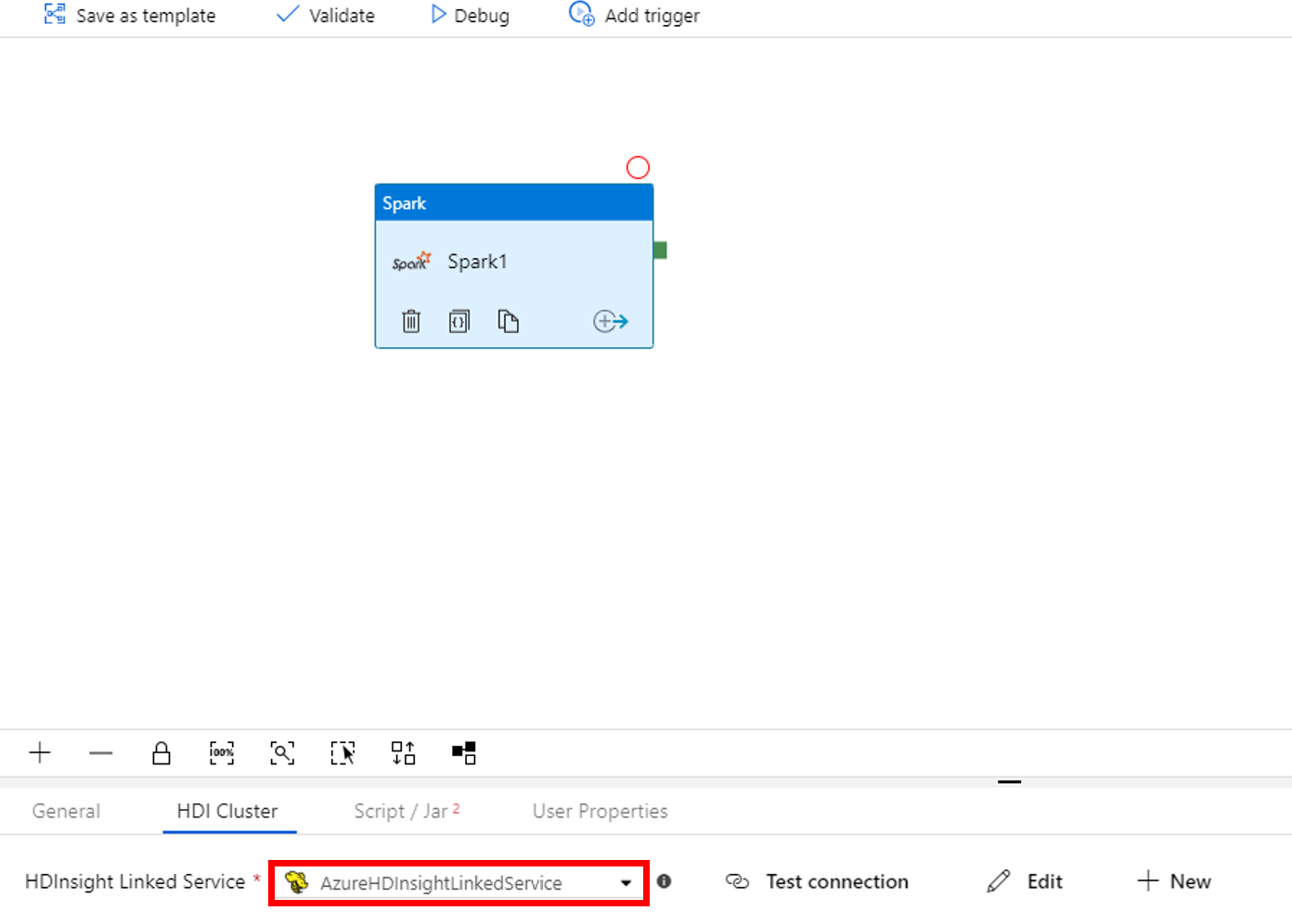
Ga naar het tabblad Script/Jar en voer de volgende stappen uit:
a. Selecteer AzureBlobStorage1 bij Taakgekoppelde service.
b. Selecteer In opslag bladeren.

c. Ga naar de map adftutorial/spark/script, selecteer WordCount_Spark.py en selecteer Voltooien.
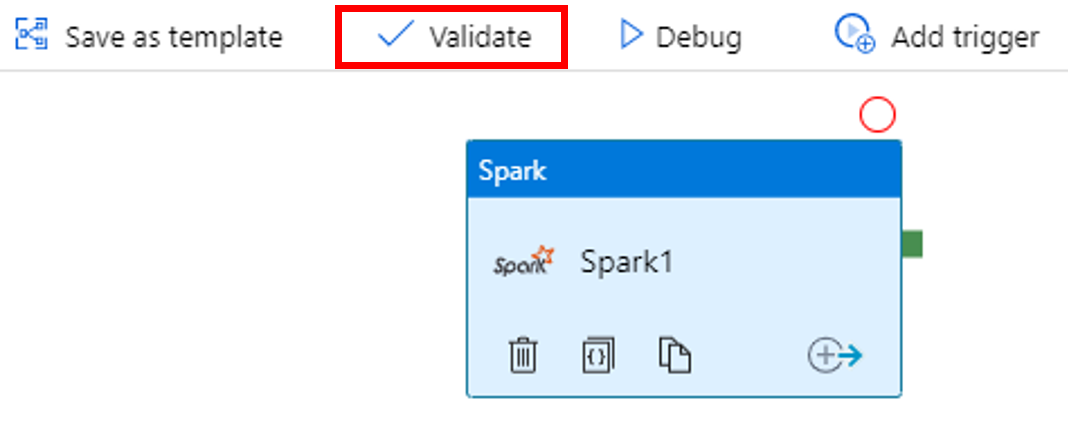
Selecteer op de werkbalk de knop Valideren om de pijplijn te valideren. Selecteer de >> (pijl-rechts) om het validatievenster te sluiten.
Selecteer Alles publiceren. De gebruikersinterface van Data Factory publiceert entiteiten (gekoppelde services en pijplijn) naar de Azure Data Factory-service.
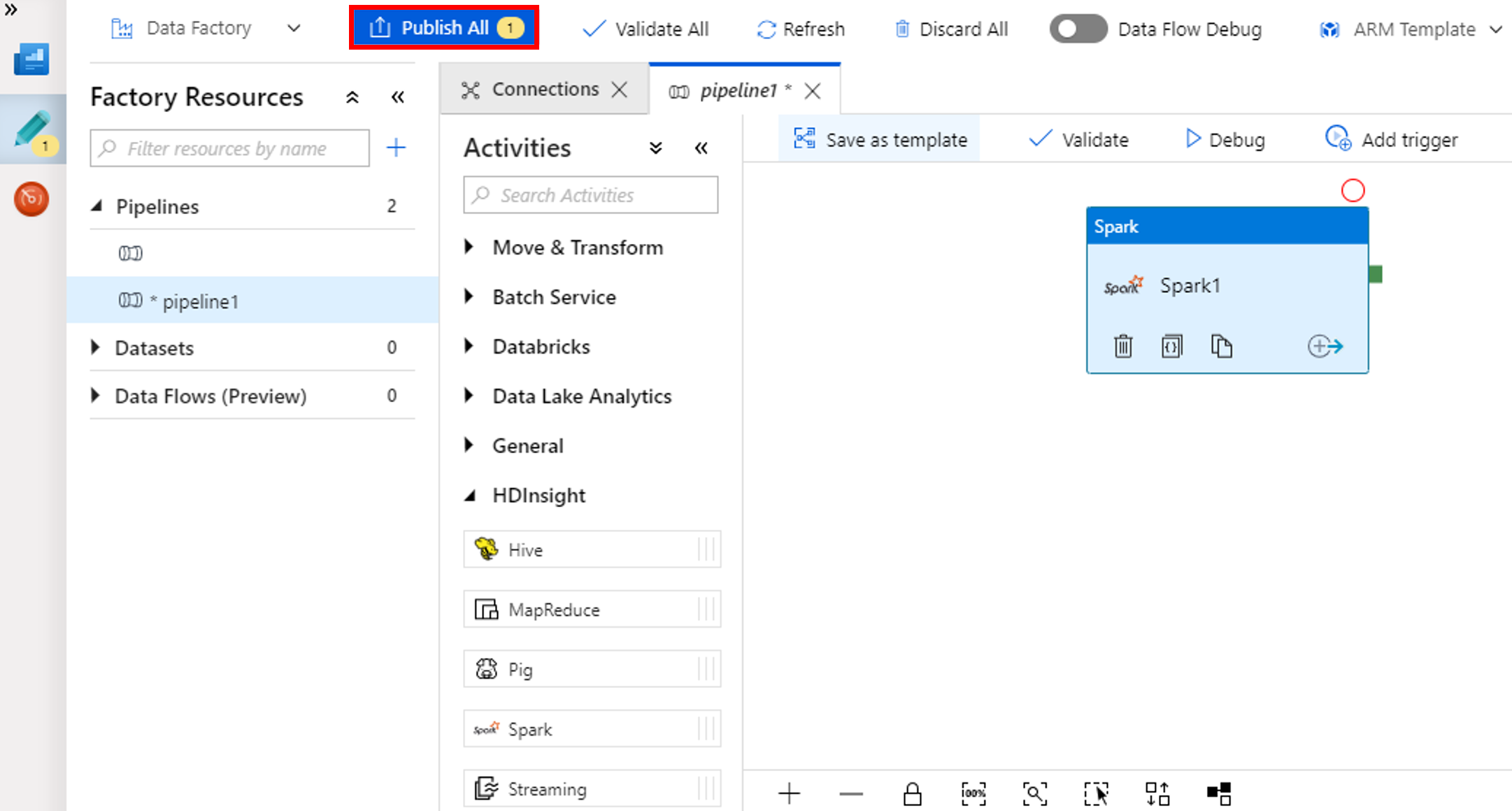
Een pijplijnuitvoering activeren
Selecteer op de werkbalk de optie Trigger toevoegen en selecteer vervolgens Nu activeren.

De pijplijnuitvoering controleren.
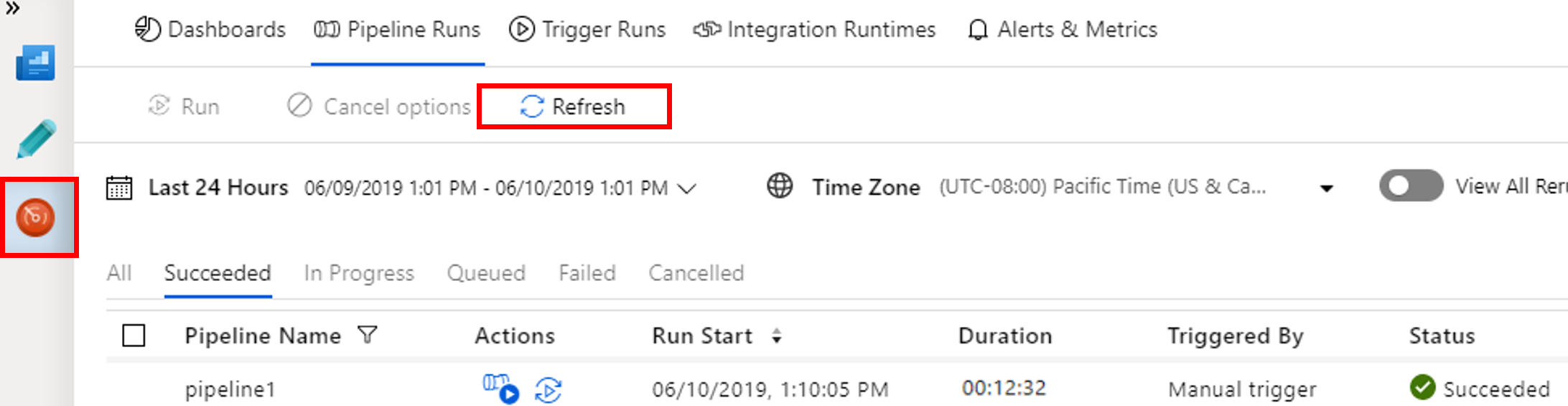
Ga naar het tabblad Controleren . Controleer of u een pijplijnuitvoering ziet. Het duurt ongeveer 20 minuten om een Spark-cluster te maken.
Selecteer regelmatig Vernieuwen om de status van de pijplijnuitvoering te controleren.
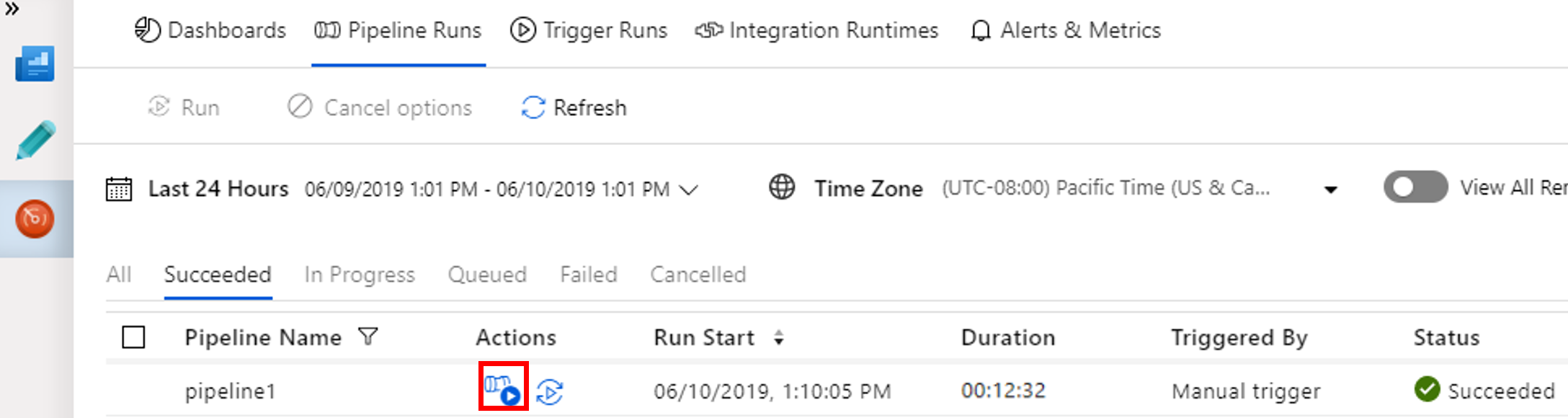
Selecteer Uitvoering van activiteiten weergeven in de kolom Acties om de uitvoering van activiteiten weer te geven die zijn gekoppeld aan de pijplijnuitvoering.
Als u wilt terugkeren naar de vorige weergave, selecteert u de koppeling Alle pijplijnuitvoeringen bovenaan.

De uitvoer controleren
Controleer of het uitvoerbestand is gemaakt in de map spark/outputfiles/wordcount van de container adftutorial.
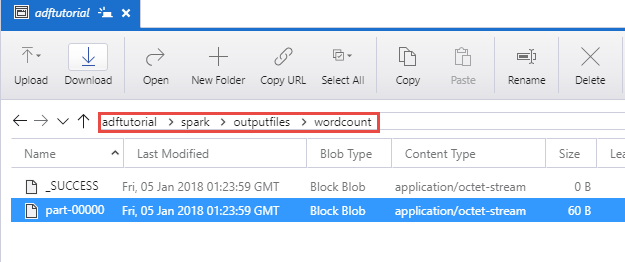
Het bestand moet elk woord uit het invoertekstbestand bevatten, plus het aantal keren dat het woord in het bestand voorkomt. Voorbeeld:
(u'This', 1)
(u'a', 1)
(u'is', 1)
(u'test', 1)
(u'file', 1)
Gerelateerde inhoud
De pijplijn in dit voorbeeld transformeert gegevens met behulp van een Spark-activiteit en een gekoppelde HDInsight-service op aanvraag. U hebt geleerd hoe u:
- Een data factory maken.
- Een pijplijn maken die een Spark-activiteit gebruikt.
- Een pijplijnuitvoering activeren.
- Controleer de pijplijnuitvoering.
Ga naar de volgende zelfstudie voor informatie over het transformeren van gegevens door een Hive-script uit te voeren in een Azure HDInsight-cluster in een virtueel netwerk: