Gegevens in een virtueel Azure-netwerk transformeren met behulp van Hive-activiteit in Azure Data Factory met Azure Portal
VAN TOEPASSING OP:  Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Tip
Probeer Data Factory uit in Microsoft Fabric, een alles-in-één analyseoplossing voor ondernemingen. Microsoft Fabric omvat alles, van gegevensverplaatsing tot gegevenswetenschap, realtime analyses, business intelligence en rapportage. Meer informatie over het gratis starten van een nieuwe proefversie .
In deze zelfstudie gebruikt u Azure Portal om een Data Factory-pijplijn te maken waarmee gegevens worden getransformeerd met behulp van Hive-activiteit in een HDInsight-cluster in een virtueel Azure-netwerk (VNet). In deze zelfstudie voert u de volgende stappen uit:
- Een data factory maken.
- Zelf-hostende Integration Runtime maken
- Gekoppelde Azure Storage- en Azure HDInsight-services maken
- Een pijplijn maken met Hive-activiteit.
- Een pijplijnuitvoering activeren.
- De pijplijnuitvoering controleren.
- De uitvoer controleren
Als u geen Azure-abonnement hebt, maakt u een gratis account voordat u begint.
Vereisten
Notitie
Het wordt aanbevolen de Azure Az PowerShell-module te gebruiken om te communiceren met Azure. Zie Azure PowerShell installeren om aan de slag te gaan. Raadpleeg Azure PowerShell migreren van AzureRM naar Az om te leren hoe u naar de Azure PowerShell-module migreert.
Azure Storage-account. U maakt een Hive-script en uploadt dit script naar de Azure-opslag. De uitvoer van het Hive-script wordt opgeslagen in dit opslagaccount. In dit voorbeeld gebruikt het HDInsight-cluster dit Azure Storage-account als primaire opslag.
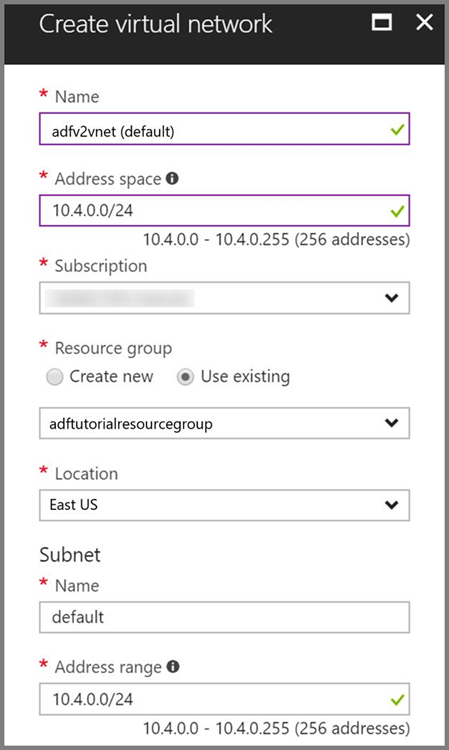
Azure Virtual Network. Als u geen virtueel Azure-netwerk hebt, maakt u er een door deze instructies te volgen. In dit voorbeeld bevindt HDInsight zich in een virtueel Azure-netwerk. Hier volgt een voorbeeldconfiguratie van Azure Virtual Network.
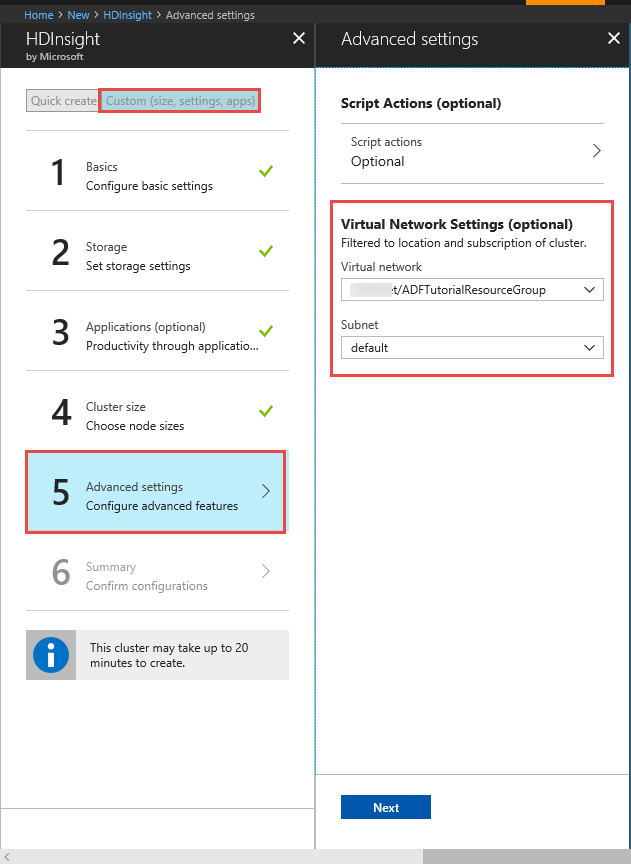
HDInsight-cluster. Maak een HDInsight-cluster en koppel dit aan het virtuele netwerk dat u in de vorige stap hebt gemaakt, door de instructies in dit artikel te volgen: Azure HDInsight uitbreiden met behulp van een virtueel Azure-netwerk. Hier volgt een voorbeeldconfiguratie van HDInsight in een virtueel netwerk.
Azure PowerShell. Volg de instructies in How to install and configure Azure PowerShell (Azure PowerShell installeren en configureren).
Een virtuele machine. Maak een Azure VM en koppel deze aan hetzelfde virtuele netwerk dat het HDInsight-cluster bevat. Zie Virtuele machines maken voor meer informatie.
Hive-script uploaden naar het Blob-opslagaccount
Maak een Hive SQL-bestand met de naam hivescript.hql met de volgende inhoud:
DROP TABLE IF EXISTS HiveSampleOut; CREATE EXTERNAL TABLE HiveSampleOut (clientid string, market string, devicemodel string, state string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE LOCATION '${hiveconf:Output}'; INSERT OVERWRITE TABLE HiveSampleOut Select clientid, market, devicemodel, state FROM hivesampletableMaak in de Azure Blob-opslag een container met de naam adftutorial als deze nog niet bestaat.
Maak een map met de naam hivescripts.
Upload het bestand hivescript.hql naar de submap hivescripts.
Een data factory maken
Als u uw data factory nog niet hebt gemaakt, volgt u de stappen in quickstart: Een gegevensfactory maken met behulp van Azure Portal en Azure Data Factory Studio om er een te maken. Nadat u deze hebt gemaakt, bladert u naar de data factory in Azure Portal.
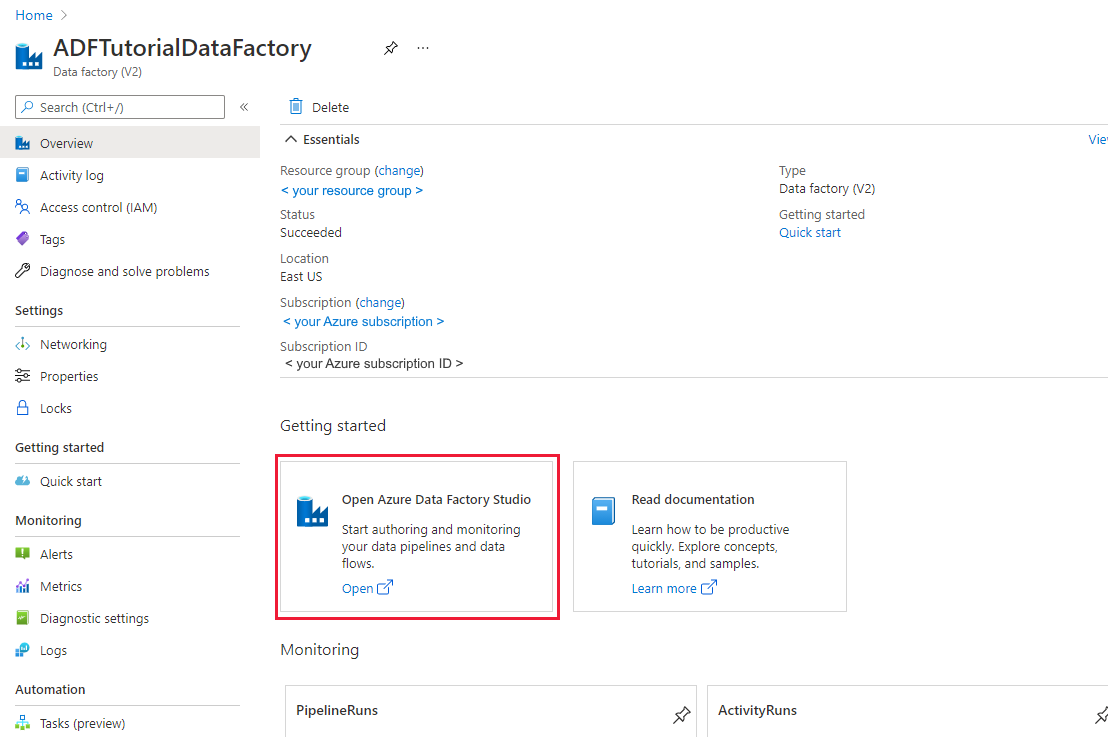
Selecteer Openen op de tegel Azure Data Factory Studio openen om de Data-Integratie toepassing op een afzonderlijk tabblad te starten.
Zelf-hostende Integration Runtime maken
Als de Hadoop-cluster zich in een virtueel netwerk bevindt, moet u een zelf-hostende Integration Runtime (IR) in hetzelfde virtuele netwerk installeren. In deze sectie maakt u een nieuwe virtuele machine die u aan hetzelfde virtuele netwerk toevoegt en waarop u een zelf-hostende IR installeert. Met de zelf-hostende IR kan de Data Factory-service verwerkingsaanvragen binnen een virtueel netwerk verzenden naar een rekenresource zoals HDInsight. Ook kunt u hiermee gegevens uit of naar gegevensarchieven binnen een virtueel netwerk verplaatsen naar Azure. U gebruikt een zelf-hostende IR wanneer ook het gegevensarchief of de rekenresource zich in een on-premises-omgeving bevindt.
Klik in de UI van Azure Data Factory op Connections onderaan het venster, ga naar het tabblad Integration Runtimes en klik op de knop + New op de werkbalk.
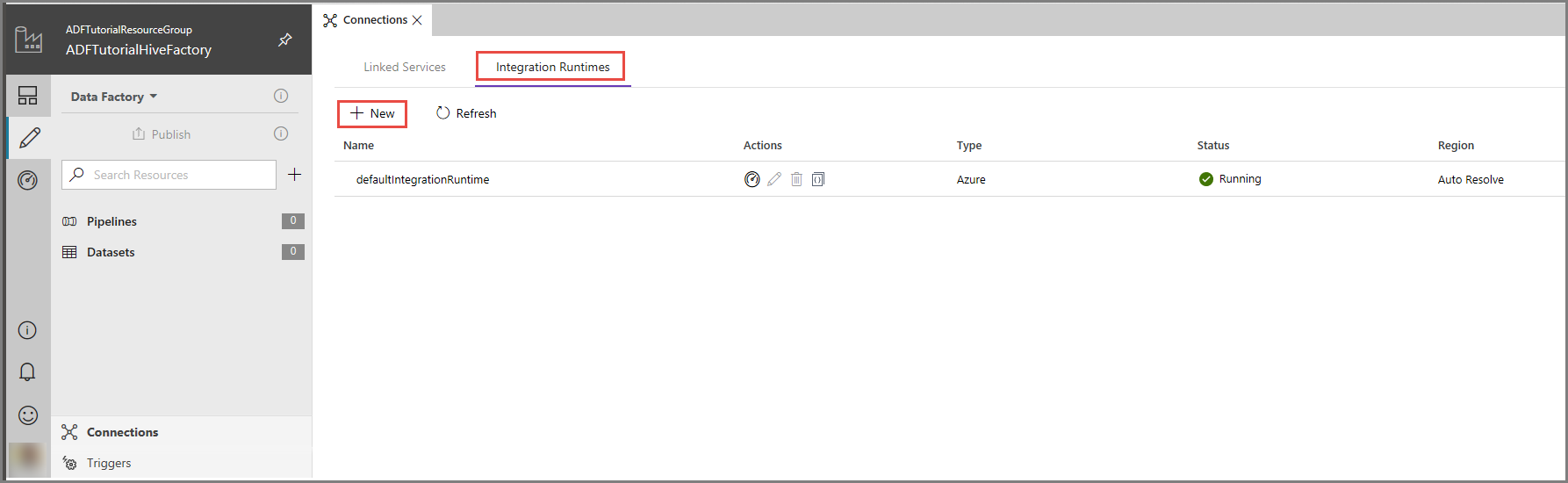
In het venster Integration Runtime Setup selecteert u de optie Perform data movement and dispatch activities to external computes en klikt u op Next.
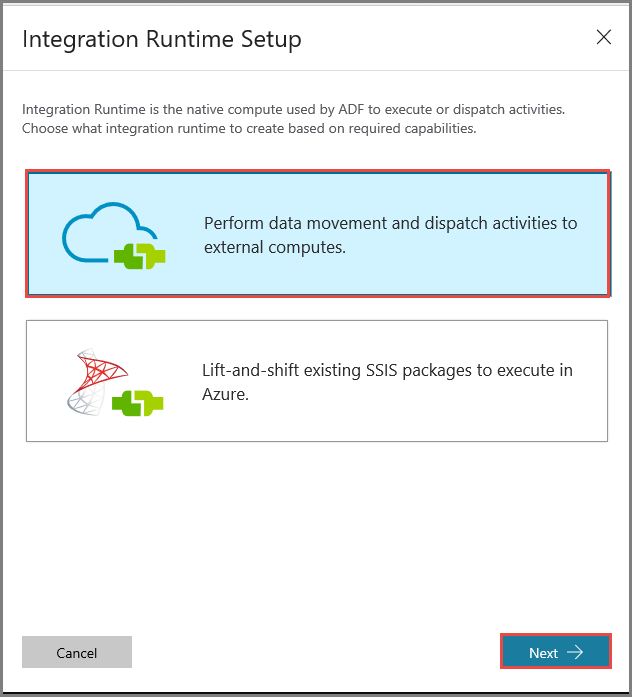
Selecteer Privénetwerk en klik op Volgende.
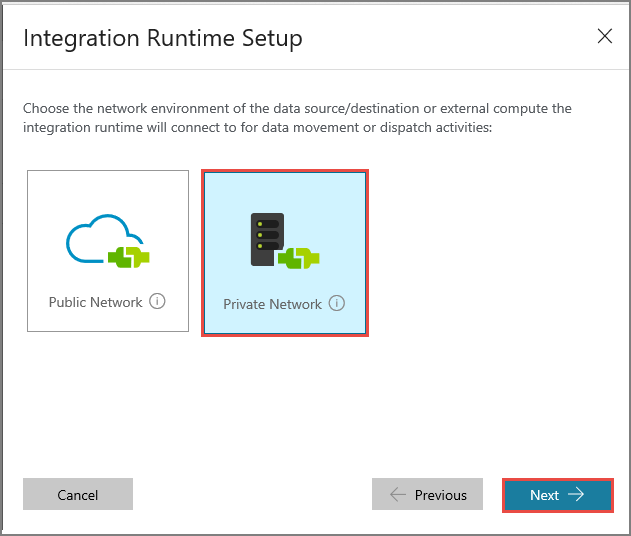
Voer MySelfHostedIR in bij Name en klik op Next.
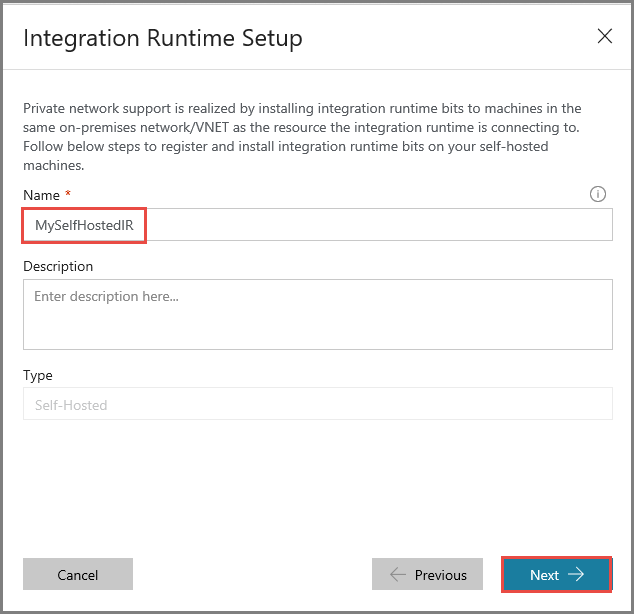
Kopieer de verificatiesleutel voor de Integration Runtime door te klikken op de knop voor kopiëren en sla de sleutel op. Houd het venster geopend. U gebruikt deze sleutel om de in een virtuele machine geïnstalleerde IR te registreren.
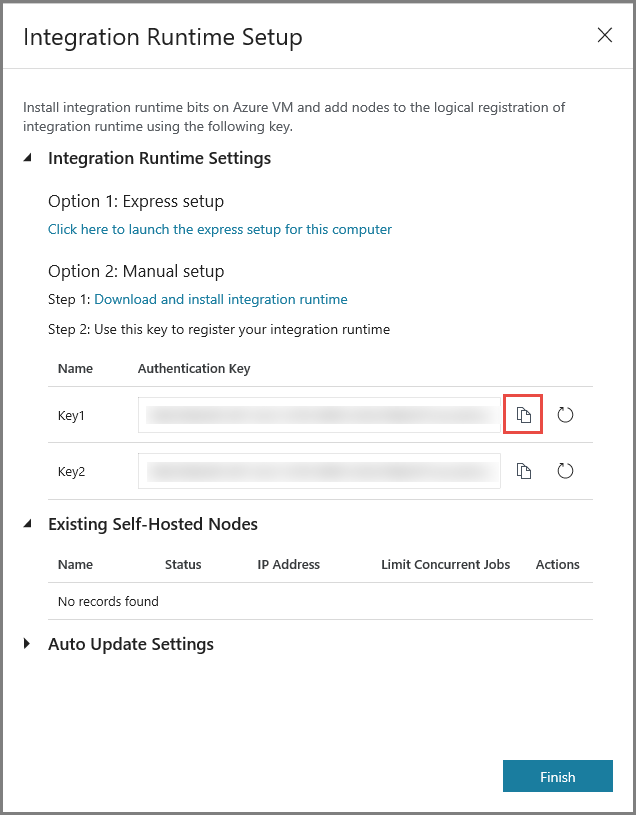
IR installeren op een virtuele machine
Download de zelf-hostende integratieruntime op de virtuele Azure-machine. Gebruik de in de vorige stap verkregen verificatiesleutel om de zelf-hostende Integration Runtime handmatig te registreren.
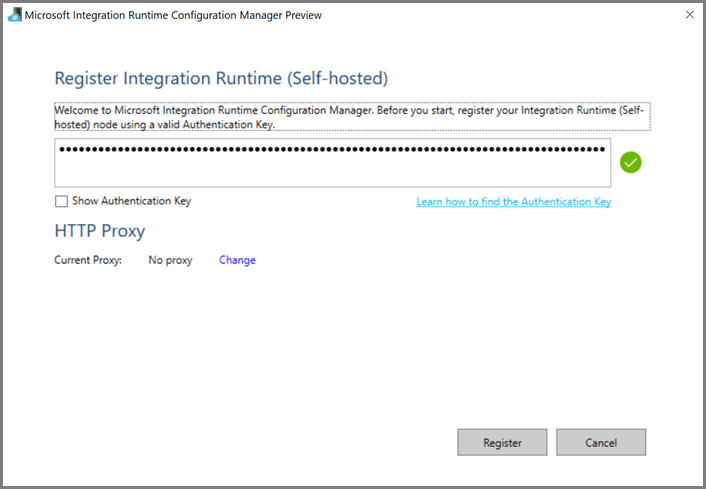
U ziet het volgende bericht wanneer de zelf-hostende Integration Runtime is geregistreerd.
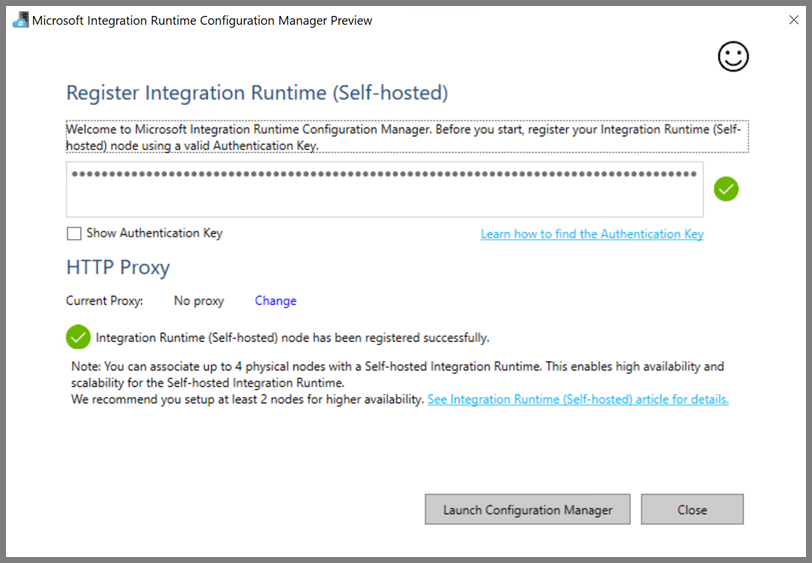
Klik op Launch Configuration Manager. Wanneer het knooppunt is verbonden met de cloudservice, ziet u de volgende pagina:
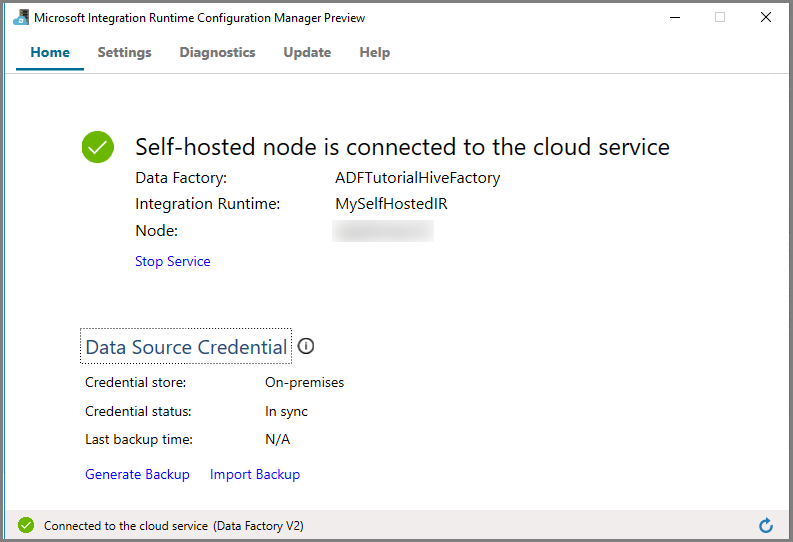
Zelf-hostende IR in de UI van Azure Data Factory
In de Azure Data Factory UI moet de naam van de zelf-hostende VM en de status ervan worden weergegeven.
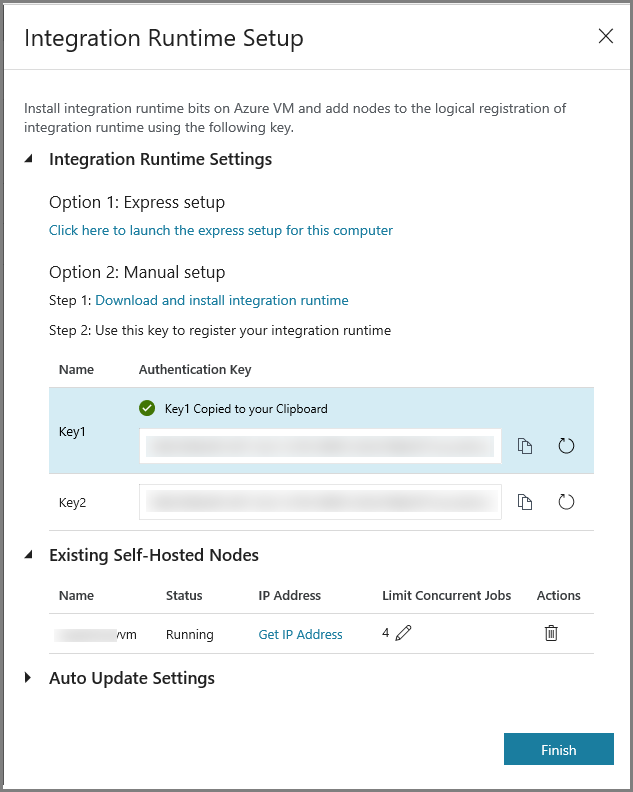
Klik op Finish om het venster Integration Runtime Setup te sluiten. De zelf-hostende IR wordt vermeld in de lijst met integratieruntimes.

Gekoppelde services maken
In deze sectie maakt en implementeert u twee gekoppelde services:
- Een gekoppelde Azure Storage-service waarmee een Azure Storage-account wordt gekoppeld aan de gegevensfactory. Deze opslag is de primaire opslag die wordt gebruikt voor het HDInsight-cluster. In dit geval gebruikt u dit Azure Storage-account ook om het Hive-script en de uitvoer van het script op te slaan.
- Een gekoppelde HDInsight-service. Azure Data Factory verzendt het Hive-script naar dit HDInsight-cluster voor uitvoering.
Een gekoppelde Azure Storage-service maken
Open het tabblad New Linked Service en klik op New.
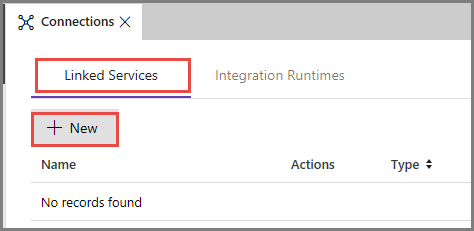
In het venster New Linked Service selecteert u Azure Blob Storage en klikt u op Continue.
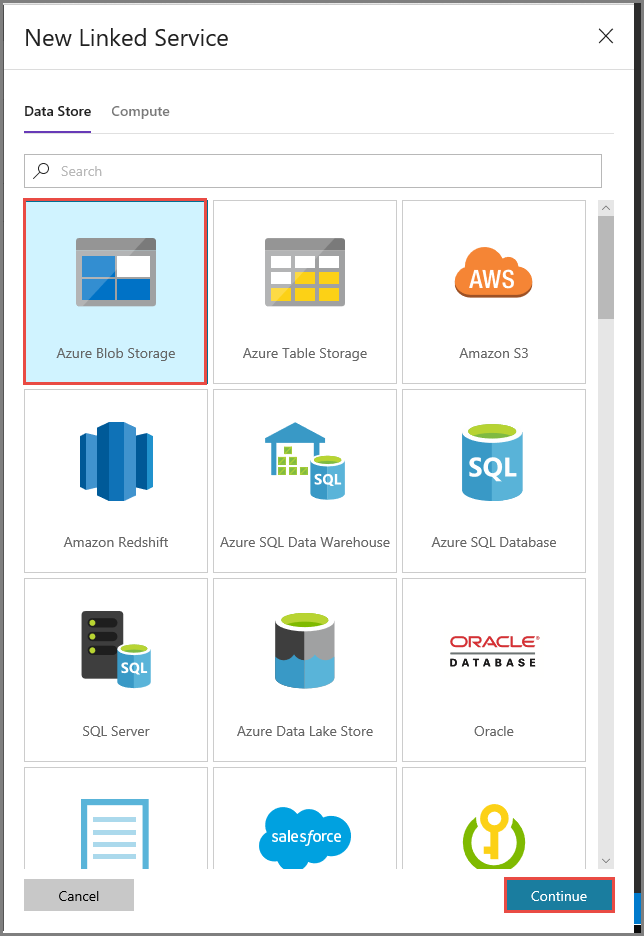
Voer in het venster New Linked Service de volgende stappen uit:
Voer AzureStorageLinkedService in als Naam.
Selecteer MySelfHostedIR bij Connect via integration runtime.
Selecteer uw Azure Storage-account als naam van het opslagaccount.
Als u de verbinding met de storage-account wilt testen, klikt u op Test connection.
Klik op Opslaan.
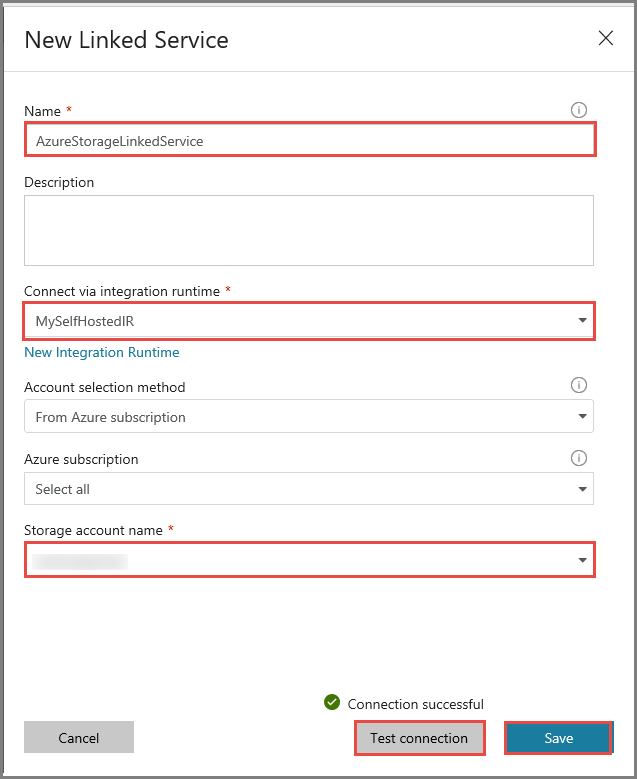
Gekoppelde HDInsight-service maken
Klik nogmaals op New om een andere gekoppelde service te maken.
Open het tabblad Compute, selecteer Azure HDInsight en klik op Continue.
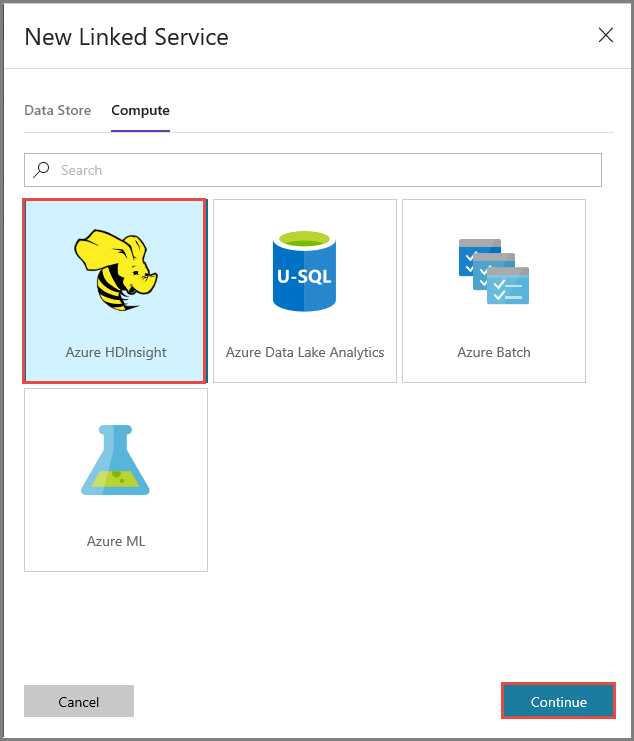
Voer in het venster New Linked Service de volgende stappen uit:
Voer AzureHDInsightLinkedService in als Name.
Selecteer Bring your own HDInsight.
Selecteer uw HDInsight-cluster bij Hdi cluster.
Voer de gebruikersnaam voor het HDInsight-cluster in.
Voer het wachtwoord voor de gebruiker in.
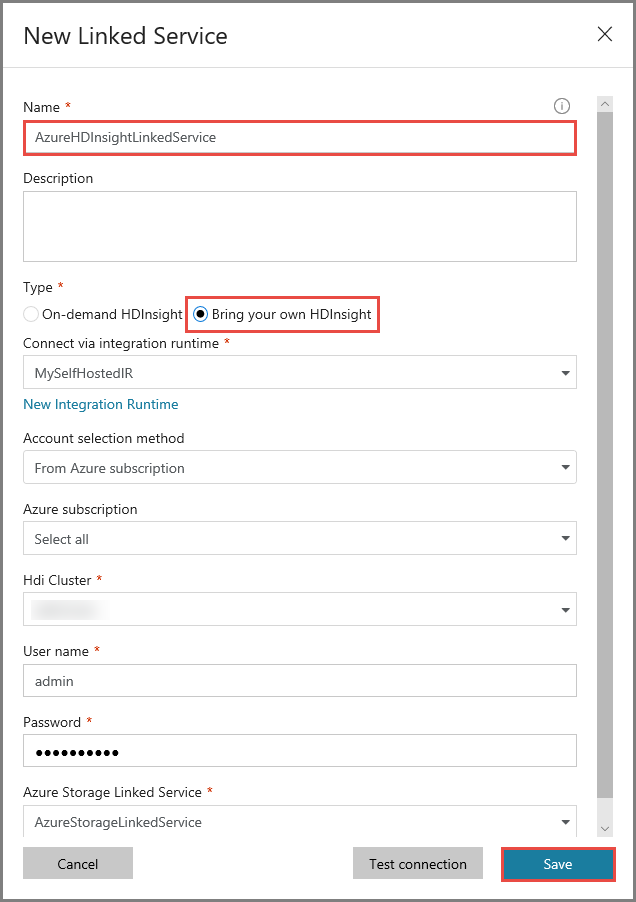
In dit artikel wordt ervan uitgegaan dat u via internet toegang hebt tot het cluster. Bijvoorbeeld, dat u verbinding met het cluster kunt maken op https://clustername.azurehdinsight.net. Dit adres maakt gebruik van de openbare gateway. Deze is niet beschikbaar als u NSG's (netwerkbeveiligingsgroepen) of door de gebruiker gedefinieerde routes hebt gebruikt om de toegang via internet te beperken. U moet het virtuele Azure-netwerk zo configureren dat de URL kan worden omgezet in een privé-IP-adres of een privégateway voor HDInsight, om ervoor te zorgen dat Data Factory taken kan verzenden naar het HDInsight-cluster in het virtuele Azure-netwerk.
Open in Azure Portal het virtuele netwerk waarin het HDInsight-cluster zich bevindt. Open de netwerkinterface met de naam die begint met
nic-gateway-0. Noteer het bijbehorende privé IP-adres. Bijvoorbeeld: 10.6.0.15.Als het virtuele Azure-netwerk een DNS-server heeft, werkt u de DNS-record bij zodat de URL van het HDInsight-cluster
https://<clustername>.azurehdinsight.netkan worden omgezet in10.6.0.15. Als u geen DNS-server in uw virtuele Azure-netwerk hebt, kunt u dit tijdelijk oplossen door het hostbestand (C:\Windows\System32\drivers\etc) te bewerken van alle VM's die als knooppunten van Integration Runtime (zelf-hostend) zijn geregistreerd. Dit doet u door een soortgelijke vermelding als de volgende toe te voegen:10.6.0.15 myHDIClusterName.azurehdinsight.net
Een pipeline maken
In deze stap maakt u een nieuwe pijplijn met een Hive-activiteit. Met deze activiteit wordt een Hive-script uitgevoerd om gegevens uit een voorbeeldtabel te retourneren en op te slaan in een pad dat u hebt gedefinieerd.
Let op de volgende punten:
- scriptPath verwijst naar het pad naar het Hive-script in het Azure Storage-account dat u hebt gebruikt voor MyStorageLinkedService. Het pad is hoofdlettergevoelig.
- Output is een argument dat wordt gebruikt in het Hive-script. Gebruik de indeling van
wasbs://<Container>@<StorageAccount>.blob.core.windows.net/outputfolder/om dit argument te laten verwijzen naar een bestaande map in de Azure-opslag. Het pad is hoofdlettergevoelig.
Klik in de Data Factory-gebruikersinterface op + (plus) in het linkerdeelvenster en klik op Pipeline.
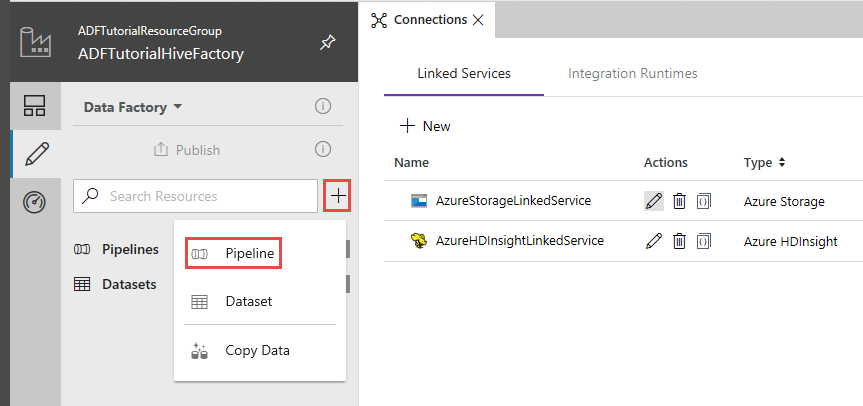
Vouw HDInsight uit in de werkset Activities en sleep de activiteit Hive naar het ontwerpoppervlak voor pijplijnen.
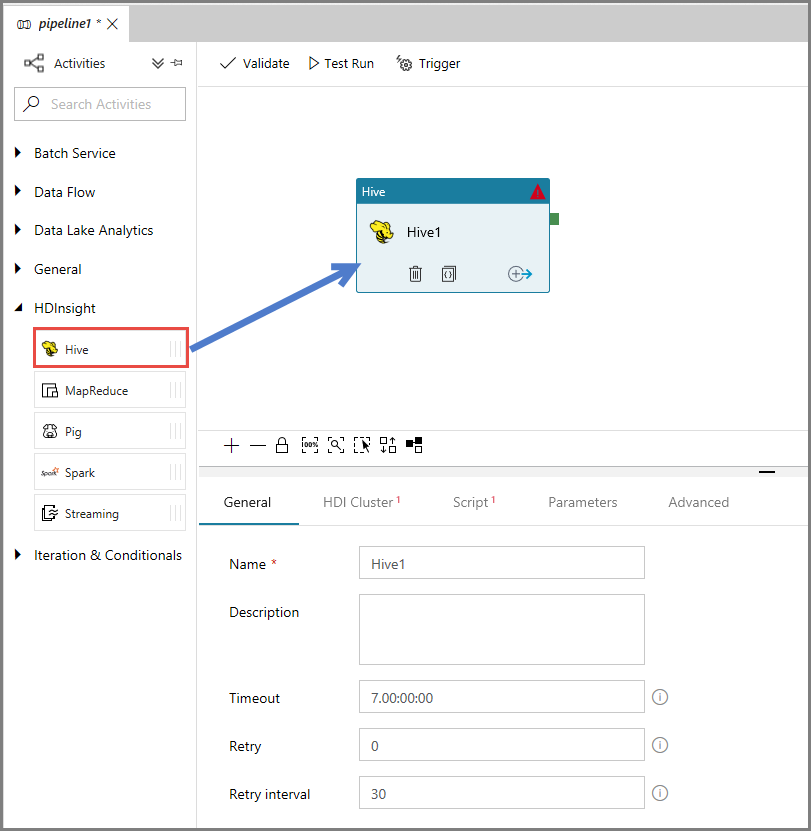
Ga vanuit het eigenschappenvenster naar het tabblad HDI Cluster en selecteer AzureHDInsightLinkedService bij HDInsight Linked Service.

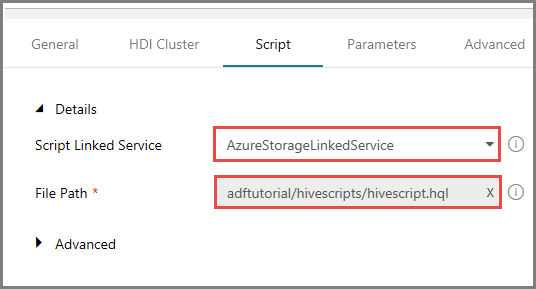
Open het tabblad Scripts en voer de volgende stappen uit:
Selecteer AzureStorageLinkedService bij Script Linked Service.
Klik bij File Path op Browse Storage.
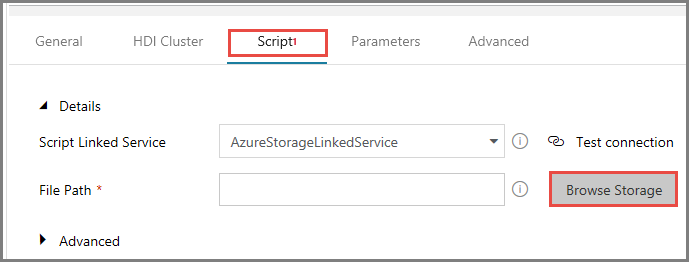
Ga in het venster Choose a file or folder naar de map hivescripts van de container adftutorial, selecteer hivescript.hql en klik op Finish.
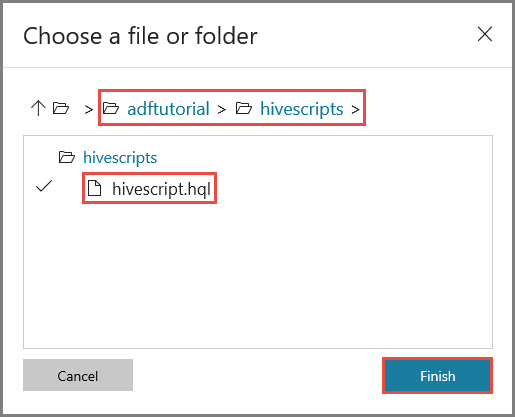
Controleer of adftutorial/hivescripts/hivescript.hql wordt weergegeven bij File Path.
Op het tabblad Script vouwt u de sectie Advanced uit.
Klik op Auto-fill from script bij Parameters.
Voer de waarde in voor de Output-parameter in de volgende indeling:
wasbs://<Blob Container>@<StorageAccount>.blob.core.windows.net/outputfolder/. Voorbeeld:wasbs://adftutorial@mystorageaccount.blob.core.windows.net/outputfolder/.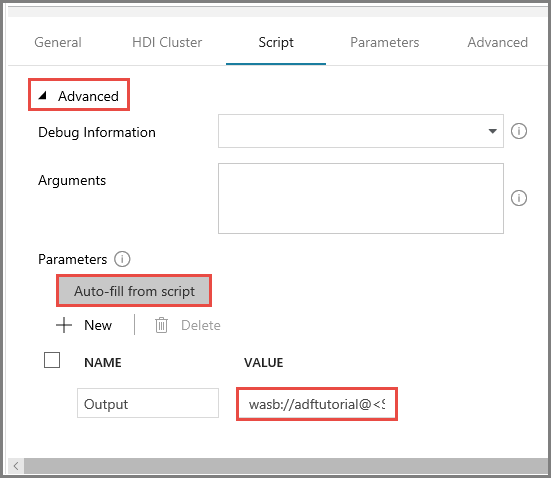
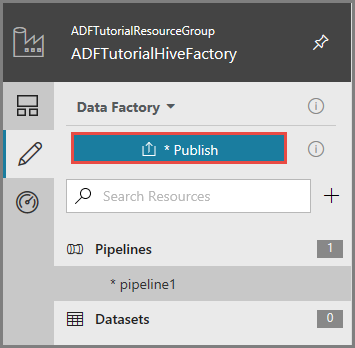
Als u artefacten naar Data Factory wilt publiceren, klikt u op Publish.
Een pijplijnuitvoering activeren
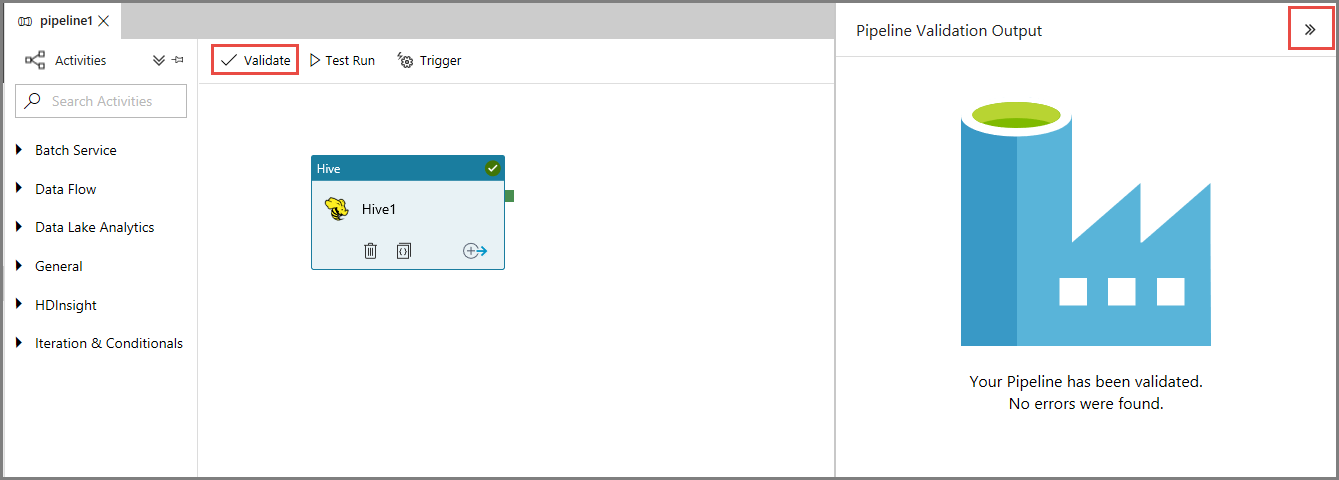
Valideer eerst de pijplijn door te klikken op de knop Validate op de werkbalk. Sluit het venster Pijplijnvalidatie-uitvoer door op de pijl-rechts (>>)te klikken.
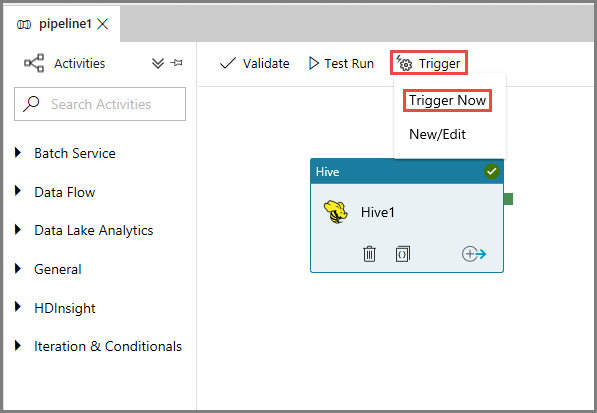
Klik in de werkbalk op Activeren en klik op Nu activeren om een pijplijnuitvoering te activeren.
De pijplijnuitvoering controleren.
Ga naar het tabblad Controleren aan de linkerkant. U ziet een pijplijn die worden uitgevoerd in de lijst Pipeline Runs.
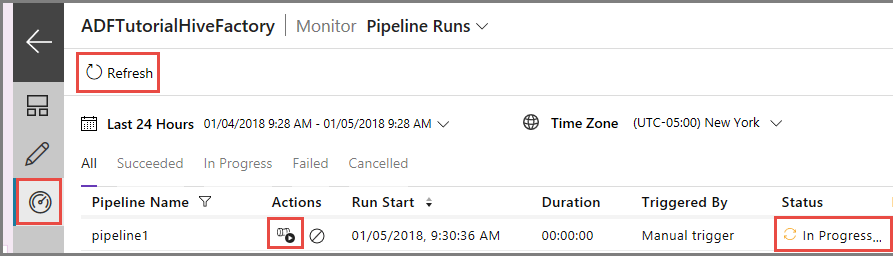
Als u de lijst wilt vernieuwen, klikt u op Refresh.
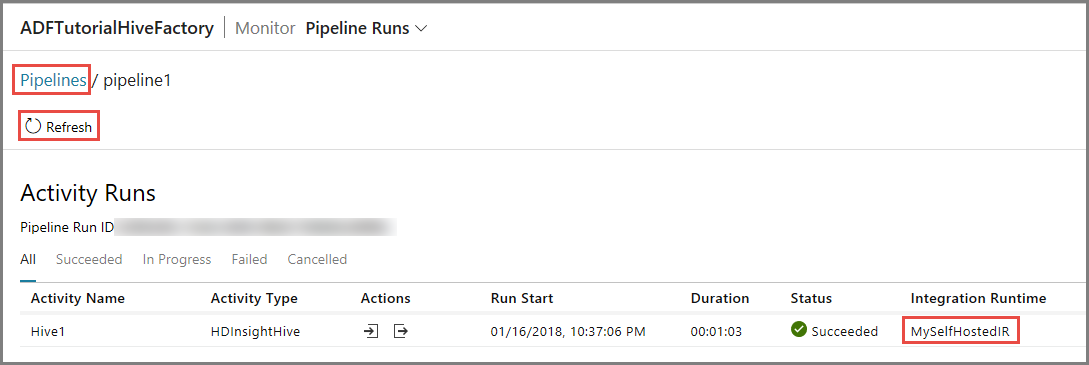
Uitvoeringen van activiteit die aan de pijplijn zijn gekoppeld, kunt u bekijken door te klikken op View activity runs in de kolom Action. Andere actiekoppelingen zijn voor het stoppen en opnieuw uitvoeren van de pijplijn.
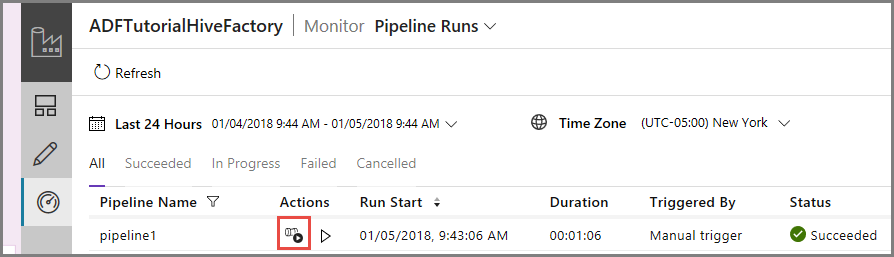
U ziet dat er slechts één activiteit actief is omdat er slechts één activiteit in de pijplijn van het type HDInsightHive is. Als u wilt terugkeren naar de vorige weergave, klikt u op de koppeling Pipelines bovenaan.
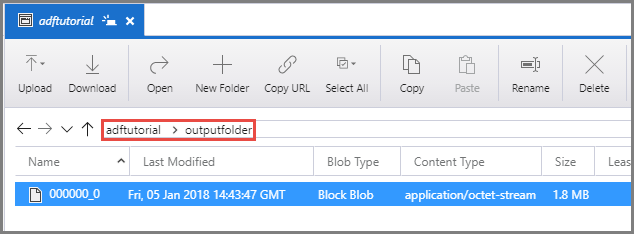
Controleer of er een uitvoerbestand in de outputfolder van de container adftutorial wordt weergegeven.
Gerelateerde inhoud
In deze zelfstudie hebt u de volgende stappen uitgevoerd:
- Een data factory maken.
- Zelf-hostende Integration Runtime maken
- Gekoppelde Azure Storage- en Azure HDInsight-services maken
- Een pijplijn maken met Hive-activiteit.
- Een pijplijnuitvoering activeren.
- De pijplijnuitvoering controleren.
- De uitvoer controleren
Ga naar de volgende zelfstudie voor meer informatie over het transformeren van gegevens met behulp van een Spark-cluster in Azure: