Incrementeel gegevens uit meerdere tabellen in SQL Server naar Azure SQL Database kopiëren met behulp van PowerShell
VAN TOEPASSING OP:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Probeer Data Factory uit in Microsoft Fabric, een alles-in-één analyseoplossing voor ondernemingen. Microsoft Fabric omvat alles, van gegevensverplaatsing tot gegevenswetenschap, realtime analyses, business intelligence en rapportage. Meer informatie over het gratis starten van een nieuwe proefversie .
In deze zelfstudie maakt u een Azure-gegevensfactory met een pijplijn waarmee wijzigingsgegevens uit meerdere tabellen van een SQL Server-database naar Azure SQL Database worden gekopieerd.
In deze zelfstudie voert u de volgende stappen uit:
- Bereid de bron- en doelserver gegevensopslag voor.
- Een data factory maken.
- Een zelf-hostende Integration Runtime maken.
- De Integration Runtime installeren.
- Maak gekoppelde services.
- Maak bron-, sink- en grenswaardegegevenssets.
- Maken, starten en controleren van een pijplijn.
- Controleer de resultaten.
- Gegevens in brontabellen toevoegen of bijwerken.
- De pijplijn opnieuw uitvoeren en controleren.
- De eindresultaten bekijken.
Overzicht
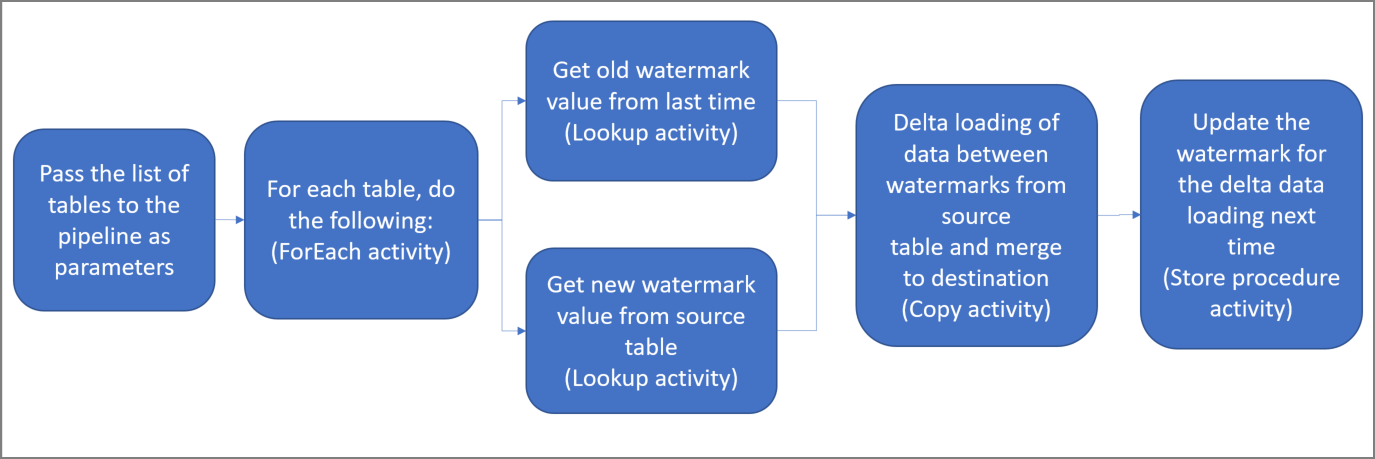
Dit zijn de belangrijke stappen voor het maken van deze oplossing:
Selecteer de grenswaardekolom.
Selecteer één kolom in elke tabel van de brongegevensopslag, die kan worden gebruikt om de nieuwe of bijgewerkte records voor elke uitvoering te segmenteren. Normaal gesproken nemen de gegevens in deze geselecteerde kolom (bijvoorbeeld, last_modify_time of id) toe wanneer de rijen worden gemaakt of bijgewerkt. De maximale waarde in deze kolom wordt gebruikt als grenswaarde.
Bereid een gegevensopslag voor om de grenswaarde in op te slaan.
In deze zelfstudie slaat u de grenswaarde op in een SQL-database.
Maak een pijplijn met de volgende activiteiten:
Maak een ForEach-activiteit die door een lijst met namen van gegevensbrontabellen loopt, die als parameter is doorgegeven aan de pijplijn. Voor elke brontabel roept deze de volgende activiteiten voor het laden van de deltagegevens voor deze tabel op.
Maak twee opzoekactiviteiten. Gebruik de eerste opzoekactiviteit om de laatste grenswaarde op te halen. Gebruik de tweede opzoekactiviteit om de nieuwe grenswaarde op te halen. Deze grenswaarden worden doorgegeven aan de kopieeractiviteit.
Maak een Copy-activiteit waarmee rijen uit het brongegevensarchief worden gekopieerd met de waarde van de watermerkkolom groter dan de oude grenswaarde en kleiner dan of gelijk aan de nieuwe watermerkwaarde. Vervolgens worden de deltagegevens uit de brongegevensopslag als een nieuw bestand gekopieerd naar een Azure Blob-opslag.
Maak een opgeslagen-procedureactiviteit waarmee de grenswaarde wordt bijgewerkt voor de pijplijn die de volgende keer wordt uitgevoerd.
Hier volgt de diagramoplossing op hoog niveau:
Als u geen Azure-abonnement hebt, maakt u een gratis account voordat u begint.
Vereisten
- SQL Server. In deze zelfstudie gebruikt u een SQL Server-database als een brongegevensopslag.
- Azure SQL-database. U gebruikt een database in Azure SQL Database als de sink-gegevensopslag. Als u geen SQL-database hebt, raadpleegt u het artikel Een Azure SQL Database maken voor de stappen voor het maken van een database.
Brontabellen maken in uw SQL Server-database
Open SQL Server Management Studio (SSMS) of Azure Data Studio en maak verbinding met de SQL Server-database.
In Server Explorer (SSMS) of in het deelvenster Verbindingen (Azure Data Studio) klikt u met de rechtermuisknop op de database en kiest u Nieuwe query.
Voer de volgende SQL-opdracht uit op uw database om tabellen te maken met de naam
customer_tableenproject_table:create table customer_table ( PersonID int, Name varchar(255), LastModifytime datetime ); create table project_table ( Project varchar(255), Creationtime datetime ); INSERT INTO customer_table (PersonID, Name, LastModifytime) VALUES (1, 'John','9/1/2017 12:56:00 AM'), (2, 'Mike','9/2/2017 5:23:00 AM'), (3, 'Alice','9/3/2017 2:36:00 AM'), (4, 'Andy','9/4/2017 3:21:00 AM'), (5, 'Anny','9/5/2017 8:06:00 AM'); INSERT INTO project_table (Project, Creationtime) VALUES ('project1','1/1/2015 0:00:00 AM'), ('project2','2/2/2016 1:23:00 AM'), ('project3','3/4/2017 5:16:00 AM');
Doeltabellen in uw Azure SQL Database maken
Open SQL Server Management Studio (SSMS) of Azure Data Studio en maak verbinding met de SQL Server-database.
In Server Explorer (SSMS) of in het deelvenster Verbindingen (Azure Data Studio) klikt u met de rechtermuisknop op de database en kiest u Nieuwe query.
Voer de volgende SQL-opdracht uit op uw database om tabellen te maken met de naam
customer_tableenproject_table:create table customer_table ( PersonID int, Name varchar(255), LastModifytime datetime ); create table project_table ( Project varchar(255), Creationtime datetime );
Nog een tabel in Azure SQL Database maken om de bovengrenswaarde op te slaan
Voer de volgende SQL-opdracht uit op uw database om een tabel met de naam
watermarktablete maken om de bovengrenswaarde op te slaan:create table watermarktable ( TableName varchar(255), WatermarkValue datetime, );Initiële watermerkwaarden voor beide brontabellen in de watermerktabel invoegen.
INSERT INTO watermarktable VALUES ('customer_table','1/1/2010 12:00:00 AM'), ('project_table','1/1/2010 12:00:00 AM');
Een opgeslagen procedure maken in de Azure SQL Database
Voer de volgende opdracht uit om een opgeslagen procedure te maken in uw database. Deze opgeslagen procedure werkt de bovengrenswaarde bij elke pijplijnuitvoering bij.
CREATE PROCEDURE usp_write_watermark @LastModifiedtime datetime, @TableName varchar(50)
AS
BEGIN
UPDATE watermarktable
SET [WatermarkValue] = @LastModifiedtime
WHERE [TableName] = @TableName
END
Gegevenstypen en aanvullende opgeslagen procedures maken in Azure SQL Database
Voer de volgende query uit om twee opgeslagen procedures en twee gegevenstypen in uw database te maken. Deze worden gebruikt voor het samenvoegen van de gegevens uit de brontabellen in doeltabellen.
Om het begin van de beleving toegankelijk te houden, gebruiken we direct deze opgeslagen procedures. Hiermee worden de deltagegevens doorgegeven via een tabelvariabele en vervolgens samengevoegd in het doelarchief. Let erop dat er geen 'groot' aantal deltarijen (meer dan 100) wordt verwacht dat moet worden opgeslagen in de tabelvariabele.
Als u een groot aantal deltarijen in het doelarchief moet samenvoegen, kunt u het beste de kopieeractiviteit gebruiken om alle deltagegevens te kopiëren naar een tijdelijke “faseringstabel” in het doelarchief. Vervolgens moet u uw eigen opgeslagen procedure maken zonder tabelvariabelen te gebruiken om ze te kunnen samenvoegen vanuit de “faseringstabel” in de “definitieve tabel”.
CREATE TYPE DataTypeforCustomerTable AS TABLE(
PersonID int,
Name varchar(255),
LastModifytime datetime
);
GO
CREATE PROCEDURE usp_upsert_customer_table @customer_table DataTypeforCustomerTable READONLY
AS
BEGIN
MERGE customer_table AS target
USING @customer_table AS source
ON (target.PersonID = source.PersonID)
WHEN MATCHED THEN
UPDATE SET Name = source.Name,LastModifytime = source.LastModifytime
WHEN NOT MATCHED THEN
INSERT (PersonID, Name, LastModifytime)
VALUES (source.PersonID, source.Name, source.LastModifytime);
END
GO
CREATE TYPE DataTypeforProjectTable AS TABLE(
Project varchar(255),
Creationtime datetime
);
GO
CREATE PROCEDURE usp_upsert_project_table @project_table DataTypeforProjectTable READONLY
AS
BEGIN
MERGE project_table AS target
USING @project_table AS source
ON (target.Project = source.Project)
WHEN MATCHED THEN
UPDATE SET Creationtime = source.Creationtime
WHEN NOT MATCHED THEN
INSERT (Project, Creationtime)
VALUES (source.Project, source.Creationtime);
END
Azure PowerShell
Installeer de nieuwste Azure PowerShell-modules met de instructies in Azure PowerShell installeren en configureren.
Een data factory maken
Definieer een variabele voor de naam van de resourcegroep die u later gaat gebruiken in PowerShell-opdrachten. Kopieer de tekst van de volgende opdracht naar PowerShell, geef tussen dubbele aanhalingstekens een naam op voor de Azure-resourcegroep en voer de opdracht uit. Een voorbeeld is
"adfrg".$resourceGroupName = "ADFTutorialResourceGroup";Als de resourcegroep al bestaat, wilt u waarschijnlijk niet dat deze wordt overschreven. Wijs een andere waarde toe aan de
$resourceGroupName-variabele en voer de opdracht opnieuw uit.Definieer een variabele voor de locatie van de data factory.
$location = "East US"Voer de volgende opdracht uit om de resourcegroep te maken:
New-AzResourceGroup $resourceGroupName $locationAls de resourcegroep al bestaat, wilt u waarschijnlijk niet dat deze wordt overschreven. Wijs een andere waarde toe aan de
$resourceGroupName-variabele en voer de opdracht opnieuw uit.Definieer een variabele voor de naam van de data factory.
Belangrijk
Werk de naam van de data factory zodanig bij dat deze uniek is. Bijvoorbeeld: ADFIncMultiCopyTutorialFactorySP1127.
$dataFactoryName = "ADFIncMultiCopyTutorialFactory";Voer de volgende cmdlet Set AzDataFactoryV2 uit om de data factory te maken:
Set-AzDataFactoryV2 -ResourceGroupName $resourceGroupName -Location $location -Name $dataFactoryName
Let op de volgende punten:
De naam van de data factory moet een Globally Unique Identifier zijn. Als de volgende fout zich voordoet, wijzigt u de naam en probeert u het opnieuw:
Set-AzDataFactoryV2 : HTTP Status Code: Conflict Error Code: DataFactoryNameInUse Error Message: The specified resource name 'ADFIncMultiCopyTutorialFactory' is already in use. Resource names must be globally unique.Als u Data Factory-exemplaren wilt maken, moet het gebruikersaccount waarmee u zich bij Azure aanmeldt, lid zijn van de rollen Inzender of Eigenaar, of moet dit een beheerder van het Azure-abonnement zijn.
Voor een lijst met Azure-regio’s waarin Data Factory momenteel beschikbaar is, selecteert u op de volgende pagina de regio’s waarin u geïnteresseerd bent, vouwt u vervolgens Analytics uit en gaat u naar Data Factory: Beschikbare producten per regio. De gegevensarchieven (Azure Storage, SQL Database, SQL Managed Instance, enzovoort) en rekenprocessen (Azure HDInsight, enzovoort) die worden gebruikt in de data factory, kunnen zich in andere regio's bevinden.
Zelf-hostende Integration Runtime maken
In deze sectie kunt u een zelf-hostende Integration Runtime maken en deze koppelen aan een on-premises computer met de SQL Server database. De zelf-hostende Integration Runtime is het onderdeel waarmee gegevens worden gekopieerd van SQL Server op uw computer naar Azure SQL Database.
Maak een variabele voor de naam van de Integration Runtime. Gebruik een unieke naam en noteer deze. U gaat deze verderop in de zelfstudie gebruiken.
$integrationRuntimeName = "ADFTutorialIR"Een zelf-hostende Integration Runtime maken.
Set-AzDataFactoryV2IntegrationRuntime -Name $integrationRuntimeName -Type SelfHosted -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupNameHier volgt een voorbeeld van uitvoer:
Name : <Integration Runtime name> Type : SelfHosted ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Description : Id : /subscriptions/<subscription ID>/resourceGroups/<ResourceGroupName>/providers/Microsoft.DataFactory/factories/<DataFactoryName>/integrationruntimes/ADFTutorialIRVoer de volgende opdracht uit om de status van de gemaakte zelf-hostende Integration Runtime op te halen. Controleer of de waarde van de status eigenschap is ingesteld op NeedRegistration.
Get-AzDataFactoryV2IntegrationRuntime -name $integrationRuntimeName -ResourceGroupName $resourceGroupName -DataFactoryName $dataFactoryName -StatusHier volgt een voorbeeld van uitvoer:
State : NeedRegistration Version : CreateTime : 9/24/2019 6:00:00 AM AutoUpdate : On ScheduledUpdateDate : UpdateDelayOffset : LocalTimeZoneOffset : InternalChannelEncryption : Capabilities : {} ServiceUrls : {eu.frontend.clouddatahub.net} Nodes : {} Links : {} Name : ADFTutorialIR Type : SelfHosted ResourceGroupName : <ResourceGroup name> DataFactoryName : <DataFactory name> Description : Id : /subscriptions/<subscription ID>/resourceGroups/<ResourceGroup name>/providers/Microsoft.DataFactory/factories/<DataFactory name>/integrationruntimes/<Integration Runtime name>Voer de volgende opdracht uit om verificatiesleutels op te halen die worden gebruikt voor de registratie van de zelf-hostende Integration Runtime met Azure Data Factory-service in de cloud:
Get-AzDataFactoryV2IntegrationRuntimeKey -Name $integrationRuntimeName -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName | ConvertTo-JsonHier volgt een voorbeeld van uitvoer:
{ "AuthKey1": "IR@0000000000-0000-0000-0000-000000000000@xy0@xy@xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx=", "AuthKey2": "IR@0000000000-0000-0000-0000-000000000000@xy0@xy@yyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyy=" }Kopieer een van de sleutels (zonder de dubbele aanhalingstekens) om de zelf-hostende Integration Runtime te registeren die u in de volgende stappen op uw computer gaat installeren.
Het hulpprogramma Integration Runtime installeren
Als u de Integration Runtime al op uw computer heeft, verwijdert u deze met behulp van Programma's toevoegen of verwijderen.
Download de zelf-hostende Integration Runtime op een lokale Windows-computer. Voer de installatie uit.
Selecteer Volgende op de pagina Welkom bij de installatie van Microsoft Integration Runtime.
Ga op de pagina Gebruiksrechtovereenkomst akkoord met de voorwaarden en de gebruiksrechtovereenkomst en selecteer Volgende.
Selecteer Volgende op de pagina Doelmap.
Selecteer Installeren op de pagina Gereed om Microsoft Integration Runtime te installeren.
Selecteer Voltooien op de pagina De installatie van Microsoft Integration Runtime is voltooid.
Plak de sleutel die u in de vorige sectie hebt opgeslagen op de pagina Integration Runtime (zelf-hostend) registreren en selecteer Registreren.
Selecteer Voltooien op de pagina Nieuw knooppunt voor Integration Runtime (zelf-hostend).
U ziet het volgende bericht wanneer de zelf-hostende Integration Runtime is geregistreerd:
Op de pagina Integration Runtime (zelf-hostend) registeren selecteert u Configuration Manager starten.
Wanneer het knooppunt is verbonden met de cloudservice, ziet u de volgende pagina:
Test nu de verbinding met uw SQL Server-database.
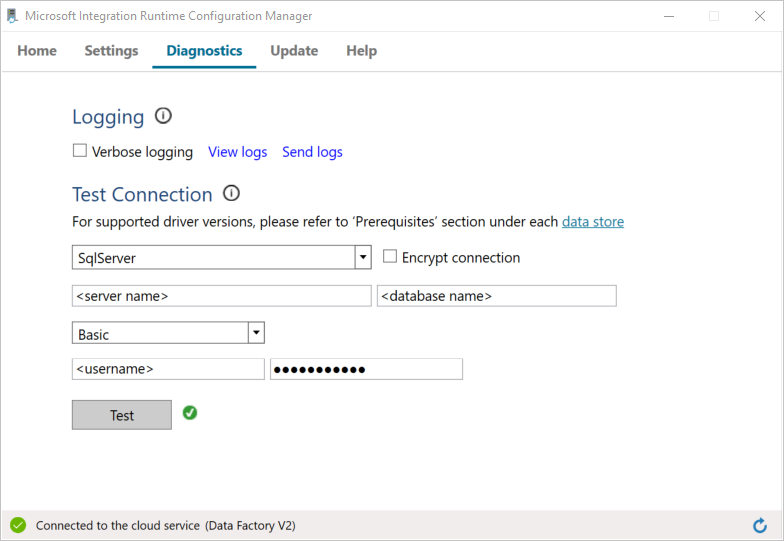
a. Ga op de pagina Configuratiebeheer naar Diagnostische gegevens.
b. Selecteer SqlServer als het type gegevensbron.
c. Voer de naam van de server in.
d. Voer de naam van de database in.
e. Selecteer de verificatiemethode.
f. Voer de gebruikersnaam in.
g. Voer het wachtwoord in dat bij de gebruikersnaam hoort.
h. Selecteer Test om te controleren of Integration Runtime verbinding kan maken met SQL Server. U ziet een groen vinkje als het gelukt is om verbinding te maken. U ziet een foutbericht als er geen verbinding kan worden gemaakt. Los eventuele problemen op en zorg ervoor dat de Integration Runtime verbinding met SQL Server kan maken.
Notitie
Noteer de waarden voor het verificatietype, de server, de database, de gebruiker en het wachtwoord. U hebt deze waarden verderop in deze zelfstudie nodig.
Gekoppelde services maken
U maakt gekoppelde services in een gegevensfactory om uw gegevensarchieven en compute-services aan de gegevensfactory te koppelen. In deze sectie maakt u gekoppelde services in uw SQL Server-database en uw database in Azure SQL Database.
De gekoppelde service voor SQL Server maken
In deze stap gaat u uw SQL Server-database aan de data factory koppelen.
Maak een JSON-bestand met de naam SqlServerLinkedService.json in de map C:\ADFTutorials\IncCopyMultiTableTutorial (maak de lokale mappen als deze nog niet bestaan) met de volgende inhoud. Selecteer de juiste sectie op basis van de verificatie die u gebruikt om verbinding te maken met SQL Server.
Belangrijk
Selecteer de juiste sectie op basis van de verificatie die u gebruikt om verbinding te maken met SQL Server.
Als u gebruikmaakt van SQL-verificatie, moet u de volgende JSON-definitie kopiëren:
{ "name":"SqlServerLinkedService", "properties":{ "annotations":[ ], "type":"SqlServer", "typeProperties":{ "connectionString":"integrated security=False;data source=<servername>;initial catalog=<database name>;user id=<username>;Password=<password>" }, "connectVia":{ "referenceName":"<integration runtime name>", "type":"IntegrationRuntimeReference" } } }Als u gebruikmaakt van Windows-verificatie, moet u de volgende JSON-definitie kopiëren:
{ "name":"SqlServerLinkedService", "properties":{ "annotations":[ ], "type":"SqlServer", "typeProperties":{ "connectionString":"integrated security=True;data source=<servername>;initial catalog=<database name>", "userName":"<username> or <domain>\\<username>", "password":{ "type":"SecureString", "value":"<password>" } }, "connectVia":{ "referenceName":"<integration runtime name>", "type":"IntegrationRuntimeReference" } } }Belangrijk
- Selecteer de juiste sectie op basis van de verificatie die u gebruikt om verbinding te maken met SQL Server.
- Vervang <de naam van de Integration Runtime door de naam> van uw Integration Runtime.
- Vervang <servernaam, <databasenaam>>, <gebruikersnaam> en <wachtwoord> door waarden van uw SQL Server-database voordat u het bestand opslaat.
- Als u een slash wilt gebruiken (
\) in de naam van uw gebruikersaccount of server, moet u het escapeteken (\) gebruiken. Een voorbeeld ismydomain\\myuser.
Voer in PowerShell de volgende cmdlet uit om over te schakelen naar de map C:\ADFTutorials\IncCopyMultiTableTutorial.
Set-Location 'C:\ADFTutorials\IncCopyMultiTableTutorial'Voer de cmdlet Set-AzDataFactoryV2LinkedService uit om de gekoppelde service AzureStorageLinkedService te maken. In het volgende voorbeeld geeft u de waarden door voor de parameters ResourceGroupName en DataFactoryName:
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SqlServerLinkedService" -File ".\SqlServerLinkedService.json"Hier volgt een voorbeeld van uitvoer:
LinkedServiceName : SqlServerLinkedService ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Properties : Microsoft.Azure.Management.DataFactory.Models.SqlServerLinkedService
De gekoppelde SQL Database-service maken
Maak een JSON-bestand met de naam AzureSQLDatabaseLinkedService.json in de map C:\ADFTutorials\IncCopyMultiTableTutorial met de volgende inhoud. (Maak de map ADF als deze nog niet bestaat.) Vervang <servernaam>, <databasenaam>, <gebruikersnaam> en <wachtwoord> door de naam van uw SQL Server-database, de naam van uw database, gebruikersnaam en wachtwoord voordat u het bestand opslaat.
{ "name":"AzureSQLDatabaseLinkedService", "properties":{ "annotations":[ ], "type":"AzureSqlDatabase", "typeProperties":{ "connectionString":"integrated security=False;encrypt=True;connection timeout=30;data source=<servername>.database.windows.net;initial catalog=<database name>;user id=<user name>;Password=<password>;" } } }Voer in PowerShell de cmdlet Set-AzDataFactoryV2LinkedService uit om de gekoppelde service AzureSQLDatabaseLinkedService te maken.
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "AzureSQLDatabaseLinkedService" -File ".\AzureSQLDatabaseLinkedService.json"Hier volgt een voorbeeld van uitvoer:
LinkedServiceName : AzureSQLDatabaseLinkedService ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Properties : Microsoft.Azure.Management.DataFactory.Models.AzureSqlDatabaseLinkedService
Gegevenssets maken
In deze stap maakt u gegevenssets die de gegevensbron, het gegevensdoel en de plaats voor het opslaan van de bovengrens aangeven.
Een brongegevensset maken
Maak een JSON-bestand met de naam SourceDataset.json in dezelfde map met de volgende inhoud:
{ "name":"SourceDataset", "properties":{ "linkedServiceName":{ "referenceName":"SqlServerLinkedService", "type":"LinkedServiceReference" }, "annotations":[ ], "type":"SqlServerTable", "schema":[ ] } }De kopieeractiviteit in de pijplijn gebruikt een SQL-query voor het laden van de gegevens in plaats van de hele tabel te laden.
Voer de cmdlet Set-AzDataFactoryV2Dataset uit om de gegevensset SourceDataset te maken.
Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SourceDataset" -File ".\SourceDataset.json"Hier volgt een uitvoervoorbeeld van de cmdlet:
DatasetName : SourceDataset ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.SqlServerTableDataset
Een sinkgegevensset maken
Maak een JSON-bestand met de naam SinkDataset.json in dezelfde map met de volgende inhoud. Het element tableName wordt in runtime dynamisch ingesteld door de pijplijn. De ForEach-activiteit in de pijplijn doorloopt een lijst met namen van tabellen en geeft de tabelnaam door aan deze gegevensset in elke iteratie.
{ "name":"SinkDataset", "properties":{ "linkedServiceName":{ "referenceName":"AzureSQLDatabaseLinkedService", "type":"LinkedServiceReference" }, "parameters":{ "SinkTableName":{ "type":"String" } }, "annotations":[ ], "type":"AzureSqlTable", "typeProperties":{ "tableName":{ "value":"@dataset().SinkTableName", "type":"Expression" } } } }Voer de cmdlet Set-AzDataFactoryV2Dataset uit om de gegevensset SinkDataset te maken.
Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SinkDataset" -File ".\SinkDataset.json"Hier volgt een uitvoervoorbeeld van de cmdlet:
DatasetName : SinkDataset ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.AzureSqlTableDataset
Een gegevensset maken voor een grenswaarde
In deze stap maakt u een gegevensset voor het opslaan van een bovengrenswaarde.
Maak een JSON-bestand met de naam WatermarkDataset.json in dezelfde map met de volgende inhoud:
{ "name": " WatermarkDataset ", "properties": { "type": "AzureSqlTable", "typeProperties": { "tableName": "watermarktable" }, "linkedServiceName": { "referenceName": "AzureSQLDatabaseLinkedService", "type": "LinkedServiceReference" } } }Voer de cmdlet Set-AzDataFactoryV2Dataset uit om de gegevensset WatermarkDataset te maken.
Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "WatermarkDataset" -File ".\WatermarkDataset.json"Hier volgt een uitvoervoorbeeld van de cmdlet:
DatasetName : WatermarkDataset ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.AzureSqlTableDataset
Een pipeline maken
In deze pijplijn wordt een lijst met tabelnamen gebruikt als parameter. De ForEach-activiteit doorloopt de lijst met namen van tabellen en voert de volgende bewerkingen uit:
Gebruik de opzoekactiviteit voor het ophalen van de oude bovengrenswaarde (de initiële waarde, of de waarde die is gebruikt in de laatste iteratie).
Gebruik de opzoekactiviteit voor het ophalen van de nieuwe bovengrenswaarde (de maximale waarde van de bovengrenskolom in de brontabel).
Gebruik de kopieeractiviteit voor het kopiëren van gegevens tussen deze twee bovengrenswaarden uit de brondatabase naar de doeldatabase.
Gebruik de opgeslagen-procedureactiviteit voor het bijwerken van de oude bovengrenswaarde die in de eerste stap van de volgende iteratie moet worden gebruikt.
Maak de pijplijn
Maak een JSON-bestand met de naam IncrementalCopyPipeline.json in dezelfde map met de volgende inhoud:
{ "name":"IncrementalCopyPipeline", "properties":{ "activities":[ { "name":"IterateSQLTables", "type":"ForEach", "dependsOn":[ ], "userProperties":[ ], "typeProperties":{ "items":{ "value":"@pipeline().parameters.tableList", "type":"Expression" }, "isSequential":false, "activities":[ { "name":"LookupOldWaterMarkActivity", "type":"Lookup", "dependsOn":[ ], "policy":{ "timeout":"7.00:00:00", "retry":0, "retryIntervalInSeconds":30, "secureOutput":false, "secureInput":false }, "userProperties":[ ], "typeProperties":{ "source":{ "type":"AzureSqlSource", "sqlReaderQuery":{ "value":"select * from watermarktable where TableName = '@{item().TABLE_NAME}'", "type":"Expression" } }, "dataset":{ "referenceName":"WatermarkDataset", "type":"DatasetReference" } } }, { "name":"LookupNewWaterMarkActivity", "type":"Lookup", "dependsOn":[ ], "policy":{ "timeout":"7.00:00:00", "retry":0, "retryIntervalInSeconds":30, "secureOutput":false, "secureInput":false }, "userProperties":[ ], "typeProperties":{ "source":{ "type":"SqlServerSource", "sqlReaderQuery":{ "value":"select MAX(@{item().WaterMark_Column}) as NewWatermarkvalue from @{item().TABLE_NAME}", "type":"Expression" } }, "dataset":{ "referenceName":"SourceDataset", "type":"DatasetReference" }, "firstRowOnly":true } }, { "name":"IncrementalCopyActivity", "type":"Copy", "dependsOn":[ { "activity":"LookupOldWaterMarkActivity", "dependencyConditions":[ "Succeeded" ] }, { "activity":"LookupNewWaterMarkActivity", "dependencyConditions":[ "Succeeded" ] } ], "policy":{ "timeout":"7.00:00:00", "retry":0, "retryIntervalInSeconds":30, "secureOutput":false, "secureInput":false }, "userProperties":[ ], "typeProperties":{ "source":{ "type":"SqlServerSource", "sqlReaderQuery":{ "value":"select * from @{item().TABLE_NAME} where @{item().WaterMark_Column} > '@{activity('LookupOldWaterMarkActivity').output.firstRow.WatermarkValue}' and @{item().WaterMark_Column} <= '@{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue}'", "type":"Expression" } }, "sink":{ "type":"AzureSqlSink", "sqlWriterStoredProcedureName":{ "value":"@{item().StoredProcedureNameForMergeOperation}", "type":"Expression" }, "sqlWriterTableType":{ "value":"@{item().TableType}", "type":"Expression" }, "storedProcedureTableTypeParameterName":{ "value":"@{item().TABLE_NAME}", "type":"Expression" }, "disableMetricsCollection":false }, "enableStaging":false }, "inputs":[ { "referenceName":"SourceDataset", "type":"DatasetReference" } ], "outputs":[ { "referenceName":"SinkDataset", "type":"DatasetReference", "parameters":{ "SinkTableName":{ "value":"@{item().TABLE_NAME}", "type":"Expression" } } } ] }, { "name":"StoredProceduretoWriteWatermarkActivity", "type":"SqlServerStoredProcedure", "dependsOn":[ { "activity":"IncrementalCopyActivity", "dependencyConditions":[ "Succeeded" ] } ], "policy":{ "timeout":"7.00:00:00", "retry":0, "retryIntervalInSeconds":30, "secureOutput":false, "secureInput":false }, "userProperties":[ ], "typeProperties":{ "storedProcedureName":"[dbo].[usp_write_watermark]", "storedProcedureParameters":{ "LastModifiedtime":{ "value":{ "value":"@{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue}", "type":"Expression" }, "type":"DateTime" }, "TableName":{ "value":{ "value":"@{activity('LookupOldWaterMarkActivity').output.firstRow.TableName}", "type":"Expression" }, "type":"String" } } }, "linkedServiceName":{ "referenceName":"AzureSQLDatabaseLinkedService", "type":"LinkedServiceReference" } } ] } } ], "parameters":{ "tableList":{ "type":"array" } }, "annotations":[ ] } }Voer de cdmlet Set-AzDataFactoryV2Pipeline uit om de pijplijn IncrementalCopyPipeline te maken.
Set-AzDataFactoryV2Pipeline -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "IncrementalCopyPipeline" -File ".\IncrementalCopyPipeline.json"Hier volgt een voorbeeld van uitvoer:
PipelineName : IncrementalCopyPipeline ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Activities : {IterateSQLTables} Parameters : {[tableList, Microsoft.Azure.Management.DataFactory.Models.ParameterSpecification]}
De pijplijn uitvoeren
Maak een parameterbestand met de naam Parameters.json in dezelfde map met de volgende inhoud:
{ "tableList": [ { "TABLE_NAME": "customer_table", "WaterMark_Column": "LastModifytime", "TableType": "DataTypeforCustomerTable", "StoredProcedureNameForMergeOperation": "usp_upsert_customer_table" }, { "TABLE_NAME": "project_table", "WaterMark_Column": "Creationtime", "TableType": "DataTypeforProjectTable", "StoredProcedureNameForMergeOperation": "usp_upsert_project_table" } ] }Voer de pijplijn IncrementalCopyPipeline uit met behulp van de cmdlet Invoke-AzDataFactoryV2Pipeline. Vervang tijdelijke aanduidingen door de namen van uw eigen resourcegroep en data factory.
$RunId = Invoke-AzDataFactoryV2Pipeline -PipelineName "IncrementalCopyPipeline" -ResourceGroup $resourceGroupName -dataFactoryName $dataFactoryName -ParameterFile ".\Parameters.json"
De pijplijn bewaken
Meld u aan bij het Azure-portaal.
Selecteer Alle services, zoek met het trefwoord gegevensfactory's en selecteer Gegevensfactory's.
Zoek naar uw data factory in de lijst met data factory’s, en selecteer deze om de pagina Data Factory te openen.
Selecteer Openen op de tegel Azure Data Factory Studio openen op de pagina Data factory openen om Azure Data Factory op een afzonderlijk tabblad te starten.
Selecteer Monitor aan de linkerkant op de startpagina van Azure Data Factory.
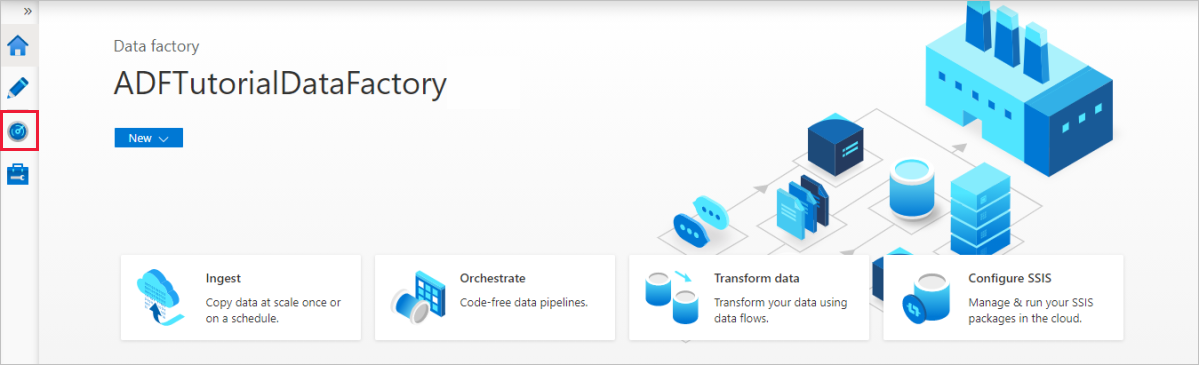
U kunt alle pijplijnactiviteiten en hun status zien. Let erop dat in het volgende voorbeeld de status van de pijplijnactiviteit Geslaagd is. U kunt parameters controleren die zijn doorgegeven aan de pijplijn door de koppeling in de kolom Parameters te selecteren. Als er een fout is opgetreden, ziet u een koppeling in de kolom Fout.

Wanneer u de koppeling in de kolom Acties selecteert, ziet u alle uitvoeringen van activiteiten voor de pijplijn.
Als u wilt terugkeren naar de weergavePijplijnuitvoeringen, selecteert u Alle pijplijnuitvoeringen bovenaan.
De resultaten bekijken
Voer in SQL Server Management Studio de volgende query's uit op de SQL-doeldatabase om te controleren of de gegevens van de brontabellen naar de doeltabellen zijn gekopieerd:
Query
select * from customer_table
Uitvoer
===========================================
PersonID Name LastModifytime
===========================================
1 John 2017-09-01 00:56:00.000
2 Mike 2017-09-02 05:23:00.000
3 Alice 2017-09-03 02:36:00.000
4 Andy 2017-09-04 03:21:00.000
5 Anny 2017-09-05 08:06:00.000
Query
select * from project_table
Uitvoer
===================================
Project Creationtime
===================================
project1 2015-01-01 00:00:00.000
project2 2016-02-02 01:23:00.000
project3 2017-03-04 05:16:00.000
Query
select * from watermarktable
Uitvoer
======================================
TableName WatermarkValue
======================================
customer_table 2017-09-05 08:06:00.000
project_table 2017-03-04 05:16:00.000
U ziet dat de bovengrenswaarden voor beide tabellen zijn bijgewerkt.
Meer gegevens toevoegen aan de brontabellen
Voer de volgende query uit op de SQL Server-brondatabase om een bestaande rij bij te werken in customer_table. Voeg een nieuwe rij in project_table in.
UPDATE customer_table
SET [LastModifytime] = '2017-09-08T00:00:00Z', [name]='NewName' where [PersonID] = 3
INSERT INTO project_table
(Project, Creationtime)
VALUES
('NewProject','10/1/2017 0:00:00 AM');
Voer de pijplijn uit
Voer nu de pijplijn opnieuw uit door de volgende PowerShell-opdracht te gebruiken:
$RunId = Invoke-AzDataFactoryV2Pipeline -PipelineName "IncrementalCopyPipeline" -ResourceGroup $resourceGroupname -dataFactoryName $dataFactoryName -ParameterFile ".\Parameters.json"Volg de pijplijnuitvoeringen met behulp van de instructies in de sectie De pijplijn bewaken. Als de pijplijnstatus In uitvoering is, ziet u een andere actiekoppeling onder Acties om de pijplijn te annuleren.
Klik op Vernieuwen om de lijst te vernieuwen totdat de uitvoering van de pijplijn is voltooid.
Selecteer desgewenst de koppeling Uitvoeringen van activiteit weergeven onder Acties om alle activiteitsuitvoeringen te bekijken die gekoppeld zijn aan deze pijplijnuitvoering.
De eindresultaten bekijken
Voer in SQL Server Management Studio de volgende query's uit op de doeldatabase om te controleren dat de bijgewerkte/nieuwe gegevens van de brontabellen naar de doeltabellen zijn gekopieerd.
Query
select * from customer_table
Uitvoer
===========================================
PersonID Name LastModifytime
===========================================
1 John 2017-09-01 00:56:00.000
2 Mike 2017-09-02 05:23:00.000
3 NewName 2017-09-08 00:00:00.000
4 Andy 2017-09-04 03:21:00.000
5 Anny 2017-09-05 08:06:00.000
Let op de nieuwe waarden van Name en LastModifytime voor de PersonID voor nummer 3.
Query
select * from project_table
Uitvoer
===================================
Project Creationtime
===================================
project1 2015-01-01 00:00:00.000
project2 2016-02-02 01:23:00.000
project3 2017-03-04 05:16:00.000
NewProject 2017-10-01 00:00:00.000
Let erop dat de invoer van NewProject toegevoegd is aan project_table.
Query
select * from watermarktable
Uitvoer
======================================
TableName WatermarkValue
======================================
customer_table 2017-09-08 00:00:00.000
project_table 2017-10-01 00:00:00.000
U ziet dat de bovengrenswaarden voor beide tabellen zijn bijgewerkt.
Gerelateerde inhoud
In deze zelfstudie hebt u de volgende stappen uitgevoerd:
- Bereid de bron- en doelserver gegevensopslag voor.
- Een data factory maken.
- Een zelf-hostende integration runtime (IR) maken.
- De Integration Runtime installeren.
- Maak gekoppelde services.
- Maak bron-, sink- en grenswaardegegevenssets.
- Maken, starten en controleren van een pijplijn.
- Controleer de resultaten.
- Gegevens in brontabellen toevoegen of bijwerken.
- De pijplijn opnieuw uitvoeren en controleren.
- De eindresultaten bekijken.
Ga naar de volgende zelfstudie voor meer informatie over het transformeren van gegevens met behulp van een Spark-cluster in Azure: