Incrementeel gegevens kopiëren van Azure SQL Database naar Azure Blob Storage met behulp van technologie voor bijhouden van wijzigingen met behulp van PowerShell
VAN TOEPASSING OP:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Probeer Data Factory uit in Microsoft Fabric, een alles-in-één analyseoplossing voor ondernemingen. Microsoft Fabric omvat alles, van gegevensverplaatsing tot gegevenswetenschap, realtime analyses, business intelligence en rapportage. Meer informatie over het gratis starten van een nieuwe proefversie .
In deze zelfstudie maakt u een Azure data factory met een pijplijn die gewijzigde gegevens laadt op basis van informatie over wijzigingen in de brondatabase in Azure SQL Database naar een Azure blob storage.
In deze zelfstudie voert u de volgende stappen uit:
- Voorbereiden van de bron-gegevensopslag
- Een data factory maken.
- Maak gekoppelde services.
- Maken van bron-, sink- en wijzigingsgegevenssets.
- Maken, uitvoeren en bewaken van de pijplijn met de volledige kopie
- Gegevens in de tabellen in gegevensbronnen toevoegen of bijwerken
- Maken, uitvoeren en bewaken van de pijplijn met de incrementele kopie
Notitie
Het wordt aanbevolen de Azure Az PowerShell-module te gebruiken om te communiceren met Azure. Zie Azure PowerShell installeren om aan de slag te gaan. Raadpleeg Azure PowerShell migreren van AzureRM naar Az om te leren hoe u naar de Azure PowerShell-module migreert.
Overzicht
In een oplossing voor gegevensintegratie is incrementeel (of delta) laden van gegevens na een eerste volledige laadhandeling een veelgebruikt scenario. De gewijzigde gegevens binnen een periode in de gegevensopslag van uw bron kan in sommige gevallen gemakkelijk opgedeeld (bijvoorbeeld LastModifyTime, CreationTime). In sommige gevallen is er geen expliciete manier voor het identificeren van de deltagegevens van de laatste keer dat u de gegevens verwerkt. De technologie voor wijzigingen bijhouden die wordt ondersteund door de gegevensopslag zoals Azure SQL Database en SQL Server kan worden gebruikt voor het identificeren van de deltagegevens. In deze zelfstudie wordt beschreven hoe u met Azure Data Factory kunt gebruikmaken van SQL-technologie voor wijzigingen bijhouden voor het incrementeel laden van wijzigingsgegevens uit Azure SQL Database in Azure Blob Storage. Zie voor meer concrete informatie over SQL-technologie voor wijzigingen bijhouden Bijhouden van wijzigingen in SQL Server.
End-to-end werkstroom
Hier zijn de gangbare end-to-end werkstroomstappen voor het incrementeel laden van gegevens met behulp van technologie voor wijzigingen bijhouden.
Notitie
Zowel de Azure SQL Database als SQL Server ondersteunen de technologie voor wijzigingen bijhouden. In deze zelfstudie wordt Azure SQL Database gebruikt als de bron-gegevensopslag. U kunt ook een SQL Server-exemplaar gebruiken.
- Eerste laad van historische gegevens (eenmaal uitvoeren):
- Technologie voor wijzigingen bijhouden inschakelen in de brondatabase in Azure SQL Database.
- Haal de eerste waarde van SYS_CHANGE_VERSION op uit de database als de basislijn voor het vastleggen van gewijzigde gegevens.
- Volledige gegevens laden van een brondatabase naar een Azure-blobopslag.
- Incrementeel laden van deltagegevens volgens een schema (periodiek uitvoeren na het initiële laden van gegevens):
- Haal de oude en nieuwe SYS_CHANGE_VERSION waarden op.
- Laden van de deltagegevens door de primaire sleutels van gewijzigde rijen (tussen twee SYS_CHANGE_VERSION waarden) uit sys.change_tracking_tables met gegevens in de brontabel, en vervolgens de deltagegevens naar de bestemming te verplaatsen.
- De SYS_CHANGE_VERSION voor de volgende keer van deltaladen bijwerken.
Oplossingen op hoog niveau
In deze zelfstudie maakt u twee pijplijnen die de volgende twee bewerkingen uitvoeren:
Initieel laden: u maakt een pijplijn met een kopieeractiviteit waarmee de volledige gegevens gekopieerd worden van het brongegevensarchief (Azure SQL Database) naar de doelgegevensopslagplaats (Azure Blob Storage).

Incrementeel laden: u maakt een pijplijn met de volgende activiteiten en laat deze periodiek uitvoeren.
- Maak twee lookup-activiteiten om de oude en nieuwe SYS_CHANGE_VERSION op te halen uit Azure SQL Database en door te geven aan de kopieeractiviteit.
- Maak een kopieeractiviteit om de gegevens ingevoegd/bijgewerkt/verwijderd tussen de twee waarden van SYS_CHANGE_VERSION van Azure SQL Database in Azure Blob-opslag te kopiëren.
- Maak een opgeslagen procedure activiteit voor het bijwerken van de waarde van SYS_CHANGE_VERSION voor de volgende pijplijn-run.

Als u geen Azure-abonnement hebt, maakt u een gratis account voordat u begint.
Vereisten
- Azure PowerShell. Installeer de nieuwste Azure PowerShell-modules met de instructies in Azure PowerShell installeren en configureren.
- Azure SQL-database. U gebruikt de database als de brongegevensopslag. Als u geen database in Azure SQL Database hebt, raadpleegt u het artikel Een database in Azure SQL Database maken om te stappen te zien om er een te maken.
- Azure Storage-account. U gebruikt de Blob-opslag als de sinkgegevensopslag. Als u geen Azure-opslagaccount hebt, raadpleegt u het artikel Een opslagaccount maken om een account te maken. Maak een container met de naam adftutorial.
Een gegevensbrontabel in uw database maken
Start SQL Server Management Studio en maak verbinding met SQL Database.
Klik in Server Explorer met de rechtermuisknop op de database en kies de Nieuwe query.
Voer de volgende SQL-opdracht uit voor uw database om een tabel met de naam
data_source_tablete maken als gegevensbronopslag.create table data_source_table ( PersonID int NOT NULL, Name varchar(255), Age int PRIMARY KEY (PersonID) ); INSERT INTO data_source_table (PersonID, Name, Age) VALUES (1, 'aaaa', 21), (2, 'bbbb', 24), (3, 'cccc', 20), (4, 'dddd', 26), (5, 'eeee', 22);Schakel wijzigingen bijhouden op uw database en de brontabel (data_source_table) in door het uitvoeren van de volgende SQL-query:
Notitie
- Vervang <uw databasenaam> met de naam van uw database waarin de data_source_table staat.
- De gewijzigde gegevens worden in het huidige voorbeeld twee dagen bewaard. Als u de gewijzigde gegevens elke drie dagen of meer laadt, zal sommige informatie niet worden meegenomen. U moet dan eventueel de waarde van CHANGE_RETENTION naar een hoger getal wijzigen. U kunt er ook voor zorgen dat de periode voor laden van de gewijzigde gegevens binnen twee dagen ligt. Zie voor meer informatie Inschakelen bijhouden van wijzigingen voor een database
ALTER DATABASE <your database name> SET CHANGE_TRACKING = ON (CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON) ALTER TABLE data_source_table ENABLE CHANGE_TRACKING WITH (TRACK_COLUMNS_UPDATED = ON)Een nieuwe tabel maken en opslaan van de ChangeTracking_version met een standaardwaarde door de volgende query uit te voeren:
create table table_store_ChangeTracking_version ( TableName varchar(255), SYS_CHANGE_VERSION BIGINT, ); DECLARE @ChangeTracking_version BIGINT SET @ChangeTracking_version = CHANGE_TRACKING_CURRENT_VERSION(); INSERT INTO table_store_ChangeTracking_version VALUES ('data_source_table', @ChangeTracking_version)Notitie
Als de gegevens niet zijn gewijzigd nadat u het bijhouden van wijzigingen voor Misciroft Azure SQL Database hebt ingeschakeld, is de waarde van de versie van wijzigingen 0.
Voer de volgende query uit om een opgeslagen procedure in uw database te maken. De pijplijn roept deze opgeslagen procedure aan voor het bijwerken van de wijzigingsversie in de tabel die u in de vorige stap hebt gemaakt.
CREATE PROCEDURE Update_ChangeTracking_Version @CurrentTrackingVersion BIGINT, @TableName varchar(50) AS BEGIN UPDATE table_store_ChangeTracking_version SET [SYS_CHANGE_VERSION] = @CurrentTrackingVersion WHERE [TableName] = @TableName END
Azure PowerShell
Installeer de nieuwste Azure PowerShell-modules met de instructies in Azure PowerShell installeren en configureren.
Een data factory maken
Definieer een variabele voor de naam van de resourcegroep die u later gaat gebruiken in PowerShell-opdrachten. Kopieer de tekst van de volgende opdracht naar PowerShell, geef tussen dubbele aanhalingstekens een naam op voor de Azure-resourcegroep en voer de opdracht uit. Voorbeeld:
"adfrg".$resourceGroupName = "ADFTutorialResourceGroup";Als de resourcegroep al bestaat, wilt u waarschijnlijk niet dat deze wordt overschreven. Wijs een andere waarde toe aan de
$resourceGroupName-variabele en voer de opdracht opnieuw uit.Definieer een variabele voor de locatie van de data factory:
$location = "East US"Voer de volgende opdracht uit om de resourcegroep te maken:
New-AzResourceGroup $resourceGroupName $locationAls de resourcegroep al bestaat, wilt u waarschijnlijk niet dat deze wordt overschreven. Wijs een andere waarde toe aan de
$resourceGroupName-variabele en voer de opdracht opnieuw uit.Definieer een variabele voor de naam van de data factory.
Belangrijk
Werk de naam van de data factory zodanig bij dat deze uniek is.
$dataFactoryName = "IncCopyChgTrackingDF";Voer de volgende cmdlet Set AzDataFactoryV2 uit om de data factory te maken:
Set-AzDataFactoryV2 -ResourceGroupName $resourceGroupName -Location $location -Name $dataFactoryName
Let op de volgende punten:
De naam van de Azure-gegevensfactory moet wereldwijd uniek zijn. Als de volgende fout zich voordoet, wijzigt u de naam en probeert u het opnieuw.
The specified Data Factory name 'ADFIncCopyChangeTrackingTestFactory' is already in use. Data Factory names must be globally unique.Als u Data Factory-exemplaren wilt maken, moet het gebruikersaccount waarmee u zich bij Azure aanmeldt, lid zijn van de rollen Inzender of Eigenaar, of moet dit een beheerder van het Azure-abonnement zijn.
Voor een lijst met Azure-regio’s waarin Data Factory momenteel beschikbaar is, selecteert u op de volgende pagina de regio’s waarin u geïnteresseerd bent, vouwt u vervolgens Analytics uit en gaat u naar Data Factory: Beschikbare producten per regio. De gegevensopslagexemplaren (Azure Storage, Azure SQL Database, enzovoort) en berekeningen (HDInsight, enzovoort) die worden gebruikt in Data Factory, kunnen zich in andere regio's bevinden.
Gekoppelde services maken
U maakt gekoppelde services in een gegevensfactory om uw gegevensarchieven en compute-services aan de gegevensfactory te koppelen. In deze sectie maakt u gekoppelde services in uw Azure Storage-account en uw database in Azure SQL Database.
Maak een gekoppelde Azure Storage-service.
Tijdens deze stap koppelt u uw Azure Storage-account aan de data factory.
Maak een JSON-bestand met de naam AzureStorageLinkedService.json in de map C:\ADFTutorials\IncCopyChangeTrackingTutorial met de volgende inhoud: Maak de map als deze nog niet bestaat. Vervang
<accountName>,<accountKey>door de naam en sleutel van uw Azure-opslagaccount voordat u het bestand opslaat.{ "name": "AzureStorageLinkedService", "properties": { "type": "AzureStorage", "typeProperties": { "connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountName>;AccountKey=<accountKey>" } } }Schakel in Azure PowerShell over naar de map C:\ADFTutorials\IncCopyChangeTrackingTutorial.
Voer de cmdlet Set-AzDataFactoryV2LinkedService uit om de gekoppelde service te maken: AzureStorageLinkedService. In het volgende voorbeeld geeft u de waarden door voor de parameters ResourceGroupName en DataFactoryName.
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "AzureStorageLinkedService" -File ".\AzureStorageLinkedService.json"Hier volgt een voorbeeld van uitvoer:
LinkedServiceName : AzureStorageLinkedService ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Properties : Microsoft.Azure.Management.DataFactory.Models.AzureStorageLinkedService
Maak een gekoppelde Azure SQL Database-service.
In deze stap koppelt u uw database aan de data factory.
Maak een JSON-bestand met de naam AzureSQLDatabaseLinkedService.json in de map C:\ADFTutorials\IncCopyChangeTrackingTutorial door de volgende inhoud: Vervang <uw-servernaam> en <uw-databasenaam> door de naam van uw server en database voordat u het bestand opslaat. U moet ook uw Azure SQL Server configureren om toegang te verlenen tot de beheerde identiteit van uw data factory.
{ "name": "AzureSqlDatabaseLinkedService", "properties": { "type": "AzureSqlDatabase", "typeProperties": { "connectionString": "Server=tcp:<your-server-name>.database.windows.net,1433;Database=<your-database-name>;" }, "authenticationType": "ManagedIdentity", "annotations": [] } }Voer in Azure PowerShell de cmdlet Set-AzDataFactoryV2LinkedService uit om de gekoppelde service te maken: AzureSQLDatabaseLinkedService.
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "AzureSQLDatabaseLinkedService" -File ".\AzureSQLDatabaseLinkedService.json"Hier volgt een voorbeeld van uitvoer:
LinkedServiceName : AzureSQLDatabaseLinkedService ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Properties : Microsoft.Azure.Management.DataFactory.Models.AzureSqlDatabaseLinkedService
Gegevenssets maken
In deze stap maakt u gegevenssets om de gegevensbron en -bestemming te vertegenwoordigen. en de plaats voor het opslaan van de SYS_CHANGE_VERSION.
Een brongegevensset maken
In deze stap maakt u een gegevensset die de brongegevens vertegenwoordigt.
Maak een JSON-bestand met de naam SourceDataset.json in dezelfde map met de volgende inhoud:
{ "name": "SourceDataset", "properties": { "type": "AzureSqlTable", "typeProperties": { "tableName": "data_source_table" }, "linkedServiceName": { "referenceName": "AzureSQLDatabaseLinkedService", "type": "LinkedServiceReference" } } }Voer de cmdlet Set-AzDataFactoryV2Dataset uit om de gegevensset te maken: SourceDataset
Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SourceDataset" -File ".\SourceDataset.json"Hier volgt een uitvoervoorbeeld van de cmdlet:
DatasetName : SourceDataset ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.AzureSqlTableDataset
Een sinkgegevensset maken
In deze stap maakt u een gegevensset die de gegevens voorstelt die worden gekopieerd uit de gegevensopslag van de bron.
Maak een JSON-bestand met de naam SinkDataset.json in dezelfde map met de volgende inhoud:
{ "name": "SinkDataset", "properties": { "type": "AzureBlob", "typeProperties": { "folderPath": "adftutorial/incchgtracking", "fileName": "@CONCAT('Incremental-', pipeline().RunId, '.txt')", "format": { "type": "TextFormat" } }, "linkedServiceName": { "referenceName": "AzureStorageLinkedService", "type": "LinkedServiceReference" } } }U kunt de adftutorial-container maken in uw Azure-blobopslag als onderdeel van de vereisten. Maak de container als deze bestaat niet (of) stel deze in op de naam van een bestaande container. In deze zelfstudie wordt de naam van het uitvoerbestand dynamisch gegenereerd met behulp van de expressie: @CONCAT('Incremental-', pipeline(). RunId, '.txt').
Voer de cmdlet Set-AzDataFactoryV2Dataset uit om de gegevensset te maken: SinkDataset
Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SinkDataset" -File ".\SinkDataset.json"Hier volgt een uitvoervoorbeeld van de cmdlet:
DatasetName : SinkDataset ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.AzureBlobDataset
Maken van een gegevensset voor bijhouden van wijzigingen
In deze stap maakt u een gegevensset voor het opslaan van een bovengrenswaarde.
Maak een JSON-bestand met de naam ChangeTrackingDataset.json in dezelfde map met de volgende inhoud:
{ "name": " ChangeTrackingDataset", "properties": { "type": "AzureSqlTable", "typeProperties": { "tableName": "table_store_ChangeTracking_version" }, "linkedServiceName": { "referenceName": "AzureSQLDatabaseLinkedService", "type": "LinkedServiceReference" } } }U maken de tabel table_store_ChangeTracking_version als onderdeel van de vereisten.
Voer de cmdlet Set-AzDataFactoryV2Dataset uit om de gegevensset te maken: ChangeTrackingDataset
Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "ChangeTrackingDataset" -File ".\ChangeTrackingDataset.json"Hier volgt een uitvoervoorbeeld van de cmdlet:
DatasetName : ChangeTrackingDataset ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.AzureSqlTableDataset
Een pijplijn maken voor de volledige kopie
In deze stap maakt u een pijplijn met een kopieeractiviteit waarmee de volledige gegevens gekopieerd worden van het brongegevensarchief (Azure SQL Database) naar de doelgegevensopslagplaats (Azure Blob Storage).
Maak een JSON-bestand: FullCopyPipeline.json in dezelfde map met de volgende inhoud:
{ "name": "FullCopyPipeline", "properties": { "activities": [{ "name": "FullCopyActivity", "type": "Copy", "typeProperties": { "source": { "type": "SqlSource" }, "sink": { "type": "BlobSink" } }, "inputs": [{ "referenceName": "SourceDataset", "type": "DatasetReference" }], "outputs": [{ "referenceName": "SinkDataset", "type": "DatasetReference" }] }] } }Voer de cmdlet Set-AzDataFactoryV2Pipeline uit om de pijplijn te maken: FullCopyPipeline.
Set-AzDataFactoryV2Pipeline -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "FullCopyPipeline" -File ".\FullCopyPipeline.json"Hier volgt een voorbeeld van uitvoer:
PipelineName : FullCopyPipeline ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Activities : {FullCopyActivity} Parameters :
Voer de volledige kopie-pijplijn uit
Voer de pijplijn uit: FullCopyPipeline met behulp van de cmdlet Invoke-AzDataFactoryV2Pipeline .
Invoke-AzDataFactoryV2Pipeline -PipelineName "FullCopyPipeline" -ResourceGroup $resourceGroupName -dataFactoryName $dataFactoryName
De volledige kopieerpijplijn bewaken
Meld u aan bij Azure Portal.
Klik op Alle services, zoek met het trefwoord
data factoriesen selecteer Gegevensfabrieken.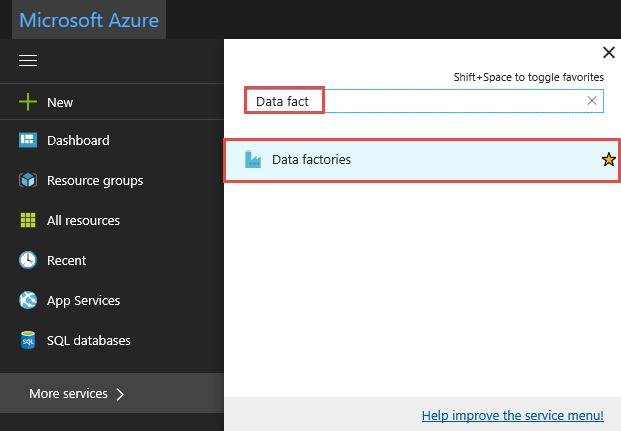
Zoek naar uw data factory in de lijst met data factorys, en selecteer deze om de Data Factory-pagina te openen.
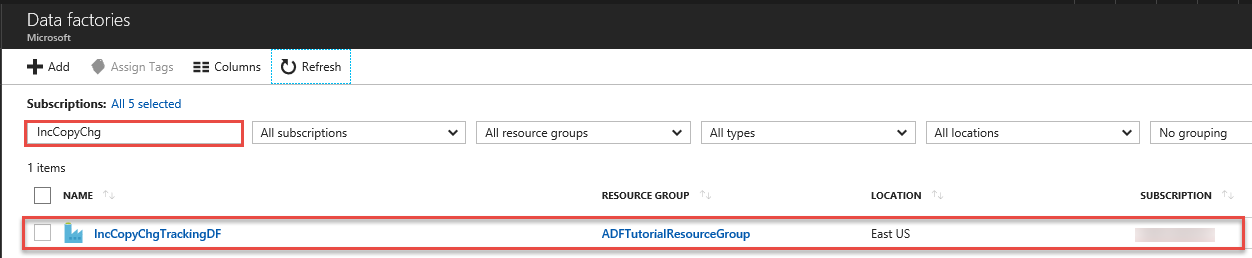
Klik op de pagina Data factory op de tegel Controleren en beheren.
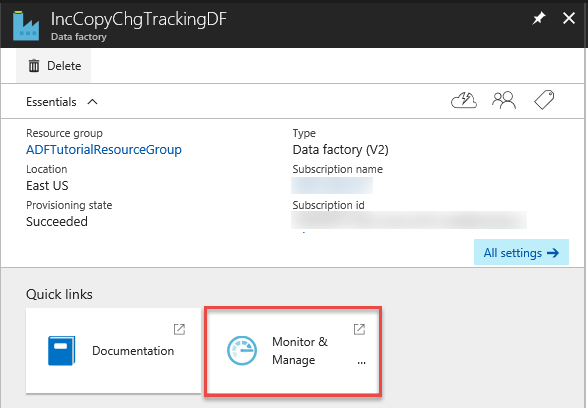
De Data-Integratie-toepassing wordt gestart op een afzonderlijk tabblad. U kunt alle pijplijnuitvoeringen en hun statussen zien. Let erop dat in het volgende voorbeeld de status van de pijplijnactiviteit Geslaagd is. U kunt parameters controleren die zijn doorgegeven aan de pijplijn door te klikken op de kolom Parameters. Als er een fout is, ziet u een koppeling in de fout-kolom. Klik op de koppeling in de kolom Acties.
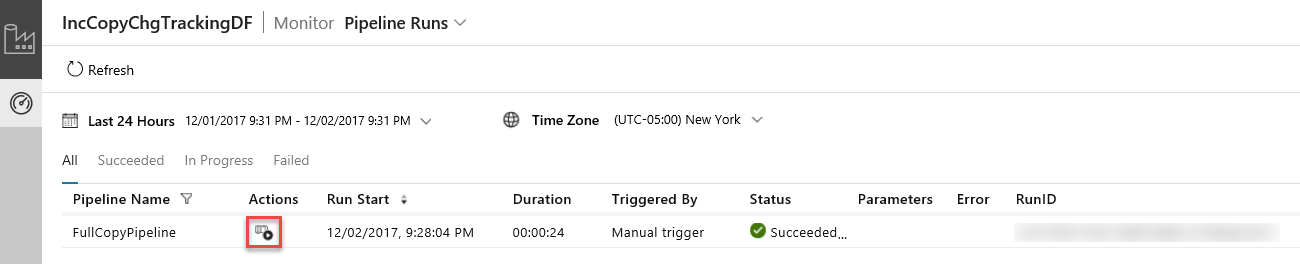
Wanneer u klikt op de koppeling in de kolom acties ziet u de volgende pagina met alle activiteiten bij uitvoering voor de pijplijn.
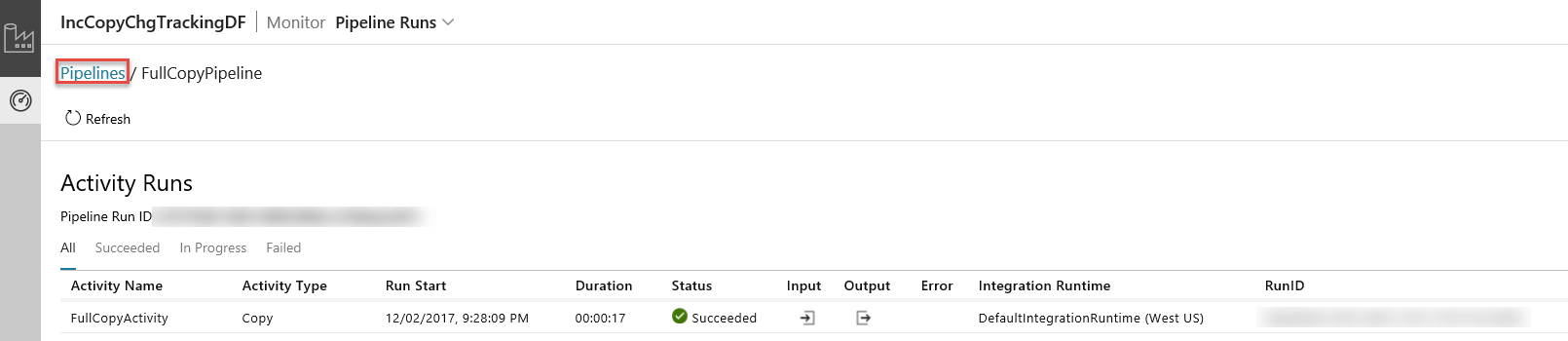
Overschakelen naar de weergave Pipeline-activiteiten kan door te klikken op Pijplijnen zoals weergegeven in de afbeelding.
De resultaten bekijken
U ziet u een bestand met de naam incremental-<GUID>.txt in de incchgtracking map van de adftutorial container.
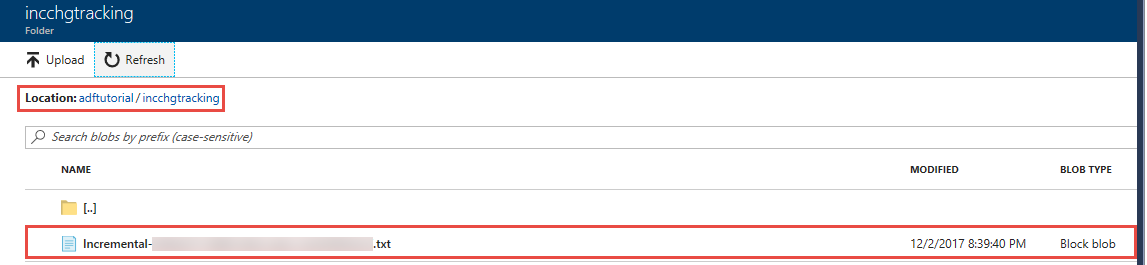
Het bestand moet de gegevens van uw database bevatten:
1,aaaa,21
2,bbbb,24
3,cccc,20
4,dddd,26
5,eeee,22
Meer gegevens toevoegen aan de brontabellen
Voer de volgende query uit op uw database om een rij toe te voegen en een rij bij te werken.
INSERT INTO data_source_table
(PersonID, Name, Age)
VALUES
(6, 'new','50');
UPDATE data_source_table
SET [Age] = '10', [name]='update' where [PersonID] = 1
Een pijplijn voor de delta-kopie maken
In deze stap maakt u een pijplijn met de volgende activiteiten en laat deze periodiek uitvoeren. De lookup-activiteiten om de oude en nieuwe SYS_CHANGE_VERSION op te halen uit Azure SQL Database en door te geven aan de kopieeractiviteit. De kopieeractiviteit om de gegevens ingevoegd/bijgewerkt/verwijderd tussen de twee waarden van SYS_CHANGE_VERSION van Azure SQL Database in Azure Blob-opslag te kopiëren. De opgeslagen procedure activiteit voor het bijwerken van de waarde van SYS_CHANGE_VERSION voor de volgende pijplijn-run.
Maak een JSON-bestand: IncrementalCopyPipeline.json in dezelfde map met de volgende inhoud:
{ "name": "IncrementalCopyPipeline", "properties": { "activities": [ { "name": "LookupLastChangeTrackingVersionActivity", "type": "Lookup", "typeProperties": { "source": { "type": "SqlSource", "sqlReaderQuery": "select * from table_store_ChangeTracking_version" }, "dataset": { "referenceName": "ChangeTrackingDataset", "type": "DatasetReference" } } }, { "name": "LookupCurrentChangeTrackingVersionActivity", "type": "Lookup", "typeProperties": { "source": { "type": "SqlSource", "sqlReaderQuery": "SELECT CHANGE_TRACKING_CURRENT_VERSION() as CurrentChangeTrackingVersion" }, "dataset": { "referenceName": "SourceDataset", "type": "DatasetReference" } } }, { "name": "IncrementalCopyActivity", "type": "Copy", "typeProperties": { "source": { "type": "SqlSource", "sqlReaderQuery": "select data_source_table.PersonID,data_source_table.Name,data_source_table.Age, CT.SYS_CHANGE_VERSION, SYS_CHANGE_OPERATION from data_source_table RIGHT OUTER JOIN CHANGETABLE(CHANGES data_source_table, @{activity('LookupLastChangeTrackingVersionActivity').output.firstRow.SYS_CHANGE_VERSION}) as CT on data_source_table.PersonID = CT.PersonID where CT.SYS_CHANGE_VERSION <= @{activity('LookupCurrentChangeTrackingVersionActivity').output.firstRow.CurrentChangeTrackingVersion}" }, "sink": { "type": "BlobSink" } }, "dependsOn": [ { "activity": "LookupLastChangeTrackingVersionActivity", "dependencyConditions": [ "Succeeded" ] }, { "activity": "LookupCurrentChangeTrackingVersionActivity", "dependencyConditions": [ "Succeeded" ] } ], "inputs": [ { "referenceName": "SourceDataset", "type": "DatasetReference" } ], "outputs": [ { "referenceName": "SinkDataset", "type": "DatasetReference" } ] }, { "name": "StoredProceduretoUpdateChangeTrackingActivity", "type": "SqlServerStoredProcedure", "typeProperties": { "storedProcedureName": "Update_ChangeTracking_Version", "storedProcedureParameters": { "CurrentTrackingVersion": { "value": "@{activity('LookupCurrentChangeTrackingVersionActivity').output.firstRow.CurrentChangeTrackingVersion}", "type": "INT64" }, "TableName": { "value": "@{activity('LookupLastChangeTrackingVersionActivity').output.firstRow.TableName}", "type": "String" } } }, "linkedServiceName": { "referenceName": "AzureSQLDatabaseLinkedService", "type": "LinkedServiceReference" }, "dependsOn": [ { "activity": "IncrementalCopyActivity", "dependencyConditions": [ "Succeeded" ] } ] } ] } }Voer de cmdlet Set-AzDataFactoryV2Pipeline uit om de pijplijn te maken: FullCopyPipeline.
Set-AzDataFactoryV2Pipeline -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "IncrementalCopyPipeline" -File ".\IncrementalCopyPipeline.json"Hier volgt een voorbeeld van uitvoer:
PipelineName : IncrementalCopyPipeline ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Activities : {LookupLastChangeTrackingVersionActivity, LookupCurrentChangeTrackingVersionActivity, IncrementalCopyActivity, StoredProceduretoUpdateChangeTrackingActivity} Parameters :
De pijplijn incrementele kopie uitvoeren
Voer de pijplijn uit: IncrementalCopyPipeline met behulp van de cmdlet Invoke-AzDataFactoryV2Pipeline .
Invoke-AzDataFactoryV2Pipeline -PipelineName "IncrementalCopyPipeline" -ResourceGroup $resourceGroupName -dataFactoryName $dataFactoryName
De pijplijn incrementele kopie bewaken
Ververs in de Data Integration Application de weergave pijplijn-runs. Controleer of u de IncrementalCopyPipeline in de lijst ziet. Klik op de koppeling in de kolom Acties.
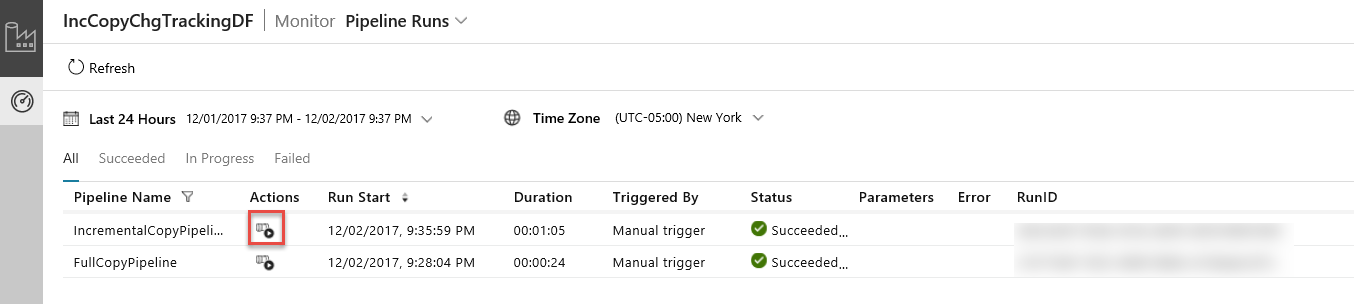
Wanneer u klikt op de koppeling in de kolom acties ziet u de volgende pagina met alle activiteiten bij uitvoering voor de pijplijn.
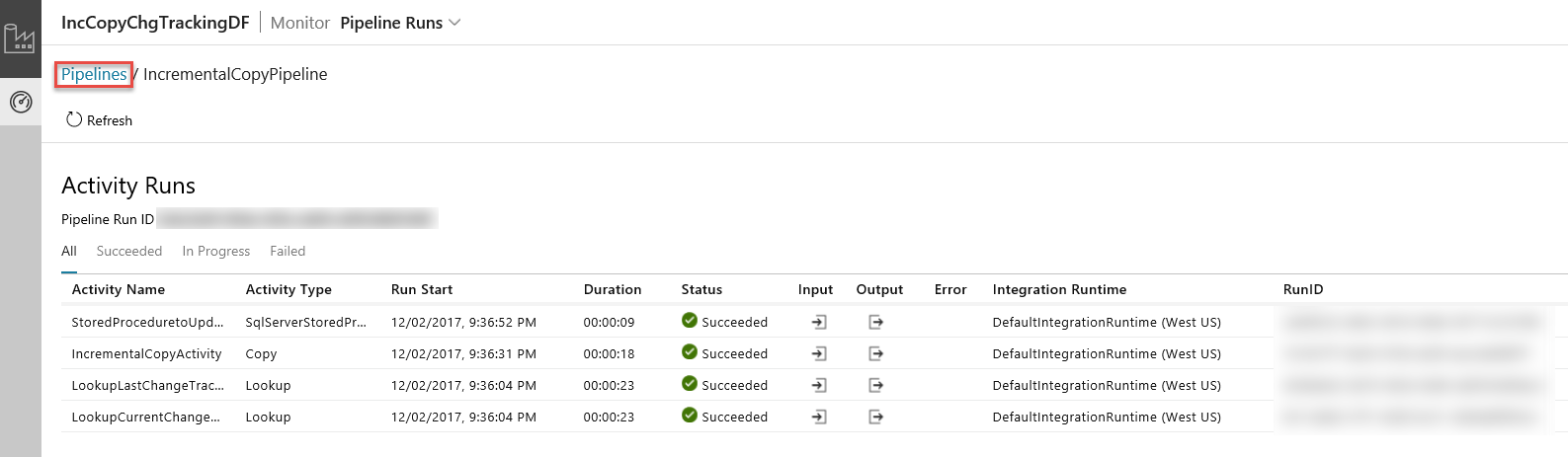
Overschakelen naar de weergave Pipeline-activiteiten kan door te klikken op Pijplijnen zoals weergegeven in de afbeelding.
De resultaten bekijken
U ziet u het tweede bestand in de incchgtracking map van de adftutorial container.
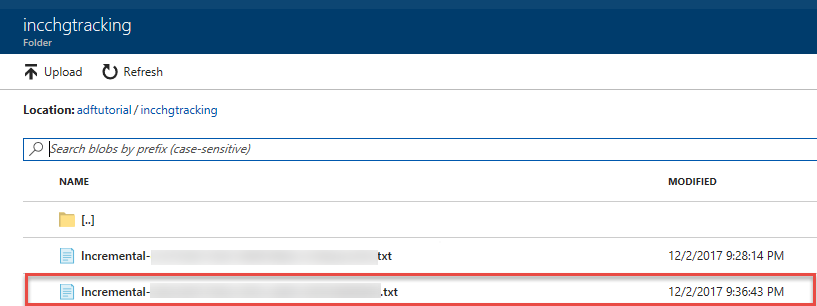
Het bestand mag alleen de deltagegevens van uw database bevatten. De record met U de bijgewerkte rij in de database en I is het een rij toegevoegd.
1,update,10,2,U
6,new,50,1,I
De eerste drie kolommen zijn gewijzigde gegevens van data_source_table. De laatste twee kolommen zijn de metagegevens van de systeemtabel bijhouden. De vierde kolom is de SYS_CHANGE_VERSION voor elke gewijzigde rij. De vijfde kolom is de bewerking: U = update, I = invoegen. Zie voor meer informatie over de traceringsgegevens CHANGETABLE.
==================================================================
PersonID Name Age SYS_CHANGE_VERSION SYS_CHANGE_OPERATION
==================================================================
1 update 10 2 U
6 new 50 1 I
Gerelateerde inhoud
Ga naar de volgende zelfstudie voor meer informatie over het kopiëren van nieuwe en gewijzigde bestanden alleen op basis van hun LastModifiedDate: