Gegevens transformeren met behulp van Hadoop Streaming-activiteit in Azure Data Factory of Synapse Analytics
VAN TOEPASSING OP:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Probeer Data Factory uit in Microsoft Fabric, een alles-in-één analyseoplossing voor ondernemingen. Microsoft Fabric omvat alles, van gegevensverplaatsing tot gegevenswetenschap, realtime analyses, business intelligence en rapportage. Meer informatie over het gratis starten van een nieuwe proefversie .
De HDInsight-streamingactiviteit in een Azure Data Factory- of Synapse Analytics-pijplijn voert Hadoop Streaming-programma's uit op uw eigen of on-demand HDInsight-cluster. Dit artikel is gebaseerd op het artikel over activiteiten voor gegevenstransformatie , waarin een algemeen overzicht wordt weergegeven van de gegevenstransformatie en de ondersteunde transformatieactiviteiten.
Lees voor meer informatie de inleidende artikelen over Azure Data Factory en Synapse Analytics en voer de zelfstudie uit: gegevens transformeren voordat u dit artikel leest.
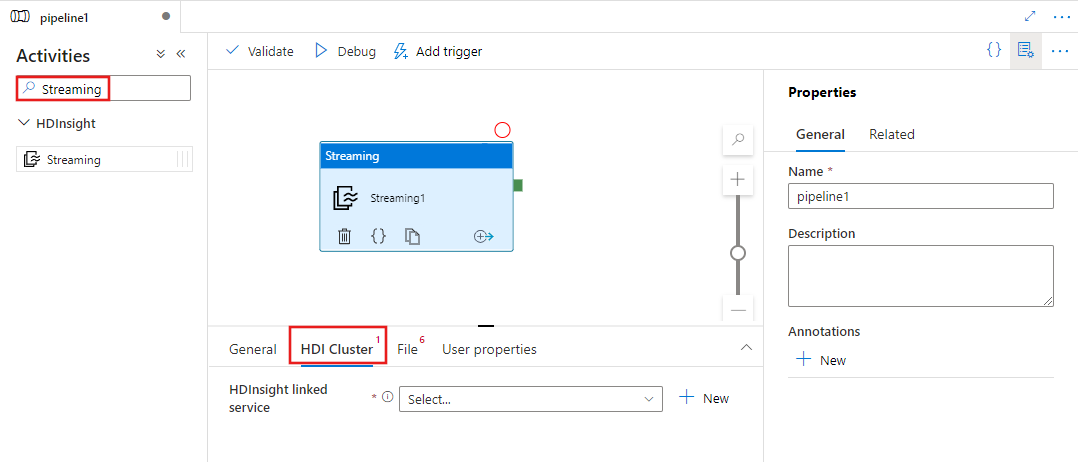
Een HDInsight-streamingactiviteit toevoegen aan een pijplijn met ui
Voer de volgende stappen uit om een HDInsight-streamingactiviteit te gebruiken voor een pijplijn:
Zoek naar Streaming in het deelvenster Pijplijnactiviteiten en sleep een streamingactiviteit naar het pijplijncanvas.
Selecteer de nieuwe streamingactiviteit op het canvas als deze nog niet is geselecteerd.
Selecteer het tabblad HDI-cluster om een nieuwe gekoppelde service te selecteren of te maken voor een HDInsight-cluster dat wordt gebruikt om de streamingactiviteit uit te voeren.
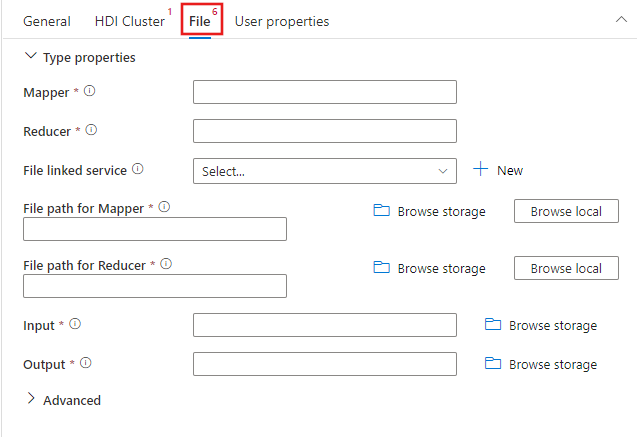
Selecteer het tabblad Bestand om de mapper- en reducernamen voor uw streamingtaak op te geven en selecteer of maak een nieuwe gekoppelde service aan een Azure Storage-account waarmee de mapper-, reducer-, invoer- en uitvoerbestanden voor de taak worden gebruikt. U kunt ook geavanceerde details configureren, waaronder foutopsporingsconfiguratie, argumenten en parameters die aan de taak moeten worden doorgegeven.
JSON-voorbeeld
{
"name": "Streaming Activity",
"description": "Description",
"type": "HDInsightStreaming",
"linkedServiceName": {
"referenceName": "MyHDInsightLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"mapper": "MyMapper.exe",
"reducer": "MyReducer.exe",
"combiner": "MyCombiner.exe",
"fileLinkedService": {
"referenceName": "MyAzureStorageLinkedService",
"type": "LinkedServiceReference"
},
"filePaths": [
"<containername>/example/apps/MyMapper.exe",
"<containername>/example/apps/MyReducer.exe",
"<containername>/example/apps/MyCombiner.exe"
],
"input": "wasb://<containername>@<accountname>.blob.core.windows.net/example/input/MapperInput.txt",
"output": "wasb://<containername>@<accountname>.blob.core.windows.net/example/output/ReducerOutput.txt",
"commandEnvironment": [
"CmdEnvVarName=CmdEnvVarValue"
],
"getDebugInfo": "Failure",
"arguments": [
"SampleHadoopJobArgument1"
],
"defines": {
"param1": "param1Value"
}
}
}
Syntaxisdetails
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| naam | Naam van de activiteit | Ja |
| beschrijving | Tekst waarin wordt beschreven waarvoor de activiteit wordt gebruikt | Nee |
| type | Voor Hadoop Streaming-activiteit is het activiteitstype HDInsightStreaming | Ja |
| linkedServiceName | Verwijzing naar het HDInsight-cluster dat is geregistreerd als een gekoppelde service. Zie het artikel Gekoppelde services berekenen voor meer informatie over deze gekoppelde service. | Ja |
| Mapper | Hiermee geeft u de naam van het uitvoerbare mapper-bestand | Ja |
| Reducer | Hiermee geeft u de naam van het uitvoerbare reductieprogramma | Ja |
| combinatie | Hiermee geeft u de naam van het uitvoerbare combinatieprogramma | Nee |
| fileLinkedService | Verwijzing naar een gekoppelde Azure Storage-service die wordt gebruikt om de Mapper-, Combiner- en Reducer-programma's op te slaan die moeten worden uitgevoerd. Hier worden alleen gekoppelde Azure Blob Storage- en ADLS Gen2-services ondersteund. Als u deze gekoppelde service niet opgeeft, wordt de gekoppelde Azure Storage-service die is gedefinieerd in de gekoppelde HDInsight-service gebruikt. | Nee |
| filePath | Geef een matrix van het pad naar de Mapper-, Combiner- en Reducer-programma's op die zijn opgeslagen in Azure Storage waarnaar wordt verwezen door fileLinkedService. Het pad is hoofdlettergevoelig. | Ja |
| input | Hiermee geeft u het WASB-pad naar het invoerbestand voor mapper. | Ja |
| output | Hiermee geeft u het WASB-pad naar het uitvoerbestand voor de reducer. | Ja |
| getDebugInfo | Hiermee geeft u op wanneer de logboekbestanden worden gekopieerd naar de Azure Storage die wordt gebruikt door het HDInsight-cluster (of) dat is opgegeven door scriptLinkedService. Toegestane waarden: Geen, Altijd of Fout. Standaardwaarde: Geen. | Nee |
| Argumenten | Hiermee geeft u een matrix van argumenten voor een Hadoop-taak. De argumenten worden doorgegeven als opdrachtregelargumenten aan elke taak. | Nee |
| Definieert | Geef parameters op als sleutel-waardeparen voor verwijzingen in het Hive-script. | Nee |
Gerelateerde inhoud
Zie de volgende artikelen waarin wordt uitgelegd hoe u gegevens op andere manieren kunt transformeren: