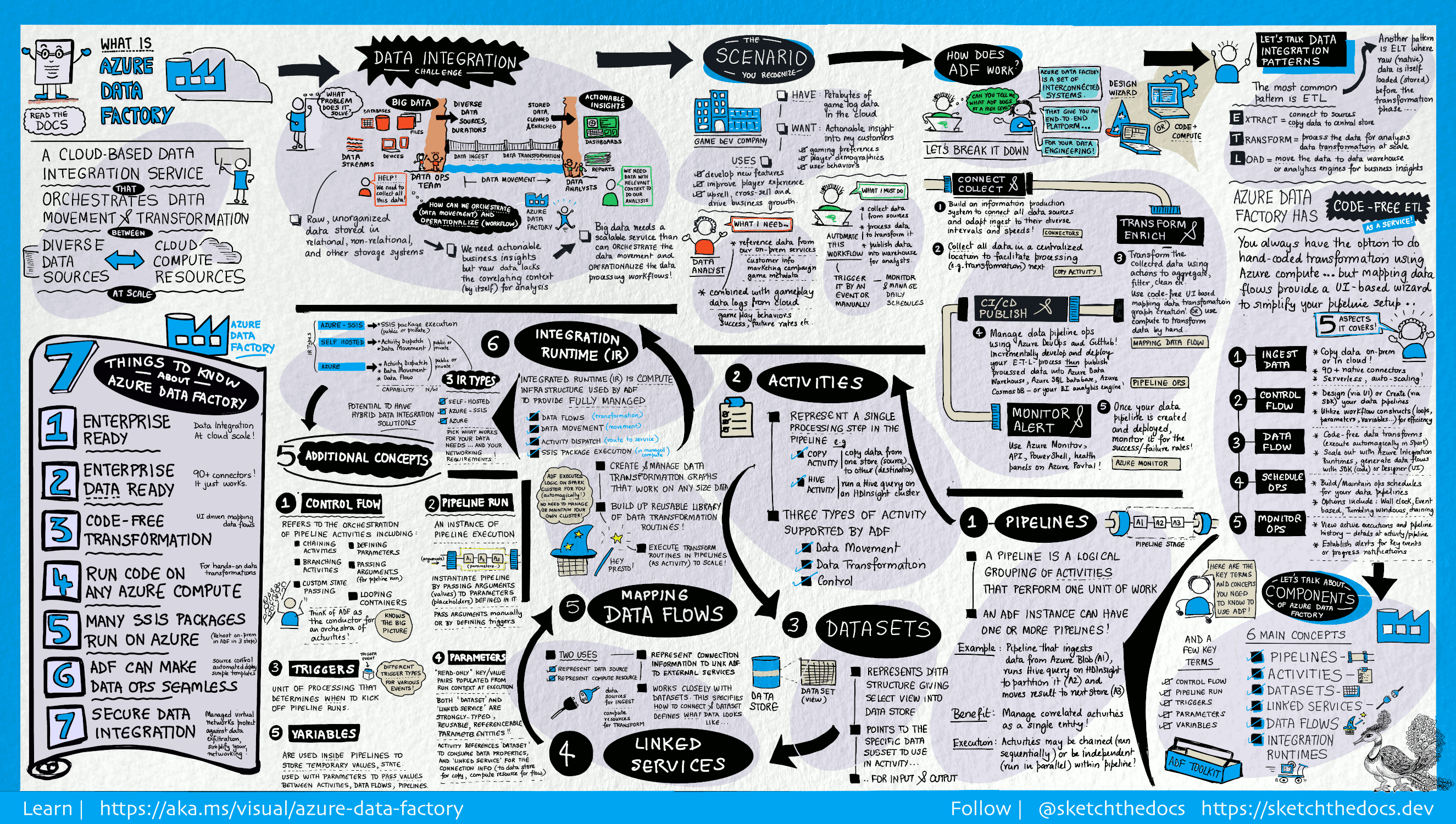
Wat is Azure Data Factory?
VAN TOEPASSING OP:  Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Tip
Probeer Data Factory uit in Microsoft Fabric, een alles-in-één analyseoplossing voor ondernemingen. Microsoft Fabric omvat alles, van gegevensverplaatsing tot gegevenswetenschap, realtime analyses, business intelligence en rapportage. Meer informatie over het gratis starten van een nieuwe proefversie .
In de wereld van big data worden onbewerkte, ongeordende gegevens vaak opgeslagen in relationele, niet-relationele en andere opslagsystemen. Op zichzelf staande, onbewerkte gegevens hebben echter niet de juiste context of betekenis om nuttige inzichten te kunnen bieden aan analisten, gegevenswetenschappers en besluitvormers.
Voor big data is een service nodig die het organiseren en het operationeel maken van processen mogelijk maakt om deze enorme hoeveelheden onbewerkte gegevens om te zetten naar bruikbare zakelijke inzichten. Azure Data Factory is een beheerde cloudservice die speciaal is ontworpen voor deze complexe hybride ETL- (extract-transform-load), ELT- (extract-load-transform) en gegevensintegratieprojecten.
Functies van Azure Data Factory
Gegevenscompressie: Tijdens de gegevens Copy-activiteit is het mogelijk om de gegevens te comprimeren en de gecomprimeerde gegevens naar de doelgegevensbron te schrijven. Deze functie helpt het bandbreedtegebruik bij het kopiëren van gegevens te optimaliseren.
Uitgebreide connectiviteitsondersteuning voor verschillende gegevensbronnen: Azure Data Factory biedt brede connectiviteitsondersteuning voor het maken van verbinding met verschillende gegevensbronnen. Dit is handig wanneer u gegevens uit verschillende gegevensbronnen wilt ophalen of schrijven.
Aangepaste gebeurtenistriggers: Met Azure Data Factory kunt u gegevensverwerking automatiseren met behulp van aangepaste gebeurtenistriggers. Met deze functie kunt u automatisch een bepaalde actie uitvoeren wanneer een bepaalde gebeurtenis plaatsvindt.
Gegevensvoorbeeld en validatie: tijdens de gegevens Copy-activiteit zijn er hulpprogramma's beschikbaar voor het bekijken en valideren van gegevens. Deze functie helpt u ervoor te zorgen dat gegevens correct worden gekopieerd en naar de doelgegevensbron worden geschreven.
Aanpasbare Gegevensstroom s: Met Azure Data Factory kunt u aanpasbare gegevensstromen maken. Met deze functie kunt u aangepaste acties of stappen voor gegevensverwerking toevoegen.
Geïntegreerde beveiliging: Azure Data Factory biedt geïntegreerde beveiligingsfuncties zoals Entra ID-integratie en op rollen gebaseerd toegangsbeheer om de toegang tot gegevensstromen te beheren. Deze functie verhoogt de beveiliging van gegevensverwerking en beschermt uw gegevens.
Gebruiksscenario's
Denk bijvoorbeeld aan een gamingbedrijf dat petabytes aan gamelogboeken verzamelt die worden geproduceerd door games in de cloud. Het bedrijf wil deze logboeken analyseren om inzicht te verkrijgen in de voorkeuren, de demografische gegevens en het gebruiksgedrag van klanten. Het bedrijf wil ook kansen voor up-selling en cross-selling identificeren, en nieuwe aantrekkelijke functies ontwikkelen om groei te stimuleren en klanten een betere ervaring te bieden.
Voor het analyseren van deze logboeken moet het bedrijf gebruikmaken van de referentiegegevens, zoals klantgegevens, game-informatie en marketingcampagnegegevens, die zich in een on-premises gegevensarchief bevinden. Het bedrijf wil deze gegevens uit het on-premises gegevensarchief gebruiken door ze te combineren met extra logboekgegevens in een gegevensarchief in de cloud.
Om inzichten te extraheren, wil het bedrijf de verzamelde gegevens verwerken met behulp van een Spark-cluster in de cloud (HDInsight) en de getransformeerde gegevens publiceren in een datawarehouse in de cloud, zoals Azure Synapse Analytics, om er gemakkelijk een rapport over te maken. Het bedrijf wil deze werkstroom automatiseren en volgens een dagelijks schema controleren en beheren. Ook wil het bedrijf de werkstroom uitvoeren wanneer bestanden in een blob store-container terechtkomen.
Azure Data Factory is het platform dat dergelijke gegevensscenario's oplost. Het is een cloud-gebaseerde ETL en gegevensintegratieservice waarmee u gegevensgestuurde werkstromen kunt maken en zo gegevensverplaatsing en -transformatie kunt indelen op schaal. Met behulp van Azure Data Factory kunt u gegevensgestuurde werkstromen (pijplijnen genoemd) maken en plannen die gegevens uit verschillende gegevensarchieven kunnen opnemen. U kunt complexe ETL-processen bouwen waarmee gegevens visueel worden getransformeerd met gegevens stromen of met behulp van berekeningsservices zoals Azure HDInsight Hadoop, Azure Databricks en Azure SQL Database.
Bovendien kunt u uw getransformeerde gegevens publiceren naar gegevensopslaglocaties zoals Azure Synapse Analytics, waar BI-toepassingen (business intelligence-oplossingen) er gebruik van kunnen maken. Via de Azure Data Factory kunnen onbewerkte gegevens uiteindelijk worden ingedeeld in zinvolle gegevensarchieven en data lakes zodat u betere zakelijke beslissingen kunt nemen.
Hoe werkt het?
Data Factory bevat een reeks onderling verbonden systemen die een volledig end-to-end platform bieden voor data-engineers.

Deze visuele handleiding biedt een gedetailleerd overzicht van de volledige Data Factory-architectuur:

Als u meer details wilt zien, selecteert u de voorgaande afbeelding om in te zoomen of bladert u naar de afbeelding met hoge resolutie.
{kind=link}
Verbinding maken en verzamelen
Bedrijven hebben gegevens van verschillende typen in verschillende on-premises bronnen, in de cloud, gestructureerd, niet-gestructureerd en semi-gestructureerd, die allemaal binnenkomen met verschillende tussenpozen en snelheden.
De eerste stap voor het bouwen van een informatieproductiesysteem bestaat uit het verbinden van alle vereiste gegevens- en verwerkingsbronnen, zoals SaaS-services (Software-as-a-Service), databases, bestandsshares en FTP-webservices. De volgende stap bestaat uit het zo nodig verplaatsen van gegevens naar een centrale locatie voor verdere verwerking.
Zonder Data Factory moeten ondernemingen aangepaste onderdelen voor gegevensverplaatsing ontwikkelen of aangepaste services schrijven om deze gegevensbronnen en verwerking te integreren. Het is duur en moeilijk om dergelijke systemen te integreren en te onderhouden. Bovendien beschikken ze vaak niet over de functionaliteit voor bewaking, waarschuwing en besturingselementen op bedrijfsniveau die een volledig beheerde service kan bieden.
Met Data Factory kunt u de kopieeractiviteit in een pijplijn gebruiken om gegevens van on-premises gegevensarchieven en gegevensarchieven uit de cloud te verplaatsen naar een gecentraliseerd gegevensarchief in de cloud voor verdere analyse. Zo kunt u bijvoorbeeld gegevens in Azure Data Lake Storage verzamelen en later transformeren met behulp van een Azure Data Lake Analytics-rekenservice. U kunt ook gegevens verzamelen in Azure Blob Storage en later transformeren met behulp van een Hadoop-cluster van Azure HDInsight.
Transformeren en verrijken
Nadat de gegevens in een gecentraliseerd gegevensarchief in de cloud zijn opgenomen, verwerkt of transformeert u de verzamelde gegevens met behulp van ADF-toewijzingsgegevensstromen. Gegevensstromen maken het voor gegevenstechnici mogelijk om transformatiegrafieken van gegevens te bouwen en te onderhouden die worden uitgevoerd op Spark zonder dat ze Spark-clusters of Spark-programmering moeten begrijpen.
Als u liever transformaties handmatig codeert, ondersteunt ADF externe activiteiten voor het uitvoeren van uw transformaties op berekeningsservices zoals HDInsight Hadoop, Spark, Data Lake Analytics en Machine Learning.
CI/CD en publiceren
Data Factory biedt volledige ondersteuning voor CI/CD van uw gegevenspijplijnen met behulp van Azure DevOps en GitHub. Zo kunt u uw ETL-processen stapsgewijs ontwikkelen en leveren voordat u het voltooide product publiceert. Nadat de onbewerkte gegevens zijn verfijnd in een bedrijfsklar verbruiksformulier, laadt u de gegevens in Azure Data Warehouse, Azure SQL Database, Azure Cosmos DB of de analyse-engine waarnaar uw zakelijke gebruikers kunnen verwijzen vanuit hun business intelligence-hulpprogramma's.
Monitor
Nadat u uw pijplijn voor gegevensintegratie hebt gemaakt en geïmplementeerd, en op die manier toegevoegde waarde biedt met getransformeerde gegevens, controleert u hoe vaak de geplande activiteiten en pijplijnen slagen en mislukken. Azure Data Factory heeft ingebouwde ondersteuning voor pijplijnbewaking via Azure Monitor, API, PowerShell, Azure Monitor-logboeken en statusvensters in de Azure-portal.
Concepten van het hoogste niveau
Een Azure-abonnement kan een of meer Azure Data Factory-exemplaren (ofwel 'data factory's') hebben. Azure Data Factory bestaat uit de volgende belangrijke onderdelen:
- Pipelines
- Activiteiten
- Gegevenssets
- Gekoppelde services
- Gegevensstromen
- Integration Runtimes
Deze onderdelen werken samen om een platform te bieden waarop u gegevensgestuurde werkstromen kunt maken met stappen voor de verplaatsing en transformatie van gegevens.
Pijplijn
Een data factory kan één of meer pijplijnen hebben. Een pijplijn is een logische groep activiteiten die samen een taak uitvoeren. De activiteiten in een pijplijn voeren samen een taak uit. Zo kan een pijplijn bijvoorbeeld een groep activiteiten bevatten die gegevens van een Azure-blob opnemen en vervolgens een Hive-query uitvoeren op een HDInsight-cluster om de gegevens te partitioneren.
Het voordeel van een pijplijn is dat u de activiteiten kunt beheren als een groep in plaats van afzonderlijke activiteiten te beheren. De activiteiten in een pijplijn kunnen in een keten worden samengevoegd om na elkaar of onafhankelijk en parallel te worden uitgevoerd.
Toewijzing gegevensstromen
Grafieken van gegevens maken en beheren die u kunt gebruiken om gegevens van elke grootte te transformeren. U kunt een herbruikbare bibliotheek met routines van gegevenstransformatie bouwen en deze processen uitvoeren op een uitgeschaalde manier vanuit uw ADF-pijplijnen. Data Factory voert uw logica uit op een Spark-cluster dat opstart en afsluit wanneer dat nodig is. U hoeft clusters nooit te beheren of te onderhouden.
Activiteit
Activiteiten vertegenwoordigen een verwerkingsstap in een pijplijn. U kunt bijvoorbeeld een kopieeractiviteit gebruiken om gegevens van één gegevensarchief naar een ander te kopiëren. U kunt ook een Hive-activiteit gebruiken, waarmee een Hive-query wordt uitgevoerd voor een Azure HDInsight-cluster om uw gegevens te transformeren of analyseren. Data Factory ondersteunt drie soorten activiteiten: activiteiten voor gegevensverplaatsing, activiteiten voor gegevenstransformatie en controleactiviteiten.
Gegevenssets
Gegevenssets vertegenwoordigen gegevensstructuren in de gegevensarchieven die simpelweg verwijzen naar de gegevens die u in uw activiteiten als in- of uitvoer wilt gebruiken.
Gekoppelde services
Gekoppelde services zijn te vergelijken met verbindingsreeksen, die de verbindingsinformatie bevatten die Data Factory nodig heeft om verbinding te maken met externe bronnen. Als u het op deze manier bekijkt, vertegenwoordigt de gegevensset in feite de structuur van de gegevens en definieert de gekoppelde service de verbinding met de gegevensbron. Een met Azure Storage gekoppelde service geeft bijvoorbeeld een verbindingsreeks zodat deze verbinding kan maken met het Azure Storage-account. Ook geeft een Azure Blob-gegevenssets de blobcontainer op, en de map met de gegevens.
Gekoppelde services worden voor twee doeleinden gebruikt in een Data Factory:
Als vertegenwoordiging van een gegevensarchief, zoals een SQL Server-database, een Oracle-database, een bestandsshare of een Azure Blob Storage-account. Zie het artikel kopieeractiviteit voor een lijst met ondersteunde gegevensarchieven.
Ter vertegenwoordiging van een rekenresource die de uitvoering van een activiteit kan hosten. De activiteit HDInsightHive wordt bijvoorbeeld uitgevoerd in een HDInsight Hadoop-cluster. Zie het artikel Gegevens transformeren voor een lijst met transformatieactiviteiten en ondersteunde rekenomgevingen.
Integration Runtime
In de Data Factory definieert een activiteit de actie die moet worden uitgevoerd. Een gekoppelde service definieert een doelgegevensarchief of een rekenservice. Een Integration Runtime vormt de brug tussen de activiteit en de gekoppelde services. Er wordt naar verwezen door de gekoppelde service of activiteit en biedt de rekenomgeving waarin de activiteit wordt uitgevoerd of wordt verzonden. Op deze manier kan de activiteit optimaal worden uitgevoerd in de regio die het dichtst mogelijk bij het doelgegevensarchief of de rekenservice ligt, terwijl wordt voldaan aan vereisten rondom beveiliging en naleving.
Triggers
Triggers zijn verwerkingseenheden die bepalen wanneer een pijplijnuitvoering moet worden gestart. Er zijn verschillende soorten triggers voor verschillende soorten gebeurtenissen.
Pijplijnuitvoeringen
Een pijplijnuitvoering is een exemplaar van de uitvoering van de pijplijn. Pijplijnuitvoeringen worden doorgaans geïnstantieerd doordat argumenten worden doorgegeven aan de parameters die zijn gedefinieerd in pijplijnen. De argumenten kunnen handmatig of in de triggerdefinitie worden doorgegeven.
Parameters
Parameters zijn sleutel-waardeparen van een alleen-lezen-configuratie. Parameters worden gedefinieerd in de pijplijn. De argumenten voor de gedefinieerde parameters worden doorgegeven tijdens het uitvoeren van de uitvoeringscontext, die wordt gemaakt door een trigger of een pijplijn die handmatig wordt uitgevoerd. Activiteiten binnen de pijplijn gebruiken de parameterwaarden.
Een gegevensset is een algemeen type parameter en een herbruikbare entiteit waarnaar kan worden verwezen. Een activiteit kan verwijzen naar gegevenssets en kan de eigenschappen die zijn gedefinieerd in de definitie van de gegevensset gebruiken.
Een gekoppelde service is ook een algemeen type parameter met de verbindingsgegevens voor een gegevensarchief of een rekenomgeving. Deze is ook een herbruikbare entiteit waarnaar kan worden verwezen.
Controlestroom
De controlestroom is een indeling van activiteiten van de pijplijn, waaronder het koppelen van activiteiten in een reeks, maken van vertakkingen en definiëren van parameters op het niveau van de pijplijn. Argumenten worden doorgegeven tijdens het aanroepen van de pijplijn op aanvraag of vanuit een trigger. Deze omvat ook het doorgeven van een aangepaste status en luscontainers, ofwel For-each-iterators.
Variabelen
Variabelen kunnen worden gebruikt in pijplijnen voor het opslaan van tijdelijke waarden en kunnen ook worden gebruikt in combinatie met parameters om het doorgeven van waarden tussen pijplijnen, gegevensstromen en andere activiteiten mogelijk te maken.
Gerelateerde inhoud
Hier volgen belangrijke documenten voor de volgende stap om te verkennen: