Gegevens verwerken door U-SQL-scripts uit te voeren in Azure Data Lake Analytics met Azure Data Factory en Synapse Analytics
VAN TOEPASSING OP:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Probeer Data Factory uit in Microsoft Fabric, een alles-in-één analyseoplossing voor ondernemingen. Microsoft Fabric omvat alles, van gegevensverplaatsing tot gegevenswetenschap, realtime analyses, business intelligence en rapportage. Meer informatie over het gratis starten van een nieuwe proefversie .
Een pijplijn in een Azure Data Factory- of Synapse Analytics-werkruimte verwerkt gegevens in gekoppelde opslagservices met behulp van gekoppelde rekenservices. Het bevat een reeks activiteiten waarbij elke activiteit een specifieke verwerkingsbewerking uitvoert. In dit artikel wordt de Data Lake Analytics U-SQL-activiteit beschreven waarmee een U-SQL-script wordt uitgevoerd op een gekoppelde Azure Data Lake Analytics-rekenservice .
Maak een Azure Data Lake Analytics-account voordat u een pijplijn maakt met een Data Lake Analytics U-SQL-activiteit. Zie Aan de slag met Azure Data Lake Analytics voor meer informatie over Azure Data Lake Analytics.
Een U-SQL-activiteit voor Azure Data Lake Analytics toevoegen aan een pijplijn met ui
Voer de volgende stappen uit om een U-SQL-activiteit te gebruiken voor Azure Data Lake Analytics in een pijplijn:
Zoek naar Data Lake in het deelvenster Pijplijnactiviteiten en sleep een U-SQL-activiteit naar het pijplijncanvas.
Selecteer de nieuwe U-SQL-activiteit op het canvas als deze nog niet is geselecteerd.
Selecteer het tabblad ADLA-account om een nieuwe gekoppelde Azure Data Lake Analytics-service te selecteren of te maken die wordt gebruikt voor het uitvoeren van de U-SQL-activiteit.
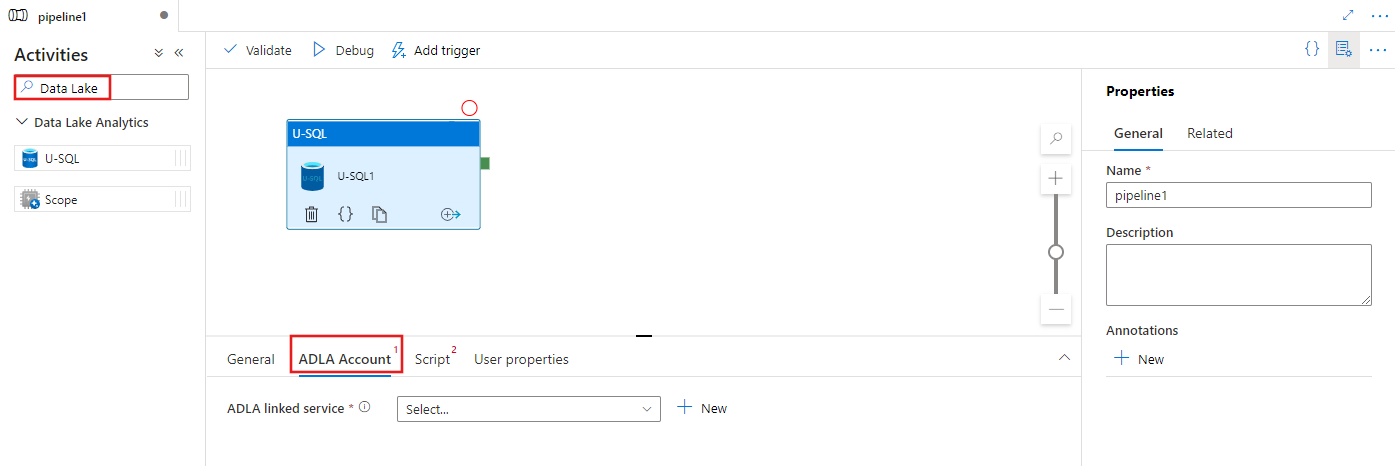
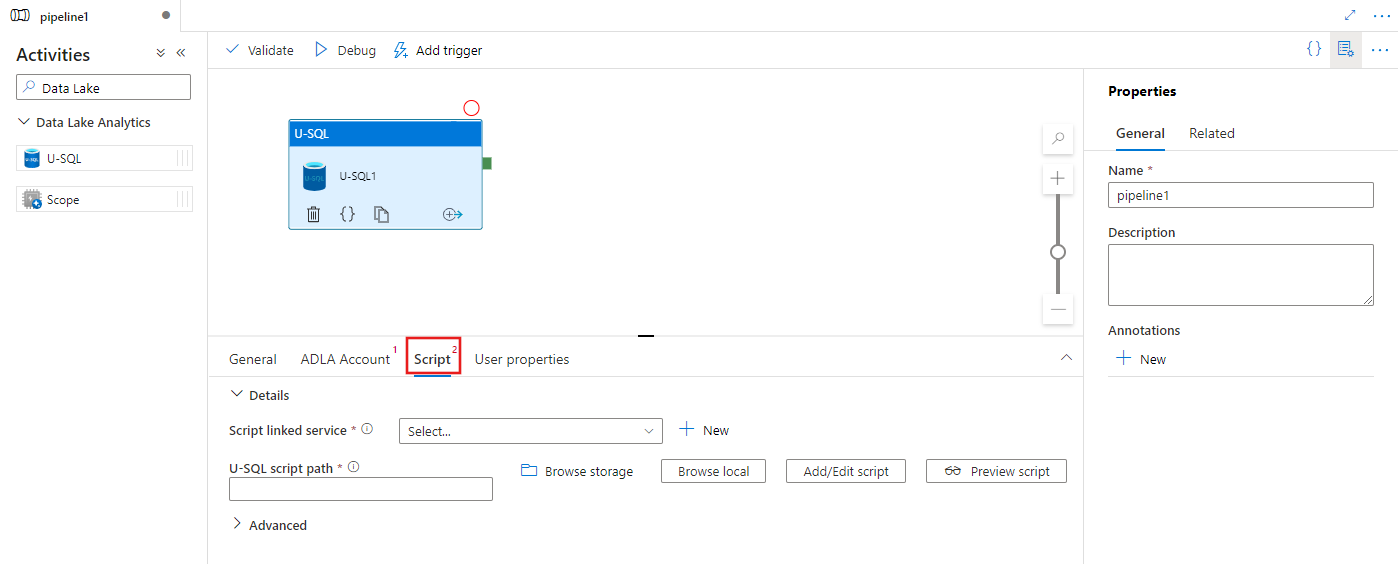
Selecteer het tabblad Script om een nieuwe gekoppelde opslagservice te selecteren of te maken, en een pad binnen de opslaglocatie, waarop het script wordt gehost.
Gekoppelde Azure Data Lake Analytics-service
U maakt een gekoppelde Azure Data Lake Analytics-service om een Azure Data Lake Analytics-rekenservice te koppelen aan een Azure Data Factory- of Synapse Analytics-werkruimte. De Data Lake Analytics U-SQL-activiteit in de pijplijn verwijst naar deze gekoppelde service.
De volgende tabel bevat beschrijvingen voor de algemene eigenschappen die worden gebruikt in de JSON-definitie.
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De typeeigenschap moet worden ingesteld op: AzureDataLakeAnalytics. | Ja |
| accountName | Azure Data Lake Analytics-accountnaam. | Ja |
| dataLakeAnalyticsUri | Azure Data Lake Analytics-URI. | Nee |
| subscriptionId | Azure-abonnements-id | Nee |
| resourceGroupName | Naam van Azure-resourcegroep | Nee |
Verificatie van service-principal
Voor de gekoppelde Azure Data Lake Analytics-service is een service-principalverificatie vereist om verbinding te maken met de Azure Data Lake Analytics-service. Als u service-principalverificatie wilt gebruiken, registreert u een toepassingsentiteit in Microsoft Entra-id en verleent u deze toegang tot zowel Data Lake Analytics als de Data Lake Store die wordt gebruikt. Zie Service-to-service-verificatie voor gedetailleerde stappen. Noteer de volgende waarden die u gebruikt om de gekoppelde service te definiëren:
- Toepassings-id
- Toepassingssleutel
- Tenant-id
Verwijs de service-principal toestemming voor uw Azure Data Lake Analytics met behulp van de wizard Gebruiker toevoegen.
Gebruik service-principalverificatie door de volgende eigenschappen op te geven:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| servicePrincipalId | Geef de client-id van de toepassing op. | Ja |
| servicePrincipalKey | Geef de sleutel van de toepassing op. | Ja |
| tenant | Geef de tenantgegevens (domeinnaam of tenant-id) op waaronder uw toepassing zich bevindt. U kunt deze ophalen door de muisaanwijzer in de rechterbovenhoek van Azure Portal te bewegen. | Ja |
Voorbeeld: Verificatie van service-principal
{
"name": "AzureDataLakeAnalyticsLinkedService",
"properties": {
"type": "AzureDataLakeAnalytics",
"typeProperties": {
"accountName": "<account name>",
"dataLakeAnalyticsUri": "<azure data lake analytics URI>",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"value": "<service principal key>",
"type": "SecureString"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>",
"subscriptionId": "<optional, subscription id of ADLA>",
"resourceGroupName": "<optional, resource group name of ADLA>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Zie Gekoppelde compute-services voor meer informatie over de gekoppelde service.
Data Lake Analytics U-SQL-activiteit
Het volgende JSON-fragment definieert een pijplijn met een Data Lake Analytics U-SQL-activiteit. De activiteitsdefinitie heeft een verwijzing naar de gekoppelde Azure Data Lake Analytics-service die u eerder hebt gemaakt. Als u een Data Lake Analytics U-SQL-script wilt uitvoeren, verzendt de service het script dat u hebt opgegeven bij Data Lake Analytics en worden de vereiste invoer en uitvoer gedefinieerd in het script voor Het ophalen en uitvoeren van Data Lake Analytics.
{
"name": "ADLA U-SQL Activity",
"description": "description",
"type": "DataLakeAnalyticsU-SQL",
"linkedServiceName": {
"referenceName": "<linked service name of Azure Data Lake Analytics>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"scriptLinkedService": {
"referenceName": "<linked service name of Azure Data Lake Store or Azure Storage which contains the U-SQL script>",
"type": "LinkedServiceReference"
},
"scriptPath": "scripts\\kona\\SearchLogProcessing.txt",
"degreeOfParallelism": 3,
"priority": 100,
"parameters": {
"in": "/datalake/input/SearchLog.tsv",
"out": "/datalake/output/Result.tsv"
}
}
}
In de volgende tabel worden namen en beschrijvingen beschreven van eigenschappen die specifiek zijn voor deze activiteit.
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| naam | Naam van de activiteit in de pijplijn | Ja |
| beschrijving | Tekst die beschrijft wat de activiteit doet. | Nee |
| type | Voor Data Lake Analytics U-SQL-activiteit is het activiteitstype DataLakeAnalyticsU-SQL. | Ja |
| linkedServiceName | Gekoppelde service aan Azure Data Lake Analytics. Zie het artikel Gekoppelde services berekenen voor meer informatie over deze gekoppelde service. | Ja |
| scriptPath | Pad naar map die het U-SQL-script bevat. De naam van het bestand is hoofdlettergevoelig. | Ja |
| scriptLinkedService | Gekoppelde service die de Azure Data Lake Store of Azure Storage koppelt die het script bevat | Ja |
| degreeOfParallelism | Het maximum aantal knooppunten dat tegelijkertijd wordt gebruikt om de taak uit te voeren. | Nee |
| priority | Bepaalt welke taken in de wachtrij moeten worden geselecteerd om eerst te worden uitgevoerd. Hoe lager het getal, hoe hoger de prioriteit. | Nee |
| parameters | Parameters die moeten worden doorgegeven aan het U-SQL-script. | Nee |
| runtimeVersion | Runtimeversie van de U-SQL-engine die moet worden gebruikt. | Nee |
| compilationMode | Compilatiemodus van U-SQL. Moet een van deze waarden zijn: Semantisch: Voer alleen semantische controles en noodzakelijke saniteitscontroles uit, Volledig: Voer de volledige compilatie uit, inclusief syntaxiscontrole, optimalisatie, codegeneratie, enzovoort, SingleBox: Voer de volledige compilatie uit met de instelling TargetType op SingleBox. Als u geen waarde voor deze eigenschap opgeeft, bepaalt de server de optimale compilatiemodus. |
Nee |
Zie SearchLogProcessing.txt voor de scriptdefinitie.
Voorbeeld van U-SQL-script
@searchlog =
EXTRACT UserId int,
Start DateTime,
Region string,
Query string,
Duration int,
Urls string,
ClickedUrls string
FROM @in
USING Extractors.Tsv(nullEscape:"#NULL#");
@rs1 =
SELECT Start, Region, Duration
FROM @searchlog
WHERE Region == "en-gb";
@rs1 =
SELECT Start, Region, Duration
FROM @rs1
WHERE Start <= DateTime.Parse("2012/02/19");
OUTPUT @rs1
TO @out
USING Outputters.Tsv(quoting:false, dateTimeFormat:null);
In het bovenstaande voorbeeldscript wordt de invoer en uitvoer voor het script gedefinieerd in @in en @out parameters. De waarden voor @in en @out parameters in het U-SQL-script worden dynamisch doorgegeven door de service met behulp van de sectie Parameters.
U kunt andere eigenschappen, zoals degreeOfParallelism en prioriteit, opgeven in uw pijplijndefinitie voor de taken die worden uitgevoerd in de Azure Data Lake Analytics-service.
Dynamische parameters
In de definitie van de voorbeeldpijplijn worden in- en uitparameters toegewezen met vastgelegde waarden.
"parameters": {
"in": "/datalake/input/SearchLog.tsv",
"out": "/datalake/output/Result.tsv"
}
Het is mogelijk om in plaats daarvan dynamische parameters te gebruiken. Voorbeeld:
"parameters": {
"in": "/datalake/input/@{formatDateTime(pipeline().parameters.WindowStart,'yyyy/MM/dd')}/data.tsv",
"out": "/datalake/output/@{formatDateTime(pipeline().parameters.WindowStart,'yyyy/MM/dd')}/result.tsv"
}
In dit geval worden invoerbestanden nog steeds opgehaald uit de map /datalake/input en worden uitvoerbestanden gegenereerd in de map /datalake/output. De bestandsnamen zijn dynamisch op basis van de begintijd van het venster dat wordt doorgegeven wanneer de pijplijn wordt geactiveerd.
Gerelateerde inhoud
Zie de volgende artikelen waarin wordt uitgelegd hoe u gegevens op andere manieren kunt transformeren: