의료 데이터 솔루션에서 구조화되지 않은 임상 노트 보강(프리뷰) 사용
[이 문서는 시험판 문서이며 변경될 수 있습니다.]
참고
이 콘텐츠는 현재 업데이트 중입니다.
구조화되지 않은 임상 노트 보강(프리뷰)은 Azure AI 언어의 Text Analytics for Health 서비스를 사용하여 구조화되지 않은 임상 노트에서 주요 FHIR(전자 의료 기록 교환) 엔터티를 추출합니다. 이러한 임상 노트에서 구조화된 데이터를 생성합니다. 그런 다음 이 구조화된 데이터를 분석하여 환자 건강 결과를 개선하기 위한 인사이트, 예측 및 품질 측정을 도출할 수 있습니다.
기능에 대해 자세히 알아보고 배포 및 구성하는 방법을 이해하려면 다음을 참조하세요.
구조화되지 않은 임상 노트 보강(프리뷰)은 의료 데이터 기반 기능에 직접 종속됩니다. 먼저 의료 데이터 기반 파이프라인을 성공적으로 설정하고 실행해야 합니다.
사전 요구 사항
- Microsoft Fabric에서 의료 데이터 솔루션 배포
- 의료 데이터 기반 배포에 기초 Notebook과 파이프라인을 설치합니다.
- Azure 언어 서비스 설정에서 설명한 대로 Azure 언어 서비스를 설정합니다.
- 구조화되지 않은 임상 노트 보강(프리뷰) 배포 및 구성
- OMOP 변환 배포 및 구성. 이 단계는 선택 사항입니다.
NLP 수집 서비스
healthcare#_msft_ta4h_silver_ingestion Notebook은 의료 데이터 솔루션 라이브러리의 NLPIngestionService 모듈을 실행하여 Text Analytics for Health 서비스를 호출합니다. 이 서비스는 FHIR 리소스 DocumentReference.Content에서 구조화되지 않은 임상 노트를 추출하여 병합된 출력을 생성합니다. 자세한 내용은 Notebook 구성 검토를 참조하세요.
실버 레이어의 데이터 스토리지
자연어 처리(NLP) API 분석 후, 구조화되고 병합된 출력은 healthcare#_msft_silver 레이크하우스 내의 다음 네이티브 테이블에 저장됩니다.
- nlpentity: 구조화되지 않은 임상 노트에서 추출된 병합된 엔터티를 포함합니다. 각 행은 텍스트 분석을 수행한 후 구조화되지 않은 텍스트에서 추출된 단일 용어입니다.
- nlprelationship: 추출된 엔터티 간의 관계를 제공합니다.
- nlpfhir: FHIR 출력 번들을 JSON 문자열로 포함합니다.
마지막 업데이트 타임스탬프를 추적하기 위해 NLPIngestionService는 세 개의 모든 실버 레이크하우스 테이블에서 parent_meta_lastUpdated 필드를 사용합니다. 이러한 추적을 통해 상위 리소스인 원본 문서 DocumentReference가 먼저 저장되어 참조 무결성이 유지됩니다. 이 프로세스는 데이터 및 분리된 리소스의 불일치를 방지하는 데 도움이 됩니다.
중요
현재, Text Analytics for Health는 UMLS Metathesaurus 어휘 설명서에 나열된 어휘를 반환합니다. 이러한 어휘에 대한 지침은 UMLS에서 데이터 가져오기를 참조하세요.
프리뷰 릴리스에서는 Observational Health Data Sciences and Informatics (OHDSI)의 지침에 따라 OMOP 샘플 데이터 세트에 포함된 SNOMED-CT (Systematized Nomenclature of Medicine - Clinical Terms), LOINC (Logical Observation Identifiers, Names, and Codes), RxNorm 용어를 사용했습니다.
OMOP 변환
Microsoft Fabric의 의료 데이터 솔루션은 Observational Medical Outcomes Partnership (OMOP) 변환을 위한 또 다른 기능도 제공합니다. 이 기능을 실행하면 실버 레이크하우스에서 OMOP 골드 레이크하우스로의 기본 변환은 구조화되지 않은 임상 노트 분석의 구조화되고 병합된 출력도 변환합니다. 이 변환은 실버 레이크하우스의 nlpentity 테이블에서 데이터를 읽어 OMOP 골드 레이크하우스의 NOTE_NLP 테이블에 출력을 매핑합니다.
자세한 내용은 OMOP 변환 개요를 참조하세요.
다음은 구조화된 NLP 출력에 대한 스키마이며, 해당 NOTE_NLP 열은 OMOP Common Data Model에 매핑됩니다.
| 병합된 문서 참조 | 설명 | Note_NLP 매핑 | 샘플 데이터 |
|---|---|---|---|
| id | 엔터티의 고유 식별자입니다. parent_id offset 및 length의 복합 키. |
note_nlp_id |
1380 |
| parent_id | 용어가 추출된 병합된 documentreferencecontent 텍스트에 대한 외래 키입니다. | note_id |
625 |
| text | 문서에 나타나는 엔터티 텍스트입니다. | lexical_variant |
알려진 알레르기 없음 |
| 오프셋 | 입력 documentreferencecontent 텍스트에서 추출된 용어의 문자 오프셋입니다. | offset |
294 |
| data_source_entity_id | 특정 원본 카탈로그의 엔터티 ID입니다. | note_nlp_concept_id 및 note_nlp_source_concept_id |
37396387 |
| nlp_last_executed | documentreferencecontent 텍스트 분석 처리 날짜입니다. | nlp_date_time 및 nlp_date |
2023-05-17T00:00:00.0000000 |
| 모델 | NLP 시스템의 이름 및 버전(Text Analytics for Health 시스템의 이름 및 버전) | nlp_system |
MSFT TA4H |

Text Analytics for Health에 대한 서비스 제한
- 문서당 최대 문자 수는 125,000자로 제한됩니다.
- 전체 요청에 포함된 문서의 최대 크기는 1MB로 제한됩니다.
- 요청당 최대 문서 수는 다음과 같이 제한됩니다.
- 웹 기반 API의 경우 25개입니다.
- 컨테이너의 경우 1,000개입니다.
로그 사용
다음 단계에 따라 Text Analytics for health API에 대한 요청 및 응답 로깅을 사용하도록 설정합니다.
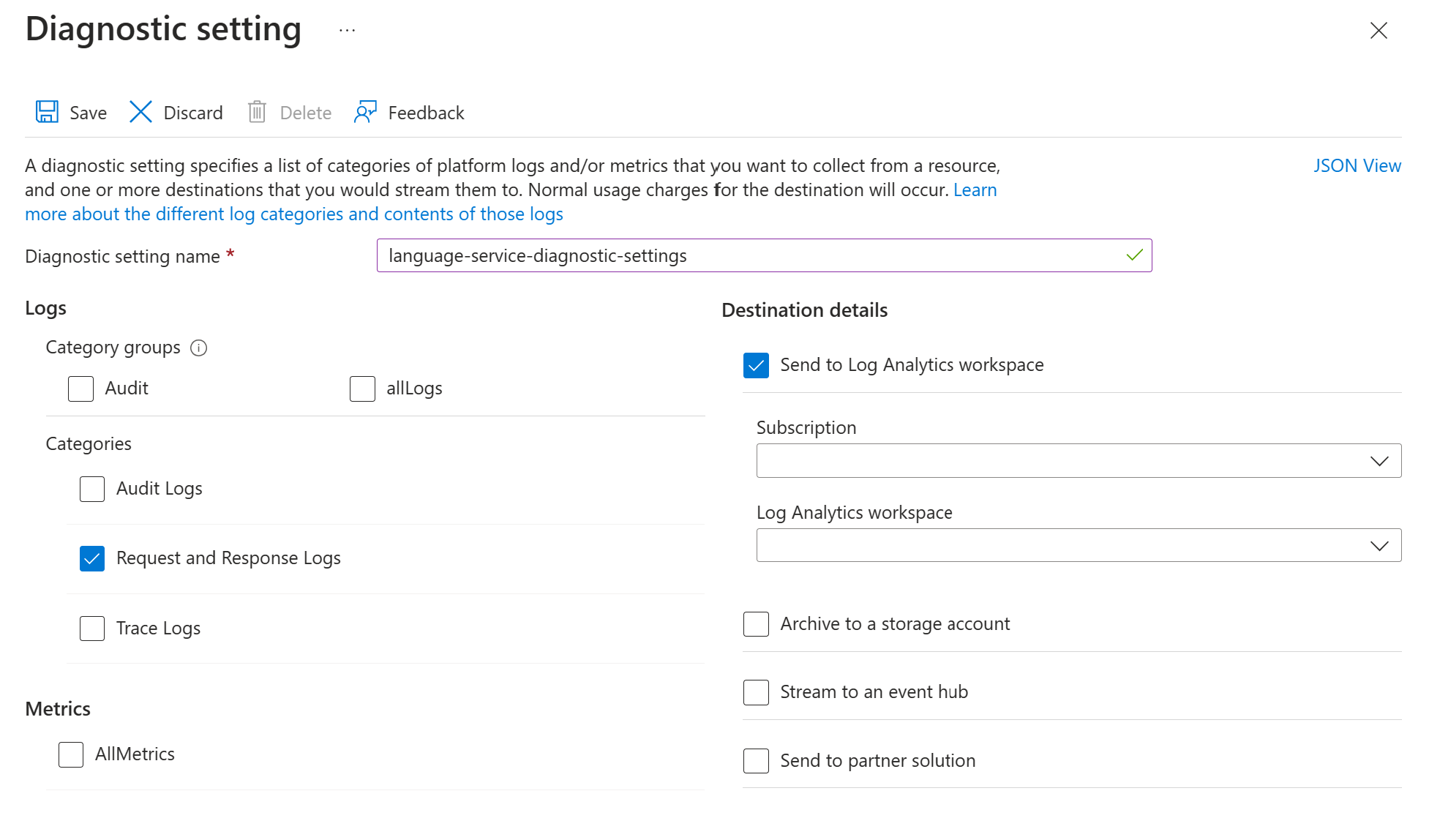
Azure AI 서비스에 대한 진단 로깅 사용의 지침에 따라 Azure 언어 서비스 리소스에 대한 진단 설정을 사용하도록 설정합니다. 이 리소스는 Azure 언어 서비스 설정 배포 단계에서 만든 언어 서비스와 동일합니다.
- 진단 설정 이름을 입력합니다.
- 범주를 요청 및 응답 로그로 설정합니다.
- 대상 세부 정보를 확인하려면 Log Analytics 작업 영역으로 보내기를 선택하고 필요한 Log Analytics 작업 영역을 선택하세요. 작업 영역이 없는 경우 표시되는 메시지에 따라 작업 영역을 만듭니다.
- 설정 저장.
NLP 수집 서비스 Notebook의 NLP 구성 섹션으로 이동합니다. 구성 매개 변수
enable_text_analytics_logs의 값을True로 업데이트합니다. 이 Notebook에 대한 자세한 내용은 Notebook 구성 검토를 참조하십시오.

Azure Log Analytics에서 로그 보기
로그 분석 데이터를 탐색하려면 다음을 수행합니다.
- Log Analytics 작업 영역으로 이동합니다.
- 로그를 찾아 선택합니다. 이 페이지에서 로그에 대한 쿼리를 실행할 수 있습니다.
샘플 쿼리
다음은 로그 데이터를 탐색하는 데 사용할 수 있는 기본 Kusto 쿼리입니다. 이 샘플 쿼리는 지난 하루 동안 Azure Cognitive Services 리소스 공급자로부터 실패한 모든 요청을 오류 유형별로 그룹화하여 검색합니다.
AzureDiagnostics
| where TimeGenerated > ago(1d)
| where Category == "RequestResponse"
| where ResourceProvider == "MICROSOFT.COGNITIVESERVICES"
| where tostring(ResultSignature) startswith "4" or tostring(ResultSignature) startswith "5"
| summarize NumberOfFailedRequests = count() by ResultSignature