Fabric에서 Apache Spark 작업 정의를 만드는 방법
이 자습서에서는 Microsoft Fabric에서 Spark 작업 정의를 만드는 방법을 알아봅니다.
필수 조건
시작하기 전에 다음 항목이 필요합니다.
- 활성 구독이 있는 Fabric 테넌트 계정 체험 계정을 만듭니다.
팁
Spark 작업 정의 항목을 실행하려면 기본 정의 파일과 기본 레이크하우스 컨텍스트가 있어야 합니다. 레이크하우스가 없는 경우 레이크하우스 만들기의 단계에 따라 레이크하우스를 만들 수 있습니다.
Spark 작업 정의 만들기
Spark 작업 정의 만들기 프로세스는 빠르고 간단하며 여러 가지 방법으로 시작할 수 있습니다.
Spark 작업 정의 만들기 옵션
만들기 프로세스를 시작하는 방법에는 두 가지가 있습니다.
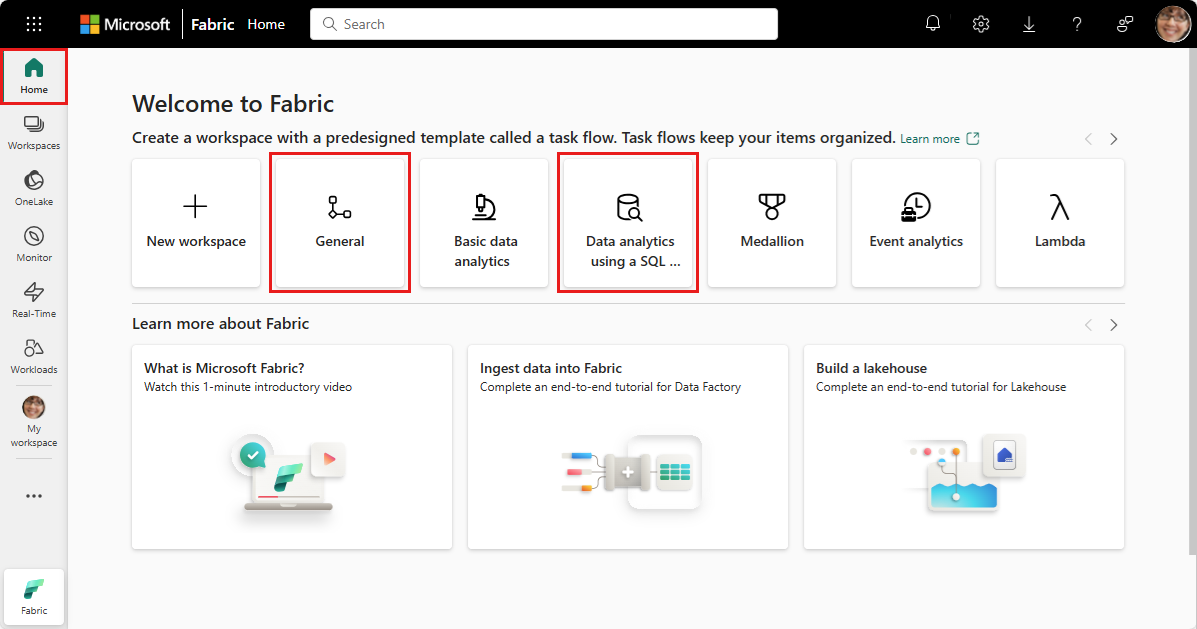
작업 영역 보기: Fabric 작업 영역에서 새 항목>Spark 작업 정의을 선택하여 Spark 작업 정의를 쉽게 만들 수 있습니다.
Fabric 홈: Spark 작업 정의를 만드는 또 다른 진입점은 Fabric 홈페이지의 'SQL ...' 타일을 사용하는 데이터 분석입니다. 일반 타일을 선택하여 동일한 옵션을 찾을 수 있습니다.

Spark 작업 정의를 만들 때 이름을 지정해야 합니다. 이 이름은 테넌트 내에서 고유해야 합니다. 새 Spark 작업 정의는 현재 작업 영역에서 생성됩니다.
PySpark(Python)에 대한 Spark 작업 정의 만들기
PySpark에 대한 Spark 작업 정의를 만들려면 다음 작업을 수행합니다.
샘플 Parquet 파일 yellow_tripdata_2022-01.parquet을 다운로드하여 Lakehouse의 파일 섹션에 업로드합니다.
새 Spark 작업 정의를 만듭니다.
언어 드롭다운 메뉴에서 PySpark(Python)를 선택합니다.
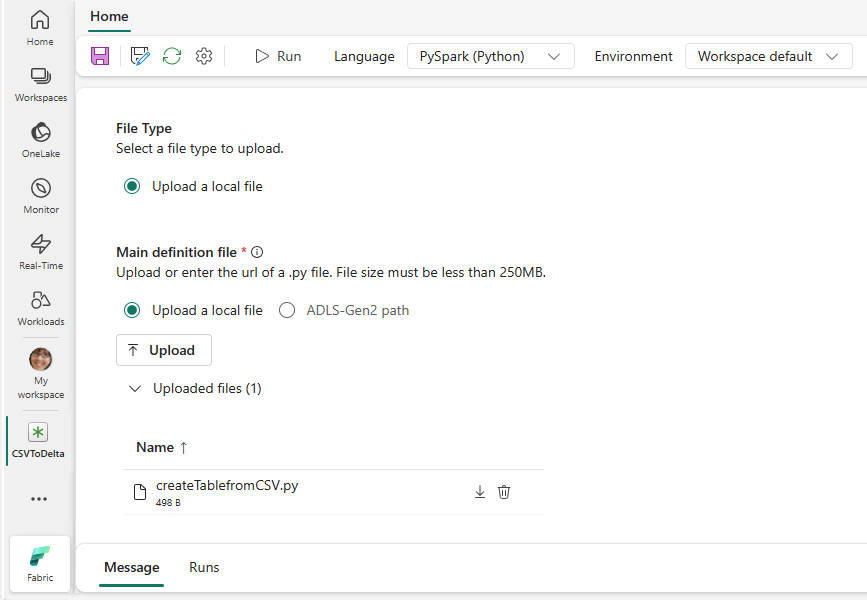
createTablefromParquet.py 샘플을 다운로드하고 기본 정의 파일로 업로드합니다. 기본 정의 파일(job.Main)은 애플리케이션 논리를 포함하고 Spark 작업을 실행해야 하는 파일입니다. 각 Spark 작업 정의에 대해 하나의 기본 정의 파일만 업로드할 수 있습니다.
로컬 데스크톱에서 기본 정의 파일을 업로드하거나 파일의 전체 ABFSS 경로를 제공하여 기존 ADLS(Azure Data Lake Storage) Gen2에서 업로드할 수 있습니다. 예들 들어
abfss://your-storage-account-name.dfs.core.windows.net/your-file-path입니다.참조 파일을 .py 파일로 업로드합니다. 참조 파일은 기본 정의 파일에서 가져오는 Python 모듈입니다. 기본 정의 파일과 마찬가지로 데스크톱 또는 기존 ADLS Gen2에서 업로드할 수 있습니다. 여러 참조 파일이 지원됩니다.
팁
ADLS Gen2 경로를 사용하는 경우 파일에 액세스할 수 있는지 확인하려면 작업을 실행하는 사용자 계정에 스토리지 계정에 대한 적절한 권한을 부여해야 합니다. 이 작업을 수행하기 위해 제안할 수 있는 두 가지 방법은 다음과 같습니다.
- 사용자 계정에 스토리지 계정에 대한 참가자 역할을 할당합니다.
- ADLS Gen2 ACL(액세스 제어 목록)을 통해 파일에 대한 사용자 계정에 읽기 및 실행 권한을 부여합니다.
수동 실행의 경우 현재 로그인한 사용자의 계정을 사용하여 작업을 제출합니다.
필요한 경우 작업에 대한 명령줄 인수를 제공합니다. 공백을 분할기로 사용하여 인수를 구분합니다.
작업에 레이크하우스 참조를 추가합니다. 작업에 하나 이상의 레이크하우스 참조가 추가되어야 합니다. 이 레이크하우스는 작업에 대한 기본 레이크하우스 컨텍스트입니다.
여러 레이크하우스 참조가 지원됩니다. Spark 설정 페이지에서 기본이 아닌 레이크하우스 이름과 전체 OneLake URL을 찾습니다.
Scala/Java에 대한 Spark 작업 정의 만들기
Scala/Java에 대한 Spark 작업 정의를 만들려면 다음 작업을 수행합니다.
새 Spark 작업 정의를 만듭니다.
언어 드롭다운에서 Spark(Scala/Java)를 선택합니다.
기본 정의 파일을 .jar 파일로 업로드합니다. 기본 정의 파일은 작업의 애플리케이션 논리를 포함하고 Spark 작업을 실행해야 하는 파일입니다. 각 Spark 작업 정의에 대해 하나의 기본 정의 파일만 업로드할 수 있습니다. Main 클래스 이름을 제공합니다.
참조 파일을 .jar 파일로 업로드합니다. 참조 파일은 기본 정의 파일에서 참조/가져오는 파일입니다.
필요한 경우 작업에 대한 명령줄 인수를 제공합니다.
작업에 레이크하우스 참조를 추가합니다. 작업에 하나 이상의 레이크하우스 참조가 추가되어야 합니다. 이 레이크하우스는 작업에 대한 기본 레이크하우스 컨텍스트입니다.
R에 대한 Spark 작업 정의 만들기
SparkR(R)에 대한 Spark 작업 정의를 만들려면 다음 작업을 수행합니다.
새 Spark 작업 정의를 만듭니다.
언어 드롭다운에서 SparkR(R)을 선택합니다.
기본 정의 파일을 .R 파일로 업로드합니다. 기본 정의 파일은 작업의 애플리케이션 논리를 포함하고 Spark 작업을 실행해야 하는 파일입니다. 각 Spark 작업 정의에 대해 하나의 기본 정의 파일만 업로드할 수 있습니다.
참조 파일을 .R 파일로 업로드합니다. 참조 파일은 기본 정의 파일에서 참조/가져오는 파일입니다.
필요한 경우 작업에 대한 명령줄 인수를 제공합니다.
작업에 레이크하우스 참조를 추가합니다. 작업에 하나 이상의 레이크하우스 참조가 추가되어야 합니다. 이 레이크하우스는 작업에 대한 기본 레이크하우스 컨텍스트입니다.
참고 항목
Spark 작업 정의는 현재 작업 영역에서 생성됩니다.
Spark 작업 정의를 사용자 지정하는 옵션
Spark 작업 정의 실행을 추가로 사용자 지정하는 몇 가지 옵션이 있습니다.
- Spark 컴퓨팅: Spark 컴퓨팅 탭 내에서 작업을 실행하는 데 사용할 Spark 버전인 런타임 버전을 볼 수 있습니다. 작업을 실행하는 데 사용할 Spark 구성 설정을 볼 수도 있습니다. 추가 버튼을 클릭하여 Spark 구성 설정을 사용자 지정할 수 있습니다.
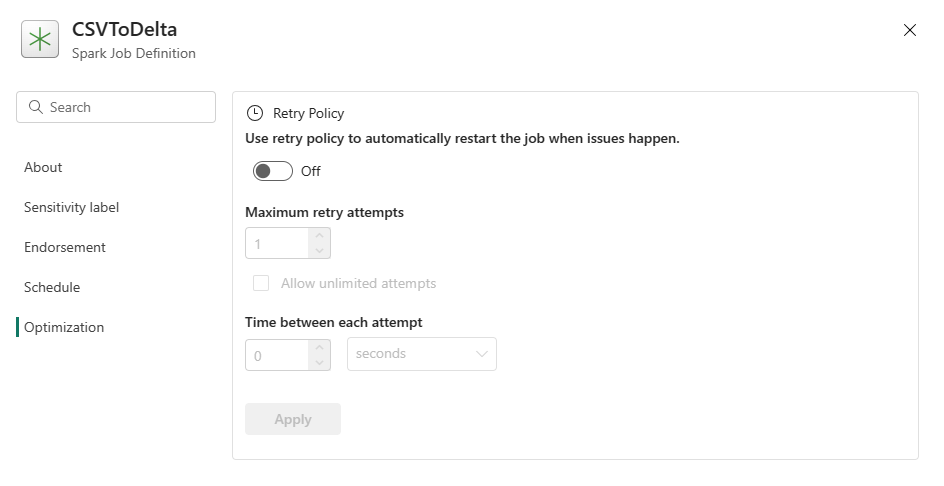
최적화: 최적화 탭에서 작업에 대한 재시도 정책을 사용하도록 설정하고 설정을 지정할 수 있습니다. 사용하도록 설정하면 작업이 실패할 경우 다시 시도됩니다. 최대 재시도 횟수와 재시도 간격을 설정할 수도 있습니다. 다시 시도할 때마다 작업이 다시 시작됩니다. 작업이 idempotent인지 확인합니다.