Windows ディスプレイ ドライバー モデル (WDDM) の操作フロー
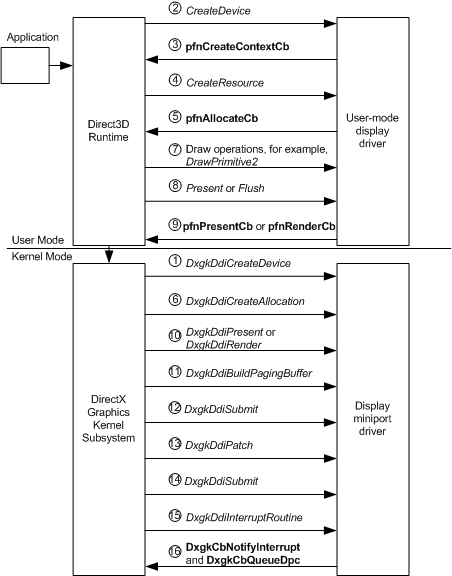
次の図は、レンダリング デバイスが作成されてからコンテンツがディスプレイに表示されるまでの WDDM 操作のフローを示しています。 この図の後で、順序付きの操作フロー シーケンスについて詳しく説明します。
レンダリング デバイスの作成
アプリケーションがレンダリング デバイスの作成を要求した後:
1: DirectX グラフィックス カーネル サブシステム (Dxgkrnl) は、カーネル モード ディスプレイ ミニポート ドライバー (KMD) DxgkDdiCreateDevice 関数を呼び出します。
KMD が、情報入力済みの DXGK_DEVICEINFO 構造体へのポインターを DXGKARG_CREATEDEVICE 構造体の pInfo メンバーに入れて返すことにより、ダイレクト メモリ アクセス (DMA) を初期化します。
2: DxgkDdiCreateDevice への呼び出しが成功すると、Direct3D ランタイムはユーザー モード ディスプレイ ドライバー (UMD) の CreateDevice 関数を呼び出します。
3: CreateDevice 呼び出しで、UMD は明示的にランタイムの pfnCreateContextCb 関数を呼び出して 1 つ以上の GPU コンテキスト (新しく作成されたデバイスで実行される GPU スレッド) を作成する必要があります。 ランタイムが、D3DDDICB_CREATECONTEXT の pCommandBuffer メンバーと CommandBufferSize メンバーに情報を入れて UMD に返し、コマンド バッファーを初期化します。
デバイスのサーフェスの作成
アプリケーションがレンダリング デバイスのサーフェスの作成を要求した後:
4: Direct3D ランタイムが、UMD の CreateResource 関数を呼び出します。
5: CreateResource が、ランタイム付属の pfnAllocateCb 関数を呼び出します。
6: ランタイムが、作成する割り当ての数と種類を指定して KMD の DxgkDdiCreateAllocation 関数を呼び出します。 DxgkDdiCreateAllocation が、割り当てに関する情報を DXGK_ALLOCATIONINFO 構造体の配列に入れて、DXGKARG_CREATEALLOCATION 構造体の pAllocationInfo メンバーで返します。
カーネル モードへのコマンド バッファーの送信
アプリケーションがサーフェスへの描画を要求した後:
7: Direct3D ランタイムが、描画操作に関連した UMD 関数を呼び出します (DrawPrimitive2 など)。
8: Direct3D ランタイムが、UMD の Present 関数または Flush 関数を呼び出して、コマンド バッファーをカーネル モードに送信します。 注: コマンド バッファーがいっぱいになった場合も、UMD はコマンド バッファーを送信します。
9: ステップ 8 への応答として、UMD が次のいずれかのランタイム付属関数を呼び出します。
- ランタイムの pfnPresentCb 関数 (Present が呼び出された場合)。
- ランタイムの pfnRenderCb 関数 (Flush が呼び出された、またはコマンド バッファーがいっぱいの場合)。
10: KMD の DxgkDdiPresent 関数 (pfnPresentCb が呼び出された場合) か、または DxgkDdiRender 関数か DxgkDdiRenderKm 関数 ( pfnRenderCb が呼び出された場合) が呼び出されます。 KMD が、コマンド バッファーを検証し、ハードウェアの形式で DMA バッファーに書き込み、使用するサーフェスを表す割り当てリストを生成します。
DMA バッファーをハードウェアに送信する
11: Dxgkrnl が、KMD の DxgkDdiBuildPagingBuffer 関数を呼び出して、GPU のアクセス可能なメモリとの間で、割り当てリストに指定された割り当てを移動するための特殊目的用の DMA バッファーを作成します。 これらの特殊な DMA バッファーはページング バッファーと呼ばれます。 DxgkDdiBuildPagingBuffer は、フレームごとに呼び出されるわけではありません。
12: Dxgkrnl が、KMD の DxgkDdiSubmitCommand 関数を呼び出して、ページング バッファーを GPU 実行ユニットのキューに入れます。
13: Dxgkrnl が、KMD の DxgkDdiPatch 関数を呼び出して、DMA バッファー内のリソースに物理アドレスを割り当てます。
14: Dxgkrnl が、KMD の DxgkDdiSubmitCommand 関数を呼び出して、DMA バッファーを GPU 実行ユニットのキューに入れます。 GPU に送信される各 DMA バッファーには、フェンス識別子 (数値) が含まれています。 GPU が DMA バッファーの処理を完了すると、GPU によって割り込みが生成されます。
15: KMD に対して DxgkDdiInterruptRoutine 関数への割り込みが通知されます。 KMD は、GPU から、完了した DMA バッファーのフェンス識別子を読み取る必要があります。
16: KMD は、
DxgkCbNotifyInterrupt