Power BI の DirectQuery
Power BI Desktop または Power BI サービスでは、多くの異なるデータ ソースにさまざまな方法で接続できます。 Power BI にデータを "インポートする" こともできます。これは、データを取得する最も一般的な方法です。 また、元のソース リポジトリ内のデータに直接接続することもでき、これは DirectQuery と呼ばれます。 この記事では、主に、DirectQuery の機能について説明します。
この記事では、次の内容について説明します。
- Power BI のさまざまなデータ接続オプション。
- インポートではなく DirectQuery を使用すべき場合に関するガイダンス。
- DirectQuery を使用する場合の制限事項と影響。
- DirectQuery を問題なく使用するための推奨事項。
- DirectQuery のパフォーマンスに関する問題を診断する方法。
この記事の中心となるのは Power BI Desktop でレポートを作成する場合の DirectQuery ワークフローですが、Power BI サービスでの DirectQuery を介した接続についても説明します。
注意
DirectQuery は、SQL Server Analysis Services の機能でもあります。 その機能の詳細の多くは Power BI での DirectQuery と共通していますが、重要な違いもあります。 この記事では主に Power BI での DirectQuery について説明し、SQL Server Analysis Services については説明しません。
SQL Server Analysis Services で DirectQuery を使用する方法の詳細については、「Power BI Desktop で複合モデルを使用する」を参照してください。 また、PDF の『SQL Server 2016 Analysis Services での DirectQuery』をダウンロードすることもできます。
Power BI のデータ接続モード
Power BI は、次のような多様なデータ ソースに接続します。
- Salesforce や Dynamics 365 などのオンライン サービス。
- SQL Server、Access、Amazon Redshift などのデータベース。
- Excel、JSON、他の形式の単純なファイル。
- Spark、Web サイト、Microsoft Exchange などのその他のデータ ソース。
これらのソースから Power BI にデータをインポートできます。 一部のソースについては、DirectQuery を使って接続することもできます。 DirectQuery をサポートするソースの概要については、「Power BI のデータ ソース」を参照してください。 DirectQuery 対応ソースは、主に、対話型クエリでよいパフォーマンスを提供できるソースです。
可能な場合は常に、Power BI にデータをインポートする必要があります。 インポートでは、Power BI のハイ パフォーマンスを誇るクエリ エンジンを活用することで、高い対話性とあらゆる機能を備えたエクスペリエンスを実現できます。
頻繁に変更されるデータの最新の状態をレポートに反映する必要がある場合のように、データのインポートでは目標を達成できない場合は、DirectQuery の使用を検討します。 DirectQuery が適しているのは、基になるデータ ソースが、一般的な集計クエリについて対話型のクエリ結果を 5 秒未満で提供でき、生成されるクエリの負荷を処理できる場合のみです。 DirectQuery を使用する場合の制限事項と影響を慎重に検討してください。
Power BI のインポートと DirectQuery の機能は、徐々に進化しています。 インポートされたデータを使うときの柔軟性を高める変更により、いっそう頻繁にインポートできるようになり、DirectQuery を使用するときのいくつかの欠点がなくなります。 機能が向上しても、基になるデータ ソースのパフォーマンスは、DirectQuery を使うときの大きな考慮事項です。 基になるデータ ソースが遅い場合、そのソースで DirectQuery を使うことはやはりできません。
以下のセクションでは、これらの 3 つのデータ接続オプション (インポート、DirectQuery、ライブ接続) について説明します。 この記事の残りの部分では、DirectQuery に焦点を当てます。
インポートの接続
SQL Server などのデータ ソースに接続し、Power BI Desktop でデータをインポートする場合には、次の接続条件があります。
最初に[データの取得] を使用するときに、選んだテーブルの各セットによって、一連のデータを返すクエリが定義されます。 データを読み込む前に、それらのクエリを編集できます (フィルターの適用、データの集計、異なるテーブルの結合など)。
読み込みでは、クエリによって定義されているすべてのデータが Power BI のキャッシュにインポートされます。
Power BI Desktop 内に視覚エフェクトを作成すると、キャッシュされたデータのクエリが実行されます。 Power BI ストアにより、高速なクエリが行われ、視覚エフェクトに対するすべての変更がすぐに反映されます。
データ ストア内の基になるデータに対する変更は、視覚エフェクトに反映されません。 データを最新の情報に更新するには、再度インポートする必要があります。
レポートを .pbix ファイルとして Power BI サービスに発行すると、インポートされたデータを含むセマンティック モデルが作成されてアップロードされます。 その後、データ更新のスケジュールを設定できます (たとえば、データを毎日再インポートします)。 元のデータ ソースの場所によっては、最新の情報に更新するためにオンプレミス データ ゲートウェイの構成が必要になる場合があります。
Power BI サービスで既存のレポートを開くか、新しいレポートを作成すると、インポートされたデータのクエリが再び行われて、対話性が保証されます。
視覚エフェクトまたはレポート ページ全体を Power BI サービスのダッシュボード タイルとしてピン留めできます。 基になるセマンティック モデルが更新されるたびに、タイルは自動的に更新されます。
DirectQuery の接続
Power BI Desktopで DirectQuery を使用してデータ ソースに接続する場合には、次の接続条件があります。
[データの取得] を使ってソースを選びます。 リレーショナル ソースの場合は、一連のデータを論理的に返すクエリが定義されているテーブルのセットを選ぶこともできます。 SAP Business Warehouse (SAP BW) のような多次元ソースの場合は、ソースのみを選びます。
読み込みの時点では、データは Power BI ストアにインポートされません。 そうではなく、視覚エフェクトを作成した時点で、Power BI Desktop によって基になるデータ ソースにクエリが送信されて、必要なデータが取得されます。 ビジュアルの更新にかかる時間は、基になるデータ ソースのパフォーマンスによって異なります。
基のデータに対する変更が、既存の視覚エフェクトにすぐに反映されることはありません。 引き続き更新する必要があります。 Power BI Desktop は、各視覚エフェクトに必要なクエリを送信し直し、必要に応じて視覚エフェクトを更新します。
レポートを Power BI サービスに発行すると、インポートの場合と同じようにセマンティック モデルが作成されてアップロードされます。 ただし、そのセマンティック モデルにはデータがありません。
Power BI サービスで既存のレポートを開くか、新しいレポートを作成すると、基になるデータ ソースのクエリが実行されて、必要なデータが取得されます。 元のデータ ソースの場所によっては、データを取得するためにオンプレミス データ ゲートウェイの構成が必要になる場合があります。
視覚エフェクトまたはレポート ページ全体を、ダッシュボード タイルとしてピン留めできます。 ダッシュボードがすばやく開くよう、タイルはスケジュール (たとえば、1 時間ごと) に従って自動的に更新されます。 データの変更頻度と、最新データを表示する重要性に応じて、更新頻度を制御できます。
ダッシュボードを開くと、タイルに反映されるのは最終更新時のデータであり、必ずしも基になるソースに対して行われた最新の変更ではありません。 開いているダッシュボードを最新の情報に更新することで、最新の状態にできます。
ライブ接続
SQL Server Analysis Services に接続するときに、データをインポートするか、または "ライブ接続" を使ってデータ モデルを選ぶかを選択できます。 ライブ接続を使用することは、DirectQuery に似ています。 データはインポートされず、基になるデータ ソースのクエリを実行して視覚エフェクトが更新されます。
たとえば、インポートを使って SQL Server Analysis Services に接続する場合は、外部の SQL Server Analysis Services ソースに対するクエリを定義して、データをインポートします。 ライブ接続する場合、ユーザーはクエリを定義せず、外部モデル全体がフィールド リストに表示されます。
この状況は、データをインポートするオプションがないことを除けば、次のソースに接続するときも当てはまります。
Power BI セマンティック モデル (たとえば、新しいレポートを作成するため、サービスに既に発行されている Power BI セマンティック モデルに接続する場合)。
Microsoft Dataverse。
ライブ接続を使う SQL Server Analysis Services レポートを発行する場合、Power BI サービスでの動作は、次の点で DirectQuery レポートに似ています。
Power BI サービスで既存のレポートを開くか、新しいレポートを作成すると、基になる SQL Server Analysis Services ソースのクエリが実行され、オンプレミス データ ゲートウェイが必要な場合があります。
ダッシュボードのタイルは、スケジュール (たとえば、1 時間ごと) に従って自動的に更新されます。
ライブ接続には、DirectQuery と異なる点もいくつかあります。 たとえば、ライブ接続では、レポートを開いているユーザーの ID が、基になる SQL Server Analysis Services ソースに常に渡されます。
DirectQuery のユース ケース
DirectQuery での接続は、次のシナリオで役に立ちます。 これらのケースの一部では、データを元のソースの場所に残しておくことが、必要または有益な場合があります。
Power BI の DirectQuery には、次のシナリオで大きな利点があります。
- データが頻繁に変更され、凖リアルタイムでのレポートが必要です。
- 事前に集計する必要なしに、大きなデータを処理する必要があります。
- 基になるソースでセキュリティ規則を定義して適用します。
- データ主権の制限が適用される。
- ソースが、SAP BW など、メジャーを含む多次元ソースである。
データが頻繁に変更され、凖リアルタイムでのレポートが必要である
インポートされたデータを使用するモデルは、1 時間に最大で 1 回更新できます。Power BI Pro または Power BI Premium サブスクリプションでは、さらに頻繁に更新されます。 データが継続的に変更されていて、レポートで最新データを表示する必要がある場合、インポートとスケジュールされた更新を使うと、ニーズが満たされない可能性があります。 Power BI にデータを直接ストリーミングできますが、この場合はサポートされるデータ量に制限があります。
DirectQuery を使うと、レポートまたはダッシュボードを開くか更新したときに、ソースの最新データが常に表示されます。 また、ダッシュボードのタイルの更新をさらに頻繁に行うこともできます (最高で 15 分ごと)。
データが非常に大きい
データが非常に大きい場合、すべてのデータをインポートすることは不可能です。 DirectQuery を使うと、データの場所でクエリが行われるので、大量のデータ転送は必要ありません。 ただし、データの量が多いと、基になるソースに対するクエリのパフォーマンスが遅くなりすぎる可能性もあります。
常にすべての詳細データをインポートする必要はありません。 Power Query エディターを使うと、インポートの間のデータの事前集計が簡単になります。 技術的には、視覚エフェクトごとに必要な集計データだけをインポートできます。 大量のデータに対する最も簡単なアプローチは DirectQuery ですが、基になるソースが DirectQuery には遅すぎる場合は、集計データのインポートが解決策になる可能性があります。
これらの詳細は、Power BI だけを使う場合に関連します。 大規模なモデルを Power BI で使用する方法の詳細については、「Power BI Premium での大規模なセマンティック モデル」を参照してください。 データを更新できる頻度に制限はありません。
基になるソースでセキュリティ規則を定義する
データをインポートするとき、Power BI は、Power BI Desktop から現在のユーザーの資格情報を使うか、または Power BI サービスからスケジュールされた更新で構成されている資格情報を使って、データ ソースに接続します。 インポートされたデータのあるレポートの発行および共有では、データの表示を許可されているユーザーとだけ共有するか、またはセマンティック モデルの一部として行レベル セキュリティを定義する必要があります。
DirectQuery を使うと、レポート閲覧者の資格情報が基になるソースに渡されて、セキュリティ規則が適用されます。 DirectQuery では、Azure SQL データ ソースへのシングル サインオン (SSO) と、データ ゲートウェイを介したオンプレミスの SQL サーバーへの SSO がサポートされています。 詳しくは、「Power BI のオンプレミスのデータ ゲートウェイ用シングル サインオン (SSO) の概要」を参照してください。
データ主権の制限が適用される
組織によっては、データ主権に関するポリシーが設けられている場合あります。つまり、データを組織外に持ち出すことができません。 このようなデータは、データのインポートに基づくソリューションで問題になります。 DirectQuery では、データは基になるソースの場所に留まっています。 ただし、DirectQuery でも、タイルのスケジュールされた更新のため、視覚エフェクト レベルで若干のデータのキャッシュが Power BI サービスによって保持されます。
基になるデータ ソースでメジャーが使用されている
SAP HANA や SAP BW などの基になるデータ ソースに、"メジャー" が含まれています。 メジャーは、インポートされるデータが、クエリで定義されている特定の集計レベルに既になっていることを意味します。 Year 別の TotalSales のように、より高いレベルで集計されたデータが必要な視覚エフェクトでは、集計値がさらに集計されます。 この集計は、Sum や Min のような加法メジャーの場合は問題ありませんが、Average や DistinctCount などの非加法メジャーでは問題になる場合があります。
DirectQuery のように、視覚エフェクトに必要な適切な集計データをソースから直接取得するには、視覚エフェクトごとにクエリを送信する必要があります。 SAP BW に接続するときに、DirectQuery を選ぶことで、このようなメジャーの処理に対応できます。 詳しくは、DirectQuery と SAP BW に関する記事をご覧ください。
現在、SAP HANA に対する DirectQuery では、データはリレーショナル ソースと同じように処理され、インポートと同様の動作になります。 詳しくは、DirectQuery と SAP HANA に関する記事をご覧ください。
DirectQuery に関する制限
DirectQuery を使うと、悪い影響が発生する可能性があります。 これらの制限の一部は、使用する正確なソースによって若干異なります。 以下のセクションでは、DirectQuery の使用に関する一般的な影響と、パフォーマンス、セキュリティ、変換、モデリング、レポートに関連する制限について説明します。
一般的な影響
DirectQuery の使用に関する一般的な影響と制限は次のとおりです。
データが変化した場合、最新のデータを表示するには最新の情報に更新する必要があります。 キャッシュを使っている場合、視覚エフェクトに常に最新データが表示される保証はありません。 たとえば、視覚エフェクトに前日のトランザクションが表示される可能性があります。 スライサーを変更して視覚エフェクトを更新すると、最近新しく到着したトランザクションを含む過去 2 日間のトランザクションが表示されることがあります。 しかし、スライサーを元の値に戻すと、キャッシュされている以前の値が再び表示される場合があります。 [最新の情報に更新] を選ぶと、すべてのキャッシュがクリアされ、ページ上のすべての視覚エフェクトが更新されて最新のデータが表示されます。
データが変化する場合、視覚エフェクト間の一貫性は保証されません。 異なる視覚エフェクトは、同じページ上でも別のページ上でも、異なるタイミングで更新される可能性があります。 基になるソースのデータが変化している場合、各視覚エフェクトに同じ時点のデータが表示される保証はありません。
たとえば詳細と合計を取得する場合のように、1 つの視覚エフェクトに対して複数のクエリが必要な場合は、1 つの視覚エフェクト内であっても整合性は保証されません。 この一貫性を保証するには、いずれかの視覚エフェクトが更新されたら常にすべての視覚エフェクトを更新するオーバーヘッドと、基になるデータ ソースでのスナップショット分離のようなコストの高い機能の使用が必要になります。
[最新の情報に更新] を選んでてページ上のすべての視覚エフェクトを更新することで、この問題を大幅に軽減できます。 インポート モードでも、複数のテーブルからデータをインポートする場合は、整合性の維持に関して同様の問題があります。
Power BI Desktop で最新の情報に更新して、スキーマの変更を反映する必要があります。 レポートを発行した後は、Power BI サービスで最新の情報に更新して、レポート内の視覚エフェクトを更新します。 ただし、基になるソース スキーマが変更された場合、Power BI サービスでは使用可能なフィールド リストは自動的に更新されません。 基になるソースからテーブルまたは列が削除された場合、更新時にクエリが失敗する可能性があります。 モデル内のフィールドを更新して変更を反映するには、Power BI Desktop でレポートを開き、[最新の情報に更新] を選ぶ必要があります。
すべてのクエリで、返すことができる行が 100 万行に制限されます。 基になるソースの 1 回のクエリで返すことができる行数には、100 万行という固定の制限があります。 一般に、この制限による実際的な影響はなく、視覚エフェクトにそれほど多くのポイントが表示されることはありません。 ただし、Power BI で送信されるクエリが完全に最適化されておらず、制限を超える中間結果が要求される場合、この制限が発生する可能性があります。
また、視覚エフェクトの作成中に、より適切な最終状態への過程でも、この制限が発生することがあります。 たとえば、顧客が 100 万を超える場合、Customer や TotalSalesQuantity を含めると、フィルターを適用するまで、この制限に達する可能性があります。 "外部データ ソースに対するクエリの結果セットが、許可されている最大サイズの '1000000' 行を超えています" というエラーが返されます。
注意
Premium 容量では、100 万行の制限を超えることができます。 詳細については、「中間行セットの最大数」を参照してください。
インポートから DirectQuery モードにモデルを変更することは変更できません。 必要なデータをすべてインポートする場合は、モデルを DirectQuery モードからインポート モードに切り替えます。 主に、DirectQuery モードでサポートされていない機能セットのため、DirectQuery モードに切り替えることはできません。 SAP BW などの多次元ソースの場合は、外部メジャーの処理が異なるため、DirectQuery からインポート モードに切り替えることはできません。
パフォーマンスと負荷の影響
DirectQuery を使うときの全体的なエクスペリエンスは、基になるデータ ソースのパフォーマンスに依存します。 たとえばスライサーの値を変更した後など、各視覚エフェクトの更新にかかる時間が 5 秒未満であれば、エクスペリエンスはそれほど悪くありませんが、インポートされたデータでの即時応答と比べると遅く感じられるでしょう。 ソースの遅さが原因で、個々の視覚エフェクトの更新に数十秒より長くかかると、エクスペリエンスは許容できないほど悪くなります。 クエリがタイムアウトする場合もあります。
基になるソースのパフォーマンスと共に、ソースにかかる負荷もパフォーマンスに影響します。 共有レポートを開く各ユーザー、および更新される各ダッシュボード タイルからは、視覚エフェクトあたり少なくとも 1 つのクエリが基になるソースに送信されます。 ソースは、適切なパフォーマンスを維持しながら、そのようなクエリの負荷を処理できる必要があります。
セキュリティへの影響
基になるデータ ソースで SSO が使われていない限り、Power BI サービスに発行された DirectQuery レポートは、常に同じ固定資格情報を使ってソースに接続します。 DirectQuery レポートを発行した直後に、使用するユーザーの資格情報を構成する必要があります。 資格情報を構成するまで、Power BI サービスでレポートを開こうとするとエラーになります。
ユーザーの資格情報を指定すると、Power BI は、インポートされたデータと同じように、レポートを開くすべてのユーザーに対してそれらの資格情報を使います。 レポートの一部として行レベルのセキュリティが定義されていない限り、すべてのユーザーに同じデータが表示されます。 基になるソースでセキュリティ規則が定義されている場合でも、レポートの共有にはインポートされるデータの場合と同じ注意を払う必要があります。
DirectQuery モードで Power BI セマンティック モデルと Analysis Services に接続すると、常に SSO が使われるため、セキュリティは Analysis Services へのライブ接続と同様になります。
Power BI Desktop から SQL Server に DirectQuery 接続する場合、代替資格情報はサポートされません。 現在の Windows 資格情報またはデータベースの資格情報を使用できます。
複合モデルを使うことにより、複数のデータ ソースを DirectQuery モデルで使用できます。 複数のデータ ソースを使うときは、基になるデータ ソースの間でデータがやり取りされる方法によるセキュリティへの影響を理解することが重要です。
データ変換の制限
DirectQuery では、Power Query エディター内で適用できるデータ変換が制限されます。 インポートされたデータでは、データを使って視覚エフェクトを作成する前に、高度な一連の変換を簡単に適用して、データのクリーンアップと再整形を行うことができます。 たとえば、JSON ドキュメントを解析したり、列から行フォームにデータをピボットしたりできます。 これらの変換は DirectQuery ではさらに制限されます。
SAP BW のようなオンライン分析処理 (OLAP) ソースに接続する場合は、変換を定義できず、外部モデル全体がソースから取得されます。 SQL Server のようなリレーショナル ソースの場合は、クエリごとに変換のセットを定義できますが、パフォーマンス上の理由からそれらの変換は制限されます。
すべての変換は、データの更新時に 1 回ではなく、基になるソースに対するすべてのクエリで適用する必要があります。 変換は、1 つのネイティブ クエリに無理なく変換できる必要があります。 複雑すぎる変換を使った場合、変換を削除するか、接続モデルをインポートに切り替える必要があることを示すエラーが発生します。
また、[データの取得] ダイアログまたは Power Query エディターでは、視覚エフェクトのデータを取得するためにそれらによって生成されて送信されるクエリ内で、サブセレクトが使われます。 このコンテキスト内で有効なクエリを Power Query エディターで定義する必要があります。 具体的には、共通テーブル式を含むクエリや、ストアド プロシージャを呼び出すクエリを使うことはできません。
モデリングの制限事項
このコンテキストでの "モデリング" という用語は、データを使ってレポートを作成する一環として、生データの調整やエンリッチを行うことを意味します。 モデリングの例を次に示します。
- テーブル間のリレーションシップの定義。
- 新しい計算の追加 (計算列やメジャーなど)。
- 列やメジャーの名前変更や非表示化。
- 階層の定義。
- 列の書式、既定の要約、並べ替え順序の定義。
- 値のグループ化またはクラスター化。
DirectQuery を使用するときも、これらのモデル エンリッチメントの多くを行い、生データのエンリッチの原則を使って、後でいっそう使いやすくできます。 ただし、DirectQuery では、使用できない、または制限されるモデリング機能がいくつかあります。 制限は、パフォーマンスの問題を回避するために適用されます。
次の制限は、すべての DirectQuery ソースに共通です。 個々のソースには、さらに多くの制限が適用される場合があります。
組み込みの日付階層がない: インポートされたデータでは、日付と日時のすべての列で、組み込みの日付階層も既定で使用できます。 たとえば、OrderDate 列を含む販売注文のテーブルをインポートし、視覚エフェクトで OrderDate を使う場合は、年、月、日など、使用する適切な日付レベルを選択できます。 DirectQuery では、この組み込み日付階層は使用できません。 多くのデータ ウェアハウスで一般的であるように、基になるソースで Date テーブルを利用できる場合は、Data Analysis Expressions (DAX) のタイム インテリジェンス関数を普通に使用できます。
日付と時刻のサポートは秒レベルまでのみ: 時刻列を使うセマンティック モデルの場合、Power BI が基になる DirectQuery ソースに対して発行するクエリの詳細レベルは、ミリ秒ではなく、秒単位までのみです。 ソース列からミリ秒のデータが削除されます。
計算列での制限: 計算列は、集計関数を使わずに行内でのみ可能です。つまり、同じテーブルの他の列の値だけを参照できます。 また、許可される DAX スカラー関数 (
LEFT()など) は、基になるソースにプッシュできる関数に限定されます。 その関数は、ソースの正確な機能によって異なります。 計算列の DAX クエリを作成するとき、サポートされない関数はオートコンプリートの一覧に表示されず、使うとエラーが発生します。親子 DAX 関数がサポートされない: DirectQuery モードでは、アカウントのチャートや従業員の階層など、親子構造を普通処理する
DAX PATH()関数ファミリを使うことはできません。クラスタリングがない: DirectQuery を使うときは、自動的にグループを見つけるためにクラスタリング機能を使うことはできません。
レポート作成の制限事項
ほとんどすべてのレポート機能は、DirectQuery モデルでもサポートされます。 基になるソースで適切なレベルのパフォーマンスが提供される限り、インポートされるデータの場合と同じ視覚エフェクトのセットを使用できます。
一般的な制限の 1 つは、DirectQuery のセマンティック モデルでは、テキスト列のデータの最大長が 32,764 文字であることです。 これより長いテキストでレポートを作成するとエラーになります。
DirectQuery ベースのレポートでは、次の Power BI レポート機能を使うとパフォーマンスの問題の原因になる可能性があります。
メジャー フィルター: メジャーまたは列の集計を使う視覚エフェクトでは、それらのメジャーにフィルターが含まれることがあります。 たとえば、次のグラフには Category 別の SalesAmount が表示されますが、売上が 20M を超えるカテゴリのみです。
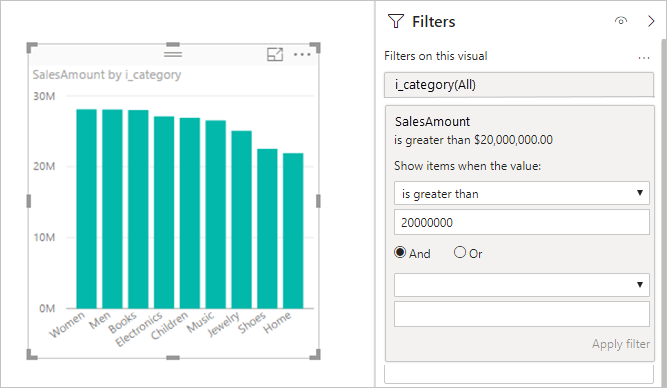
この方法を使うと、基になるソースに 2 つのクエリが送信されます。
- 1 つ目のクエリでは、SalesAmount が 2000 万より大きいという条件を満たすカテゴリが取得されます。
- 2 つ目のクエリでは、
WHEREの条件を満たしたカテゴリを含む、視覚エフェクトに必要なデータが取得されます。
この例のようにカテゴリの数が数百から数千の場合、このアプローチは一般に問題なく機能します。 カテゴリの数が多くなると、パフォーマンスが低下する可能性があります。 カテゴリの数が 100 万より多い場合、このクエリは失敗します。
TopN フィルター: 何らかのメジャーによってランク付けされた上位または下位の
N個の値のみをフィルター処理する高度なフィルターを定義できます。 たとえば、フィルターで上位 10 個のカテゴリを含めることができます。 この方法でも、基になるソースに 2 つのクエリが送信されます。 ただし、1 つ目のクエリで基になるソースからすべてのカテゴリが返された後、返された結果に基づいてTopNが決定されます。 この方法では、関係する列のカーディナリティによっては、パフォーマンスの問題が発生したり、クエリ結果に対する 100 万行の制限のためにクエリが失敗したりする可能性があります。中央値:
SumやCount Distinctなどの集計はすべて、基になるソースにプッシュされます。 ただし、通常、medianの集計は基になるソースではサポートされません。medianの場合は、詳細データが基になるソースから取得され、返された結果から中央値が計算されます。 このアプローチは、比較的少数の結果に対して中央値を計算する場合は問題ありません。100 万行の制限によりカーディナリティが大きい場合は、パフォーマンスの問題が起こるか、クエリが失敗する場合があります。 たとえば、国や地域の人口の中央値のクエリを実行すると問題がなくても、販売価格の中央値では問題になる可能性があります。
"contains" のような高度なテキスト フィルター: テキスト列の高度なフィルター処理では、
containsやbegins withなどのフィルターを使用できます。 一部のデータ ソースでは、これらのフィルターによりパフォーマンスが低下する場合があります。 特に、完全一致が必要な場合は、既定のcontainsフィルターを使わないでください。 実際のデータによっては同じ結果になるかもしれませんが、インデックスのためにパフォーマンスが大きく異なる可能性があります。複数選択スライサー: 既定では、スライサーで可能な選択は 1 つのみです。 フィルターで複数選択を許可すると、パフォーマンスの問題が発生する可能性があります。 たとえば、ユーザーが関心のある 10 製品を選んだ場合、新しい選択のたびにクエリがソースに送信されます。 クエリが完了する前にユーザーは次の項目を選択できますが、このアプローチでは基になるソース上で余分な負荷が発生します。
テーブル視覚エフェクトでの合計: 既定では、テーブルとマトリックスには合計と小計が表示されます。 多くの場合、このような合計の値を取得するには、基になるソースに別のクエリを送信する必要があります。 この要件は、
DistinctCount集計を使うとき常に、または SAP BW や SAP HANA で DirectQuery を使うすべてのケースに当てはまります。 [書式] ペインを使うことで、そのような合計をオフにできます。
DirectQuery に関する推奨事項
このセクションでは、その影響の点で、DirectQuery を問題なく使用する方法に関する概要レベルのガイダンスを提供します。
基になるデータ ソースのパフォーマンス
シンプルな視覚エフェクトが 5 秒以内に更新され、妥当な対話型エクスペリエンスを提供できることを検証します。 視覚エフェクトの更新に 30 秒より長くかかる場合、レポートの発行後にさらに問題が発生すると、ソリューションが動かなくなる可能性があります。
クエリが遅い場合は、基になるソースに送信されるクエリと、パフォーマンスが遅い理由を調べます。 詳しくは、「パフォーマンスの問題の診断」をご覧ください。
この記事では、可能性のあるすべての基になるソースを対象にした、データベースの最適化に関する広範な推奨事項については説明しません。 以下の標準的なデータベース プラクティスが、ほとんどの状況に当てはまります。
パフォーマンスを向上させるには、他のデータ型の列を結合するのではなく、整数列に基づくリレーションシップを使用します。
適切なインデックスを作成します。 インデックスの作成は、一般に、列ストア インデックスをサポートするソース (SQL Server など) でそれを使うことを意味します。
ソースで必要な統計を更新します。
モデルの設計
モデルを定義するときは、次のガイダンスに従います。
Power Query エディターで複雑なクエリを作成しないようにします。 Power Query エディターでは、複雑なクエリが単一の SQL クエリに変換されます。 そのテーブルに送信されたすべてのクエリのサブセレクトに単一のクエリが表示されます。 そのクエリが複雑な場合、送信されるクエリでパフォーマンスの問題が発生する可能性があります。 Power Query エディターの [適用したステップ] で最後のステップを右クリックし、[ネイティブ クエリを表示] を選ぶことで、一連のステップの実際の SQL クエリを取得できます。
メジャーを単純に保つ。 少なくとも最初は、メジャーを単純な集計に制限します。 メジャーが満足のいく方法で動作したら、より複雑なメジャーを定義できますが、パフォーマンスに注意してください。
計算列ではリレーションシップを使用しない。 Power BI では、複数列の結合を行う必要があるデータベースで、複数の列を主キーまたは外部キーとしてリレーションシップの基にすることはできません。 一般的な回避策は、計算列を使って列を連結し、その列を基にして結合することです。
この回避策はインポートされたデータの場合は問題ありませんが、DirectQuery の場合は、式での結合になります。 その結果、通常はインデックスを使用できず、パフォーマンスの低下につながります。 唯一の回避策は、複数の列を基になるデータ ソースの 1 つの列に実際に具体化することです。
"uniqueidentifier" の列ではリレーションシップを使用しない。 Power BI では、
uniqueidentifierデータ型はネイティブにサポートされていません。uniqueidentifier列の間にリレーションシップを定義すると、キャストを含む結合を使用するクエリになります。 このアプローチの場合も、一般にパフォーマンスの低下を招きます。 唯一の回避策は、基になるデータ ソースで代替型の列を具体化することです。リレーションシップで "to" 列を非表示にする。 リレーションシップの
to列は通常、toテーブルの主キーです。 その列を非表示にする必要がありますが、非表示にした場合、フィールド リストに表示されず、視覚エフェクトで使用できません。 多くの場合、リレーションシップの基になっている列は実際には "システム列" です (たとえば、データ ウェアハウス内の代理キー)。 その場合でも、このような列は非表示にするのが最善です。列に意味がある場合は、表示され、主キーと同等になる単純な式を持つ、計算列を導入します。次はその例です。
ProductKey_PK (Destination of a relationship, hidden) ProductKey (= [ProductKey_PK], visible) ProductName ...計算列とデータ型の変更をすべて調べる。 複合モデルで DirectQuery を使う場合は、計算テーブルを使用できます。 これらの機能は必ずしも有害であるとは限りませんが、結果のクエリには、列への単純な参照ではなく、式が含まれます。 それらのクエリでは、インデックスが使われなくなる可能性があります。
リレーションシップで双方向クロス フィルタリングを使わない。 双方向クロス フィルタリングを使うと、クエリ ステートメントのパフォーマンスが悪くなる可能性があります。 双方向クロス フィルタリングについて詳しくは、「Power BI Desktop の DirectQuery で双方向のクロス フィルタリングを有効にする」を参照するか、双方向クロス フィルタリングに関するホワイト ペーパーをダウンロードしてください。 このホワイト ペーパーの例は SQL Server Analysis Services に関するものですが、基本的なポイントは Power BI にも当てはまります。
設定 [参照整合性を想定] で実験する。 リレーションシップで [参照整合性を想定] を設定すると、
INNER JOINではなくOUTER JOINステートメントをクエリで使用できるようになります。 このガイダンスに従うと一般にクエリのパフォーマンスが向上しますが、それはデータ ソースの仕様によって異なります。Power Query エディターでは、相対データ フィルタリングの使用を避けます。 Power Query エディターでは相対データ フィルタリングを定義できます。 たとえば、日付が過去 14 日間である行にフィルター処理できます。
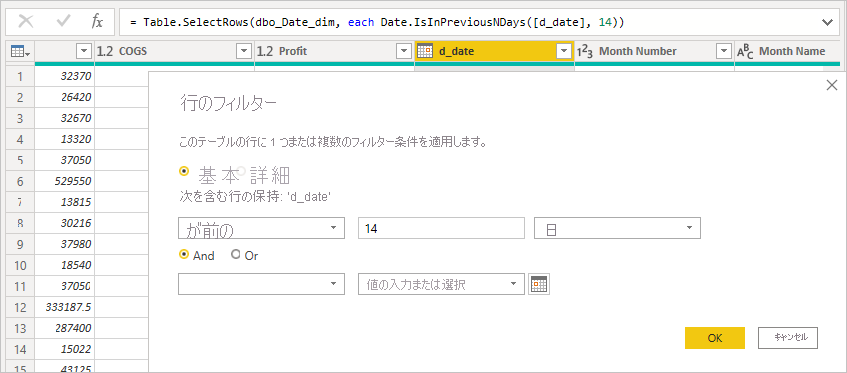
ただし、このフィルターは、ネイティブ クエリで確認できるように、クエリ作成日時のような固定日付に基づくフィルターに変換されます。

このデータは望むものではない可能性があります。 レポートが実行された日付に基づいてフィルターが適用されるようにするには、レポートで日付フィルターを適用します。
DAX DATE()関数を使って過去の日数を計算する計算列を作成し、その計算列をフィルターで使うことができます。
レポート デザイン
DirectQuery 接続を使うレポートを作成するときは、次のガイダンスに従ってください。
クエリを減らすオプションの使用を検討する: Power BI には、送信するクエリを減らしたり、結果のクエリの実行に時間がかかる場合にパフォーマンスを低下させる特定の操作を無効にしたりするレポート オプションがあります。 これらのオプションは、Power BI Desktop でレポートを操作するときに適用され、ユーザーが Power BI サービスでレポートを使うときにも適用されます。
Power BI Desktop でこのようなオプションにアクセスするには、 [ファイル]>[オプションと設定]>[オプション] の順に進み、 [クエリを減らす] を選択します。
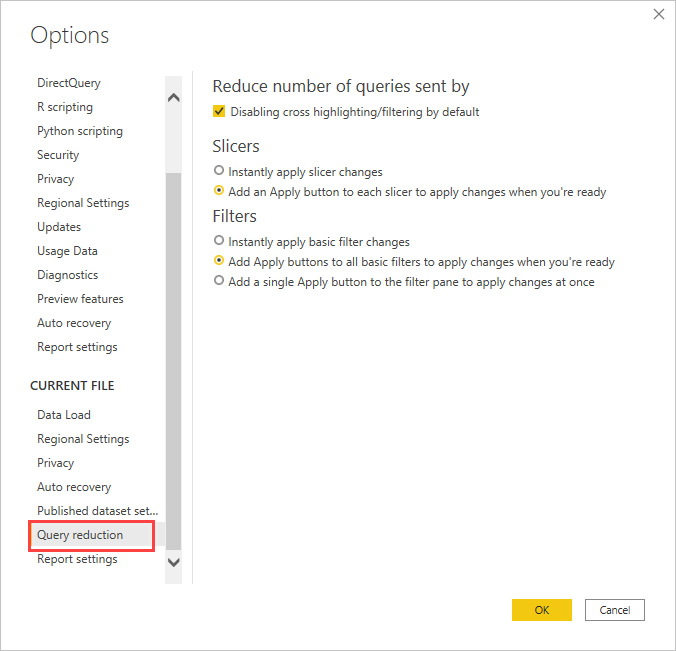
[クエリを減らす] 画面で選択すると、スライサーまたはフィルターの選択の [適用] ボタンが表示されます。 フィルターまたはスライサーの [適用] ボタンを選ぶまで、クエリは送信されません。 その後、クエリではユーザーの選択を使ってデータがフィルター処理されます。 このボタンを使うと、スライサーとフィルターを適用する前に、それらに関する複数の選択を行うことができます。
フィルターを最初に適用する: 常に、視覚エフェクト作成の最初の段階で該当するフィルターを適用します。 たとえば、TotalSalesAmount と ProductName をドラッグしてから特定の年でフィルター処理するのではなく、最初に Year でフィルターを適用します。
視覚エフェクトを作成する各ステップでは、クエリが送信されます。 最初のクエリが完了する前に別の変更を行うことができますが、この方法ではまだ、基になるソースでの不要な負荷が残ります。 早期にフィルターを適用すると、一般にそれらの中間クエリのコストが減ります。 早期にフィルターを適用しないと、100 万行の上限に達する可能性があります。
ページの視覚エフェクトの数を制限する: ページを開くか、ページ レベルのスライサーまたはフィルターを変更すると、ページ上のすべての視覚エフェクトが更新されます。 並列クエリの数には制限があります。 視覚エフェクトの数が増えると、一部の視覚エフェクトは順番に更新されるため、ページの更新にかかる時間が長くなります。 したがって、1 ページの視覚エフェクトの数を制限し、代わりに単純なページを多数作成することをお勧めします。
視覚エフェクト間の相互作用を無効にすることを検討する: 既定では、レポート ページ上の 1 つの視覚エフェクトを使って、そのページ上の他の視覚エフェクトに処理とクロス強調表示を適用できます。 たとえば、円グラフで 1999 を選択すると、縦棒グラフが 1999 のカテゴリの売上を示すようにクロス強調表示されます。
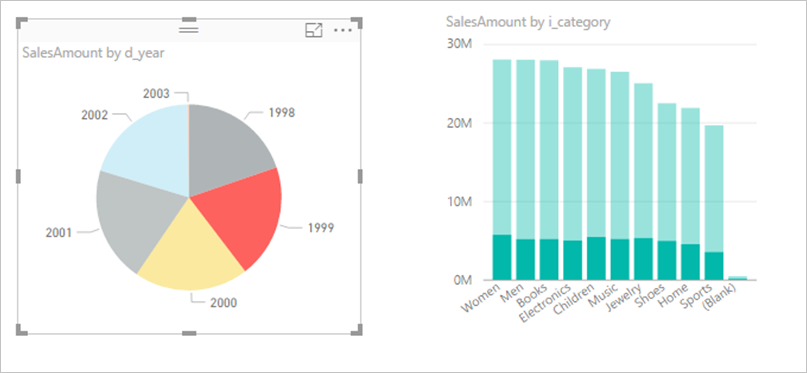
DirectQuery でのクロスフィルター処理とクロス強調表示では、基になるソースにクエリを送信する必要があります。 ユーザーの選択への応答に不当に長い時間がかかる場合は、この操作をオフにする必要があります。
[クエリを減らす] 設定を使って、レポート全体またはケースバイケースでクロス強調表示を無効にすることができます。 詳細については、「Power BI のレポート内でビジュアルがどのように相互作用するか」を参照してください。
[接続の最大数]
基になるデータ ソースごとに DirectQuery によって開かれる接続の最大数を設定できます。これにより、各データ ソースに同時に送信されるクエリ数が制御されます。
DirectQuery によって開かれるコンカレント接続の既定最大数は 10 です。 Power BI Desktop での現在のファイルの最大数を変更するには、[ファイル]>[オプションと設定]>[オプション] に移動し、左側のペインの [現在のファイル] セクションで [DirectQuery] を選びます。
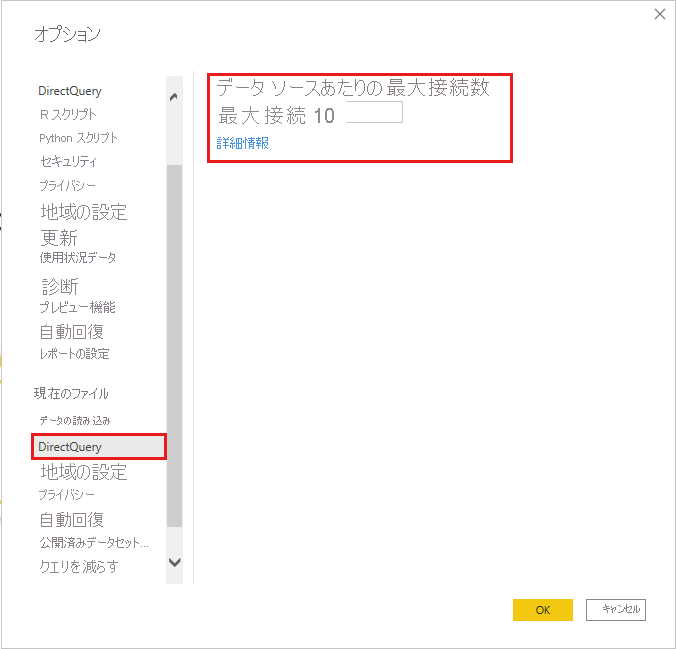
この設定は、現在のレポートに DirectQuery ソースが少なくとも 1 つあるときにのみ有効になります。 この値は、すべての DirectQuery ソースと、レポートに追加される新しい DirectQuery ソースに適用されます。
[データ ソースあたりの最大接続数] を大きくすると、基になるデータ ソースに送信されるクエリを増やすことができます (指定された最大数まで)。 このアプローチは、1 つのページ上に多くの視覚エフェクトがある場合、または多数のユーザーが同時にレポートにアクセスする場合に便利です。 接続の最大数に到達した後は、接続が利用可能になるまで、後続のクエリは待ち行列に入ります。 上限が高いほど、基になるソースでの負荷が増えるため、この設定では全体的なパフォーマンスの向上は保証されません。
レポートを Power BI サービスに発行した後では、同時実行クエリの最大数は、レポートが発行されるターゲット環境で設定されている固定制限にも依存するようになります。 Power BI、Power BI Premium、Power BI Report Server では、適用される上限が異なります。 次の表は、各 Power BI 環境のデータ ソースごとのアクティブな接続の上限を示しています。 これらの制限は、クラウドのデータ ソースとオンプレミスのデータ ソース (SQL Server、Oracle、Teradata など) に適用されます。
| Environment | データ ソースあたりの上限 |
|---|---|
| Power BI Pro | 10 アクティブ接続 |
| Power BI Premium | セマンティック モデル SKU の制限によって異なる |
| Power BI Report Server | 10 アクティブ接続 |
注意
拡張メタデータを有効にすると、DirectQuery の最大接続数の設定がすべての DirectQuery ソースに適用されます。これは、Power BI Desktop で作成されるすべてのモデルに対する既定の設定です。
Power BI サービスでの DirectQuery
すべての DirectQuery データ ソースは Power BI Desktop でサポートされており、一部のソースは Power BI サービス内から直接使うこともできます。 たとえば、ビジネス ユーザーは Power BI を使って Salesforce 内の自分のデータに接続し、Power BI Desktop を使わずにダッシュボードをすぐに取得できます。
Power BI サービスでは、次の 2 つの DirectQuery 対応ソースのみを直接使用できます。
- Spark
- Azure Synapse Analytics (旧称 SQL Data Warehouse)
これら 2 つのソースの場合でも、Power BI Desktop 内で DirectQuery を使い始めるのがやはり最善です。 Power BI サービスは、最初に接続するのは簡単ですが、結果のレポートをさらに拡張する場合に制限があります。 たとえば、サービスでは、計算を作成したり、多くの分析機能を使ったり、基になるスキーマの変更を反映するためにメタデータを更新したりすることはできません。
Power BI サービスでの DirectQuery レポートのパフォーマンスは、基になるデータ ソースでの負荷の程度によって異なります。 負荷は次に依存します。
- レポートとダッシュボードを共有するユーザーの数。
- レポートの複雑さ。
- レポートで行レベル セキュリティが定義されているかどうか。
Power BI サービスでのレポートの動作
Power BI サービスでレポートを開くと、現在表示されているページ上のすべての視覚エフェクトが更新されます。 視覚エフェクトごとに、基になるデータ ソースに対して少なくとも 1 回クエリを実行する必要があります。 視覚エフェクトによっては、複数回のクエリが必要になる場合があります。 たとえば、視覚エフェクトには、2 つの異なるファクト テーブルの集計値が表示されたり、より複雑なメジャーが含まれていたり、Count Distinct のような非加法メジャーの合計が含まれていたりする場合があります。 新しいページに移動すると、それらの視覚エフェクトが更新されます。 更新すると、新しいクエリのセットが基になるソースに送信されます。
レポートでのすべてのユーザー操作により、視覚エフェクトが更新される可能性があります。 たとえば、スライサーで別の値が選択されると、影響を受けるすべての視覚エフェクトを更新するために新しいクエリ セットを送信する必要があります。 視覚エフェクトを選んで他の視覚エフェクトをクロス強調表示したり、フィルターを変更したりする場合も同様です。 同様に、レポートの作成または編集でも、最終的な視覚エフェクトを生成するために、パスの各ステップでクエリを送信する必要があります。
結果のキャッシュがいくつかあります。 まったく同じ結果が最近取得された場合、視覚エフェクトはすぐに更新されます。 行レベル セキュリティが定義されている場合、これらのキャッシュはユーザー間で共有されません。
DirectQuery を使うと、発行されたレポートに対して Power BI サービスが提供する機能の一部に、いくつかの重要な制限が適用されます。
クイック分析情報がサポートされない: Power BI のクイック分析情報は、興味がある可能性のある情報を検出するために一連の高度なアルゴリズムを適用しながら、セマンティック モデルのさまざまなサブセットを検索します。 クイック分析情報にはハイ パフォーマンスのクエリが必要であるため、DirectQuery を使うセマンティック モデルでは、この機能は利用できません。
Excel で分析を使うとパフォーマンスが低下する:Excel で分析機能を使ってセマンティック モデルを調べることができ、Excel でピボット テーブルとピボット グラフを作成できます。 この機能は DirectQuery を使用するセマンティック モデルでサポートされていますが、パフォーマンスは Power BI でビジュアルを作成するより遅くなります。 Excel を使うことが重要なシナリオでは、DirectQuery を使うかどうかを決めるときに、この問題を考慮してください。
Excel で階層が表示されない: たとえば、Excel で分析を使うとき、DirectQuery を使用する Azure Analysis Services モデルまたは Power BI セマンティック モデルで定義されている階層は Excel に表示されません。
ダッシュボードの更新
Power BI サービスでは、個々の視覚エフェクトまたはページ全体をタイルとしてダッシュボードにピン留めできます。 DirectQuery セマンティック モデルに基づくタイルは、スケジュールに従って基になるデータ ソースにクエリを送信することで自動的に更新されます。 既定では、セマンティック モデルは 1 時間ごとに更新されますが、セマンティック モデル設定の一部として、更新スケジュールの間隔を毎週から 15 分ごとの間で構成できます。
行レベル セキュリティがモデルで定義されていない場合、各タイルは 1 回更新され、その結果がすべてのユーザー間で共有されます。 行レベル セキュリティを使っている場合は、各タイルでユーザーごとに個別のクエリを基になるソースに送信する必要があります。
大きな相乗効果が発生する可能性があります。 10 個のタイルを含み、100 人のユーザーで共有され、行レベル セキュリティが設定された DirectQuery を使うセマンティック モデルで作成されるダッシュボードでは、更新のたびに、少なくとも 1000 個のクエリが基になるソースに送信されます。 行レベル セキュリティの使用と、更新スケジュールの構成については、慎重に検討してください。
クエリのタイムアウト
Power BI サービスでは個々のクエリに 4 分のタイムアウトが適用されます。 4 分より長くかかるクエリは失敗します。 この制限は、過度に長い実行時間が原因の問題を回避するためのものです。 DirectQuery は、対話型クエリのパフォーマンスを提供できるソースにのみ使用する必要があります。
タイムアウト制限に達すると、ビジュアルの読み込みに失敗し、次のエラーが発生します:The query has exceeded the available resources. Try filtering to decrease the amount of data requested. The XML for Analysis request timed out before it was completed. Timeout value: 225 sec。
パフォーマンス診断
このセクションでは、パフォーマンスの問題を診断する方法、またはレポートを最適化するためのより詳細な情報を取得する方法について説明します。
パフォーマンスの問題の診断は、Power BI サービスではなく、Power BI Desktop で始めます。 パフォーマンスの問題は、多くの場合、基になるソースのパフォーマンスに基づいています。 Power BI Desktop 環境がより分離されているほど、いっそう簡単に問題を特定して診断できます。
このアプローチでは、Power BI ゲートウェイなどの特定のコンポーネントが最初に削除されます。 パフォーマンスの問題が Power BI Desktop では発生しない場合は、Power BI サービスでレポートの詳細を調査できます。
Power BI Desktop のパフォーマンス アナライザーは、問題を特定するための便利なツールです。 ページ上の多くの視覚エフェクトではなく、1 つの視覚エフェクトに問題を分離してみてください。 Power BI Desktop ページ上の 1 つの視覚エフェクトが遅い場合は、パフォーマンス アナライザーを使って、Power BI Desktop が基になるソースに送信するクエリを分析します。
また、一部の基になるデータ ソースが出力するトレースと診断情報を見ることもできます。 ソースからのトレースがない場合でも、トレース ファイルには、クエリの実行方法とその改善方法に関する有用な詳細が含まれている場合があります。 次のプロセスを使って、Power BI が送信するクエリとその実行時間を表示できます。
SQL Server Profiler を使用してクエリを表示する
既定では、Power BI Desktop は特定のセッションの間のイベントを FlightRecorderCurrent.trc という名前のトレース ファイルに記録します。 トレース ファイルは、AnalysisServicesWorkspaces というフォルダー内の現在のユーザーの Power BI Desktop フォルダーにあります。
一部の DirectQuery ソースでは、基になるデータ ソースに送信されたすべてのクエリがこのトレース ファイルに含まれます。 ログにクエリを送信するデータ ソースは次のとおりです。
- SQL Server
- Azure SQL データベース
- Azure Synapse Analytics (旧称 SQL Data Warehouse)
- Oracle
- Teradata
- SAP HANA
トレース ファイルは、無料でダウンロードできる SQL Server Management Studio に含まれる SQL Server Profiler を使って読むことができます。
現在のセッションのトレース ファイルを開くには:
Power BI Desktop セッションの間に、[ファイル]>[オプションと設定]>[オプション] を選んでから、[診断] を選びます。
[クラッシュ ダンプの収集] で、[クラッシュ ダンプ/トレース フォルダーを開く] を選びます。
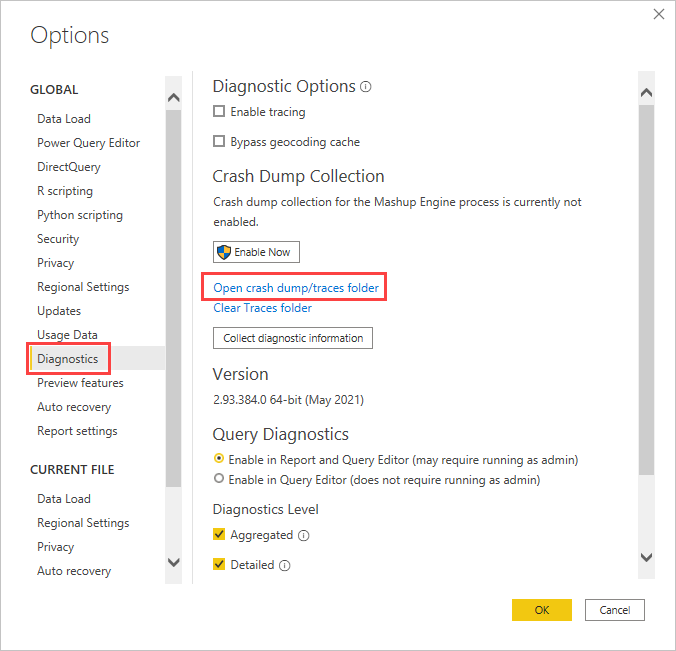
Power BI Desktop\Traces フォルダーが開きます。
親フォルダーに移動してから AnalysisServicesWorkspaces フォルダーに移動します。そこには、Power BI Desktop の開いているインスタンスごとに 1 つのワークスペース フォルダーが含まれます。 これらのフォルダーは整数のサフィックスが付いた名前になっています (例: AnalysisServicesWorkspace2058279583)。 関連付けられている Power BI Desktop セッションが終了すると、ワークスペース フォルダーは削除されます。
現在の Power BI セッションのワークスペース フォルダー内の \Data フォルダーには、FlightRecorderCurrent.trc というトレース ファイルが含まれます。 場所を記録しておきます。
SQL Server Profiler を開き、[ファイル]>[開く]>[トレース ファイル] を選びます。
現在の Power BI セッションのトレース ファイルへのパスに移動するか、パスを入力して、FlightRecorderCurrent.trc を開きます。
SQL Server Profiler に、現在のセッションからのすべてのイベントが表示されます。 次のスクリーンショットでは、クエリのイベントのグループが強調されています。 各クエリ グループには次のイベントが含まれます。
Query BeginとQuery Endイベントは、Power BI UI で視覚エフェクトまたはフィルターを変更することで、または Power Query エディターでのデータのフィルター処理または変換によって生成される、DAX クエリの開始と終了を表します。DirectQuery BeginとDirectQuery Endイベントの 1 つ以上のペアは、DAX クエリの評価の一部として基になるデータ ソースに送信されたクエリを表します。

複数の DAX クエリを並列して実行できるので、異なるグループからのイベントが混在している可能性があります。 ActivityID の値を使って、同じグループに属しているイベントを特定できます。
次の列も重要です。
- TextData: イベントのテキスト形式の詳細です。
Query BeginとQuery Endイベントの場合、詳細は DAX クエリです。DirectQuery BeginとDirectQuery Endイベントの場合、詳細は基になるソースに送信された SQL クエリです。 現在選択されているイベントの TextData も、画面の下部にあるペインに表示されます。 - EndTime: イベントが完了した時刻です。
- Duration: DAX または SQL クエリの実行にかかった時間 (ミリ秒単位)。
- Error: エラーが発生したかどうか。発生した場合は、イベントも赤で表示されます。
パフォーマンスの問題の可能性の診断に役立つトレースをキャプチャするには:
複数のワークスペース フォルダーで混乱するのを避けるために、1 つの Power BI Desktop セッションを開きます。
Power BI Desktop で関心のあるアクションのセットを実行します。 さらにアクションをいくつか実行して、目的のイベントがトレース ファイルに確実にフラッシュされるようにします。
SQL Server Profiler を開いて、トレースを調べます。 Power BI Desktop を閉じるとトレース ファイルが削除されることに注意してください。 また、Power BI Desktop でのその他のアクションはすぐに表示されません。 新しいイベントを表示するには、トレース ファイルを閉じてもう一度開く必要があります。
個々のセッションを適度な小ささ (数百秒ではなく 10 秒くらいのアクション) にします。 このアプローチを使用すると、トレースファイルをより簡単に解釈できます。 トレース ファイルのサイズにも制限があります。 長いセッションでは前の方のイベントが破棄される可能性があります。
クエリの形式を理解する
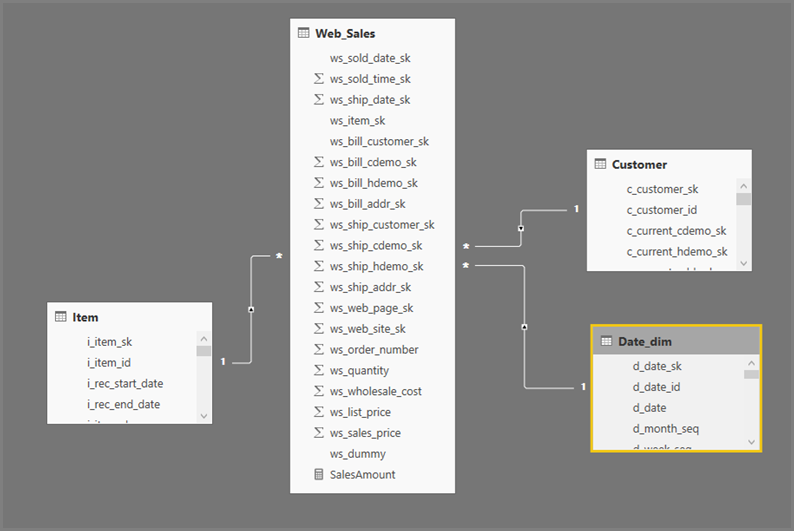
Power BI Desktop のクエリの一般的な形式では、参照するテーブルごとにサブセレクトが使われます。 Power Query エディターのクエリで、サブセレクト クエリが定義されています。 たとえば、SQL Server に次のような TPC-DS テーブルがあるとします。
次のクエリを実行します。
SalesAmount (SUMX(Web_Sales, [ws_sales_price]*[ws_quantity]))
by Item[i_category]
for Date_dim[d_year] = 2000
Power BI での結果の視覚エフェクトは次のようになります。
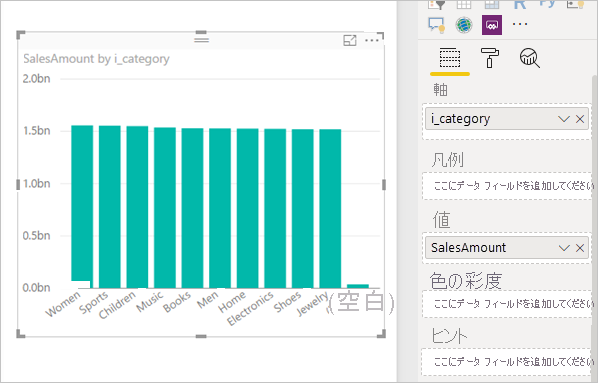
その視覚エフェクトの更新では、次の図の SQL クエリが生成されます。 Web_Sales、Item、Date_dim に関する 3 つのサブセレクト クエリがあり、視覚エフェクトで参照されている列は 4 つだけであっても、それぞれから対応するテーブルのすべての列が返されます。
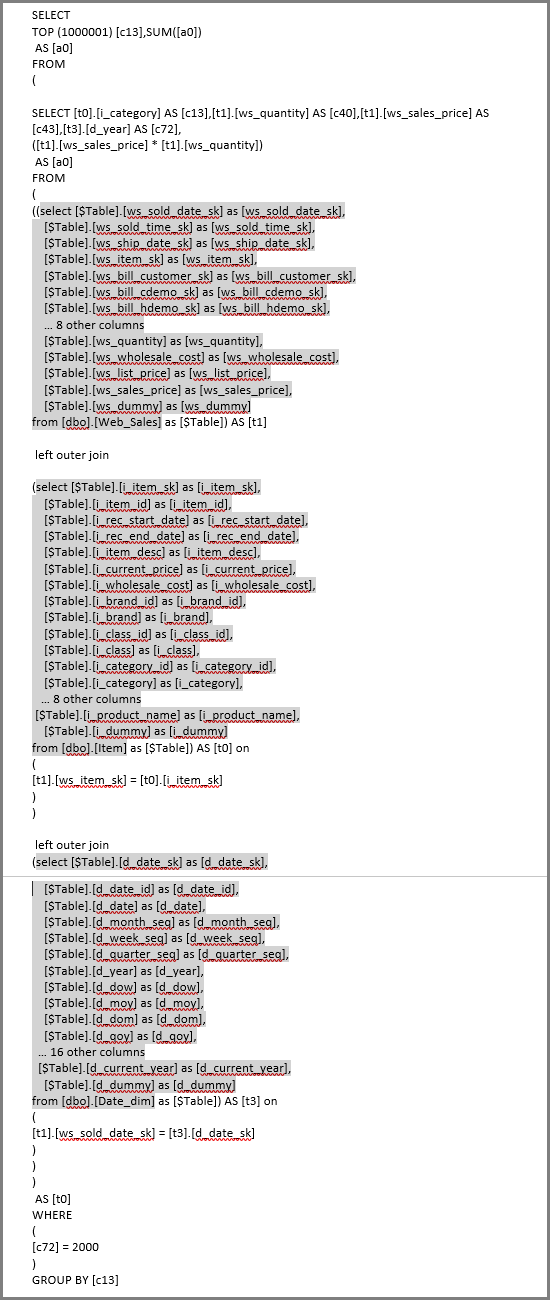
Power Query エディターでは、正確なサブセレクト クエリが定義されます。 サブセレクトをこのように使っても、DirectQuery でサポートされるデータ ソースのパフォーマンスに影響することは示されていません。 SQL Server などのデータ ソースでは、他の列への参照は最適化により除外されます。
アナリストが SQL クエリを直接指定するため、Power BI ではこのパターンが使われています。 Power BI では、指定したとおりにクエリが使われ、その書き換えは試みられません。
関連するコンテンツ
Power BI での DirectQuery について詳しくは、以下をご覧ください。
この記事では、すべてのデータ ソースに共通する DirectQuery の側面について説明しました。 特定のソースについて詳しくは、以下の記事をご覧ください。