Power BI で DirectQuery を使用して SAP HANA データ ソースに接続する
DirectQuery を使用して SAP HANA データ ソースに直接接続できます。これは、多くの場合、インポート モデルをサポートするために使用可能なリソースを超える大規模なデータセットに必要です。 DirectQuery モードで SAP HANA に接続するには、それぞれ異なる機能を備えた 2 つの方法があります。
SAP HANA を多次元ソースとして扱う (既定値): この場合の動作は、Power BI が SAP Business Warehouse や Analysis Services などの他の多次元ソースに接続する場合と似ています。 多次元ソースとして SAP HANA に接続すると、1 つの分析ビューまたは計算ビューが選択され、そのビューのすべてのメジャー、階層、属性がフィールド リストで使用できます。 セマンティック モデルでは、計算列やその他のデータのカスタマイズを追加することはできません。 ビジュアルが作成されると、集計データは SAP HANA から直接取得されます。 SAP HANA を多次元ソースとして扱うのが、SAP HANA 経由の新しい DirectQuery レポートの既定値です。
SAP HANA をリレーショナル ソースとして扱う: この場合、Power BI は SAP HANA をリレーショナル データ ソースとして扱います。 このアプローチにより、柔軟性が向上します。 特に、計算列を追加し、他のソースのデータを含めることができますが、メジャーが期待どおりに集計されるように注意する必要があります。 加算効果のない対策は避けてください。 また、パフォーマンスの問題を回避するために、列と結合が少ない単純なビューを使用してください。 セマンティック モデルで測定値を再作成することを検討しますが、複雑な測定値は折りたたまれない可能性があることに注意してください。 SAP HANA 階層は、SAP HANA をリレーショナル ソースとして使用する場合は使用できません。
接続方法はグローバル ツール オプションによって決まります。このオプションは、次の図に示すように、
![DirectQuery オプションを示す [オプション] ダイアログのスクリーンショット。](media/desktop-directquery-sap-hana/directquery-sap-hana_01a.png)
SAP HANA をリレーショナル ソースとして扱うオプションは、SAP HANA 経由の DirectQuery を使用して、新しい レポート
2 つの SAP HANA 接続方法は異なる動作を構成するため、既存のレポートを 1 つの接続方法から別の接続方法に切り替えすることはできません。
SAP HANA を多次元ソースとして扱う (既定)
SAP HANA へのすべての新しい接続では、この接続方法が既定で使用され、SAP HANA は多次元ソースとして扱われます。 多次元ソースとして SAP HANA に接続する場合は、次の考慮事項が適用されます。
データの取得ナビゲーターでは、1 つの SAP HANA ビューを選択できます。 メジャーや属性を個々に選択することはできません。 接続時に定義されたクエリはありません。これは、データのインポートや、SAP HANA をリレーショナル ソースとして扱うときに DirectQuery を使用する場合とは異なります。 この考慮事項は、この接続方法を選択するときに SAP HANA SQL クエリを直接使用できないことも意味します。
選択したビューのすべてのメジャー、階層、および属性がフィールド リストに表示されます。
ビジュアルでメジャーを使用すると、SAP HANA がクエリを実行して、ビジュアルに必要な集計レベルでメジャー値を取得します。 カウンターや比率などの非加法メジャーを処理する場合、すべての集計は SAP HANA によって実行され、Power BI ではそれ以上の集計は実行されません。
SAP HANA から正しい集計値を常に取得できるようにするには、特定の制限を課す必要があります。 たとえば、計算列を追加したり、同じレポート内の複数の SAP HANA ビューのデータを結合したりすることはできません。 列を削除したり、データ型を変更したりすることもできません。
SAP HANA を多次元ソースとして扱うと、リレーショナル アプローチの代替
フィールド リストには、SAP HANA ビューのすべてのメジャー、属性、階層が含まれます。 この接続方法を使用する場合は、次の動作が適用されることに注意してください。
少なくとも 1 つの階層に含まれる属性は、既定では非表示になります。 ただし、フィールド リストのコンテキスト メニューから [非表示 表示] を選択すると、必要に応じて表示できます。 必要に応じて、同じコンテキスト メニューから表示できます。
SAP HANA では、別の属性をラベルとして使用するように属性を定義できます。 たとえば、Product (値は
1、2、3など) は、ProductName (値はBike、Shirt、Glovesなど) をそのラベルとして使用できます。 この場合、フィールド リストには Product の 1 つのフィールドが表示され、その値はラベルBike、Shirt、Glovesなどですが、キー値1、2、3によって並べ替えられ、一意性が決定されます。 Product.Key非表示列も作成され、必要に応じて基になるキー値にアクセスできます。
基になる SAP HANA ビューで定義されている変数は接続時に表示され、必要な値を入力できます。 これらの値は、後でリボンから [データ
許可されるモデリング操作は、SAP HANA から正しい集計データを常に取得できるようにする必要がある場合に、DirectQuery を使用する場合の一般的なケースよりも制限が厳しくなっています。 ただし、指標の定義、フィールドの名前変更と非表示、表示形式の定義を含むいくつかの追加や変更を加えることが可能です。 このような変更はすべて更新時に保持され、SAP HANA ビューに加えられた競合しない変更が適用されます。
モデリングに関するその他の制限事項
前述の制限に加えて、SAP HANA に多次元ソースとして接続する場合は、次のモデリング制限に注意してください。
- 計算列のサポートなし: 計算列を作成する機能は無効です。 この事実は、計算列に依存するグループ化とクラスタリングが使用できないことも意味します。
- メジャーのその他の制限: SAP HANA から提供されるサポート レベルを反映するために、メジャーで使用できる DAX 式には他にも制限があります。 たとえば、テーブルに対して集計関数を使用することはできません。
- リレーションシップの定義はサポートされていません。 レポート内でクエリできるビューは 1 つだけです。そのため、リレーションシップの定義はサポートされません。
- データ ビューなし:データ ビュー では、通常、詳細レベルのデータがテーブルに表示されます。 多次元ソースの性質上、SAP HANA を多次元ソースとして使用する場合、このビューは使用できません。
- 列とメジャーの詳細は修正されています。 フィールド リスト内の列とメジャーは、基になるソースによって決定され、変更できません。 たとえば、列を削除したり、そのデータ型を変更したりすることはできません。 ただし、名前を変更することはできます。
その他の視覚化の制限
多次元ソースとして SAP HANA に接続する場合、ビジュアルには制限があります。
- 列集計なし: 視覚化では列の集計を変更できません。常に [集計しない] です。
SAP HANA をリレーショナル ソースとして扱う
リレーショナル ソースとして SAP HANA に接続するには、[ファイル
SAP HANA をリレーショナル ソースとして使用する場合は、追加の柔軟性を利用できます。 たとえば、計算列を作成し、複数の SAP HANA ビューのデータを含め、結果のテーブル間にリレーションシップを作成できます。 ただし、SAP HANA に多次元ソースとして接続する場合、特に SAP HANA ビューに単純な合計ではなく個別のカウントや平均などの非加法メジャーが含まれている場合は、動作に違いがあります。 非加法的な尺度では、間違った結果を生む可能性があります。 また、このメジャーにより、SAP HANA でのクエリ プランの最適化の効率が低下し、クエリのパフォーマンスとタイムアウトが低下する可能性があります。
リレーショナル ソースとしての SAP HANA について
まず、データの取得 または Power Query エディターで定義されたクエリが集計を実行するときに、SQL Server などのリレーショナル ソースの動作を明確にすると便利です。 次の例では、Power Query エディターで定義されているクエリにより、ProductID 別に平均価格が返されます。
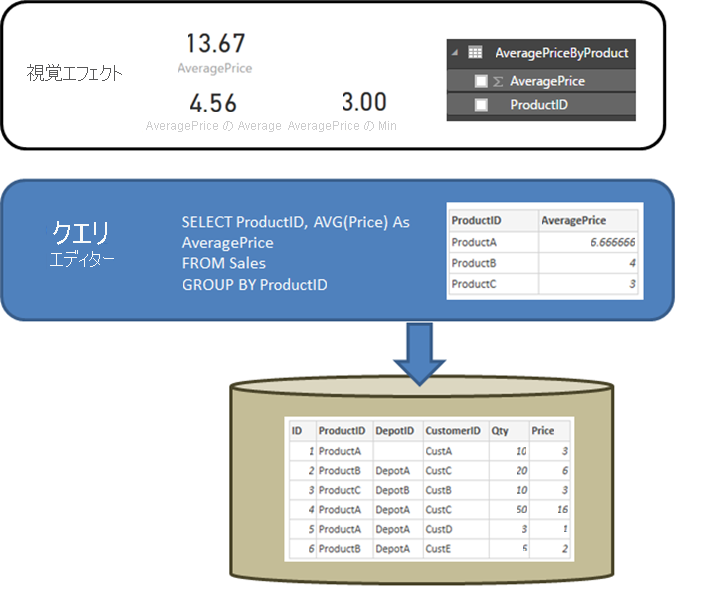
データが DirectQuery を使用する代わりに Power BI にインポートされた場合、次のような状況が発生します。
- データは、Power Query エディターで作成されたクエリによって定義された集計レベルでインポートされます。 たとえば、製品別の平均価格などです。 この結果、Visual で使用できる ProductID と AveragePrice
2 つの列を含むテーブルが作成されます。 - ビジュアルでは、Sum、Average、Minなどの後続の集計が、インポートされたデータに対して実行されます。 たとえば、ビジュアルに AveragePrice を含めると、既定では Sum 集計が使用され、この例では、ProductIDごとに AveragePrice の合計が返されます(この例では 13.67)。 ビジュアルで使用される代替集計関数 (Min や Averageなど) にも同じことが当てはまります。 たとえば、
AveragePrice の平均は、6.66、4、3 の平均を返します。これは、基になるテーブルの 6 つのレコード (5.17) の 価格 の平均ではなく、4.56 に相当します。
同じリレーショナル ソースに対する DirectQuery が Import の代わりに使用されている場合、同じセマンティクスが適用され、結果はまったく同じになります。
同じクエリを使用すると、データが実際にインポートされていない場合でも、論理的にまったく同じデータがレポート レイヤーに表示されます。
ビジュアルでは、Sum、Average、Minなどの後続の集計が、クエリからその論理テーブルに対して再度実行されます。 ここでも、AveragePrice の Average を含む視覚化では、同様に 4.56 が返されます。
接続がリレーショナル ソースとして扱われる場合は、SAP HANA を検討してください。 Power BI は、メジャーを含むことができる SAP HANA の分析ビューと計算ビューの両方で使用できます。 しかし、現在、SAP HANA のアプローチは、このセクションで前述したのと同じ原則に従っています。データの取得 または Power Query エディターで定義されたクエリによって使用可能なデータが決定され、ビジュアル内の後続の集計はそのデータを超え、Import と DirectQuery の両方に同じことが適用されます。 ただし、SAP HANA の性質上、最初の
先ほどの SQL Server の例と同等なものとして、ID、ProductID、DepotID を含む SAP HANA ビューと、ビュー内に Average of Price と定義された AveragePrice を含むメジャーがあります。
[データの取得] エクスペリエンスで、選択されたのが ProductID と AveragePrice メジャーだった場合、それはビューに対するクエリを定義し、その集計データを要求しています。 前の例では、わかりやすくするために、SAP HANA SQL の正確な構文と一致しない擬似 SQL が使用されています。 次に、ビジュアルで定義されたそれ以上の集計は、このようなクエリの結果をさらに集計します。 ここでも、SQL Server の場合に前述したように、この結果は Import と DirectQuery の両方のケースに適用されます。 DirectQuery の場合、データの取得 または Power Query エディターからのクエリは、SAP HANA に送信された 1 つのクエリ内のサブセレクトで使用されるため、実際には、さらに集計する前にすべてのデータが読み取られるわけではありません。
SAP HANA 上の DirectQuery をリレーショナル ソースとして使用する場合、これらすべての考慮事項と動作には、次の重要な考慮事項が必要です。
単純な Sum、Min または Max ではないなど、SAP HANA のメジャーが非加法の場合、視覚化で実行されるその後の集計に注意を払う必要があります。
データの取得 または Power Query エディターでは、必要なデータを取得するために必要な列のみを含める必要があります。これは、結果が SAP HANA に送信できる妥当なクエリである必要があるクエリであることを反映しています。 たとえば、多数の列が選択され、後続のビジュアルで必要になる可能性があると考えられる場合、DirectQuery の単純なビジュアルの場合でも、サブセレクトで使用される集計クエリには、一般的にパフォーマンスが低下し、タイムアウトが発生する可能性がある列の数十が含まれていることを意味します。
次の例で、[データの取得] ダイアログで 5 つの列 (CalendarQuarter、Color、LastName、ProductLine、SalesOrderNumber) をメジャー OrderQuantity と共に選択すると、Min OrderQuantity を含む単純な視覚化を後で作成したときに、SAP HANA への次の SQL クエリが発生することを意味します。 強調表示されている部分はサブセレクトであり、データの取得 / Power Query エディター からのクエリを含んでいます。 このサブセレクトによってカーディナリティが高い結果が得られる場合、SAP HANA のパフォーマンスが低下したり、タイムアウトが発生したりする可能性があります。 パフォーマンスへの影響は、Power BI がサブセレクト内のすべてのフィールドを要求するためではありません。これらのフィールドのほとんどは、外側のクエリによって投影されます。 むしろ、この影響は、サブセレクトにおける措置が HANA サーバーで具体化されるように強制しているためです。

この動作のため、データの取得 または Power Query エディターで選択した項目は、必要な項目に限定することをお勧めしますが、その結果、SAP HANA に対して適切なクエリが実行されます。 可能であれば、セマンティック モデルで必要なすべてのメジャーを再作成し、従来のリレーショナル ソースと同様に SAP HANA を使用することを検討してください。
ベスト プラクティス
どちらの方法でも SAP HANA に接続するには、DirectQuery の使用に関する一般的な推奨事項、特に優れたクエリ パフォーマンスの確保に関連する推奨事項に従ってください。 詳細については、「Power BIで DirectQuery を使用する
考慮事項と制限事項
次の一覧では、完全にはサポートされていないすべての SAP HANA 機能、または Power BI の使用時に動作が異なる機能について説明します。
- 親子階層: 親の子階層は Power BI に表示されません。 これは、Power BI が SQL インターフェイスを使用して SAP HANA にアクセスし、親の子階層に SQL を使用して完全にアクセスできないためです。
- その他の階層メタデータ: 階層の基本構造は Power BI に表示されますが、一部の階層メタデータ (不規則階層の動作の制御など) は効果がありません。 繰り返しますが、これは SQL インターフェイスによって課される制限によるものです。
- SSL を使用した接続 : TLS でインポートと多次元を使用して接続できますが、リレーショナル接続方法に TLS を使用するように構成された SAP HANA インスタンスに接続することはできません。
- 属性ビューのサポート: Power BI は分析ビューと計算ビューに接続できますが、属性ビューに直接接続することはできません。
- カタログ オブジェクトのサポート: Power BI はカタログ オブジェクトに接続できません。
- 発行後に変数に変更する: レポートの発行後に、Power BI サービスで SAP HANA 変数の値を直接変更することはできません。
既知の問題
次の一覧では、Power BI を使用して SAP HANA (DirectQuery) に接続するときの既知の問題について説明します。
カウンターやその他のメジャーについてクエリを実行するときの SAP HANA の問題: 分析ビューに接続していて、カウンター メジャーやその他の比率メジャーが同じ視覚化に含まれている場合、SAP HANA から正しくないデータが返されます。 この問題は、SAP Note 2128928 (計算列とカウンターに対してクエリを実行する場合の予期しない結果)によってカバーされます。 この場合、比率の測定値が正しくありません。
単一の SAP HANA 列から複数の Power BI 列を : SAP HANA 列が複数の階層で使用されている一部の計算ビューでは、SAP HANA は列を 2 つの別個の属性として公開します。 この方法では、Power BI で 2 つの列が作成されます。 ただし、これらの列は既定では非表示になり、階層または列が直接関係するすべてのクエリが正しく動作します。
関連コンテンツ
DirectQuery の詳細については、次のリソースを参照してください。
- Power BI の DirectQuery
- DirectQuery でサポートされているデータ ソース
- DirectQuery と SAP BW
- オンプレミス データ ゲートウェイ