リアルタイム ハブからデータを取得する (プレビュー)
この記事では、リアルタイムハブから新規または既存のテーブルのいずれかにデータを取得する方法について説明します。
重要
この機能はプレビュー段階にあります。
Note
現在、リアルタイム ハブでは、ソースとしてのイベントストリームのみがサポートされています。 リアルタイム ハブは現在プレビュー段階です。
前提条件
- Microsoft Fabric 対応容量を持つワークスペース
- 編集アクセス許可を持つ KQL データベース
- データ ソースのあるイベントストリーム
ソース
リアルタイム ハブからデータを取得するには、データ ソースとしてリアルタイム データ ハブからリアルタイム ストリームを選択する必要があります。 リアルタイム ハブは、次の方法で選択できます。
KQL データベースの下部リボンで 次のいずれかを行います。
[データの取得] ドロップダウン メニューの [連続] で、[リアルタイム ハブ (プレビュー)] を選択します。
[データの取得] を選択し、[データの取得] ウィンドウで、[リアルタイム ハブ] セクションからストリームを選択します。
![[ソース] タブが選択されている [データの取得] ウィンドウのスクリーンショット。](media/get-data-kql/select-data-source.png)
リアルタイム ハブ ストリームの一覧からデータ ストリームを選択します。
![[ソース] タブが選択されている [データの取得] ウィンドウのスクリーンショット。](media/get-data-kql/select-data-source.png#lightbox)
構成
ターゲット テーブルを選択します。 新しいテーブルにデータを取り込む場合は、[+ 新しいテーブル] を選択し、テーブル名を入力します。
Note
テーブル名には、スペース、英数字、ハイフン、アンダースコアを含め、最大 1024 文字を使用できます。 特殊文字はサポートされていません。
[データ ソースの構成] で、次の表に記載されている情報を使用して設定情報を入力します。 一部の設定情報は、eventstream から自動的に入力されます。
![新しいテーブルが入力され、1 つのサンプル データ ファイルが選択されている [構成] タブのスクリーンショット。](media/get-data-real-time-hub/configure-tab.png)
設定 説明 ワークスペース イベントストリーム ワークスペースの場所。 ワークスペース名は自動的に入力されます。 Eventstream 名 イベントストリームの名前。 イベントストリーム名は自動的に入力されます。 データ接続名 ワークスペース内でデータ接続を参照と管理に使用される名前。 データ接続名は自動的に入力されます。 必要に応じて、新しい名前を入力できます。 名前に含めることができる文字は、英数字、ダッシュ、ピリオドのみで、長さは 40 字まで使用できます。 Eventstream で取り込む前にイベントを処理する このオプションを使用すると、宛先テーブルへのデータ インジェストの前にデータを処理するように設定できます。 選択すると、Eventstream でデータ インジェスト プロセスが続行されます。 詳細については、「Eventstream で取り込む前にイベントを処理する」を参照してください。 高度なフィルター 圧縮 ハブからの送信としてのイベントのデータ圧縮。 オプションは None (既定値)、または GZip 圧縮です。 イベント システム プロパティ イベント メッセージごとに複数のレコードがある場合、システム プロパティは最初のものに追加されます。 詳細については、イベント システムのプロパティに関するページを参照してください。 イベント取得の開始日 データ接続は、イベント取得開始日以降に作成された既存のイベントを取得します。 保持期間に基づいて、ハブによって保持されるイベントのみを取得できます。 タイム ゾーンは UTC です。 時刻を指定しない場合、既定の時刻はデータ接続が作成される時刻です。 [次へ] を選択します
![新しいテーブルが入力され、1 つのサンプル データ ファイルが選択されている [構成] タブのスクリーンショット。](media/get-data-real-time-hub/configure-tab.png#lightbox)
Eventstream で取り込む前にイベントを処理する
[Eventstream で取り込む前にイベントを処理する] オプションを使用すると、宛先テーブルに取り込む前にデータを処理できます。 このオプションにより、データ取得プロセスが イベントストリーム でシームレスに続行され、宛先テーブルとデータ ソースの詳細が自動的に入力されます。
Eventstream で取り込む前にイベントを処理する方法:
[設定] タブ内で、[Eventstream で取り込む前にイベントを処理する] を選択します。
[Eventstream でイベントを処理する] ダイアログ ボックス内で、[Eventstream で続行する] を選択します。
重要
[Eventstream で続行] を選択すると、リアルタイムインテリジェンスでのデータ取得プロセスが終了し、宛先テーブルとデータソースの詳細が自動入力された状態で、Eventstream 内で続行されます。
![[Eventstream でのイベントの処理] ダイアログ ボックスのスクリーンショット。](media/get-data-process-event-preingestion/configure-tab-process-event-in-eventstream.png)
[Eventstream] で、[KQL データベース] の宛先ノードを選択し、[KQL データベース] ウィンドウ内で、[取り込む前のイベント処理] が選択されていること、および宛先の詳細が適切であることを確認します。
![[Eventstream でのイベントの処理] ページのスクリーンショット。](media/get-data-process-event-preingestion/process-event-in-eventstream.png)
[イベント プロセッサを開く] を選択して、データ処理を設定し、[保存] を選択します。 詳細については、「イベント プロセッサ エディターを使用したイベント データの処理」を参照してください。
[KQL データベース] ウィンドウに戻り、 [追加] を選択して、[KQL データベース] 宛先ノードの設定を完了します。
データが宛先テーブルに取り込まれたことを確認します。
![[Eventstream でのイベントの処理] ダイアログ ボックスのスクリーンショット。](media/get-data-process-event-preingestion/configure-tab-process-event-in-eventstream.png#lightbox)
![[Eventstream でのイベントの処理] ページのスクリーンショット。](media/get-data-process-event-preingestion/process-event-in-eventstream.png#lightbox)
Note
Eventstream で取り込む前のイベント処理が完了しており、この記事の残りの手順を実行する必要ありません。
検査
[検査] タブが開き、データのプレビューが表示されます。
インジェスト プロセスを完了するには、[完了] を選択します。
![[検査] タブのスクリーンショット。](media/get-data-real-time-hub/inspect-data.png#lightbox)
必要に応じて、次の操作を行います。
- [コマンド ビューアー] を選択し、入力から生成される自動コマンドを表示してコピーします。
- ドロップダウンから必要な形式を選択して、自動的に推論されるデータの形式を変更します。 データは EventData オブジェクトの形式でハブから読み取られます。 サポートされている形式は、Avro、Apache Avro、CSV、JSON、ORC、Parquet、PSV、RAW、SCsv、SOHsv、TSV、TXTおよび TSVE です。
- 列を編集します。
- データ型に基づく [詳細] オプションを確認します。
列の編集
Note
- 表形式 (CSV、TSV、PSV) では、列を 2 回マップすることはできません。 既存の列にマップするには、最初に新しい列を削除します。
- 既存の列の型を変更することはできません。 異なる形式の列にマップしようとすると、空の列になってしまう場合があります。
テーブルに加えることができる変更は、次のパラメーターによって異なります。
- テーブルの種類が新規かまたは既存か
- マッピングの種類が新規かまたは既存か
| テーブルの種類です。 | マッピングの種類 | 使用可能な調整 |
|---|---|---|
| 新しいテーブル | 新しいマッピング | 列の名前変更、データ型の変更、データ ソースの変更、マッピング変換、列の追加、列の削除 |
| 既存のテーブル | 新しいマッピング | 新しい列の追加 (その後、データ型の変更、名前変更、更新が可能) |
| 既存のテーブル | 既存のマッピング | なし |

マッピング変換
一部のデータ形式マッピング (Parquet、JSON、Avro) では、簡単な取り込み時の変換がサポートされています。 マッピング変換を適用するには、[列の編集] ウィンドウで列を作成または更新します。
マッピング変換は、データ型が int または long であるソースを使用して、string または datetime 型の列に対して実行できます。 サポートされているマッピング変換は次のとおりです。
- DateTimeFromUnixSeconds
- DateTimeFromUnixMilliseconds
- DateTimeFromUnixMicroseconds
- DateTimeFromUnixNanoseconds
データ型に基づく [詳細] オプション
表形式 (CSV、TSV、PSV):
表形式データには、ソース データを既存の列にマップするために使用される列名が必ずしも含まれるとは限りません。 最初の行を列名として使用するには、[最初の行を列ヘッダーにする] を選択します。
![[最初の行] のスクリーンショットは列ヘッダー スイッチです。](media/get-data-process-event-advanced-options/first-row-header.png#lightbox)
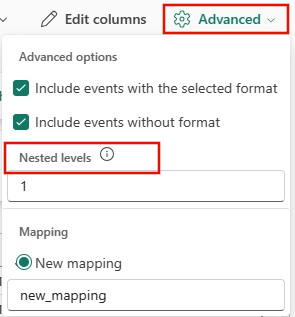
JSON:
JSON データの列分割を指定するには、[詳細]>[入れ子のレベル] を 1 から 100 までで選択します。
まとめ
[データ準備] ウィンドウでは、データ インジェストが正常に終了した場合、3 つのステップすべてに緑色のチェックマークが表示されます。 カードを選択してクエリを実行すること、取り込まれたデータを削除すること、インジェストの概要のダッシュボードを表示することができます。 [閉じる] を選択して、ウィンドウを閉じます。

関連するコンテンツ
- データベースを管理するには、「データの管理」を参照してください。
- クエリを作成、格納、およびエクスポートするには、「KQL クエリセット内のデータのクエリ」を参照してください。
- 新しいイベントストリームからデータを取得するには、「新しいイベントストリームからデータを取得する」を参照してください。