Azure Synapse Analytics のサーバーレス SQL プールのトラブルシューティング
この記事には、Azure Synapse Analytics のサーバーレス SQL プールでよく発生する問題のトラブルシューティング方法に関する情報が含まれています。
Azure Synapse Analytics の詳細については、概要のトピックを参照してください。
Synapse Studio
Synapse Studio は、データベース アクセス ツールをインストールすることなく、ブラウザーを使用してデータにアクセスできる使いやすいツールです。 Synapse Studio は大量のデータセットを読み取ったり、SQL オブジェクトを完全に管理するようには設計されていません。
Synapse Studio でサーバーレス SQL プールがグレー表示される
Synapse Studio がサーバーレス SQL プールへの接続を確立できない場合、サーバーレス SQL プールがグレー表示されるか、状態が [オフライン] と表示されます。
通常、この問題が発生する原因は次に示す 2 つの理由のいずれかです。
- Azure Synapse Analytics バックエンドとの通信がネットワークによって妨げられています。 最もよくあるケースは、TCP ポート 1443 がブロックされている場合です。 サーバーレス SQL プールを動作させるには、このポートのブロックを解除します。 その他の問題でも、サーバーレス SQL プールが動作しなくなることがあります。 詳しくは、トラブルシューティング ガイドに関する記事をご覧ください。
- ユーザーにサーバーレス SQL プールにサインインするためのアクセス許可がありません。 アクセスできるようにするには、Azure Synapse ワークスペース管理者がユーザーをワークスペース管理者ロールまたは SQL 管理者ロールに追加する必要があります。 詳しくは、「Azure Synapse アクセス制御」をご覧ください。
WebSocket 接続が予期せず閉じられた
Websocket connection was closed unexpectedly. というエラー メッセージでクエリが失敗することがあります。このメッセージは、たとえばネットワークの問題のために、Synapse Studio へのブラウザーの接続が中断されたことを意味します。
- この問題を解決するには、クエリを再実行します。
- さらに調査する場合は、Synapse Studio ではなく、Azure Data Studio または SQL Server Management Studio で同じクエリを試してください。
- 環境でこのメッセージが頻繁に発生する場合は、ネットワーク管理者にサポートしてもらいます。 ファイアウォールの設定を調べて、トラブルシューティング ガイドを確認することもできます。
- 問題が解決しない場合は、Azure portal でサポート チケットを作成します。
サーバーレス データベースが Synapse Studio に表示されない
サーバーレス SQL プールに作成されたデータベースが表示されない場合は、サーバーレス SQL プールが起動したかどうかを確認します。 サーバーレス SQL プールが非アクティブ化されている場合、データベースは表示されません。 アクティブ化してデータベースが表示されるようにするには、サーバーレス SQL プールで任意のクエリ (SELECT 1 など) を実行します。
Synapse サーバーレス SQLプールが使用不可と表示される
多くの場合、この動作の原因は正しくないネットワーク構成です。 ポートが適切に構成されていることを確認します。 ファイアウォールまたはプライベート エンドポイントを使用する場合は、それらの設定も確認します。
最後に、適切なロールが付与されていること、取り消されていないことを確認します。
要求で以前のキーまたは期限切れのキーが使用されるため、新しいデータベースを作成できない
このエラーは、暗号化に使用されるワークスペースのカスタマー マネージド キーを変更することによって発生します。 最新バージョンのアクティブ キーを使用して、ワークスペース内のすべてのデータを再暗号化することを選択できます。 再暗号化するには、Azure portal のキーを一時キーに変更してから、暗号化に使用するキーに戻します。 ワークスペース キーを管理する方法については、こちらを参照してください。
サブスクリプションを別の Microsoft Entra テナントに転送した後、Synapse サーバーレス SQL プールを使用できない
サブスクリプションを別の Microsoft Entra テナントに移動した場合、サーバーレス SQL プールでいくつかの問題が発生する可能性があります。 サポート チケットを作成すると、問題を解決するために Azure サポートから連絡があります。
ストレージ アクセス
Azure ストレージのファイルにアクセスしようとしてエラーが発生する場合は、データにアクセスするためのアクセス許可があることを確認します。 一般公開されているファイルにアクセスできる必要があります。 資格情報を使わないでデータにアクセスしようとする場合は、自身の Microsoft Entra ID でファイルに直接アクセスできることを確認します。
ファイルへのアクセスに使用する必要がある Shared Access Signature キーがある場合は、その資格情報を含むサーバー レベルまたはデータベース スコープの資格情報を作成したことを確認します。 ワークスペースのマネージド ID とカスタム サービス プリンシパル名 (SPN) を使ってデータにアクセスする必要がある場合は、資格情報が必要です。
Azure Data Lake Storage のファイルの読み取り、一覧表示、またはアクセスができない
明示的な資格情報を使わないで Microsoft Entra ログインを使用している場合は、自身の Microsoft Entra ID でストレージのファイルにアクセスできることを確認します。 ファイルにアクセスするには、Microsoft Entra ID に BLOB データ閲覧者アクセス許可、または ADLS のアクセス制御リスト (ACL) の一覧表示および読み取りを行うアクセス許可が必要です。 詳細については、「ファイルを開くことができないため、クエリが失敗する」を参照してください。
資格情報を使ってストレージにアクセスする場合は、お使いのマネージド ID または SPN にデータ閲覧者または共同作成者のロール、または特定の ACL アクセス許可があることを確認します。 Shared Access Signature トークンを使った場合は、それに rl アクセス許可があり、有効期限が切れていないことを確認します。
SQL ログインとデータ ソースのないOPENROWSET 関数を使っている場合は、ストレージ URI と一致し、ストレージにアクセスするためのアクセス許可がある、サーバー レベルの資格情報を使っていることを確認します。
ファイルを開くことができないため、クエリが失敗する
File cannot be opened because it does not exist or it is used by another process というエラーでクエリが失敗したときに、ファイルが存在し、かつ別のプロセスで使用されていないことが確かな場合は、サーバーレス SQL プールからファイルにアクセスできません。 この問題が発生するのは、通常、Microsoft Entra ID にファイルへのアクセス権がないか、ファイアウォールによってファイルへのアクセスがブロックされているためです。
既定では、サーバーレス SQL プールは Microsoft Entra ID を使ってファイルへのアクセスを試みます。 この問題を解決するには、ファイルにアクセスするための適切な権限を持っている必要があります。 最も簡単な方法は、クエリ対象のストレージ アカウントに対するストレージ BLOB データ共同作成者ロールを自分に付与することです。
詳細については、以下を参照してください:
ストレージ BLOB データ共同作成者ロールに代わるもの
ストレージ BLOB データ共同作成者ロールを自分に付与する代わりに、ファイルのサブセットに対してさらに細かいアクセス許可を付与することもできます。
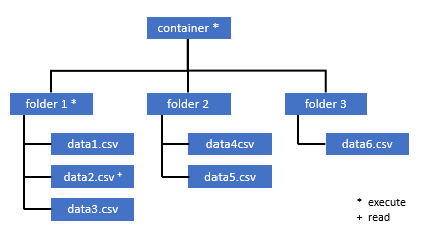
このコンテナー内の一部のデータにアクセスする必要があるすべてのユーザーには、ルート (コンテナー) までのすべての親フォルダーに対する実行アクセス許可も必要です。
Azure Data Lake Storage Gen2 で ACL を設定する方法の詳細を確認してください。
注意
コンテナー レベルの実行アクセス許可は、Azure Data Lake Storage Gen2 内で設定する必要があります。 フォルダーに対するアクセス許可は、Azure Synapse 内で設定できます。
この例で data2.csv のクエリを実行する場合は、次のアクセス許可が必要です。
- コンテナーに対する実行アクセス許可
- folder1 に対する実行アクセス許可
- data2.csv に対する読み取りアクセス許可
アクセスしたいデータに対する完全なアクセス許可を持つ管理者ユーザーで、Azure Synapse にサインインします。
データ ペインでファイルを右クリックして、[アクセスの管理] を選びます。
![[アクセスの管理] オプションを示すスクリーンショット。](media/resources-self-help-sql-on-demand/manage-access.png)
[読み取り] アクセス許可以上を選びます。 ユーザーの UPN またはオブジェクト ID を入力します (例:
user@contoso.com)。 [追加] を選択します。このユーザーに読み取りアクセス許可を付与します。

注意
ゲスト ユーザーの場合は、Azure Synapse で直接行うことはできないので、Azure Data Lake でこのステップを直接行う必要があります。
パス上のディレクトリの内容を一覧表示できない
このエラーは、Azure Data Lake のクエリを実行しているユーザーがストレージのファイルの一覧を表示できないことを示しています。 このエラーは、複数のシナリオで発生する可能性があります。
- Microsoft Entra パススルー認証を使っている Microsoft Entra ユーザーに、Data Lake Storage のファイルの一覧を表示するためのアクセス許可がありません。
- Microsoft Entra ID または SQL のユーザーが Shared Access Signature キーまたはワークスペースのマネージド ID を使ってデータを読み取っていて、そのキーまたは ID にストレージのファイルの一覧を表示するアクセス許可がありません。
- Dataverse のデータにアクセスしているユーザーに、Dataverse のデータのクエリを実行するためのアクセス許可がありません。 このシナリオは、SQL ユーザーを使っている場合に発生する可能性があります。
- Delta Lake にアクセスしているユーザーに、Delta Lake のトランザクション ログを読み取るアクセス許可がない可能性があります。
この問題を解決するための最も簡単な方法は、クエリ対象のストレージ アカウントでのストレージ BLOB データ共同作成者ロールを自分に付与することです。
詳細については、以下を参照してください:
Dataverse テーブルの内容の一覧を表示できない
リンクされた DataVerse テーブルを読み取るために Dataverse に対する Azure Synapse Link を使っている場合は、サーバーレス SQL プールを使用してリンクされたデータにアクセスするために Microsoft Entra アカウントを使う必要があります。 詳しくは、Azure Data Lake での Azure Synapse Link for Dataverse に関する記事をご覧ください。
SQL ログインを使って、DataVerse テーブルを参照している外部テーブルを読み取ろうとした場合、次のエラーが発生します。External table '???' is not accessible because content of directory cannot be listed.
Dataverse の外部テーブルでは、常に、Microsoft Entra パススルー認証が使われます。 Shared Access Signature キーまたはワークスペースのマネージド ID を使うように、それらを構成することは "できません"。
Delta Lake トランザクション ログの内容の一覧を表示できない
サーバーレス SQL プールで Delta Lake トランザクション ログ フォルダーを読み取ることができない場合、次のエラーが返されます。
Content of directory on path 'https://.....core.windows.net/.../_delta_log/*.json' cannot be listed.
_delta_log フォルダーが存在することを確認します。 Delta Lake 形式に変換されていないプレーンな Parquet ファイルのクエリを実行している可能性があります。 _delta_log フォルダーが存在する場合は、基になる Delta Lake フォルダーに対する読み取りおよび一覧表示の両方のアクセス許可を持っていることを確認します。 FORMAT='csv' を使って、json ファイルを直接読み取ってみます。 URI を BULK パラメーターに含めます。
select top 10 *
from openrowset(BULK 'https://.....core.windows.net/.../_delta_log/*.json',FORMAT='csv', FIELDQUOTE = '0x0b', FIELDTERMINATOR ='0x0b',ROWTERMINATOR = '0x0b')
with (line varchar(max)) as logs
このクエリが失敗した場合、呼び出し元には基になるストレージ ファイルを読み取るためのアクセス許可がありません。
クエリ実行
次のケースでは、クエリの実行中にエラーが発生する可能性があります。
- 呼び出し元が、一部のオブジェクトにアクセスできません。
- クエリが、外部データにアクセスできません。
- サーバーレス SQL プールでサポートされていない何らかの機能が、クエリに含まれています。
現在のリソースの制約によりクエリを実行できないため、クエリが失敗する
This query cannot be executed due to current resource constraints. というエラー メッセージでクエリが失敗する場合があります。このメッセージは、リソースの制約のため、現時点ではサーバーレス SQL プールが実行できないことを意味します。 トラブルシューティングのいくつかのオプションを次に示します。
- 適切なサイズのデータ型が使用されていることを確認してください。
- クエリで Parquet ファイルを対象にする場合は、既定で VARCHAR(8000) になるため、文字列型の列に対して明示的な型を定義することを検討してください。 推論されたデータ型を確認します。
- 対象のクエリが CSV ファイルをターゲットとしている場合は、統計を作成することを検討してください。
- クエリを最適化するには、サーバーレス SQL プールのパフォーマンスのベスト プラクティスに関する記事をご覧ください。
クエリ タイムアウトが時間切れになりました
サーバーレス SQL プールでクエリが 30 分以上実行された場合、エラー Query timeout expired が返されます。 サーバーレス SQL プールのこの制限は変更できません。
- ベスト プラクティスを適用して、クエリを最適化してみてください。
- CREATE EXTERNAL TABLE AS SELECT (CETAS) を使って、クエリの一部を具体化してみてください。
- 他のクエリがリソースを利用している可能性があるため、サーバーレス SQL プールで実行されている同時実行ワークロードがあるかどうかを調べます。 その場合は、複数のワークスペースにワークロードを分割できます。
無効なオブジェクト名
このエラー Invalid object name 'table name' は、サーバーレス SQL プール データベースに存在しないオブジェクト (テーブル、ビューなど) を使っていることを示します。 次のオプションを試してください。
テーブルまたはビューの一覧を表示し、オブジェクトが存在するかどうかを調べます。 Synapse Studio にはサーバーレス SQL プールで使用できない一部のテーブルが表示される可能性があるため、SQL Server Management Studio または Azure Data Studio を使います。
オブジェクトが表示される場合は、大文字と小文字の区別があるデータベース照合順序またはバイナリ データベース照合順序を使っていることを調べます。 オブジェクト名が、クエリで使った名前と一致していない可能性があります。 バイナリ データベース照合順序では、
Employeeとemployeeは 2 つの異なるオブジェクトです。オブジェクトが表示されない場合は、Lake または Spark データベースのテーブルのクエリを実行しようとしている可能性があります。 次の理由により、サーバーレス SQL プールのテーブルを使用できない場合があります。
- テーブルに、サーバーレス SQL プールで表すことができない列の型が含まれます。
- テーブルに、サーバーレス SQL プールでサポートされていない形式が含まれます。 たとえば、Avro や ORC などです。
文字列データまたはバイナリ データが切り捨てられます
このエラーは、文字列型またはバイナリ列型 (VARCHAR、VARBINARY、NVARCHAR など) の長さが、読み取るデータの実際のサイズよりも短い場合に発生します。 このエラーは、列型の長さを増やすことで解決できます。
- 文字列の列が
VARCHAR(32)型として定義されていて、テキストが 60 文字の場合は、列スキーマでVARCHAR(60)型 (またはそれ以上) を使用します。 - スキーマ推論 (
WITHスキーマを含まない) を使用している場合、すべての文字列の列がVARCHAR(8000)型として自動的に定義されます。 このエラーが発生する場合は、より大きいVARCHAR(MAX)列型を持つWITH句でスキーマを明示的に定義し、このエラーを解決します。 - テーブルが Lake データベースにある場合は、Spark プールの文字列の列のサイズを増やしてみてください。
- サーバーレス SQL プールで VARCHAR 値を自動的に切り詰めるには、
SET ANSI_WARNINGS OFFを試してみてください (機能に影響がない場合)。
文字列の後の引用符が閉じていない
文字列列で LIKE 演算子を使ったり、文字列リテラルと比較したりすると、まれに次のエラーが発生する場合があります。
Unclosed quotation mark after the character string
このエラーは、列で Latin1_General_100_BIN2_UTF8 照合順序を使っている場合に発生する可能性があります。 問題を解決するには、Latin1_General_100_BIN2_UTF8 照合順序ではなく Latin1_General_100_CI_AS_SC_UTF8 照合順序を列に設定してください。 それでもエラーが返される場合は、Azure portal からサポート リクエストを送信してください。
あるディストリビューションから別のディストリビューションにデータを転送しているときに、tempdb 領域を割り当てられなかった
クエリ実行エンジンがデータを処理してクエリを実行しているノード間でデータを転送できない場合、Could not allocate tempdb space while transferring data from one distribution to another というエラーが返されます。 このエラーは、現在のリソース制約エラーによりクエリを実行できないため、汎用クエリが失敗する特殊なケースです。 このエラーは、tempdb データベースに割り当てられたリソースがクエリを実行するには不十分な場合に返されます。
サポート チケットを提出する前に、ベスト プラクティスを適用してください。
外部ファイルの処理中にエラーが発生してクエリが失敗する (最大エラー数に達しました)
error handling external file: Max errors count reached というエラー メッセージでクエリが失敗する場合は、指定した列の型と読み込む必要があるデータが一致していないことを意味します。
エラーおよび検索する行および列に関する詳細な情報を取得するには、パーサーのバージョンを 2.0 から 1.0 に変更します。
例
このクエリ 1 でファイル names.csv のクエリを実行すると、Azure Synapse サーバーレス SQL プールから Error handling external file: 'Max error count reached'. File/External table name: [filepath]. というエラーが返されます。次に例を示します。
names.csv ファイルには以下が含まれています。
Id,first name,
1, Adam
2,Bob
3,Charles
4,David
5,Eva
クエリ 1:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='2.0',
FIELDTERMINATOR =';',
FIRSTROW = 2
)
WITH (
[ID] SMALLINT,
[Text] VARCHAR (1) COLLATE Latin1_General_BIN2
)
AS [result]
原因
パーサーのバージョンをバージョン 2.0 から 1.0 に変更するとすぐに、エラー メッセージが問題の特定に役立つようになります。 新しいエラー メッセージは Bulk load data conversion error (truncation) for row 1, column 2 (Text) in data file [filepath]. になります
切り捨ては、列の型が小さすぎてデータが収まらないことを意味します。 この names.csv ファイルに含まれる最長の名は 7 文字です。 少なくとも VARCHAR(7) のデータ型を使用する必要があります。 エラーは、次のコード行で発生します。
[Text] VARCHAR (1) COLLATE Latin1_General_BIN2
このようにクエリを変更すると、エラーは解決されます。 デバッグ後に、パフォーマンスを最大にするため、パーサーのバージョンを 2.0 に変更します。
どのパーサー バージョンをいつ使用するのかについて詳しくは、Synapse Analytics でサーバーレス SQL プールを使っているときの OPENROWSET の使用に関する記事をご覧ください。
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='2.0',
FIELDTERMINATOR =';',
FIRSTROW = 2
)
WITH (
[ID] SMALLINT,
[Text] VARCHAR (7) COLLATE Latin1_General_BIN2
)
AS [result]
ファイルを開けなかったため、一括読み込みできない
エラー Cannot bulk load because the file could not be opened は、クエリの実行中にファイルが変更された場合に返されます。 通常、Cannot bulk load because the file {file path} could not be opened. Operating system error code 12. (The access code is invalid.) などのエラーが表示される場合があります
サーバーレス SQL プールでは、クエリの実行中に変更されているファイルを読み取ることはできません。 クエリではファイルをロックできません。 変更操作が "追加された" ことがわかっている場合は、{"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]} のオプションを設定してみることができます。
詳しくは、追加専用ファイルに対してクエリを実行する方法または追加専用ファイルにテーブルを作成する方法をご覧ください。
データ変換エラーでクエリが失敗する
Bulk load data conversion error (type mismatches or invalid character for the specified code page) for row n, column m [columnname] in the data file [filepath]. というエラー メッセージでクエリが失敗する場合があります。このメッセージは、データ型が行番号 n および列 m の実際のデータと一致しなかったことを意味します。
たとえば、データ内は整数のみと予想したのに、行 n に文字列があった場合、このエラー メッセージが表示されます。
この問題を解決するには、選択したファイルとデータ型を調べます。 また、行区切り記号とフィールド ターミネータの設定が正しいかどうかも確認します。 次の例では、列の型として VARCHAR を使用して検査を行う方法を示します。
フィールド ターミネータ、行区切り記号、引用符のエスケープについて詳しくは、「CSV ファイルに対してクエリを実行する」をご覧ください。
例
ファイル names.csv のクエリを実行する場合:
Id, first name,
1,Adam
2,Bob
3,Charles
4,David
five,Eva
次のクエリを使用する場合:
クエリ 1:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =',',
FIRSTROW = 2
)
WITH (
[ID] SMALLINT,
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
Azure Synapse サーバーレス SQL プールからエラー Bulk load data conversion error (type mismatch or invalid character for the specified code page) for row 6, column 1 (ID) in data file [filepath]. が返されます
この問題に対処するには、データを参照し、情報に基づいて決定する必要があります。 この問題の原因になっているデータを確認するには、最初にデータ型を変更する必要があります。 データ型 SMALLINT を使って ID 列のクエリを実行する代わりに、VARCHAR (100) を使ってこの問題を分析します。
この少し変更したクエリ 2 を使うと、データを処理して名前の一覧を返すことができるようになります。
クエリ 2:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =',',
FIRSTROW = 2
)
WITH (
[ID] VARCHAR(100),
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
データの 5 行目の ID に予期しない値が含まれている場合があります。 このような状況では、データのビジネス所有者と、この例のようなデータの破損を回避する方法について同意することが重要です。 アプリケーション レベルで防止できなければ、適切なサイズの VARCHAR が唯一の選択肢になる可能性があります。
ヒント
VARCHAR() をできるだけ短くしてみます。 パフォーマンスが低下する可能性があるため、可能な場合は VARCHAR(MAX) を避けます。
クエリの結果が想定したものではない
クエリが失敗しなくても、結果セットが想定したとおりにならない場合があります。 結果の列が空であったり、予期しないデータが返されたりすることがあります。 このシナリオでは、行区切り記号またはフィールド ターミネータの選択が正しくなかった可能性があります。
この問題を解決するには、別のデータ検索方法を使用し、それらの設定を変更します。 次の例に示すように、このクエリのデバッグは簡単です。
例
クエリ 1 のクエリでファイル names.csv のクエリを実行すると、Azure Synapse サーバーレス SQL プールからはおかしな結果が返されます。
names.csv:
Id,first name,
1, Adam
2, Bob
3, Charles
4, David
5, Eva
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =';',
FIRSTROW = 2
)
WITH (
[ID] VARCHAR(100),
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
| ID | Firstname |
| ------------- |------------- |
| 1,Adam | NULL |
| 2,Bob | NULL |
| 3,Charles | NULL |
| 4,David | NULL |
| 5,Eva | NULL |
列 Firstname に値がないようです。 代わりに、すべての値が ID 列に含まれています。 それらの値は、コンマで区切られています。 この問題は、フィールド ターミネータとしてセミコロン記号の代わりにコンマを選択する必要があるコード行によって発生しました。
FIELDTERMINATOR =';',
この 1 文字を変更すると、問題が解決します。
FIELDTERMINATOR =',',
クエリ 2 によって作成される結果セットは、想定したとおりになります。
クエリ 2:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =',',
FIRSTROW = 2
)
WITH (
[ID] VARCHAR(100),
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
戻り値:
| ID | Firstname |
| ------------- |------------- |
| 1 | Adam |
| 2 | Bob |
| 3 | Charles |
| 4 | David |
| 5 | Eva |
列の型が外部データ型と互換性がない
Column [column-name] of type [type-name] is not compatible with external data type […], というエラー メッセージでクエリが失敗する場合は、PARQUET データ型が正しくない SQL データ型にマップされた可能性があります。
たとえば、Parquet ファイルに浮動小数点数 (12.89 など) の価格の列があり、それを INT にマップしようとした場合、このようなエラー メッセージが表示されます。
この問題を解決するには、ファイルと選んだデータ型を調べます。 こちらのマッピング テーブルは、正しい SQL データ型の選択に役立ちます。 ベスト プラクティスとしては、何もしないと VARCHAR データ型に解決される列のマッピングのみを指定します。 可能な場合は VARCHAR を回避すると、クエリのパフォーマンスが向上します。
例
このクエリ 1 でファイル taxi-data.parquet のクエリを実行すると、Azure Synapse サーバーレス SQL プールから次のエラーが返されます。
ファイル taxi-data.parquet には次のものが含まれます。
|PassengerCount |SumTripDistance|AvgTripDistance |
|---------------|---------------|----------------|
| 1 | 2635668.66000064 | 6.72731710678951 |
| 2 | 172174.330000005 | 2.97915543404919 |
| 3 | 296384.390000011 | 2.8991352022851 |
| 4 | 12544348.58999806| 6.30581582240281 |
| 5 | 13091570.2799993 | 111.065989028627 |
クエリ 1:
SELECT
*
FROM
OPENROWSET(
BULK '<filepath>taxi-data.parquet',
FORMAT='PARQUET'
) WITh
(
PassengerCount INT,
SumTripDistance INT,
AVGTripDistance FLOAT
)
AS [result]
Column 'SumTripDistance' of type 'INT' is not compatible with external data type 'Parquet physical type: DOUBLE', please try with 'FLOAT'. File/External table name: '<filepath>taxi-data.parquet'.
このエラー メッセージは、データ型に互換性がないことを示し、INT ではなく FLOAT を使用することが提案されています。 エラーは、次のコード行で発生します。
SumTripDistance INT,
この少し変更したクエリ 2 を使うと、データを処理して 3 つの列をすべて表示できるようになります。
クエリ 2:
SELECT
*
FROM
OPENROWSET(
BULK '<filepath>taxi-data.parquet',
FORMAT='PARQUET'
) WITh
(
PassengerCount INT,
SumTripDistance FLOAT,
AVGTripDistance FLOAT
)
AS [result]
クエリが分散処理モードでサポートされていないオブジェクトを参照している
エラー The query references an object that is not supported in distributed processing mode は、Azure Storage または Azure Cosmos DB 分析ストレージのデータのクエリ中に使用できないオブジェクトまたは関数を使用したことを示します。
一部のオブジェクト (システム ビューなど) と関数は、Azure Data Lake または Azure Cosmos DB 分析ストレージに格納されているデータのクエリの間は使用できません。 外部データをシステム ビューと結合したり、一時テーブルに外部データを読み込むクエリを使用したり、一部のセキュリティ関数またはメタデータ関数を使用して外部データをフィルター処理したりしないようにします。
WaitIOCompletion の呼び出しに失敗しました
エラー メッセージ WaitIOCompletion call failed は、リモート ストレージ (Azure Data Lake) からデータを読み取る I/O 操作の完了を待っている間にクエリが失敗したことを示しています。
このエラー メッセージには、次のパターンがあります: Error handling external file: 'WaitIOCompletion call failed. HRESULT = ???'. File/External table name...
ストレージが、サーバーレス SQL プールと同じリージョンにあることを確認します。 ストレージのメトリックを調べて、ストレージ レイヤーに I/O 要求を飽和させる可能性のある他のワークロード (新しいファイルのアップロードなど) がないことを確認します。
HRESULT フィールドに結果コードが含まれています。 最も一般的なエラー コードと、考えられる解決策を次に示します。
このエラーは、ソース ファイルがストレージ内に存在しないことを意味します。
このエラー コードが発生する理由は、次のとおりです。
- ファイルが別のアプリケーションによって削除された。
- この一般的なシナリオでは、クエリの実行が開始され、ファイルが列挙されて、ファイルが検出されます。 その後、クエリの実行の間に、ファイルが削除されます。 たとえば、Databricks、Spark、または Azure Data Factory によって削除されることがあります。 ファイルが見つからないため、クエリは失敗します。
- この問題は、デルタ形式でも発生する可能性があります。 テーブルの新しいバージョンがあり、クエリは削除されたファイルに対して再度実行されないため、再試行すると成功する可能性があります。
- 無効な実行プランがキャッシュされています。
- 一時的な軽減策として、コマンド
DBCC FREEPROCCACHEを実行します。 問題が解決しない場合は、サポート チケットを作成します。
- 一時的な軽減策として、コマンド
NOT 付近に不適切な構文がある
エラー Incorrect syntax near 'NOT' は、列定義に NOT NULL 制約を含む列のある外部テーブルが存在することを示します。
- テーブルを更新して、列定義から NOT NULL を削除します。
- このエラーは、CETAS ステートメントから作成されたテーブルで一時的に発生することもあります。 問題が解決しない場合は、外部テーブルを削除してから作成し直してみてください。
パーティション列から NULL 値が返される
クエリがパーティション分割列ではなく NULL 値を返す場合、またはパーティション列が見つからない場合は、トラブルシューティングの手順がいくつかあります。
- テーブルを使ってパーティション分割されたデータセットのクエリを実行する場合、テーブルではパーティション分割がサポートされません。 テーブルをパーティション分割されたビューに置き換えます。
- FILEPATH() 関数を使って、パーティション分割されたファイルのクエリを実行する OPENROWSET でパーティション分割されたビューを使う場合は、その場所でワイルドカードパターンを正しく指定し、ワイルドカードを参照するために適切なインデックスを使ったことを確認します。
- パーティション分割されたフォルダー内でファイルのクエリを直接実行する場合、パーティション分割列はファイルの列の一部ではありません。 パーティション値は、ファイルではなくフォルダー パスに配置されます。 そのため、ファイルにパーティション値は含まれません。
列の型 DATETIME2 の値をバッチに挿入できませんでした
Inserting value to batch for column type DATETIME2 failed というエラーは、サーバーレス プールが基になるファイルの日付値を読み取りできないことを示します。 Parquet または Delta Lake ファイルに格納されている datetime 値を DATETIME2 列として表すことはできません。
Spark を使ってファイル内の最小値を調べ、一部の日付が 0001-01-03 未満であることを確認します。 Spark 2.4 (サポートされていないランタイム バージョン) バージョンまたはレガシ datetime ストレージ形式を引き続き使用するそれ以降の Spark バージョンを使ってファイルを保存した場合、前の datetime 値はユリウス暦を使って書き込まれており、これはサーバーレス SQL プールで使われる予期的グレゴリオ暦と一致しません。
Parquet (一部の Spark バージョン) で値を書き込むために使われるユリウス暦と、サーバーレス SQL プールで使われる予期的グレゴリオ暦との間に、2 日の差がある場合があります。 この違いにより、無効な負の日付値への変換が発生する可能性があります。
これらの値は SQL で無効な日付値として扱われるため、Spark を使って更新してみてください。 SQL の日付範囲外の値を Delta Lake の NULL に更新する方法のサンプルを次に示します。
from delta.tables import *
from pyspark.sql.functions import *
deltaTable = DeltaTable.forPath(spark,
"abfss://my-container@myaccount.dfs.core.windows.net/delta-lake-data-set")
deltaTable.update(col("MyDateTimeColumn") < '0001-02-02', { "MyDateTimeColumn": null } )
この変更により、表現できない値が削除されます。 ユリウス暦と予期的グレゴリオ暦の間にはまだ食い違いがあるため、他の日付の値は、適切に読み込まれても、正しく表されない可能性があります。 Spark 3.0 以前のバージョンを使っている場合は、1900-01-01 より前の日付についても、予期しない日付のずれが発生する場合があります。
Spark 3.1 以降に移行し、予期的グレゴリオ暦に切り替えることを検討してください。 既定では、最新の Spark バージョンには、サーバーレス SQL プール内の予定表に合わせた予期的グレゴリオ暦が使用されます。 より後のバージョンの Spark でレガシ データを再度読み込み、次の設定を使って日付を修正します。
spark.conf.set("spark.sql.legacy.parquet.int96RebaseModeInWrite", "CORRECTED")
トポロジの変更またはコンピューティング コンテナーの障害が原因でクエリが失敗する
このエラーは、サーバーレス SQL プールで何らかの内部プロセスの問題が発生したことを示している可能性があります。 サポート チケットを提出し、その中に、Azure サポート チームが問題を調査するために役立ちそうなすべての必要な詳細情報を記載します。
通常のワークロードと比較して異なる可能性のあるものについて説明します。 たとえば、このエラーが発生する前に、大量の同時リクエストが行われていたり、特殊なワークロードやクエリが開始していた可能性があります。
ワイルドカード展開がタイムアウトした
「クエリ フォルダーと複数のファイル」セクションで説明されているように、サーバーレス SQL プールでは、ワイルドカードを使用した複数のファイル/フォルダーの読み取りがサポートされています。 クエリあたりのワイルドカードの上限数は 10 個です。 この機能はコストがかかることに注意する必要があります。 サーバーレス プールにワイルドカードと一致するすべてのファイルが一覧表示されるまでに時間がかかります。 これにより待機時間が発生し、クエリを実行しようとしているファイルの数が多い場合、この待機時間が長くなる可能性があります。 この場合、次のエラーが発生することがあります。
"Wildcard expansion timed out after X seconds."
これを回避するには、いくつかの軽減手順を実行できます。
- サーバーレス SQL プールのベスト プラクティスに関する記事で説明されているベスト プラクティスを適用します。
- ファイルをより大きなファイルにまとめて、クエリを実行しようとしているファイルの数を減らしてみてください。 ファイル サイズが 100 MB を超えるようにしてください。
- パーティション分割列に対するフィルターが可能な限り使用されるようにします。
- 差分ファイル形式を使用している場合は、Spark の書き込みの最適化機能を使用します。 これにより、読み取りと処理が必要なデータの量を減らすことで、クエリのパフォーマンスを向上させることができます。 書き込みの最適化の使用方法については、Apache Spark での書き込みの最適化の使用に関する記事を参照してください。
- パーティション分割列に対して暗黙的なフィルターを事実上ハードコーディングすることで、最上位のワイルドカードの一部を回避するには、動的 SQL を使用します。
自動スキーマ推論を使用する場合に列が不足する
スキーマがわからない場合や、WITH 句を省略してスキーマを指定していない場合でも、ファイルに対して簡単にクエリを実行できます。 その場合、列名とデータ型はファイルから推論されます。 一度に多数のファイルを読み取る場合、スキーマはストレージから取得した最初のファイル サービスから推測されることに注意してください。 これは、スキーマを定義するためにサービスで使用されるファイルにこれらの列が含まれていなかったため、予想される列の一部が省略されていることを意味する場合があります。 スキーマを明示的に指定するには、OPENROWSET WITH 句を使用します。 (外部テーブルまたは OPENROWSET WITH 句を使用して) スキーマを指定した場合は、既定の lax パス モードが使用されます。 つまり、一部のファイルに存在しない列は NULL として返されます (それらのファイルからの行の場合)。 パス モードの使用方法を理解するには、次のドキュメントとサンプルを確認してください。
構成
サーバーレス SQL プールでは、T-SQLを使ってデータベース オブジェクトを構成できます。 次にいくつかの制約を示します。
masterとlakehouseまたは Spark データベースにオブジェクトを作成することはできません。- 資格情報を作成するには、マスター キーが必要です。
- オブジェクトで使われているデータを参照するにはアクセス許可が必要です。
データベースを作成できない
エラー CREATE DATABASE failed. User database limit has been already reached. を受け取る場合は、1 つのワークスペースでサポートされている最大数のデータベースを作成しています。 詳細については、「制約」を参照してください。
- オブジェクトを分離する必要がある場合は、データベース内でスキーマを使用します。
- Azure Data Lake Storage を参照する必要がある場合は、サーバーレス SQL プールで同期されるレイクハウス データベースまたは Spark データベースを作成します。
行の最小サイズがテーブル行の最大許容サイズである 8060 バイトを超えているため、テーブルの作成または変更に失敗した
任意のテーブルでは、1 行あたり最大 8 KB のサイズを持つことができます (行外の VARCHAR(MAX)/VARBINARY(MAX) データは含まれません)。 行内のセルの合計サイズが 8060 バイトを超えるテーブルを作成すると、次のエラーが発生します。
Msg 1701, Level 16, State 1, Line 3
Creating or altering table '<table name>' failed because the minimum row size would be <???>,
including <???> bytes of internal overhead.
This exceeds the maximum allowable table row size of 8060 bytes.
このエラーは、列サイズが 8060 バイトを超える Spark テーブルを作成し、サーバーレス SQL プールで Spark テーブル データを参照するテーブルが作成できない場合にも、Lake データベースで発生する可能性があります。
軽減策として、CHAR(N) のような固定サイズの型の使用を避け、可変サイズの VARCHAR(N) 型に置き換えるか、CHAR(N) のサイズを小さくします。 SQL Server における 8 KB の行グループの制限に関する記事を参照してください。
この操作を実行する前に、マスター キーをデータベースに作成するか、またはセッションでマスター キーを開きます。
Please create a master key in the database or open the master key in the session before performing this operation. というエラー メッセージでクエリが失敗する場合は、ユーザー データベースが現時点でマスター キーにアクセスできないことを意味します。
ほとんどの場合、新しいユーザー データベースを作成し、まだマスター キーを作成していません。
この問題を解決するには、次のクエリを使用してマスター キーを作成します。
CREATE MASTER KEY [ ENCRYPTION BY PASSWORD ='strongpasswordhere' ];
Note
ここで、'strongpasswordhere' は別のシークレットに置き換えます。
CREATE ステートメントがマスター データベースでサポートされていない
エラー メッセージ Failed to execute query. Error: CREATE EXTERNAL TABLE/DATA SOURCE/DATABASE SCOPED CREDENTIAL/FILE FORMAT is not supported in master database. でクエリが失敗した場合は、サーバーレス SQL プール内の master データベースが以下の作成をサポートしていないことを意味します。
- 外部テーブル。
- 外部データ ソース。
- データベース スコープの資格情報。
- 外部ファイル形式。
解決策を次に示します
ユーザー データベースの作成:
CREATE DATABASE <DATABASE_NAME>前に
masterデータベースで失敗した <DATABASE_NAME> のコンテキストで、CREATE ステートメントを実行します。外部ファイル形式の作成の例を次に示します。
USE <DATABASE_NAME> CREATE EXTERNAL FILE FORMAT [SynapseParquetFormat] WITH ( FORMAT_TYPE = PARQUET)
Microsoft Entra ログインまたはユーザーを作成できない
データベースに Microsoft Entra の新しいログインまたはユーザーを作成しようとするとエラーが発生する場合は、データベースへの接続に使ったログインを確認します。 新しい Microsoft Entra ユーザーを作成しようとするログインには、Microsoft Entra ドメインにアクセスして、ユーザーが存在するかどうかを確認するためのアクセス許可が必要です。 次の点に注意してください。
- SQL のログインにはこのアクセス許可がないため、SQL 認証を使うと、常にこのエラーが発生します。
- Microsoft Entra ログインを使って新しいログインを作成する場合は、Microsoft Entra ドメインにアクセスするためのアクセス許可があるかどうかを確認します。
Azure Cosmos DB
サーバーレス SQL プールでは、OPENROWSET 関数を使って Azure Cosmos DB 分析ストレージのクエリを実行できます。 Azure Cosmos DB のコンテナーに分析ストレージがあることを確認します。 アカウント、データベース、コンテナー名が正しく指定されていることを確認します。 また、Azure Cosmos DB のアカウント キーが有効であることを確認します。 詳細については、「前提条件」を参照してください。
OPENROWSET 関数を使用して Azure Cosmos DB のクエリを実行できない
Azure Cosmos DB アカウントに接続できない場合は、前提条件を確認してください。 次の表に、考えられるエラーとトラブルシューティングの操作を示します。
| エラー | 根本原因 |
|---|---|
| 構文エラー: - OPENROWSET の近くに正しくない構文があります。- ... は、認識された BULK OPENROWSET プロバイダー オプションではありません。- ... の近くに正しくない構文があります。 |
考えられる根本原因: - 1 番目のパラメーターとして Azure Cosmos DB を使用していません。 - 3 番目のパラメーターで識別子の代わりに文字列リテラルを使用しています。 - 3 番目のパラメーター (コンテナー名) が指定されていません。 |
| Azure Cosmos DB の接続文字列にエラーがありました。 | - アカウント、データベース、またはキーが指定されていません。 - 接続文字列のオプションが認識されません。 - 接続文字列の末尾にセミコロン ; が記述されています。 |
| Azure Cosmos DB のパスの解決が、エラー "正しくないアカウント名" または "正しくないデータベース名" で失敗しました。 | 指定されたアカウント名、データベース名、またはコンテナーが見つからないか、指定されたコレクションで分析ストレージが有効になっていません。 |
| Azure Cosmos DB のパスの解決が、エラー "正しくないシークレット値" または "シークレットが null または空" で失敗しました。 | アカウント キーが無効であるか、存在しません。 |
Azure Cosmos DB の文字列型の読み取り中に UTF-8 照合順序の警告が返される
OPENROWSET 列の照合順序のエンコードが UTF-8 でない場合、サーバーレス SQL プールからコンパイル時警告が返されます。 現在のデータベースで実行されるすべての OPENROWSET 関数の既定の照合順序は、次の T-SQL ステートメントを使用して簡単に変更できます。
ALTER DATABASE CURRENT COLLATE Latin1_General_100_CI_AS_SC_UTF8;
文字列述語を使ってデータをフィルター処理するときに、Latin1_General_100_BIN2_UTF8 照合順序を使用すると最適なパフォーマンスが得られます。
Azure Cosmos DB 分析ストアに行が見つからない
Azure Cosmos DB の一部の項目が、OPENROWSET 関数によって返されない場合があります。 次の点に注意してください。
- トランザクション ストアと分析ストアの間には同期遅延があります。 Azure Cosmos DB のトランザクション ストアに入力したドキュメントは、分析ストアに表示されるまでに 2 から 3 分かかる場合があります。
- ドキュメントがスキーマ制約に違反している可能性があります。
クエリで、Azure Cosmos DB の一部の項目に NULL 値が返される
Azure Synapse SQL では、次の場合、トランザクション ストアにある値の代わりに NULL が返されます。
- トランザクション ストアと分析ストアの間には同期遅延があります。 Azure Cosmos DB のトランザクション ストアに入力した値は、分析ストアに表示されるまでに 2 から 3 分かかる場合があります。
- WITH 句の列名またはパス式が間違っている可能性があります。 WITH 句の列名 (または列の型の後のパス式) は、Azure Cosmos DB コレクションのプロパティ名と一致する必要があります。 比較では、"大文字と小文字が区別されます"。 たとえば、
productCodeとProductCodeは異なるプロパティです。 列名が Azure Cosmos DB のプロパティ名と完全に一致することを確認します。 - 1,000 を超えるプロパティや 127 を超える入れ子レベルなど、一部のスキーマ制約に違反している場合、プロパティが分析ストレージに移動されない可能性があります。
- 適切に定義されたスキーマ表現を使っている場合、トランザクション ストア内の値の型が正しくない可能性があります。 適切に定義されたスキーマにより、ドキュメントをサンプリングすることで、各プロパティの型がロックされます。 トランザクション ストアに追加された、型が一致しない値は、間違った値として扱われ、分析ストアに移行されません。
- 完全に忠実なスキーマ表現を使っている場合は、プロパティ名の後に型のサフィックスを追加していることを確認します (例:
$.price.int64)。 参照先のパスに値が表示されない場合は、異なる型のパス (例:$.price.float64) の下に格納されている可能性があります。 詳しくは、完全に忠実なスキーマでの Azure Cosmos DB コレクションのクエリに関する記事をご覧ください。
列に外部データ型との互換性がない
WITH 句に指定された列の型が Azure Cosmos DB コンテナーの型と一致しない場合、エラー Column 'column name' of the type 'type name' is not compatible with the external data type 'type name'. が返されます。 セクション「Azure Cosmos DB から SQL 型へのマッピング」で説明されているように列の型を変更するか、または VARCHAR 型を使用してください。
Azure Cosmos DB のパスの解決がエラーで失敗する
Resolving Azure Cosmos DB path has failed with error 'This request is not authorized to perform this operation'. というエラーが発生する場合は、Azure Cosmos DB でプライベート エンドポイントを使用したかどうかを確認します。 プライベート エンドポイントを使用してサーバーレス SQL プールで分析ストアにアクセスできるようにするには、Azure Cosmos DB 分析ストアのプライベート エンドポイントを構成する必要があります。
Azure Cosmos DB のパフォーマンスの問題
予期しないパフォーマンスの問題が発生している場合は、次のようなベスト プラクティスを適用していることを確認します。
- クライアント アプリケーション、サーバーレス プール、Azure Cosmos DB 分析ストレージを同じリージョンに配置したことを確認する。
- 最適なデータ型で WITH 句を使っていることを確認する。
- 文字列述語を使ってデータをフィルター処理するときに、Latin1_General_100_BIN2_UTF8 照合順序を使用していることを確認する。
- キャッシュされる可能性があるクエリを繰り返している場合は、クエリ結果を Azure Data Lake Storage に格納するために CETAS を使用してみる。
Delta Lake
サーバーレス SQL プールでの Delta Lake のサポートに関して、いくつかの制限事項があります。
- OPENROWSET 関数または外部テーブルの場所で、ルート Delta Lake フォルダーを参照していることを確認します。
- ルート フォルダーには、
_delta_logという名前のサブフォルダーが必要です。_delta_logフォルダーがない場合、クエリは失敗します。 そのフォルダーがない場合は、Apache Spark プールを使用して Delta Lake に変換する必要があるプレーンな Parquet ファイルを参照しています。 - パーティション スキーマを記述するためにワイルドカードを指定しないでください。 Delta Lake パーティションは、Delta Lake クエリによって自動的に識別されます。
- ルート フォルダーには、
- Apache Spark プールに作成された Delta Lake テーブルは、サーバーレス SQL プールで自動的に使用できますが、スキーマは更新されません (パブリック プレビューの制限事項)。 Spark プールを使用して Delta テーブルに列を追加した場合、変更はサーバーレス SQL プール データベースに表示されません。
- 外部テーブルでは、パーティション分割はサポートされていません。 パーティションの除去を使用するには、Delta Lake フォルダーのパーティション分割されたビューを使用します。 この記事で後述する既知の問題と回避策を参照してください。
- サーバーレス SQL プールでは、タイム トラベル クエリはサポートされていません。 履歴データの読み取りには、Synapse Analytics で Apache Spark プールを使用します。
- サーバーレス SQL プールでは、Delta Lake ファイルの更新はサポートされていません。 サーバーレス SQL プールを使用して、最新バージョンの Delta Lake のクエリを実行できます。 Delta Lake の更新には、Synapse Analytics で Apache Spark プールを使います。
- CETAS コマンドを使って、クエリ結果を Delta Lake 形式のストレージに格納することはできません。 CETAS コマンドでは、出力形式として Parquet と CSV のみがサポートされています。
- Synapse Analytics のサーバーレス SQL プールは、Delta リーダー バージョン 1 と互換性があります。
- Synapse Analytics のサーバーレス SQL プールでは、ブルーム フィルターを使うデータセットはサポートされていません。 サーバーレス SQL プールはブルーム フィルターを無視します。
- Delta Lake のサポートは、専用 SQL プールでは使用できません。 Delta Lake ファイルのクエリにサーバーレス SQL プールを使っていることを確認してください。
- サーバーレス SQL プールに関する既知の問題の詳細については、「Azure Synapse Analytics の既知の問題」を参照してください。
サーバーレス サポート Delta 1.0 バージョン
サーバーレス SQL プールは、Delta Lake 1.0 バージョンのみ読み取りします。 サーバーレス SQL プールはレベル 1 のDelta リーダーであり、次の機能はサポートしていません。
- 列マッピングは無視されます。サーバーレス SQL プールは元の列名を返します。
- 削除ベクトルは無視され、削除された行または更新された行の古いバージョンが返されます (おそらく間違った結果)。
- 次の Delta Lake 機能はサポートされていません: V2 チェックポイント、タイムゾーンなしの timestamp、 VACUUM プロトコル チェック
削除ベクターは無視されます
Delta Lake テーブルが Delta ライター バージョン 7 を使用するように構成されている場合、削除された行と更新された行の古いバージョンが Delete Vector (DV) に格納されます。 サーバーレス SQL プールには Delta リーダー 1 レベルがあるため、削除ベクトルは無視されます。サポートされていない Delta Lake バージョンを読み取る際に、誤った結果が生成される可能性があります。
Delta テーブルでの列の名前変更はサポートされていない
サーバーレス SQL プールでは、名前が変更された列を含む Delta Lake テーブルのクエリはサポートされていません。 サーバーレス SQL プールでは、名前が変更された列からデータを読み取ることができません。
Delta テーブル内の列の値が NULL です
Delta リーダー バージョン 2 以降を必要とする Delta データ セットを使用していて、バージョン 1 でサポートされていない機能 (列の名前変更、列の削除、列マッピングなど) を使用している場合、参照される列の値が表示されない可能性があります。
JSON テキストが適切に書式設定されない
このエラーは、サーバーレス SQL プールが Delta Lake トランザクション ログを読み取ることができないことを示します。 次のエラーが表示されることがあります。
Msg 13609, Level 16, State 4, Line 1
JSON text is not properly formatted. Unexpected character '' is found at position 263934.
Msg 16513, Level 16, State 0, Line 1
Error reading external metadata.
Delta Lake データ セットが破損していないことを確認します。 Azure Synapse の Apache Spark プールを使用して、Delta Lake フォルダーの内容を読み取ることができることを確認します。 これにより、_delta_log ファイルが破損していないことを確認します。
回避策
Apache Spark プールを使って Delta Lake データセットにチェックポイントを作成し、クエリを再実行してみます。 チェックポイントによってトランザクションの JSON ログ ファイルが集計され、問題が解決する可能性があります。
データ セットが有効な場合は、サポート チケットを作成して追加情報を提供します。
- 列の追加または削除やテーブルの最適化などの変更を行わないでください。この操作により、Delta Lake トランザクション ログ ファイルの状態が変わる可能性があります。
_delta_logフォルダーの内容を新しい空のフォルダーにコピーします。.parquet dataファイルはコピー "しないでください"。- 新しいフォルダーにコピーした内容を読み取り、同じエラーが発生していることを確認します。
- コピーした
_delta_logファイルの内容を Azure サポートに送信します。
これで、引き続き Spark プールで Delta Lake フォルダーを使用できるようになりました。 この情報の共有が許可されている場合は、Microsoft サポートにコピーしたデータを提供します。 Azure チームは、delta_log ファイルの内容を調査し、考えられるエラーとその回避策に関する詳細情報を提供します。
デルタ ログの解決に失敗した
エラー Resolving Delta logs on path '%ls' failed with error: Cannot parse json object from log folder. は、サーバーレス SQL プールで差分ログを解決できないことを示しています。最も一般的な原因は、Spark 3.3 に追加された checkpointSchema フィールドにより、_delta_log フォルダー内の last_checkpoint_file が 200 バイトを超えていることです。
このエラーを回避するには、次の 2 つのオプションがあります。
- Spark ノートブックで適切な構成を変更し、新しいチェックポイントを生成して、
last_checkpoint_fileが再作成されるようにします。 Azure Databricks を使用している場合、構成の変更は次のようになります。spark.conf.set("spark.databricks.delta.checkpointSchema.writeThresholdLength", 0); - Spark 3.2.1 にダウングレードします。
現在、エンジニアリング チームは Spark 3.3 の完全なサポートに取り組んでいます。
Spark で作成された Delta テーブルがサーバーレス プールに表示されない
注意
Spark で作成された Delta テーブルのレプリケーションはまだパブリック プレビュー段階です。
Spark で Delta テーブルを作成し、サーバーレス SQL プールに表示されない場合は、次の点を確認してください。
- Spark テーブルは遅延して同期されるため、しばらく (通常は 30 秒) 待機します。
- しばらく待ってもサーバーレス SQL プールにテーブルが表示されなかった場合は、Spark Delta テーブルのスキーマを確認します。 複合型またはサーバーレスでサポートされていない型を含む Spark テーブルは使用できません。 同じスキーマを持つ Spark Parquet テーブルをレイク データベースに作成し、そのテーブルがサーバーレス SQL プールに表示されることを確認します。
- テーブルによって参照される Delta Lake フォルダーにワークスペースのマネージド ID がアクセスできることを確認します。 サーバーレス SQL プールでは、ワークスペースのマネージド ID を使用して、ストレージからテーブル列の情報を取得してテーブルを作成します。
Lake データベース
Spark または Synapse デザイナーを使用して作成された Lake データベース テーブルは、クエリ用のサーバーレス SQL プールで自動的に使用できます。 サーバーレス SQL プールを使用して、Spark プールを使用して作成された Parquet、CSV、Delta Lake テーブルに対してクエリを実行し、db_datareader ロールの他のスキーマ、ビュー、プロシージャ、テーブル値関数、Microsoft Entra ユーザーを Lake データベースに追加できます。 考えられる問題については、このセクションを参照してください。
Spark で作成されたテーブルがサーバーレス プールで使用できない
作成されたテーブルは、サーバーレス SQL プールですぐには使用できない場合があります。
- テーブルは、少し遅れてサーバーレス プールで使用できるようになります。 サーバーレス SQL プールにテーブルが表示されるまでに、Spark での作成後、5 から 10 分待機する必要がある場合があります。
- サーバーレス SQL プールでは、Parquet、CSV、Delta の各形式を参照するテーブルのみが使用できます。 その他のテーブルの種類は使用できません。
- サポートされていない列の種類を含むテーブルは、サーバーレス SQL プールでは使用できません。
- Lake データベースの Delta Lake テーブルへのアクセスは、パブリック プレビュー段階です。 このセクションまたは Delta Lake セクションに記載されているその他の問題を確認してください。
Spark で作成された外部テーブルで、サーバーレス プールに予期しない結果が表示されている
ソースの Spark 外部テーブルとサーバーレス プール上のレプリケートされた外部テーブルの間に不一致が発生している可能性があります。 これは、Spark 外部テーブルの作成に使用されるファイルに拡張子がない場合に発生する可能性があります。 適切な結果を得るには、すべてのファイルに .parquet などの拡張子が付いていることを確認します。
レプリケートされたデータベースに対して操作が許可されていない
このエラーは、Lake データベースの変更や、外部テーブル、外部データ ソース、データベース スコープ資格情報、または Lake データベース内の他のオブジェクトの作成を実行している場合に返されます。 これらのオブジェクトは、SQL データベースでのみ作成できます。
Lake データベースは Apache Spark プールからレプリケートされ、Apache Spark によって管理されます。 したがって、T-SQL 言語を使用して SQL Database のようなオブジェクトを作成することはできません。
Lake データベースでは、次の操作のみが許可されます。
dbo以外のスキーマでのビュー、プロシージャ、インライン テーブル値関数 (iTVF) の作成、削除、または変更。- Microsoft Entra ID のデータベース ユーザーの作成と削除。
db_datareaderスキーマのデータベース ユーザーの追加または削除。
Lake データベースでは、それ以外の操作は許可されません。
Note
dbo スキーマでビュー、プロシージャ、関数を作成する (またはスキーマを省略して既定のスキーマを使用する (通常は dbo)) と、エラー メッセージが表示されます。
Lake データベースの Delta テーブルは、サーバーレス SQL プールでは使用できません
ワークスペースのマネージド ID が、Delta フォルダーを含む ADLS ストレージに対する読み取りアクセス権を持っていることを確認します。 サーバーレス SQL プールは、ADLS に配置された Delta ログから Delta Lake テーブル スキーマを読み取り、ワークスペースのマネージド ID を使用して Delta トランザクション ログにアクセスします。
マネージド ID 資格情報を使用して Azure Data Lake Storage を参照するデータ ソースを一部の SQL Database に設定し、マネージド ID を持つデータ ソースの上に外部テーブルを作成して、マネージド ID を持つテーブルがストレージにアクセスできることを確認します。
Lake データベースの Delta テーブルのスキーマが Spark とサーバーレス プールで異なる
サーバーレス SQL プールを使用すると、Spark または Synapse デザイナーを用いて、Lake データベースで作成された Parquet、CSV、Delta テーブルにアクセスできます。 Delta テーブルへのアクセスはまだパブリック プレビュー段階であるため、現在は、サーバーレスでは作成時に Delta テーブルが Spark に同期されますが、Spark の ALTER TABLE ステートメントを使用して後で列を追加した場合、スキーマは更新されません。
これはパブリック プレビューの制限事項です。 この問題を解決するには、テーブルを変更する代わりに、Spark で Delta テーブルを削除して再作成します (可能な場合)。
パフォーマンス
サーバーレス SQL プールでは、データ セットのサイズとクエリの複雑さに基づいて、リソースがクエリに割り当てられます。 クエリに提供されるリソースを変更したり、制限したりすることはできません。 場合によっては、予期しないクエリ パフォーマンスの低下が発生し、根本原因の特定が必要になることがあります。
クエリの実行時間が非常に長い
実行時間が 30 分を超えるクエリがある場合は、クエリからクライアントに返される結果の速度が遅くなります。 サーバーレス SQL プールには、実行に 30 分の制限があります。 それを超える時間は、結果のストリーミングに費やされます。 次の回避策をお試しください。
- Synapse Studio を使用している場合は、他のアプリケーション (SQL Server Management Studio、Azure Data Studio など) で問題を再現します。
- SQL Server Management Studio、Azure Data Studio、Power BI、または他のアプリケーションを使って実行するとクエリが遅い場合は、ネットワークの問題とベスト プラクティスを確認します。
- CETAS コマンドにクエリを入力し、クエリの実行時間を測定します。 CETAS コマンドは、結果を Azure Data Lake Storage に格納し、クライアント接続に依存しません。 CETAS コマンドが元のクエリよりも速く終了する場合は、クライアントとサーバーレス SQL プール間のネットワーク帯域幅を確認します。
Synapse Studio を使用して実行するとクエリが遅くなる
Synapse Studio を使っている場合は、SQL Server Management Studio や Azure Data Studio などのデスクトップ クライアントを使用してみてください。 Synapse Studio は、HTTP プロトコルを使ってサーバーレス SQL プールに接続する Web クライアントです。これは一般的に、SQL Server Management Studio または Azure Data Studio で使用されるネイティブ SQL 接続より低速です。
アプリケーションを使用して実行するとクエリが遅くなる
クエリの実行速度が遅い場合は、次の問題を調べます。
- そのクライアント アプリケーションがサーバーレス SQL プール エンドポイントと併置されていることを確認します。 リージョンをまたいでクエリを実行すると、結果セットの待機時間が長くなり、ストリーミングが低速になることがあります。
- 結果セットの低速ストリーミングの原因となるネットワークの問題がないことを確認します
- クライアント アプリケーションに十分なリソースがあること (たとえば、CPU の使用率が 100% になっていないこと) を確認します。
- ストレージ アカウントまたは Azure Cosmos DB 分析ストレージが、サーバーレス SQL エンドポイントと同じリージョンに配置されていることを確認してください。
リソースの併置に関するベスト プラクティスを参照してください。
クエリの実行時間が大きく異なる
同じクエリを実行していて、クエリの実行時間に違いが見られる場合、この動作を引き起こす可能性のあるいくつかの理由が考えられます。
- これがクエリの初めての実行かどうかを調べます。 初めてクエリを実行するときに、プランを作成するために必要な統計情報が収集されます。 統計情報は、基になるファイルをスキャンすることによって収集されるため、クエリの実行時間が長くなる場合があります。 Synapse Studio では、クエリの前に実行される SQL 要求リストに "全体統計の作成" クエリが表示されます。
- 統計は、しばらくすると有効期限が切れる可能性があります。 サーバーレス プールは統計をスキャンして再構築する必要があるため、定期的にパフォーマンスへの影響が見られる可能性があります。 クエリの前に実行される別の "全体統計の作成" クエリが SQL 要求一覧に表示されている場合があります。
- 長時間クエリを実行したときに、同じエンドポイントで実行されているワークロードがあるかどうかを確認します。 サーバーレス SQL エンドポイントによって、並列実行されているすべてのクエリに均等にリソースが割り当てられるため、クエリが遅延する可能性があります。
接続
サーバーレス SQL プールでは、TDS プロトコルを使って接続し、T-SQL 言語を使ってデータのクエリを実行できます。 SQL Server または Azure SQL Database に接続できるほとんどのツールは、サーバーレス SQL プールにも接続できます。
SQL プールは準備中です。
サーバーレス SQL プールは、長期間使用されないと非アクティブにされます。 アクティブ化は、最初の接続試行など、最初の次のアクティビティで自動的に行われます。 アクティブ化プロセスには、1 回の接続試行間隔よりも少し時間がかかる場合があります。そのため、このエラー メッセージが表示されます。 接続試行を再試行するだけで十分です。
ベスト プラクティスとして、これをサポートするクライアントでは、ConnectionRetryCount と ConnectRetryInterval 接続文字列キーワードを使用して再接続動作を制御します。
エラー メッセージが解決しない場合は、Azure portalからサポート チケットを受け取ります。
Synapse Studio から接続できない
「Synapse Studio」セクションをご覧ください。
ツールから Azure Synapse プールに接続できない
一部のツールには、Azure Synapse サーバーレス SQLプールに接続するために使用できる明示的オプションがあります。 SQL Server または SQL Database に接続するときに使うオプションを使用します。 サーバーレス SQL プールは SQL Server や SQL Database と同じプロトコルを使うため、接続ダイアログに "Synapse" というブランド名を付ける必要はありません。
論理サーバー名のみを入力でき、database.windows.net ドメインがあらかじめ定義されているツールの場合でも、Azure Synapse ワークスペース名の後に -ondemand サフィックスと database.windows.net ドメインを付けます。
セキュリティ
データベースへのアクセス権限、コマンドの実行権限、Azure Data Lake や Azure Cosmos DB ストレージへのアクセス権限が、ユーザーに付与されていることを確認します。
Azure Cosmos DB アカウントにアクセスできない
分析用ストレージにアクセスするには、読み取り専用の Azure Cosmos DB キーを使用する必要があります。そのため、有効期限が切れていないか、再作成されていないかを確認します。
「Azure Cosmos DB のパスの解決がエラーで失敗する」のエラーが発生する場合は、ファイアウォールを構成してあることを確認します。
レイクハウスまたは Spark データベースにアクセスできない
ユーザーがレイクハウスや Spark のデータベースにアクセスできない場合、データベースにアクセスして読み取るためのアクセス許可がユーザーにない可能性があります。 CONTROL SERVER アクセス許可を持つユーザーには、すべてのデータベースへのフル アクセス権があるはずです。 制限付きアクセス許可として、CONNECT ANY DATABASE と SELECT ALL USER SECURABLES の使用を試みる場合があります。
SQL ユーザーが Dataverse テーブルにアクセスできない
Dataverse のテーブルは、呼び出し元の Microsoft Entra ID を使ってストレージにアクセスします。 高いアクセス許可を持つ SQL ユーザーがテーブルからデータを選択しようとしても、テーブルは Dataverse データにアクセスできません。 このシナリオはサポートされていません。
SPI でロールの割り当てが作成されるときに、Microsoft Entra のサービス プリンシパルのサインインが失敗する
別のサービス プリンシパル識別子 (SPI) を使用して SPI または Microsoft Entra アプリのロールの割り当てを作成する場合、または既に作成済みでサインインに失敗した場合は、次のエラーが表示される可能性があります: Login error: Login failed for user '<token-identified principal>'.
サービス プリンシパルのログインは、セキュリティ ID (SID) として、オブジェクト ID ではなくアプリケーション ID を使って作成する必要があります。 サービス プリンシパルには既知の制限があり、別の SPI やアプリに対してロールの割り当てを作成するときに、Azure Synapse が Microsoft Graph からアプリケーション ID をフェッチできないようになっています。
解決策 1
Azure portal>[Synapse Studio]>[管理]>[アクセス制御] に移動し、目的のサービス プリンシパルに Synapse 管理者または Synapse SQL 管理者を手動で追加します。
解決策 2
SQL コードを使って、適切なログインを手動で作成する必要があります。
use master
go
CREATE LOGIN [<service_principal_name>] FROM EXTERNAL PROVIDER;
go
ALTER SERVER ROLE sysadmin ADD MEMBER [<service_principal_name>];
go
解決策 3
PowerShell を使って、サービス プリンシパルの Azure Synapse 管理者を設定することもできます。 Az.Synapse モジュールをインストールしておく必要があります。
解決するには、-ObjectId "parameter" を指定して New-AzSynapseRoleAssignment コマンドレットを使用します。 そのパラメーター フィールドでは、ワークスペース管理者の Azure サービス プリンシパルの資格情報を使って、オブジェクト ID ではなくアプリケーション ID を指定します。
PowerShell スクリプト:
$spAppId = "<app_id_which_is_already_an_admin_on_the_workspace>"
$SPPassword = "<application_secret>"
$tenantId = "<tenant_id>"
$secpasswd = ConvertTo-SecureString -String $SPPassword -AsPlainText -Force
$cred = New-Object -TypeName System.Management.Automation.PSCredential -ArgumentList $spAppId, $secpasswd
Connect-AzAccount -ServicePrincipal -Credential $cred -Tenant $tenantId
New-AzSynapseRoleAssignment -WorkspaceName "<workspaceName>" -RoleDefinitionName "Synapse Administrator" -ObjectId "<app_id_to_add_as_admin>" [-Debug]
Note
この場合、Synapse Data Studio UI には上記のメソッドによって追加されたロールの割り当てが表示されないため、UI にも表示できるように、オブジェクト ID とアプリケーション ID の両方に同時にロールの割り当てを追加することをお勧めします。
New-AzSynapseRoleAssignment -WorkspaceName "<workspaceName>" -RoleDefinitionName "Synapse Administrator" -ObjectId "<object_id_to_add_as_admin>" [-Debug]
検証
サーバーレス SQL エンドポイントに接続し、SID を使った外部ログイン (先ほどのサンプルでは app_id_to_add_as_admin) が作成されていることを確認します。
SELECT name, convert(uniqueidentifier, sid) AS sid, create_date
FROM sys.server_principals
WHERE type in ('E', 'X');
または、設定した管理者アプリを使って、サーバーレス SQL エンドポイントにサインインしてみます。
制約
システムのいくつかの一般的な制約が、ワークロードに影響する可能性があります。
| プロパティ | 制限事項 |
|---|---|
| サブスクリプションあたりの Azure Synapse ワークスペースの最大数 | 制限に関するページを参照してください。 |
| サーバーレス プールあたりのデータベースの最大数 | 100 (Apache Spark プールから同期されたデータベースを含まない)。 |
| Apache Spark プールから同期されたデータベースの最大数 | 制限なし。 |
| データベースあたりのデータベース オブジェクトの最大数 | 1 つのデータベース内のオブジェクトの合計数は 2,147,483,647 以下にする必要があります。 SQL Server データベース エンジンでの制限事項に関するページをご覧ください。 |
| 識別子の最大長 (文字数) | 128。SQL Server データベース エンジンでの制限事項に関するページをご覧ください。 |
| クエリの最大継続時間 | 30 分。 |
| 結果セットの最大サイズ | 最大 400 GB (同時実行クエリ間で共有)。 |
| 最大コンカレンシー | 制限はなく、クエリの複雑さとスキャンされたデータの量によって異なります。 1 つのサーバーレス SQL プールで、軽量クエリを実行している 1,000 個のアクティブ セッションを同時に処理できます。 クエリがより複雑な場合や大量のデータをスキャンする場合は、数が減少します。その場合は、可能であればコンカレンシーを減らし、より長期間にわたってクエリを実行することを検討してください。 |
| 外部テーブル名の最大サイズ | 100 文字。 |
サーバーレス SQL プールにデータベースを作成できない
サーバーレス SQL プールには制限があり、ワークスペースごとに 100 を超えるデータベースを作成することはできません。 オブジェクトを分離して孤立させる必要がある場合は、スキーマを使用します。
エラー CREATE DATABASE failed. User database limit has been already reached を受け取る場合は、1 つのワークスペースでサポートされている最大数のデータベースを作成しています。
異なるテナントのデータを分離するために、個別のデータベースを使用する必要はありません。 すべてのデータは、外部のデータ レイクと Azure Cosmos DB に格納されます。 テーブル、ビュー、関数定義などのメタデータは、スキーマを使って正常に分離できます。 スキーマベースの分離は、データベースとスキーマが同じ概念である Spark でも使用されます。