サーバーレス SQL プールを使用してレイク データベースにアクセスする
Azure Synapse Analytics ワークスペースでは、Spark データ レイク上に 2 種類のデータベースを作成できます。
- Apache Spark ノートブック、データベース テンプレート、または Microsoft Dataverse (以前の Common Data Service) を使って、レイク データの上にテーブルを定義できるレイク データベース。 これらのテーブルは、サーバーレス SQL プールを使用して T-SQL (Transact-SQL) 言語でクエリを実行できます。
- サーバーレス SQL プールを使って、独自のデータベースとテーブルを直接定義できる SQL データベース。 T-SQL の CREATE DATABASE と CREATE EXTERNAL TABLE を使ってオブジェクトを定義し、テーブル上に SQL ビュー、プロシージャ、インラインテーブル値関数を追加できます。
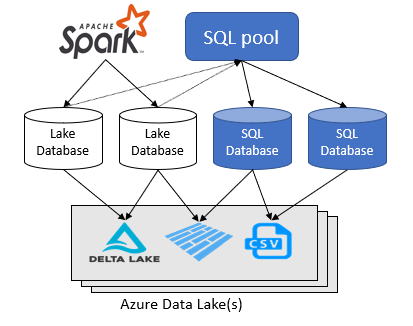
この記事では、Azure Synapse Analytics のサーバーレス SQL プール内のレイク データベースに焦点を当てます。
Azure Synapse Analytics では、Spark またはデータベース デザイナーを使ってレイク データベースとテーブルを作成し、サーバーレス SQL プールを使ってレイク データベース内のデータを分析できます。 Apache Spark プール、レイク データベース テンプレート、または Dataverse で作成されたレイク データベースとテーブル (parquet または CSV ベース) は、サーバーレス SQL プール エンジンでのクエリの実行に自動的に使用できます。 変更されたレイク データベースとテーブルは、しばらくするとサーバーレス SQL プールで使用できるようになります。 Spark またはデータベース デザイナーで行われた変更がサーバーレスに表示されるまで、延期期間があります。
レイク データベースを管理する
Spark によって作成されたレイク データベースを管理するには、Apache Spark プールまたはデータベース デザイナーを使用できます。 たとえば、Spark プール ジョブを使ってレイク データベースを作成または削除します。 サーバーレス SQL プールを使って、レイク データベースまたはレイク データベース内のオブジェクトを作成することはできません。
Spark の default データベースを、default という名前のレイク データベースとして、サーバーレス SQL プールのコンテキストで使用できます。
Note
サーバーレス SQL プールに同じ名前のレイクと SQL データベースを作成することはできません。
レイク データベース内のテーブルは、サーバーレス SQL プールからは変更できません。 レイク データベースを変更するには、データベース デザイナーまたは Apache Spark プールを使います。 サーバーレス SQL プールを使用すると、T-SQL コマンドを使用して、レイク データベースで次の変更を行うことができます。
- レイク データベース内のビュー、プロシージャ、インライン テーブル値関数を追加、変更、削除します。
- データベース スコープの Microsoft Entra ユーザーを追加および削除します。
- db_datareader ロールの Microsoft Entra データベース ユーザーを追加または削除します。 db_datareader ロールの Microsoft Entra データベース ユーザーは、レイク データベース内のすべてのテーブルを読み取るアクセス許可を持っていますが、他のデータベースのデータを読み取ることはできません。
セキュリティ モデル
レイク データベースとテーブルは、2 つのレベルでセキュリティ保護されます。
- 次のいずれかを Microsoft Entra ユーザーに割り当てることにより、基になるストレージ レイヤー:
- Azure ロールベースのアクセス制御 (Azure RBAC)
- Azure の属性ベースのアクセス制御 (Azure ABAC) ロール
- アクセス制御リスト (ACL) のアクセス許可
- Microsoft Entra ユーザーを定義し、レイク データを参照するテーブルからデータを
SELECTするための SQL アクセス許可を付与できる SQL レイヤー。
レイク セキュリティ モデル
レイク データベース ファイルへのアクセスは、ストレージ レイヤーでのレイク アクセス許可を使って制御されます。 Microsoft Entra ユーザーのみがレイク データベース内のテーブルを使用でき、独自の ID を使ってレイク内のデータにアクセスできます。
外部テーブルに使われる基になるデータへのアクセス権を、ユーザー、サービス プリンシパルが割り当てられた Microsoft Entra アプリケーション、セキュリティ グループなどのセキュリティ プリンシパルに付与できます。 データ アクセスの場合は、次の両方のアクセス許可を付与します。
- ファイルに対する
read (R)アクセス許可を付与します (テーブルの基になるデータ ファイルなど)。 - ファイルが格納されているフォルダーと、ルートまでのすべての親フォルダーに対する
execute (X)アクセス許可を付与します。 これらのアクセス許可の詳細については、アクセス制御リスト (ACL) を参照してください。
たとえば、https://<storage-name>.dfs.core.windows.net/<fs>/synapse/workspaces/<synapse_ws>/warehouse/mytestdb.db/myparquettable/ では、セキュリティ プリンシパルに次のものが必要です。
-
<fs>から始まってmyparquettableまでのすべてのフォルダーに対するexecute (X)アクセス許可。 -
myparquettableおよびそのフォルダー内のファイルに対するread (R)アクセス許可。これにより、データベース (同期されたもの、または元のもの) 内のテーブルを読み取ることができます。
セキュリティ プリンシパルに、データベース内でオブジェクトを作成したり、オブジェクトを削除したりする権限が必要な場合は、warehouse フォルダー内のフォルダーとファイルに対する追加の write (W) アクセス許可が必要になります。 データベース内のオブジェクトの変更は、サーバーレス SQL プールからはできず、Spark プールまたはデータベース デザイナーからのみ可能です。
SQL セキュリティ モデル
Azure Synapse ワークスペースには、サーバーレス SQL プールを使ってレイク データベースのクエリを実行できる T-SQL エンドポイントがあります。 データ アクセスに加えて、SQL インターフェイスではテーブルにアクセスできるユーザーを制御できます。 ユーザーがサーバーレス SQL プールを使って共有レイク データベースにアクセスできるようにする必要があります。 レイク データベースにアクセスできるユーザーには、次の 2 種類があります。
- 管理者: サーバーレス SQL プール内で Synapse SQL 管理者ワークスペース ロールまたは sysadmin サーバー レベル ロールを割り当てます。 このロールは、すべてのデータベースを完全に制御できます。 Synapse 管理者と Synapse SQL 管理者のロールも、サーバーレス SQL プール内のすべてのオブジェクトに対するすべてのアクセス許可を既定で持っています。
- ワークスペース閲覧者: サーバーレス SQL プールに対するサーバー レベルのアクセス許可 GRANT CONNECT ANY DATABASE と GRANT SELECT ALL USER SECURABLES をログインに付与します。これにより、ログインは任意のデータベースにアクセスして読み取ることができます。 これは、ユーザーに閲覧者/管理者以外のアクセス権を割り当てる場合に適しています。
- データベース閲覧者: レイク データベースに Microsoft Entra ID からデータベース ユーザーを作成し、それらを db_datareader ロールに追加します。これにより、レイク データベース内のデータを読み取ることができます。
詳細については、共有データベースのアクセス制御の設定を参照してください。
レイク データベースのカスタム SQL オブジェクト
レイク データベースでは、スキーマ、プロシージャ、ビュー、インライン テーブル値関数 (iTVF) などのカスタム T-SQL オブジェクトを作成できます。 カスタム SQL オブジェクトを作成するには、オブジェクトを配置するスキーマを作成する必要があります。 カスタム SQL オブジェクトは、Spark、データベース デザイナー、または Dataverse で定義されたレイク テーブル用に予約されているため、dbo スキーマに配置することはできません。
重要
SQL オブジェクトを配置するカスタム SQL スキーマを作成する必要があります。 カスタム SQL オブジェクトを dbo スキーマに配置することはできません。
dbo スキーマは、もともと Spark またはデータベース デザイナーで作成されたレイク テーブル用に予約されています。
例
レイク データベースに SQL データベース閲覧者を作成する
この例では、共有テーブルを介してデータを読むことができる Microsoft Entra ユーザーをレイク データベースに追加します。 ユーザーは、サーバーレス SQL プールを介してレイク データベースに追加されます。 次に、データを読むことができるように、ユーザーを db_datareader ロールに割り当てます。
CREATE USER [customuser@contoso.com] FROM EXTERNAL PROVIDER;
GO
ALTER ROLE db_datareader
ADD MEMBER [customuser@contoso.com];
ワークスペース レベルのデータ リーダーを作成する
GRANT CONNECT ANY DATABASE と GRANT SELECT ALL USER SECURABLES のアクセス許可を持つログインは、サーバーレス SQL プールを使ってすべてのテーブルを読み取ることができますが、SQL データベースを作成したり、その中のオブジェクトを変更したりすることはできません。
CREATE LOGIN [wsdatareader@contoso.com] FROM EXTERNAL PROVIDER
GRANT CONNECT ANY DATABASE TO [wsdatareader@contoso.com]
GRANT SELECT ALL USER SECURABLES TO [wsdatareader@contoso.com]
このスクリプトを使うと、レイク データベース内の任意のテーブルを読み取ることができる、管理者特権を持たないユーザーを作成できます。
サーバーレス SQL プールを使用して Spark データベースを作成して接続する
まず、ワークスペースに既に作成済みの Spark クラスターを使用して、mytestlakedb という名前の新しい Spark データベースを作成します。 たとえば、次の .NET for Spark ステートメントで Spark C# ノートブックを使用して、これを実現できます。
spark.sql("CREATE DATABASE mytestlakedb")
しばらくすると、サーバーレス SQL プールからレイク データベースを見ることができるようになります。 たとえば、サーバーレス SQL プールから次のステートメントを実行します。
SELECT * FROM sys.databases;
結果に mytestlakedb が含まれていることを確認します。
レイク データベースにカスタム SQL オブジェクトを作成する
次の例では、reports スキーマでカスタム ビュー、プロシージャ、インライン テーブル値関数 (iTVF) を作成する方法を示します。
CREATE SCHEMA reports
GO
CREATE OR ALTER VIEW reports.GreenReport
AS SELECT puYear, puMonth,
fareAmount = SUM(fareAmount),
tipAmount = SUM(tipAmount),
mtaTax = SUM(mtaTax)
FROM dbo.green
GROUP BY puYear, puMonth
GO
CREATE OR ALTER PROCEDURE reports.GreenReportSummary
AS BEGIN
SELECT puYear, puMonth,
fareAmount = SUM(fareAmount),
tipAmount = SUM(tipAmount),
mtaTax = SUM(mtaTax)
FROM dbo.green
GROUP BY puYear, puMonth
END
GO
CREATE OR ALTER FUNCTION reports.GreenDataReportMonthly(@year int)
RETURNS TABLE
RETURN ( SELECT puYear = @year, puMonth,
fareAmount = SUM(fareAmount),
tipAmount = SUM(tipAmount),
mtaTax = SUM(mtaTax)
FROM dbo.green
WHERE puYear = @year
GROUP BY puMonth )
GO