クイック スタート:Synapse ワークスペースを作成する
このクイック スタートでは、Synapse ワークスペースを作成します。残りのチュートリアルに従うことで、専用 SQL プールとサーバーレス Apache Spark プールを作成できます。
前提条件
- Azure サブスクリプションをお持ちでない場合は、開始する前に無料アカウントを作成してください。
- このチュートリアルの手順を完了するには、所有者ロールが割り当てられているリソース グループにアクセスできる必要があります。 このリソース グループで Synapse ワークスペースを作成します。
Azure portal で Synapse ワークスペースを作成する
プロセスを開始する
- Azure portal を開き、Enter キーを押さずに検索バーに「Synapse」と入力します。
- 検索結果の [サービス] で、 [Azure Synapse Analytics] を選択します。
- [作成] を選択して、ワークスペースを作成します。
[基本] タブ > [プロジェクトの詳細]
以下のフィールドを設定します。
- [サブスクリプション] - 任意のサブスクリプションを選択します。
- [リソース グループ] - 任意のリソース グループを使用します。
- [Managed Resource group](マネージド リソース グループ) - 空白のままにします。
[基本] タブ > [ワークスペースの詳細]
以下のフィールドを設定します。
- [ワークスペース名] - グローバルに一意の任意の名前を選択します。 このチュートリアルでは、myworkspace を使用します。
- [リージョン] - クライアント アプリケーションまたはサービス (Azure Virtual Machine、Power BI、Azure Analysis Service など) と、データを含むストレージ (Azure Data Lake Storage、Azure Cosmos DB 分析ストレージ) が配置されているリージョンを選択します。
Note
クライアント アプリケーションやストレージが併置されていないワークスペースは、さまざまなパフォーマンス上の問題の根本原因になる可能性があります。 データやクライアントが複数のリージョンに配置されている場合は、データやクライアントが併置されているリージョンごとに個別のワークスペースを作成できます。
[Data Lake Storage Gen 2 の選択] で、次の操作を行います。
[アカウント名] で、 [新規作成] を選択し、新しいストレージ アカウントに contosolake などの名前を付けます。この名前は一意である必要があります。
ヒント
"Azure Synapse リソース プロバイダー (Microsoft.Synapse) を、選択したサブスクリプションに登録する必要があります" というエラーが表示される場合は、Azure portal を開いて [サブスクリプション] を選択します。 サブスクリプションを選択します。 [設定] リストで、[リソース プロバイダー] を選択します。 Microsoft.Synapse を検索して選択し、[登録] を選択します。
[File system name](ファイル システム名) で、 [新規作成] を選択し、users という名前を付けます。 これにより、users というストレージ コンテナーが作成されます。 ワークスペースでは、このストレージ アカウントを Spark テーブルおよび Spark アプリケーション ログの "プライマリ" ストレージ アカウントとして使用します。
[Data Lake Storage Gen2 アカウント のストレージ BLOB データ共同作成者ロールを自分に割り当てます] ボックスをオンにします。
プロセスを完了する
[確認と作成]>[作成] の順に選択します。 ワークスペースの準備は数分で完了します。
注意
既存の専用 SQL プール (以前の SQL DW) のワークスペース機能を有効にするには、専用の SQL プール (以前の SQL DW) 用のワークスペースを有効にする方法に関するページを参照してください。
Synapse Studio を開く
Azure Synapse ワークスペースが作成された後、Synapse Studio を開く方法は 2 つあります。
Azure portal で Synapse ワークスペースを開き、Synapse ワークスペースの [概要] セクションで、[Synapse Studio の起動] ボックスの [開く] を選択します。
https://web.azuresynapse.netにアクセスし、ワークスペースにサインインします。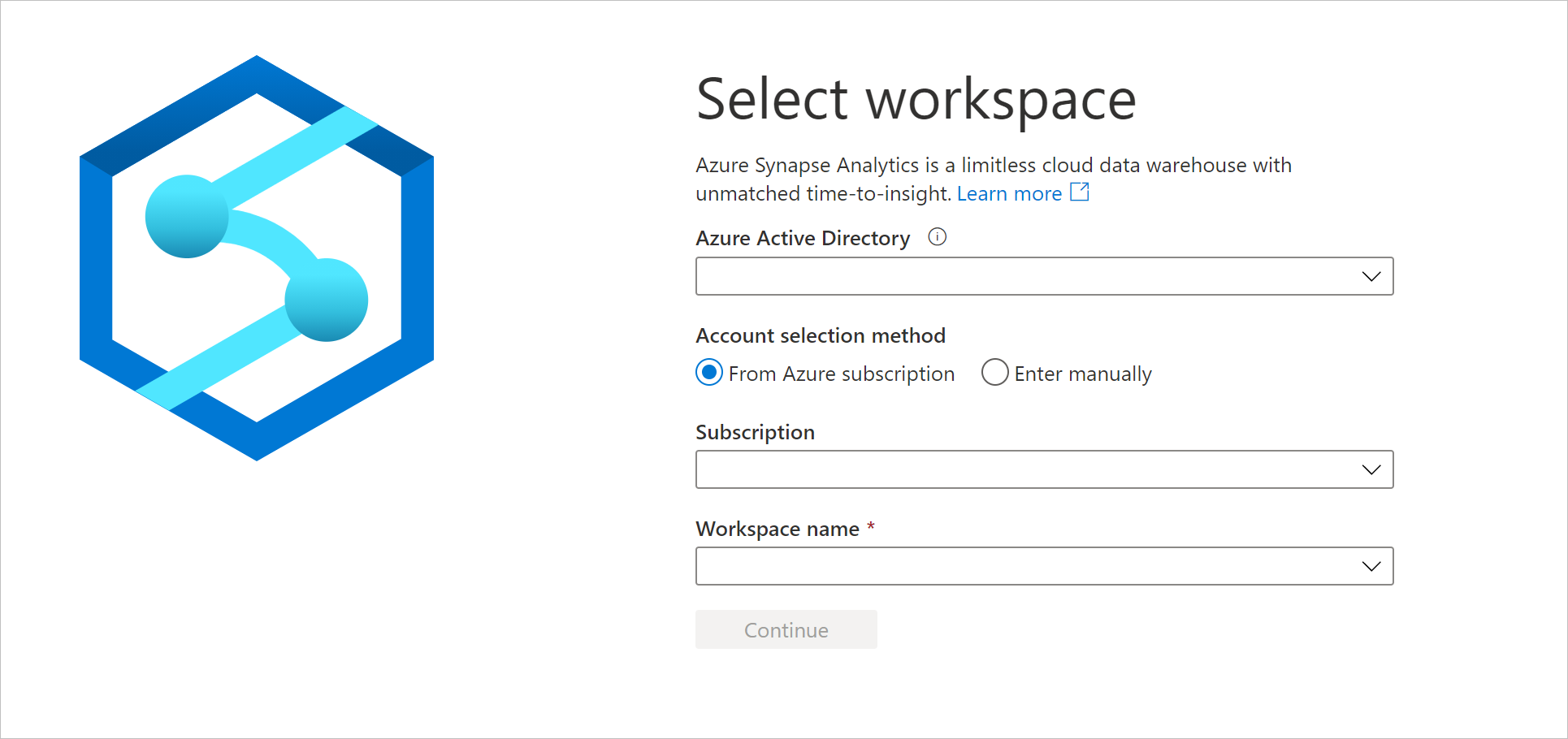
注意
ワークスペースにサインインするには、2 つの アカウント選択方法があります。 1 つは Azure サブスクリプションからの方法、もう 1 つは手動による入力です。 Synapse Azure ロール以上のレベルの Azure ロールがある場合は、両方の方法を使用してワークスペースにログインできます。 関連する Azure ロールがなく、Synapse RBAC ロールとして許可されている場合、ワークスペースにログインする唯一の方法は 手動の入力 しかありません。 Synapse RBAC の詳細については、「Synapse ロールベースのアクセス制御 (RBAC) とは」を参照してください。
プライマリ ストレージ アカウントにサンプル データを配置する
このファースト ステップ ガイドの多くの例では、ニューヨーク市のタクシー データから成る 100,000 行の小さなサンプル データセットを使います。 まず、ワークスペース用に作成したプライマリ ストレージ アカウントにこれを配置します。
- NYC Taxi - グリーン乗車データセットをお使いのコンピューターにダウンロードします。
- リンクから元のデータセットの場所に移動し、特定の年を選んで、Parquet 形式のグリーン タクシー乗車レコードをダウンロードします。
- ダウンロードしたファイルの名前を NYCTripSmall.parquet に変更します。
- Synapse Studio で、データ ハブに移動します。
- [リンク済み] を選択します。
- [Azure Data Lake Storage Gen2] カテゴリの下に、myworkspace ( プライマリ - contosolake ) のような名前の項目が表示されます。
- [users (Primary)](ユーザー (プライマリ)) という名前のコンテナーを選択します。
- [アップロード] を選択し、ダウンロードした
NYCTripSmall.parquetファイルを選択します。
Parquet ファイルをアップロードしたら、等価な 2 つの URI で使用できるようになります。
https://contosolake.dfs.core.windows.net/users/NYCTripSmall.parquetabfss://users@contosolake.dfs.core.windows.net/NYCTripSmall.parquet
ヒント
このチュートリアルの後の例では、UI の contosolake を、ワークスペースで選択したプライマリ ストレージ アカウントの名前で置き換えてください。