クイックスタート: サーバーレス SQL プールを使用する
Synapse サーバーレス SQL プールは、Azure Storage に配置されたファイルに対して SQL クエリを実行できるサーバーレス クエリ サービスです。 このクイックスタートでは、サーバーレス SQL プールを使用してさまざまな種類のファイルにクエリを実行する方法について説明します。 サポートされている形式の一覧については、OPENROWSET のページを参照してください。
このクイックスタートでは、CSV、Apache Parquet、および JSON ファイルに対してクエリを実行します。
前提条件
クエリを発行する SQL クライアントを選択します。
- Azure Synapse Studio は、ストレージ内のファイルを参照したり、SQL クエリを作成したりするために使用できる Web ツールです。
- Azure Data Studio は、オンデマンド データベースで SQL クエリとノートブックを実行できるクライアント ツールです。
- SQL Server Management Studio は、オンデマンド データベースで SQL クエリを実行できるクライアント ツールです。
このクイックスタートのパラメーター:
| パラメーター | 説明 |
|---|---|
| サーバーレス SQL プール サービス エンドポイント アドレス | サーバー名として使用されます |
| サーバーレス SQL プール サービス エンドポイント リージョン | サンプルで使用するストレージを決定するために使用されます |
| エンドポイント アクセスのユーザー名とパスワード | エンドポイントへのアクセスに使用されます |
| ビューの作成に使用するデータベース | サンプルの開始点として使用されるデータベース |
初回セットアップ
サンプルを使用する前に、次の作業を行います。
- ビューのデータベースを作成します (ビューを使用する場合)
- サーバーレス SQL プールがストレージ内のファイルにアクセスするために使用する資格情報を作成します
データベースの作成
独自のデモ用データベースを作成します。 このデータベースは、ビューの作成に使用するほか、この記事のサンプル クエリでも使用します。
注意
このデータベースは、実際のデータではなくビューのメタデータに対してのみ使用されます。 クイックスタートで後で使用するデータベース名を書き留めておきます。
次のクエリを使用します。mydbname は任意の名前に変更します。
CREATE DATABASE mydbname
データ ソースの作成
サーバーレス SQL プールを使用してクエリを実行するには、ストレージ内のファイルにアクセスするためにサーバーレス SQL プールが使用できるデータ ソースを作成します。 次のコード スニペットを実行し、このセクションのサンプルで使用するデータ ソースを作成します。
-- create master key that will protect the credentials:
CREATE MASTER KEY ENCRYPTION BY PASSWORD = <enter very strong password here>
-- create credentials for containers in our demo storage account
CREATE DATABASE SCOPED CREDENTIAL sqlondemand
WITH IDENTITY='SHARED ACCESS SIGNATURE',
SECRET = 'sv=2022-11-02&ss=b&srt=co&sp=rl&se=2042-11-26T17:40:55Z&st=2024-11-24T09:40:55Z&spr=https&sig=DKZDuSeZhuCWP9IytWLQwu9shcI5pTJ%2Fw5Crw6fD%2BC8%3D'
GO
CREATE EXTERNAL DATA SOURCE SqlOnDemandDemo WITH (
LOCATION = 'https://sqlondemandstorage.blob.core.windows.net',
CREDENTIAL = sqlondemand
);
CSV ファイルに対してクエリを実行する
次の図は、クエリを実行するファイルのプレビューです。
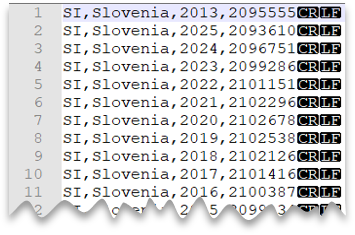
次のクエリは、ヘッダー行を含まず、Windows スタイルの改行があり、コンマ区切りの列が存在する CSV ファイルを読み取る方法を示しています。
SELECT TOP 10 *
FROM OPENROWSET
(
BULK 'csv/population/*.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0'
)
WITH
(
country_code VARCHAR (5)
, country_name VARCHAR (100)
, year smallint
, population bigint
) AS r
WHERE
country_name = 'Luxembourg' AND year = 2017
クエリのコンパイル時にスキーマを指定できます。 その他の例については、CSV ファイルに対してクエリを実行する方法を参照してください。
Parquet ファイルのクエリ
次のサンプルは、Parquet ファイルのクエリを実行するための自動スキーマ推論機能を示しています。 これはスキーマを指定せずに 2017 年 9 月の行の数を返します。
注意
Parquet ファイルを読み取るときに OPENROWSET WITH 句で列を指定する必要はありません。 この場合、サーバーレス SQL プールは Parquet ファイル内のメタデータを利用し、名前で列をバインドします。
SELECT COUNT_BIG(*)
FROM OPENROWSET
(
BULK 'parquet/taxi/year=2017/month=9/*.parquet',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT='PARQUET'
) AS nyc
parquet ファイルのクエリの実行に関する詳細を参照してください。
JSON ファイルのクエリ
JSON サンプル ファイル
ファイルは json コンテナーの books フォルダーに格納され、次の構造を持つ 1 つの book エントリを含みます。
{
"_id":"ahokw88",
"type":"Book",
"title":"The AWK Programming Language",
"year":"1988",
"publisher":"Addison-Wesley",
"authors":[
"Alfred V. Aho",
"Brian W. Kernighan",
"Peter J. Weinberger"
],
"source":"DBLP"
}
JSON ファイルのクエリ
次のクエリでは、JSON_VALUE を使用して、「Probabilistic and Statistical Methods in Cryptology, An Introduction by Selected articles」という書籍からスカラー値 (タイトル、出版社) を取得する方法について説明しています。
SELECT
JSON_VALUE(jsonContent, '$.title') AS title
, JSON_VALUE(jsonContent, '$.publisher') as publisher
, jsonContent
FROM OPENROWSET
(
BULK 'json/books/*.json',
DATA_SOURCE = 'SqlOnDemandDemo'
, FORMAT='CSV'
, FIELDTERMINATOR ='0x0b'
, FIELDQUOTE = '0x0b'
, ROWTERMINATOR = '0x0b'
)
WITH
( jsonContent varchar(8000) ) AS [r]
WHERE
JSON_VALUE(jsonContent, '$.title') = 'Probabilistic and Statistical Methods in Cryptology, An Introduction by Selected Topics'
重要
ここでは、JSON ファイル全体を単一の行と列として読み取ります。 そのため、FIELDTERMINATOR、FIELDQUOTE、ROWTERMINATOR は、ファイル内に存在しないと考えられる 0x0b に設定しています。
次のステップ
これで、次の記事に進む準備ができました。