Azure HDInsight のビジネス継続性アーキテクチャ
この記事では、Azure HDInsight で検討できる事業継続性アーキテクチャの例をいくつか示します。 災害発生時の機能低下に対する許容度は、アプリケーションによって異なるビジネス上の意思決定です。 アプリケーションによっては、一定期間、使用できなくなるか、または機能の制限や処理の遅延がありながら部分的に使用するということが許容される場合があります。 他のアプリケーションでは、機能の制限が一切許容されない場合もあります。
注意
この記事に記載されているアーキテクチャは、決して網羅的なものではありません。 求められる事業継続性、運用の複雑さ、および保有コストなどを客観的に判断し、独自のアーキテクチャを設計する必要があります。
Apache Hive と Interactive Query
HDInsight Hive および Interactive Query クラスターでは、事業継続性を実現するために Hive Replication V2 を使用することをお勧めします。 レプリケートする必要があるスタンドアロンの Hive クラスターの永続的な部分は、ストレージ レイヤーと Hive メタストアです。 Enterprise セキュリティ パッケージを使用するマルチユーザー シナリオの Hive クラスターには、Microsoft Entra Domain Services と Ranger メタストアが必要です。
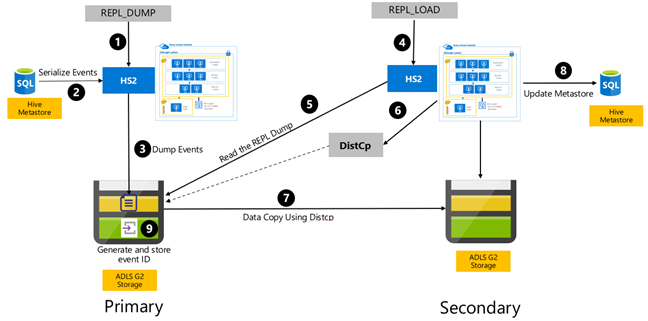
Hive のイベントベースのレプリケーションは、プライマリ クラスターとセカンダリ クラスターの間で構成されます。 これには、ブートストラップと増分実行という 2 つの異なるフェーズが含まれます。
ブートストラップにより、Hive ウェアハウス全体 (Hive メタストアの情報を含む) が、プライマリからセカンダリへレプリケートされます。
増分実行はプライマリ クラスターで自動的に実行され、増分実行中に生成されたイベントはセカンダリ クラスターで再生されます。 セカンダリ クラスターでは、レプリケーションの実行後にセカンダリ クラスターとプライマリ クラスターのイベントが整合するよう、プライマリ クラスターで生成されたイベントに追い付きます。
セカンダリ クラスターが必要になるのは、分散コピー (DistCp) を実行するレプリケーション時のみですが、ストレージとメタストアは永続化されている必要があります。 レプリケーションの前に、スクリプト化されたセカンダリ クラスターをオンデマンドで起動し、その上でレプリケーション スクリプトを実行して、レプリケーションが正常に終了した後に破棄することもできます。
セカンダリ クラスターは通常、読み取り専用です。 セカンダリ クラスターで読み取り/書き込みを行うよう設定することはできますが、これにより、セカンダリ クラスターからプライマリ クラスターに変更をレプリケートすることになるため、複雑さが増します。
Hive のイベントベースのレプリケーションの RPO および RTO
RPO: データの損失は、最後に成功したプライマリからセカンダリへの増分レプリケーション イベントに制限されます。
RTO: 障害が発生してから、セカンダリとのアップストリームおよびダウンストリームのトランザクションが再開されるまでの時間。
Apache Hive と Interactive Query のアーキテクチャ
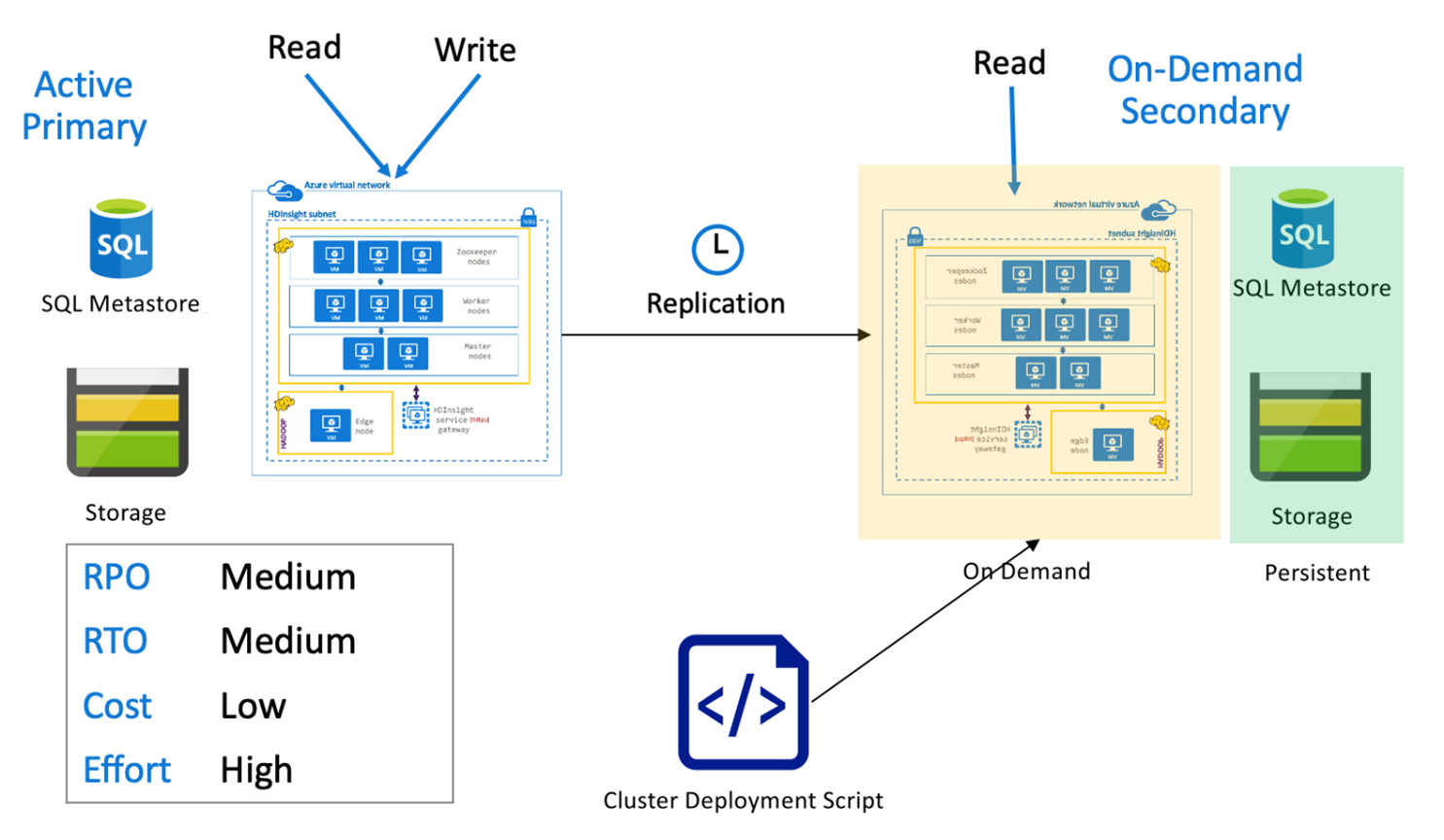
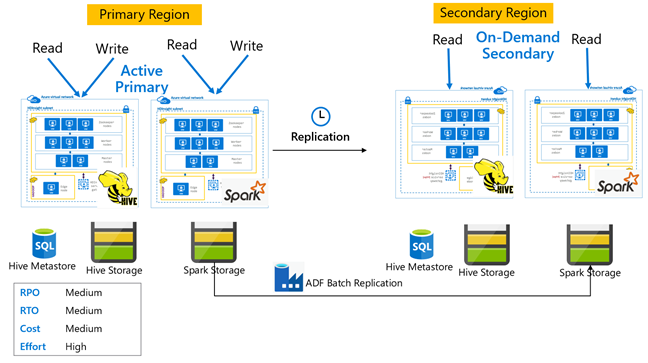
オンデマンド セカンダリを備えた Hive アクティブ プライマリ
"オンデマンド セカンダリを備えたアクティブ プライマリ" のアーキテクチャでは、通常の操作中、アプリケーションからアクティブなプライマリ リージョンに書き込みが行われ、セカンダリ リージョンではクラスターがプロビジョニングされていません。 セカンダリ リージョンの SQL メタストアとストレージは永続化されており、HDInsight クラスターは、スケジュールされた Hive レプリケーションが実行される前にのみ、オンデマンドでスクリプト化およびデプロイされます。
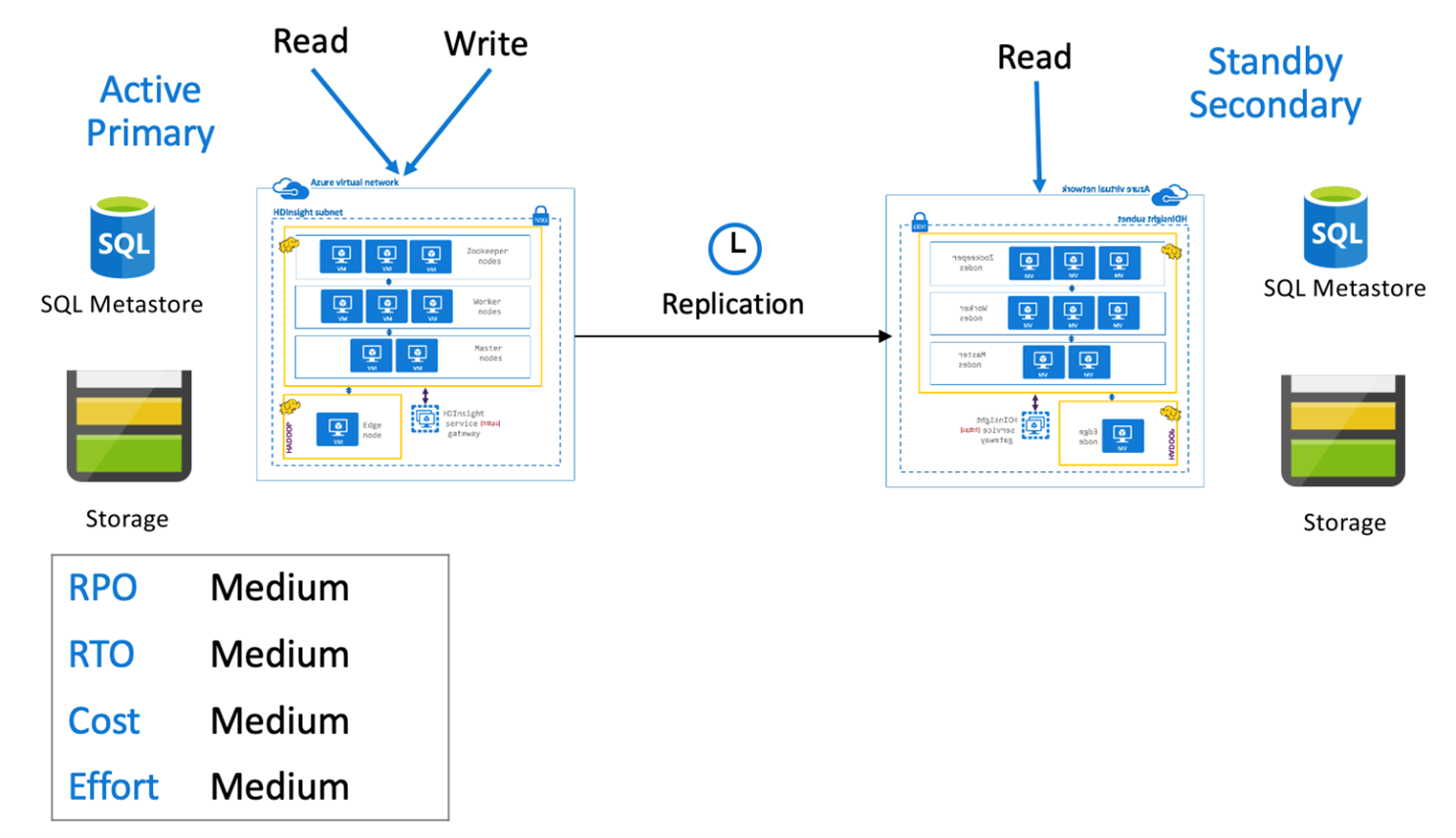
スタンバイ セカンダリを備えた Hive アクティブ プライマリ
"スタンバイ セカンダリを備えたアクティブ プライマリ" では、通常の操作中、アプリケーションからアクティブなプライマリ リージョンへ書き込みが行われ、読み取り専用モードのスケールダウンされたスタンバイ セカンダリ クラスターが実行されます。 通常の操作中は、リージョン固有の読み取り操作をセカンダリにオフロードすることができます。
Hive レプリケーションとコード サンプルの詳細については、Azure HDInsight クラスターでの Apache Hive レプリケーションに関する記事を参照してください。
Apache Spark
Spark ワークロードには 必ずしも Hive コンポーネントが含まれるとは限りません。 Spark SQL ワークロードで Hive からデータを読み書きできるようにするため、HDInsight Spark クラスターでは、同じリージョンの Hive または Interactive Query クラスターと Hive カスタム メタストアが共有になっています。 このようなシナリオでは、Spark ワークロードのリージョン間レプリケーションを行うには、Hive メタストアとストレージのレプリケーションも行う必要があります。 このセクションのフェールオーバー シナリオは、次の両方に適用されます。
- HDInsight Interactive Query クラスターを使用した、Hive Warehouse Connector (HWC) セットアップを使用した ACID テーブル上の Spark SQL。
- HDInsight Hadoop クラスターを使用した非 ACID テーブルの Spark SQL ワークロード。
Spark がスタンドアロン モードで動作するシナリオでは、キュレーションされたデータと保存された Spark Jars (Livy ジョブ用) を、Azure Data Factory の DistCP を使用して、プライマリ リージョンからセカンダリ リージョンに定期的にレプリケートする必要があります。
バージョン コントロール システムを使用して、プライマリ クラスターやセカンダリ クラスターに簡単にデプロイできる場所に Spark ノートブックやライブラリを保管することをお勧めします。 プライマリまたはセカンダリ ワークスペースに適切なデータ マウントを読み込むため、ノートブック ベースおよびノートブック ベース以外のソリューションの準備ができていることを確認してください。
HDInsight でネイティブに提供されるものを超える顧客固有のライブラリがある場合は、それらを追跡して、定期的にスタンバイ セカンダリ クラスターに読み込む必要があります。
Apache Spark レプリケーションの RPO と RTO
RPO: データの損失は、最後に成功したプライマリからセカンダリへの増分レプリケーション (Spark および Hive) に制限されます。
RTO: 障害が発生してから、セカンダリとのアップストリームおよびダウンストリームのトランザクションが再開されるまでの時間。
Apache Spark アーキテクチャ
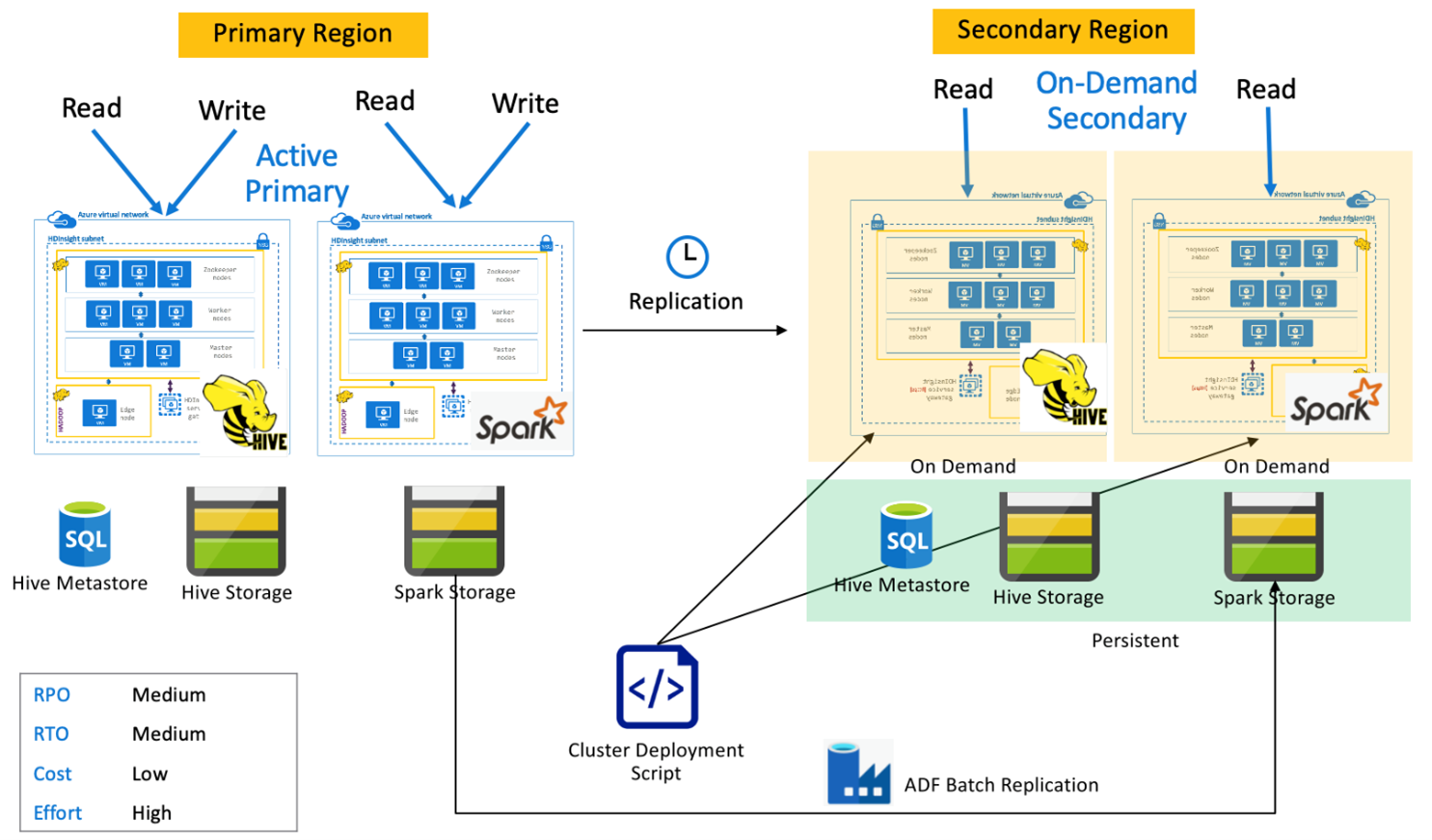
オンデマンド セカンダリを備えた Spark アクティブ プライマリ
通常の操作中は、アプリケーションからプライマリ リージョンにある Spark および Hive クラスターへ読み込みと書き込みが行われ、セカンダリ リージョンではクラスターがプロビジョニングされていません。 セカンダリ リージョンにある SQL メタストア、Hive ストレージ、および Spark ストレージは永続化されています。 Spark と Hive クラスターは、オンデマンドでスクリプト化およびデプロイされます。 Hive レプリケーションは Hive ストレージと Hive メタストアをレプリケートするために使用され、Azure Data Factory の DistCP はスタンドアロンの Spark ストレージをコピーするために使用されます。 依存関係の DistCp の計算のため、各 Hive レプリケーションの実行の前に Hive クラスターをデプロイする必要があります。
スタンバイ セカンダリを備えた Spark アクティブ プライマリ
通常の操作中は、アプリケーションからプライマリ リージョンの Spark と Hive クラスターに対して読み取りと書き込みが行われ、読み取り専用モードのスケールダウンされたスタンバイ状態の Hive および Spark クラスターがセカンダリ リージョンで実行されます。 通常の操作中は、リージョン固有の Hive および Spark の読み取り操作をセカンダリにオフロードすることができます。
Apache HBase
HBase エクスポートと HBase レプリケーションは、HDInsight HBase クラスター間で事業継続性を実現するための一般的な方法です。
HBase エクスポートは、HBase エクスポート ユーティリティを使用して、プライマリ HBase クラスターからその基になる Azure Data Lake Storage Gen 2 ストレージにテーブルをエクスポートするバッチ レプリケーション プロセスです。 エクスポートされたデータには、セカンダリ HBase クラスターからアクセスして、テーブル (セカンダリにあらかじめ存在している必要があります) にインポートすることができます。 HBase のエクスポートはテーブル レベルの細かさを提供しますが、増分更新の場合、エクスポート オートメーション エンジンによって、各実行に含まれる増分行の範囲が制御されます。 詳細については、HDInsight の HBase バックアップおよびレプリケーションに関するページを参照してください。
HBase レプリケーションでは、完全に自動化された方法で HBase クラスター間の凖リアルタイム レプリケーションが使用されます。 レプリケーションはテーブル レベルで実行されます。 すべてのテーブル、あるいは特定のテーブルをレプリケーションの対象にすることができます。 HBase レプリケーションは結果整合性です。つまり、プライマリ リージョンのテーブルに対する最新の編集が、即座にすべてのセカンダリで利用できるとは限らないということです。 セカンダリは、結果的にプライマリと整合することが保証されています。 HBase レプリケーションは、以下の場合に、2 つ以上の HDInsight HBase クラスター間で設定できます。
- プライマリとセカンダリが、同じ仮想ネットワーク内に存在している。
- プライマリとセカンダリが、同じリージョン内の異なるピアリングされた VNet に存在している。
- プライマリとセカンダリが、異なるリージョン内の、異なるピアリングされた VNet に存在している。
詳細については、「Azure 仮想ネットワーク内で Apache HBase クラスターのレプリケーションを設定する」を参照してください。
HBase クラスターのバックアップを実行するには、hbase フォルダのコピー、テーブルのコピー、スナップショットなど、他にもいくつかの方法があります。
HBase の RPO と RTO
HBase エクスポート
- RPO: データの損失は、最後に成功したプライマリからセカンダリへのバッチ増分インポートに制限されます。
- RTO: プライマリに障害が発生してから、セカンダリで I/O 操作が再開されるまでの時間。
HBase レプリケーション
- RPO: データの損失は、セカンダリで受信した最後の WalEdit の転送分に限定されます。
- RTO: プライマリに障害が発生してから、セカンダリで I/O 操作が再開されるまでの時間。
HBase アーキテクチャ
HBase レプリケーションは、次の 3 つのモードで設定できます:リーダー/フォロワー、リーダー/リーダー、および循環。
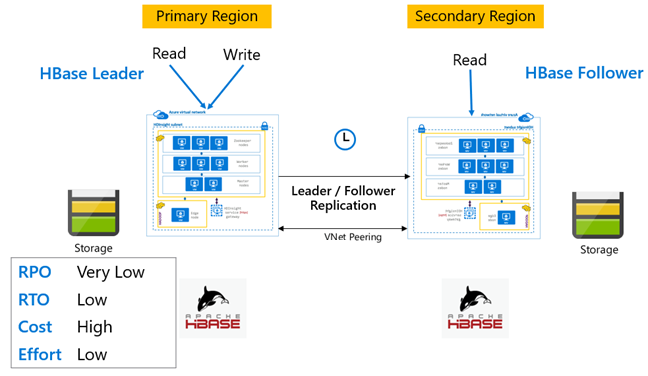
HBase レプリケーション: リーダー/フォロワー モデル
このリージョンをまたがるセットアップでは、レプリケーションはプライマリ リージョンからセカンダリ リージョンへ一方向で行われます。 一方向のレプリケーションでは、プライマリ上のすべてのテーブルまたは特定のテーブルを識別できます。 通常の操作中は、セカンダリ クラスターを使用して、そのリージョン内で読み取り要求を処理できます。
セカンダリ クラスターは、独自のテーブルをホストできる通常の HBase クラスターとして動作し、リージョンのアプリケーションからの読み取りと書き込みを行うことができます。 ただし、レプリケートされたテーブルや、セカンダリにネイティブなテーブルへの書き込みは、プライマリにはレプリケートされません。
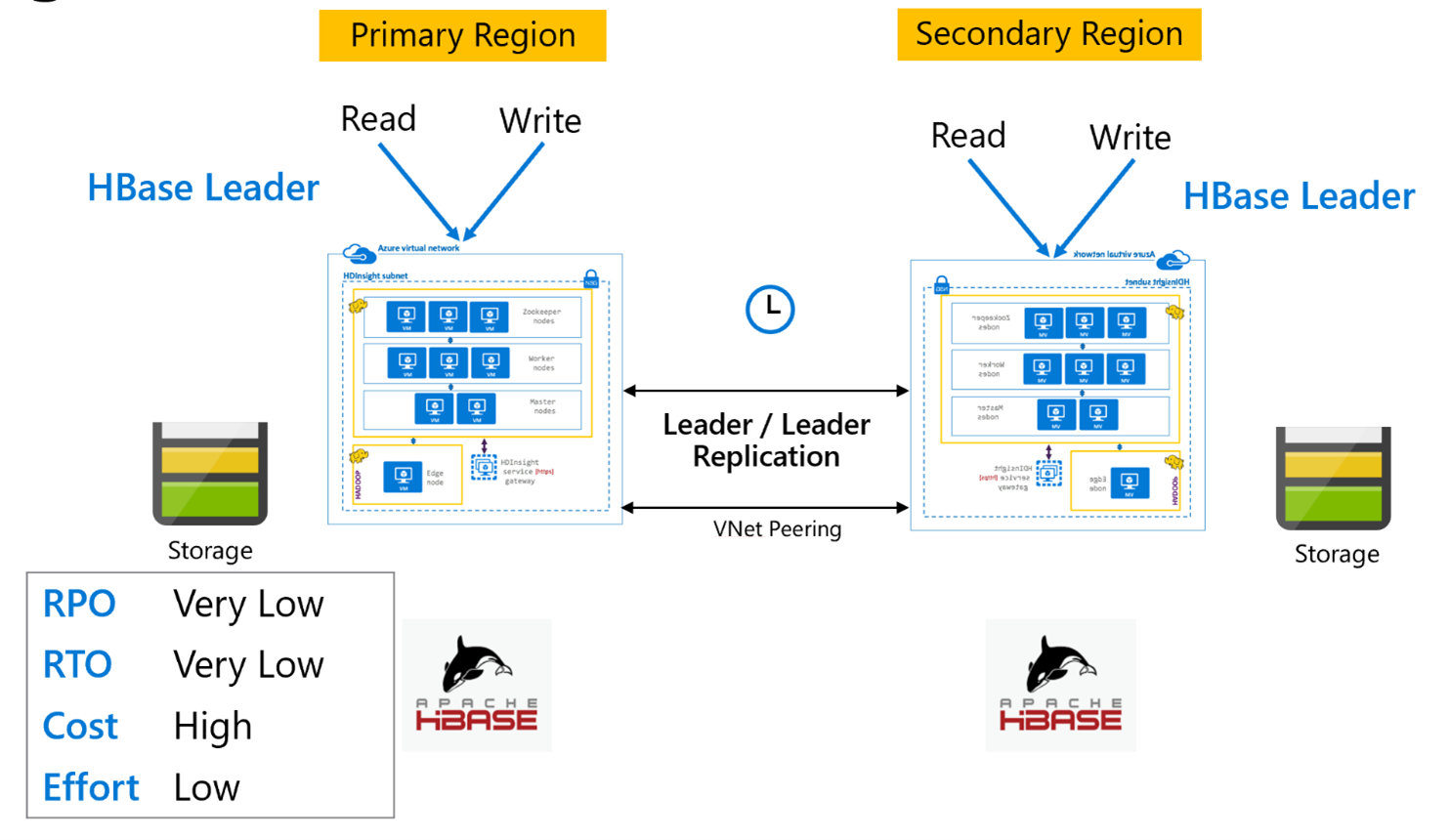
HBase レプリケーション: リーダー モデル
このリージョンをまたがるセットアップは、プライマリ リージョンとセカンダリ リージョンの間でレプリケーションが双方向に行われることを除けば、一方向のセットアップとよく似ています。 アプリケーションでは、読み取り/書き込みモードで両方のクラスターを使用でき、更新内容はそれらの間で非同期に交換されます。
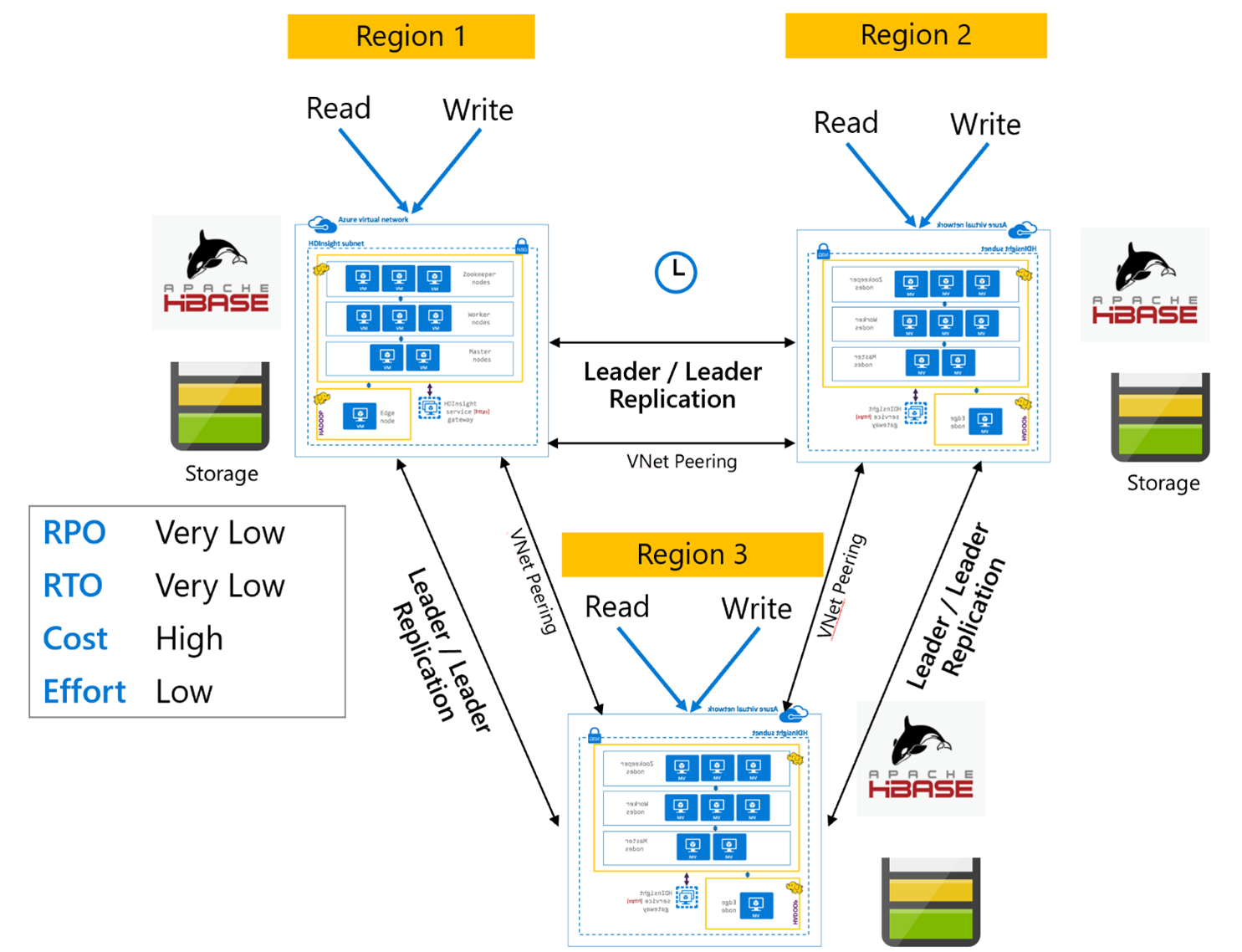
HBase レプリケーション:複数リージョンまたは循環
複数リージョン/循環レプリケーション モデルは HBase レプリケーションの拡張であり、リージョン固有の HBase クラスターの読み取りと書き込みが可能な複数のアプリケーションを含む、グローバル冗長 HBase アーキテクチャを作成するために使用できます。 クラスターは、ビジネス要件に応じて、リーダー/リーダーまたはリーダー/フォロワーのさまざまな組み合わせで設定することができます。
Apache Kafka
複数のリージョンにわたる可用性を提供するため、HDInsight 4.0 では Kafka MirrorMaker がサポートされています。これを使用すると、別のリージョンでプライマリ Kafka クラスターのセカンダリ レプリカを維持することができます。 MirrorMaker は、プライマリ クラスター内の特定のトピックから消費し、セカンダリ内の同じ名前のトピックへ生成する、大まかなコンシューマーとプロデューサーのペアとして機能します。 MirrorMaker を使用した高可用性ディザスター リカバリーのためのクラスター間レプリケーションは、プロデューサーとコンシューマーをレプリカ クラスターにフェールオーバーさせる必要があることを前提にしています。 詳細については、「MirrorMaker を使用して HDInsight 上の Kafka に Apache Kafka トピックをレプリケートする」を参照してください
レプリケーションが開始された時点のトピックの有効期間によっては、MirrorMaker トピックのレプリケーションにより、ソースとレプリカのトピックの間で異なるオフセットが発生する可能性があります。 HDInsight Kafka クラスターでは、個々のクラスター レベルで使用できる高可用性機能であるトピック パーティション レプリケーションもサポートされています。
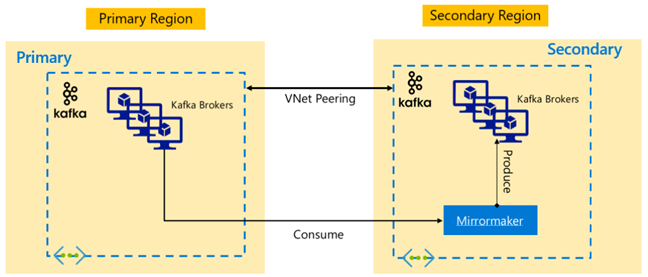
Apache Kafka アーキテクチャ
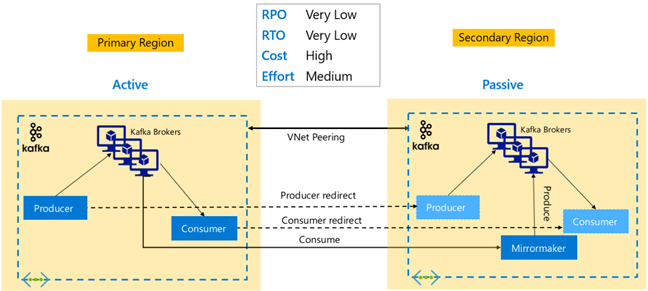
Kafka レプリケーション:アクティブ/パッシブ
アクティブ/パッシブ セットアップを使用すると、アクティブからパッシブへの非同期の一方向ミラーリングが可能になります。 プロデューサーとコンシューマーでは、アクティブおよびパッシブ クラスターが存在することを認識し、アクティブが失敗した場合にパッシブにフェールオーバーする準備ができている必要があります。 次に、アクティブ/パッシブ セットアップの長所と短所をいくつか示します。
長所:
- クラスター間のネットワーク待機時間が、アクティブなクラスターのパフォーマンスに影響しない。
- 一方向のレプリケーションが持つ簡潔さ。
短所:
- パッシブ クラスターが十分に活用されないままになる可能性がある。
- アプリケーション プロデューサーとコンシューマーにフェールオーバー認識を組み込むことで、設計の複雑さが増す。
- アクティブ クラスターのエラー発生時にデータが失われる可能性がある。
- アクティブとパッシブ クラスター間のトピックの結果整合性。
- プライマリへのフェールバックにより、トピック内のメッセージに不整合が生じる可能性がある。
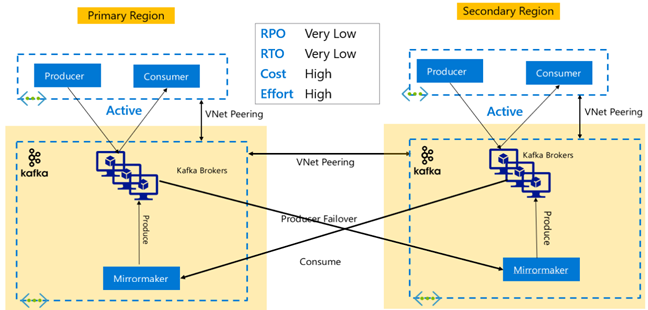
Kafka レプリケーション:アクティブ/アクティブ
アクティブ/アクティブ セットアップには、MirrorMaker を使用した双方向の非同期レプリケーションが可能な、リージョンが異なる 2 つの VNet ピアリング HDInsight Kafka クラスターが含まれます。 この設計では、プライマリのコンシューマーによって消費されるメッセージはセカンダリのコンシューマーでも使用でき、その逆も同様です。 次に、アクティブ/アクティブ セットアップの長所と短所をいくつか示します。
長所:
- 状態が複製されるため、フェールオーバーとフェールバックの実行が簡単。
短所:
- セットアップ、管理、および監視は、アクティブ/パッシブよりも複雑。
- 循環レプリケーションの問題に対処する必要がある。
- 双方向レプリケーションにより、リージョンのデータ エグレス コストが高くなる。
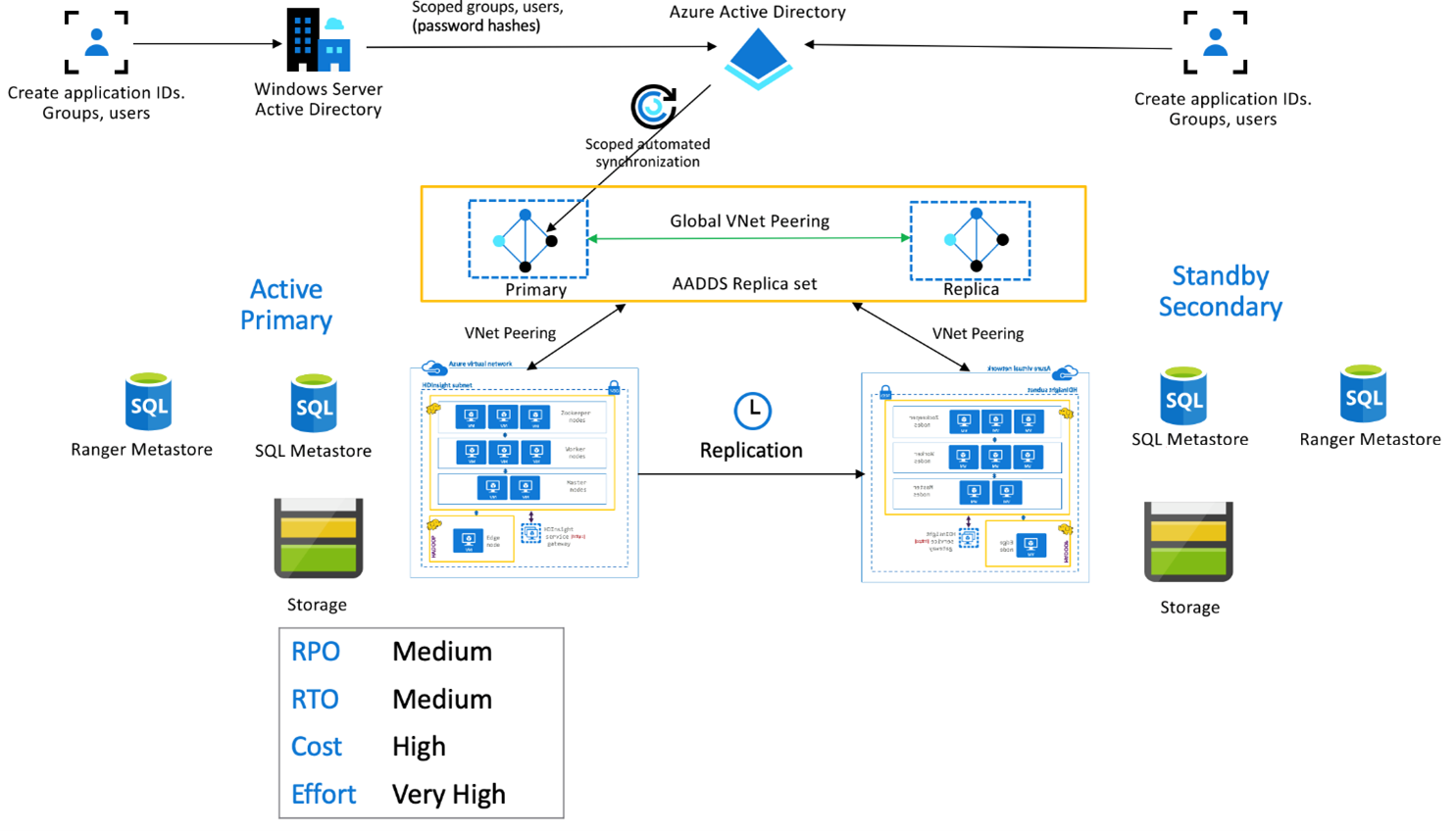
HDInsight Enterprise セキュリティ パッケージ
このセットアップは、プライマリとセカンダリの両方でマルチユーザー機能を有効にし、Microsoft Entra Domain Services レプリカ セットでユーザーが両方のクラスターへの認証を行うことができるようにするために使われます。 通常の操作中は、ユーザーが読み取り操作に制限されるように、Ranger ポリシーをセカンダリに設定する必要があります。 次のアーキテクチャでは、ESP が有効になっている Hive のアクティブ プライマリ (スタンバイ セカンダリ) のセットアップを示します。
Ranger メタストア レプリケーション:
Ranger メタストアは、データ承認を制御するための Ranger ポリシーを永続的に格納して提供するために使用されます。 Ranger ポリシーはプライマリとセカンダリで独立して維持し、セカンダリは読み取りレプリカとして維持することをお勧めします。
要件でプライマリとセカンダリの間で Ranger ポリシーを同期させておくことが求められる場合は、Ranger Import/Export を使用して、プライマリからセカンダリへ Ranger ポリシーを定期的にバックアップおよびインポートします。
プライマリとセカンダリの間で Ranger ポリシーをレプリケートすると、セカンダリが書き込み可能になり、セカンダリへの誤った書き込みが発生して、データに一貫性がなくなる可能性があります。
次のステップ
この記事で説明した項目の詳細については、次を参照してください。