Azure HDInsight クラスターで Apache Hive レプリケーションを使用する方法
データベースとウェアハウスのコンテキストでは、レプリケーションは、一方のウェアハウスから他方にエンティティを複製するプロセスです。 複製は、データベース全体、またはテーブルやパーティションなどのより小さいレベルに適用できます。 目的は、基本エンティティが変更されるたびに変化するレプリカを保持することです。 Apache Hive でのレプリケーションでは、ディザスター リカバリーに重点が置かれ、一方向のプライマリ コピー レプリケーションが提供されます。 HDInsight クラスターでは、Hive Replication を使用して、Hive メタストアと、Azure Data Lake Storage Gen2 上の関連付けられた基になるデータ レイクを一方向にレプリケートできます。
Hive Replication は長年にわたって進化しており、新しいバージョンでは、より優れた機能が提供され、速度が向上し、リソースの消費量が減少しています。 この記事では、HDInsight 3.6 と HDInsight 4.0 の両方のクラスターの種類でサポートされている Hive Replication (Replv2) について説明します。
replv2 の利点
Hive ReplicationV2 (Replv2 とも呼ばれます) には、Hive の IMPORT と EXPORT を使用していた Hive レプリケーションの最初のバージョンと比べて次の利点があります。
- イベント ベースの増分レプリケーション
- ポイントインタイム レプリケーション
- 帯域幅の要件の削減
- 中間コピー数の削減
- レプリケーションの状態の維持
- 制約付きレプリケーション
- ハブおよびスポーク モデルのサポート
- ACID テーブルのサポート (HDInsight 4.0)
レプリケーション フェーズ
Hive イベント ベースのレプリケーションは、プライマリとセカンダリのクラスター間で構成されます。 このレプリケーションは、ブートストラップと増分実行の 2 つの異なるフェーズで構成されています。
ブートストラップ
ブートストラップは、データベースの基本状態をプライマリからセカンダリにレプリケートするために 1 回実行することを目的としています。 必要に応じてブートストラップを構成して、レプリケーションを有効にする必要がある対象データベース内のテーブルのサブセットを含めることができます。
増分実行
ブートストラップの実行後、増分実行はプライマリ クラスターで自動化され、これらの増分実行中に生成されたイベントがセカンダリ クラスターで再生されます。 セカンダリ クラスターがプライマリ クラスターに追いつくと、セカンダリはプライマリのイベントと整合します。
レプリケーションのコマンド
Hive には、イベントのフローを調整するための一連の REPL コマンド (DUMP、LOAD、STATUS) が用意されています。 DUMP コマンドを実行すると、プライマリ クラスターですべての DDL/DML イベントのローカル ログが生成されます。 LOAD コマンドは、抽出されたレプリケーション ダンプ出力にログされたメタデータおよびデータを遅延コピーする方法であり、ターゲット クラスターで実行されます。 STATUS コマンドはターゲット クラスターから実行され、最新のレプリケーション ロードが正常にレプリケートされたことを示す最新のイベント ID を提供します。
レプリケーション ソースを設定する
レプリケーションを開始する前に、レプリケートするデータベースがレプリケーション ソースとして設定されていることを確認します。 DESC DATABASE EXTENDED <db_name> コマンドを使用すると、パラメーター repl.source.for がポリシー名で設定されているかどうかを確認できます。
ポリシーがスケジュールされていて、repl.source.for パラメーターが設定されていない場合は、まず ALTER DATABASE <db_name> SET DBPROPERTIES ('repl.source.for'='<policy_name>') を使用してこのパラメーターを設定する必要があります。
ALTER DATABASE tpcds_orc SET DBPROPERTIES ('repl.source.for'='replpolicy1')
データ レイクにメタデータをダンプする
関連するメタデータを Azure Data Lake Storage Gen2 にダンプするには、ブートストラップ フェーズで REPL DUMP [database name]. => location / event_id コマンドを使用します。 event_id には、関連するメタデータが Azure Data Lake Storage Gen2 に格納された最小イベントを指定します。
repl dump tpcds_orc;
出力例:
| dump_dir | last_repl_id |
|---|---|
| /tmp/hive/repl/38896729-67d5-41b2-90dc-46eeed4c5dd0 | 2925 |
ターゲット クラスターにデータを読み込む
REPL LOAD [database name] FROM [ location ] { WITH ( ‘key1’=‘value1’{, ‘key2’=‘value2’} ) } コマンドは、レプリケーションのブートストラップと増分の両方のフェーズにおいて、ターゲット クラスターにデータを読み込むために使用されます。 [database name] は、ソースと同じにすることも、ターゲット クラスター上では別の名前にすることもできます。 [location] は、前の REPL DUMP コマンドの出力の場所を表します。 これは、ターゲット クラスターがソース クラスターと通信できる必要があることを意味します。 WITH 句は主にターゲット クラスターの再起動を防ぐために追加されたものであり、これでレプリケーションが可能になります。
repl load tpcds_orc from '/tmp/hive/repl/38896729-67d5-41b2-90dc-46eeed4c5dd0';
最後にレプリケートされたイベント ID を出力する
REPL STATUS [database name] コマンドはターゲット クラスターで実行され、最後にレプリケートされた event_id を出力します。 このコマンドを使用すると、ユーザーはターゲット クラスターがレプリケートされてどのようなどのような状態になったかを把握できます。 このコマンドの出力を使用して、増分レプリケーション用の次の REPL DUMP コマンドを作成できます。
repl status tpcds_orc;
出力例:
| last_repl_id |
|---|
| 2925 |
関連するデータおよびメタデータをデータ レイクにダンプする
関連するメタデータおよびデータを Azure Data Lake Storage にダンプするには、REPL DUMP [database name] FROM [event-id] { TO [event-id] } { LIMIT [number of events] } コマンドを使用します。 このコマンドは増分フェーズで使用され、ソース ウェアハウスで実行されます。 増分フェーズでは FROM [event-id] が必要です。event-id の値は、ターゲット ウェアハウスで REPL STATUS [database name] コマンドを実行することで取得できます。
repl dump tpcds_orc from 2925;
出力例:
| dump_dir | last_repl_id |
|---|---|
| /tmp/hive/repl/38896729-67d5-41b2-90dc-466466agadd0 | 2960 |
Hive レプリケーションのプロセス
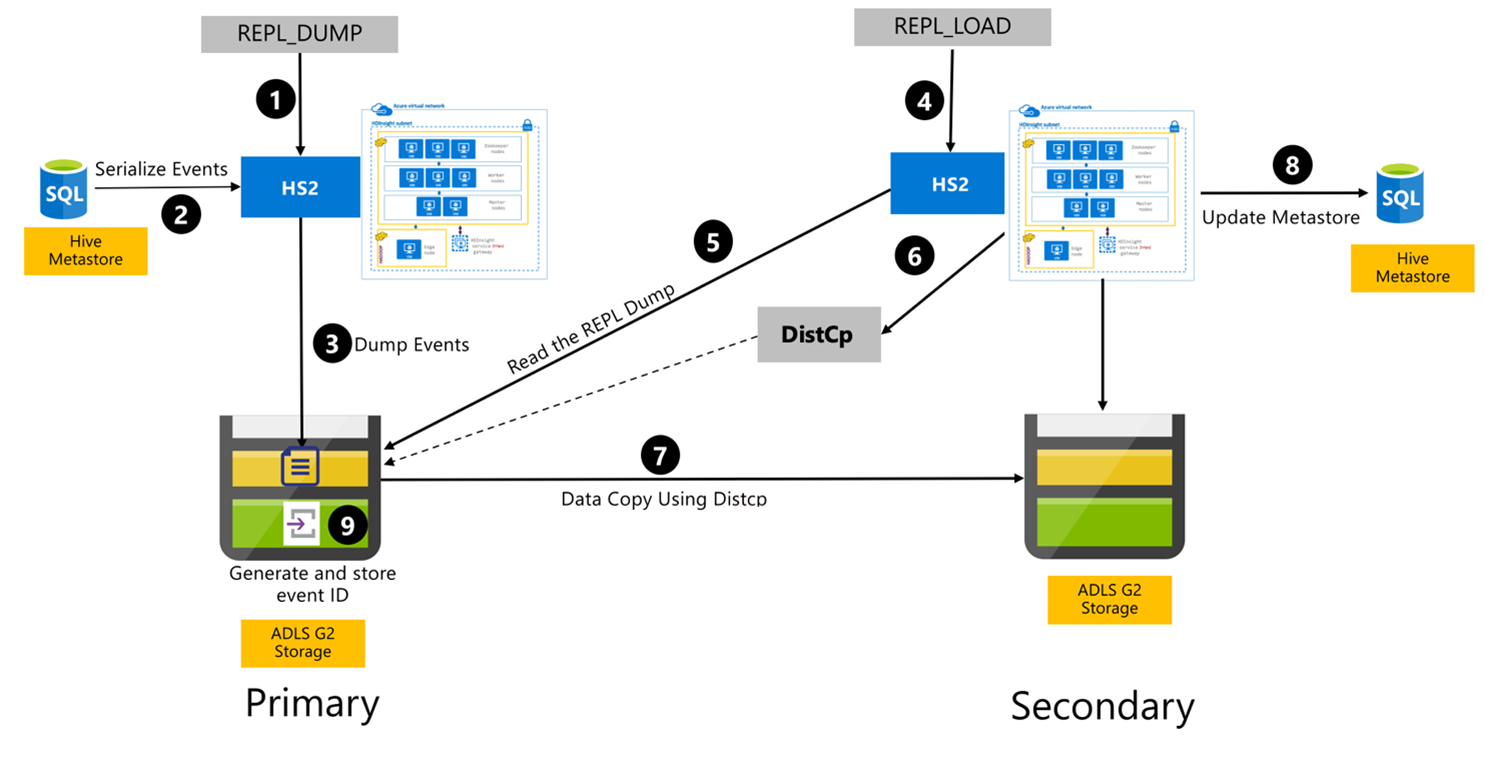
次の手順は、Hive Replication プロセス中に発生する順次イベントです。
レプリケートするテーブルが特定のポリシーのレプリケーション ソースとして設定されていることを確認します。
REPL_DUMPコマンドが、データベース名、イベント ID の範囲、Azure Data Lake Storage Gen2 ストレージの URL などの関連する制約と共にプライマリ クラスターに対して発行されます。メタストアからのすべての追跡イベントのダンプが最新のものにシリアル化されます。 このダンプは、
REPL_DUMPによって指定された URL のプライマリ クラスター上の Azure Data Lake Storage Gen2 ストレージ アカウントに格納されます。プライマリ クラスターで、レプリケーション メタデータがプライマリ クラスターの Azure Data Lake Storage Gen2 ストレージに保持されます。 パスは、Ambari の Hive Config UI で構成できます。 このプロセスで、メタデータが格納されているパスと、最新の追跡 DML/DDL イベントの ID が提供されます。
REPL_LOADコマンドは、セカンダリ クラスターから発行されます。 このコマンドは、手順 3 で構成したパスを指します。セカンダリ クラスターで、手順 3 で作成した追跡イベントを使用して、メタデータ ファイルが読み取られます。 セカンダリ クラスターが、
REPL_DUMPからの追跡イベントが格納されているプライマリ クラスターの Azure Data Lake Storage Gen2 ストレージへのネットワーク接続を備えていることを確認します。セカンダリ クラスターで、分散コピー (
DistCP) コンピューティングが生成されます。セカンダリ クラスターにより、プライマリ クラスターのストレージからデータがコピーされます。
セカンダリ クラスターのメタストアが更新されます。
最後の追跡イベント ID がプライマリ メタストアに格納されます。
増分レプリケーションは同じプロセスに従いますが、最後にレプリケートされたイベント ID が入力として必要になります。 これにより、最後のレプリケーション イベント以降の増分コピーが発生します。 増分レプリケーションは通常、要求される回復ポイントの目標 (RPO) を達成するために事前に定義された頻度で自動化されます。
レプリケーションのパターン
レプリケーションは通常、プライマリとセカンダリの間で一方向に構成されます。ここで、プライマリは読み取りと書き込みの要求に対応します。 セカンダリ クラスターは、読み取り要求のみに対応します。 障害が発生した場合、セカンダリで書き込みが許可されますが、レプリケーションの反転をプライマリに構成し直す必要があります。
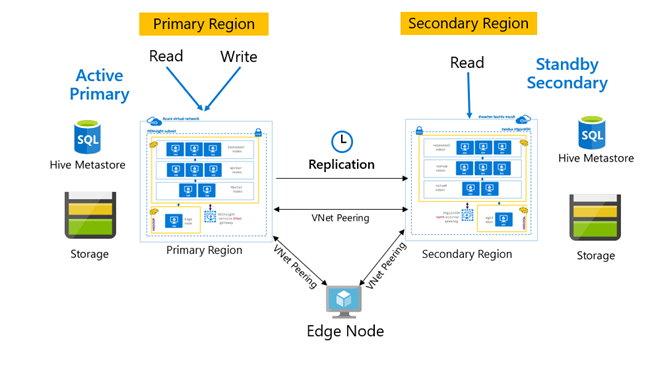
プライマリ/セカンダリ、ハブおよびスポーク、リレーなど、Hive レプリケーションに適したパターンは多数あります。
HDInsight のアクティブ プライマリ/スタンバイ セカンダリは、一般的な事業継続とディザスター リカバリー (BCDR) パターンです。HiveReplicationV2 では、VNet ピアリングを使用する、リージョンで区切られた HDInsight Hadoop クラスターでこのパターンを使用できます。 両方のクラスターにピアリングされた共通の仮想マシンを使用して、レプリケーションの自動化スクリプトをホストできます。 使用可能な HDInsight BCDR パターンの詳細については、HDInsight の事業継続性に関するドキュメントを参照してください。
Enterprise セキュリティ パッケージを使用した Hive レプリケーション
Enterprise セキュリティ パッケージを使用して HDInsight Hadoop クラスターで Hive レプリケーションが計画されている場合は、Ranger metastore と Microsoft Entra Domain Services のレプリケーション メカニズムを考慮する必要があります。
Microsoft Entra Domain Services レプリカ セット機能を使用して、複数のリージョンにわたって Microsoft Entra テナントごとに複数の Microsoft Entra Domain Services レプリカ セットを作成します。 個々のレプリカ セットは、それぞれのリージョンで HDInsight の VNet とピアリングされている必要があります。 この構成では、Microsoft Entra Domain Services への変更 (構成、ユーザー ID と資格情報、グループ、グループ ポリシー オブジェクト、コンピューター オブジェクトなどを含む) が、Microsoft Entra Domain Services レプリケーションを使用してマネージド ドメイン内のすべてのレプリカ セットに適用されます。
Ranger ポリシーは、Ranger のインポート/エクスポート機能を使用して、定期的にバックアップし、プライマリからセカンダリにレプリケートすることができます。 セカンダリ クラスターに実装しようとしている承認のレベルに応じて、Ranger ポリシーのすべてまたはサブセットをレプリケートすることを選択できます。
サンプル コード
次のコー ドシーケンスは、tpcds_orc というサンプル テーブルにブートストラップおよび増分のレプリケーションを実装する方法の例を示しています。
レプリケーション ポリシーのソースとしてテーブルを設定します。
ALTER DATABASE tpcds_orc SET DBPROPERTIES ('repl.source. for'='replpolicy1');プライマリ クラスターでブートストラップ ダンプを行います。
repl dump tpcds_orc with ('hive.repl.rootdir'='/tmpag/hiveag/replag');出力例:
dump_dir last_repl_id /tmpag/hiveag/replag/675d1bea-2361-4cad-bcbf-8680d305a27a 2925 セカンダリ クラスターでブートストラップ読み込みを行います。
repl load tpcds_orc from '/tmpag/hiveag/replag 675d1bea-2361-4cad-bcbf-8680d305a27a';セカンダリ クラスターで
REPLの状態を確認します。repl status tpcds_orc;last_repl_id 2925 プライマリ クラスターで増分ダンプを行います。
repl dump tpcds_orc from 2925 with ('hive.repl.rootdir'='/tmpag/hiveag/ replag');出力例:
dump_dir last_repl_id /tmpag/hiveag/replag/31177ff7-a40f-4f67-a613-3b64ebe3bb31 2960 セカンダリ クラスターで増分読み込みを行います。
repl load tpcds_orc from '/tmpag/hiveag/replag/31177ff7-a40f-4f67-a613-3b64ebe3bb31';セカンダリ クラスターで
REPLの状態を確認します。repl status tpcds_orc;last_repl_id 2960
次のステップ
この記事で説明した項目の詳細については、次を参照してください。