Azure HDInsight で Hive Warehouse Connector を使用して Apache Spark と Apache Hive を統合する
Apache Hive Warehouse Connector (HWC) は、Apache Spark と Apache Hive でより簡単に作業できるようにするライブラリです。 Spark DataFrames と Hive テーブル間でデータを移動するなどのタスクをサポートしています。 また、Spark ストリーミング データを Hive テーブルに転送します。 Hive Warehouse Connector は、Spark と Hive の間で橋渡しのように動作します。 Scala、Java、Python も開発用のプログラミング言語としてサポートされます。
Hive Warehouse Connector を使用すると、Hive および Spark の独自の機能を活用して、強力なビッグデータ アプリケーションを構築できます。
Apache Hive では、ACID (原子性、一貫性、分離性、持続性) なデータベース トランザクションがサポートされています。 Hive における ACID およびトランザクションの詳細については、「Hive Transactions (Hive トランザクション)」を参照してください。 Hive には、Apache Ranger を通じた詳細なセキュリティ コントロールと、Apache Spark では使用できない Low Latency Analytical Processing (LLAP) も備わっています。
Apache Spark には、Apache Hive では使用できないストリーミング機能を提供する Structured Streaming API があります。 HDInsight 4.0 以降、Apache Spark 2.3.1 以降と Apache Hive 3.1.0 はメタストア カタログが異なり、相互運用性が困難になりました。
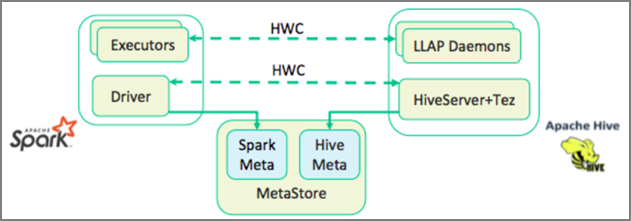
Hive Warehouse Connector (HWC) によって、Spark と Hive を一緒に使用することが容易になります。 HWC ライブラリは、LLAP デーモンから Spark Executor にデータを並列で読み込みます。 このプロセスにより、Spark から Hive への標準の JDBC 接続よりも効率性と適応性が高まります。 これにより、HWC の 2 種類の実行モードが実現します。
- HiveServer2 を介した Hive JDBC モード
- LLAP デーモンを使った Hive LLAP モード [推奨]
既定では、HWC は Hive LLAP デーモンを使うように構成されています。 前述のモードとそれぞれの API を使った Hive クエリの実行 (読み取りと書き込みの両方) については、HWC API に関するページを参照してください。
Hive Warehouse Connector でサポートされる操作の一部を次に示します。
- テーブルを記述する
- ORC 形式データ用のテーブルを作成する
- Hive データを選択して DataFrame を取得する
- DataFrame を Hive にバッチで書き込む
- Hive の更新ステートメントを実行する
- Hive からテーブル データを読み取り、Spark で変換し、新しい Hive テーブルに書き込む
- Hive ストリーミングを使用して DataFrame または Spark ストリームを Hive に書き込む
Hive Warehouse Connector の設定
重要
- Spark 2.4 Enterprise セキュリティ パッケージ クラスターにインストールされている HiveServer2 Interactive インスタンスは、Hive Warehouse Connector での使用がサポートされていません。 代わりに、HiveServer2 Interactive ワークロードをホストするために、別の HiveServer2 Interactive クラスターを構成する必要があります。 単一の Spark 2.4 クラスターを利用する Hive Warehouse Connector の構成はサポートされていません。
- Hive Warehouse Connector (HWC) ライブラリは、ワークロード管理 (WLM) 機能が有効にされた Interactive Query クラスターでの使用がサポートされていません。
Spark ワークロードのみが存在し、HWC ライブラリを使用するシナリオでは、Interactive Query クラスターでワークロード管理機能が有効にされていないことを確認してください (hive.server2.tez.interactive.queue構成は、ハイブ構成で設定されません)。
Spark ワークロード (HWC) と LLAP ネイティブ ワークロードの両方が存在するシナリオでは、共有メタストア データベースを使用して、2 つの個別の Interactive Query クラスターを作成する必要があります。 必要に応じて WLM 機能を有効にできるネイティブ LLAP ワークロード用の 1 つのクラスターと WLM 機能を構成しない HWC のみのワークロード用の他方のクラスター。 1 つのクラスターでのみ有効にされている場合でも、両方のクラスターから WLM リソース プランを表示できることに注意してください。 WLM 機能が無効にされているクラスターのリソース プランの変更は、他方のクラスターの WLM 機能に影響する可能性があるため、行わないでください。 - Spark は、データ分析を簡略化するために R コンピューティング言語をサポートしていますが、Hive Warehouse Connector (HWC) ライブラリは R との併用がサポートされていません。HWC ワークロードを実行するには、Scala、Java、Python のみをサポートする JDBC スタイルの HiveWarehouseSession API を使って、Spark から Hive へのクエリを実行することができます。
- JDBC モードによる HiveServer2 を介したクエリの実行 (読み取りと書き込みの両方) は、Array/Struct/Map 型などの複合データ型ではサポートされません。
- HWC は、ORC ファイル形式での書き込みのみをサポートしています。 ORC 以外の書き込み (例: parquet やテキスト ファイル形式) は HWC ではサポートされません。
Hive Warehouse Connector には、Spark ワークロードと Interactive Query ワークロード用に、個別のクラスターが必要です。 次の手順に従って、Azure HDInsight にこれらのクラスターを設定します。
サポートされているクラスターの種類とバージョン
| HWC バージョン | Spark バージョン | InteractiveQuery バージョン |
|---|---|---|
| v1 | Spark 2.4 | HDI 4.0 | Interactive Query 3.1 | HDI 4.0 |
| v2 | Spark 3.1 | HDI 5.0 | Interactive Query 3.1 | HDI 5.0 |
クラスターの作成
ストレージ アカウントとカスタム Azure 仮想ネットワークを使って HDInsight Spark 4.0 クラスターを作成します。 Azure 仮想ネットワークでのクラスターの作成については、「既存の仮想ネットワークへの HDInsight の追加」を参照してください。
Spark クラスターと同じストレージ アカウントと Azure 仮想ネットワークを使って HDInsight 対話型クエリ (LLAP) 4.0 クラスターを作成します。
HWC 設定の構成
準備情報の収集
Web ブラウザーで
https://LLAPCLUSTERNAME.azurehdinsight.net/#/main/services/HIVEに移動します。ここで、LLAPCLUSTERNAME は Interactive Query クラスターの名前です。[概要]>[HiveServer2 Interactive JDBC URL] の順に移動し、値を書き留めます。 値は次のようになります。
jdbc:hive2://<zookeepername1>.rekufuk2y2ce.bx.internal.cloudapp.net:2181,<zookeepername2>.rekufuk2y2ce.bx.internal.cloudapp.net:2181,<zookeepername3>.rekufuk2y2ce.bx.internal.cloudapp.net:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2-interactive[Configs]>[Advanced]>[Advanced hive-site]>[hive.zookeeper.quorum] の順に移動し、値を書き留めます。 値は次のようになります。
<zookeepername1>.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:2181,<zookeepername2>.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:2181,<zookeepername3>.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:2181[Configs]>[Advanced]>[General]>[hive.metastore.uris] の順に移動し、値を書き留めます。 値は次のようになります。
thrift://iqgiro.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:9083,thrift://hn*.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:9083[Configs]>[Advanced]>[Advanced hive-interactive-site]>[hive.llap.daemon.service.hosts] の順に移動し、値を書き留めます。 値は次のようになります。
@llap0
Spark クラスター設定の構成
Web ブラウザーで
https://CLUSTERNAME.azurehdinsight.net/#/main/services/SPARK2/configsに移動します。ここで、CLUSTERNAME は Apache Spark クラスターの名前です。[Custom spark2-defaults] を展開します。
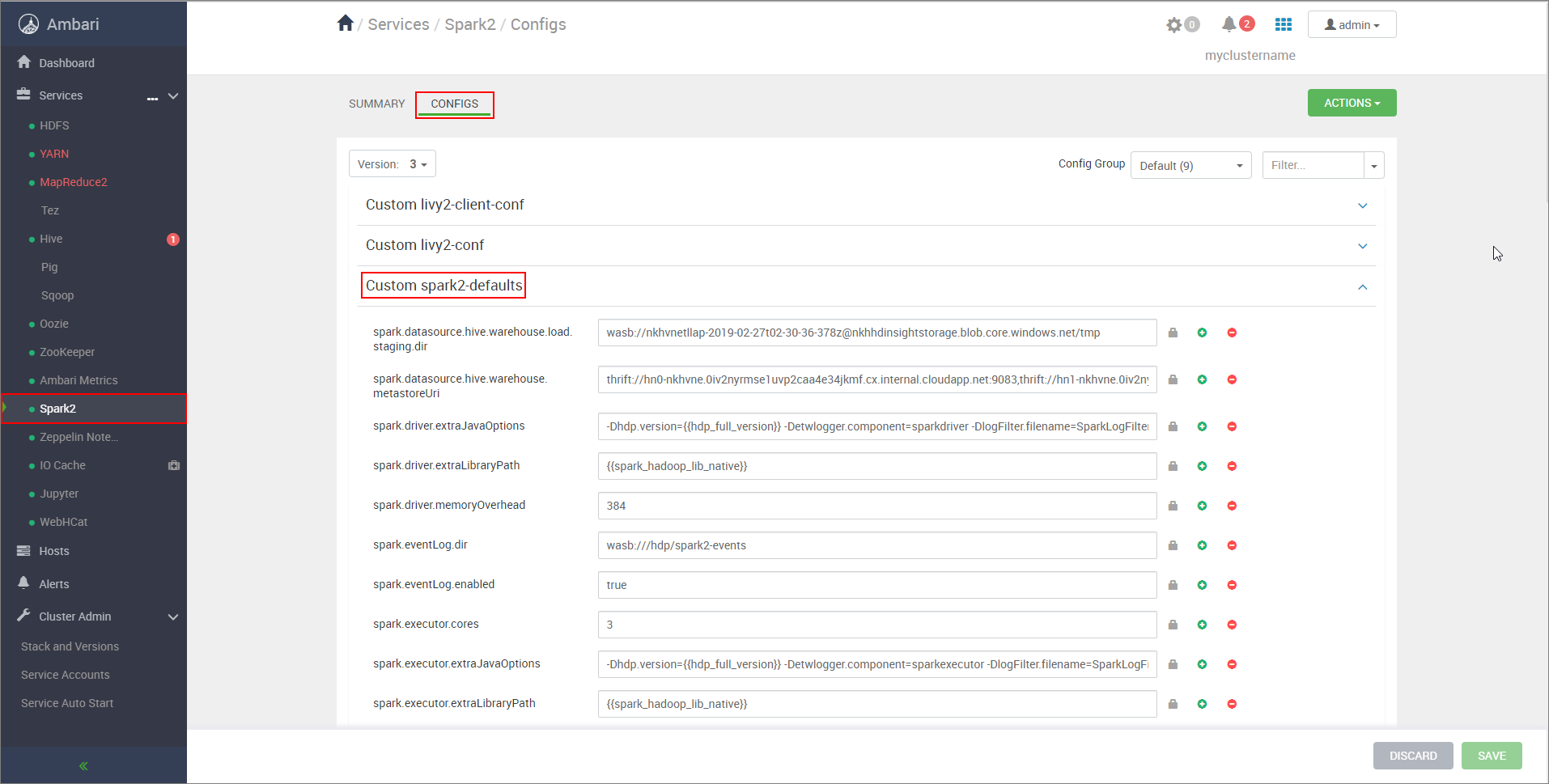
[プロパティの追加] を選択して、次の構成を追加します。
構成 値 spark.datasource.hive.warehouse.load.staging.dirADLS Gen2 ストレージ アカウントを使用している場合は、 abfss://STORAGE_CONTAINER_NAME@STORAGE_ACCOUNT_NAME.dfs.core.windows.net/tmpを使用します。
Azure Blob Storage アカウントを使用している場合は、wasbs://STORAGE_CONTAINER_NAME@STORAGE_ACCOUNT_NAME.blob.core.windows.net/tmpを使用します。
HDFS と互換性のある適切なステージング ディレクトリに設定します。 2 つの異なるクラスターがある場合、ステージング ディレクトリは、HiveServer2 がそこにアクセスできるように、LLAP クラスターのストレージ アカウントのステージング ディレクトリにあるフォルダーである必要があります。STORAGE_ACCOUNT_NAMEをクラスターによって使用されているストレージ アカウントの名前に置き換え、STORAGE_CONTAINER_NAMEをストレージ コンテナーの名前に置き換えます。spark.sql.hive.hiveserver2.jdbc.urlHiveServer2 Interactive JDBC URL から先ほど取得した値 spark.datasource.hive.warehouse.metastoreUrihive.metastore.uris から先ほど取得した値。 spark.security.credentials.hiveserver2.enabledYARN クラスター モードの場合は true、YARN クライアント モードの場合はfalse。spark.hadoop.hive.zookeeper.quorumhive.zookeeper.quorum から先ほど取得した値。 spark.hadoop.hive.llap.daemon.service.hostshive.llap.daemon.service.hosts から先ほど取得した値。 変更を保存し、影響を受けるすべてのコンポーネントを再起動します。
Enterprise セキュリティ パッケージ (ESP) クラスター用の HWC の構成
Enterprise セキュリティ パッケージ (ESP) を使用すると、Active Directory ベースの認証、マルチユーザーのサポート、ロールベースのアクセス制御など、エンタープライズレベルの機能を Azure HDInsight の Apache Hadoop クラスターで利用できます。 ESP に関する詳細については、「HDInsight で Enterprise セキュリティ パッケージを使用する」を参照してください。
前のセクションで説明した構成とは別に、ESP クラスターで HWC を使用するための次の構成を追加します。
Spark クラスターの Ambari Web UI で、 [Spark2]>[CONFIGS]>[Custom spark2-defaults] の順に移動します。
次のプロパティを更新します。
構成 値 spark.sql.hive.hiveserver2.jdbc.url.principalhive/<llap-headnode>@<AAD-Domain>Web ブラウザーで
https://CLUSTERNAME.azurehdinsight.net/#/main/services/HIVE/summaryに移動します。ここで、CLUSTERNAME は Interactive Query クラスターの名前です。 [HiveServer2 Interactive] をクリックします。 スクリーンショットに示したように、LLAP を実行しているヘッド ノードの完全修飾ドメイン名 (FQDN) が表示されます。<llap-headnode>は、この値に置き換えます。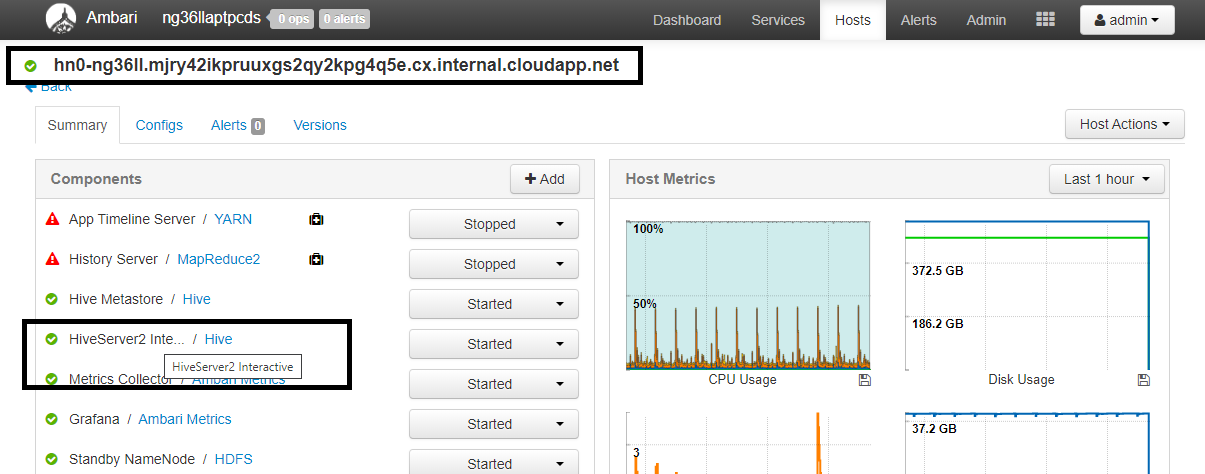
ssh コマンドを使用して Interactive Query クラスターに接続します。
/etc/krb5.confファイルでdefault_realmパラメーターを探します。<AAD-DOMAIN>は、その値に置き換えます。値の文字列は大文字にしてください。そうしないと、資格情報が見つからなくなります。
たとえば、
hive/hn*.mjry42ikpruuxgs2qy2kpg4q5e.cx.internal.cloudapp.net@PKRSRVUQVMAE6J85.D2.INTERNAL.CLOUDAPP.NETです。
変更を保存し、必要に応じてコンポーネントを再起動します。
Hive Warehouse Connector の使用
いくつかの異なる方法の中から選択し、Hive Warehouse Connector を使って自分の対話型クエリ クラスターに接続してクエリを実行できます。 サポートされている方法には次のツールがあります。
Spark から HWC に接続するいくつかの例を次に示します。
Spark-shell
これは、Scala シェルの変更バージョンを介して対話形式で Spark を実行する方法です。
ssh コマンドを使用して Apache Spark クラスターに接続します。 次のコマンドを編集して CLUSTERNAME をクラスターの名前に置き換えてから、そのコマンドを入力します。
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netSSH セッションから次のコマンドを実行して、
hive-warehouse-connector-assemblyのバージョンを確認します。ls /usr/hdp/current/hive_warehouse_connector上で特定した
hive-warehouse-connector-assemblyのバージョンを使用して、次のコードを編集します。 次のコマンドを実行して、spark シェルを起動します。spark-shell --master yarn \ --jars /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-<VERSION>.jar \ --conf spark.security.credentials.hiveserver2.enabled=falsespark シェルの起動後、次のコマンドを使用して Hive Warehouse Connector インスタンスを開始できます。
import com.hortonworks.hwc.HiveWarehouseSession val hive = HiveWarehouseSession.session(spark).build()
Spark-submit
spark-submit は、任意の Spark プログラム (またはジョブ) を Spark クラスターに送信するユーティリティです。
spark-submit ジョブにより、指示に従って Spark と Hive Warehouse Connector の設定と構成が行われ、渡したプログラムが実行され、使っていたリソースが完全に解放されます。
scala/java コードを依存関係と共にアセンブリ jar にビルドしたら、次のコマンドを使用して、Spark アプリケーションを起動します。
<VERSION> および <APP_JAR_PATH> を実際の値に置き換えます。
YARN クライアント モード
spark-submit \ --class myHwcApp \ --master yarn \ --deploy-mode client \ --jars /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-<VERSION>.jar \ --conf spark.security.credentials.hiveserver2.enabled=false /<APP_JAR_PATH>/myHwcAppProject.jarYARN クラスター モード
spark-submit \ --class myHwcApp \ --master yarn \ --deploy-mode cluster \ --jars /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-<VERSION>.jar \ --conf spark.security.credentials.hiveserver2.enabled=true /<APP_JAR_PATH>/myHwcAppProject.jar
このユーティリティは、アプリケーション全体を pySpark で記述して .py ファイル (Python) にパッケージ化し、コード全体を Spark クラスターに送信して実行できるようにする場合にも使います。
Python アプリケーションの場合は、/<APP_JAR_PATH>/myHwcAppProject.jar の場所に .py ファイルを渡し、--py-files を使って以下の構成ファイル (Python .zip) を検索パスに追加します。
--py-files /usr/hdp/current/hive_warehouse_connector/pyspark_hwc-<VERSION>.zip
Enterprise セキュリティ パッケージ (ESP) クラスターに対するクエリの実行
spark-shell または spark-submit を起動する前に、kinit を使用します。 USERNAME を、クラスターへのアクセス許可を持つドメイン アカウントの名前に置き換えます。その後、以下のコマンドを実行します。
kinit USERNAME
Spark ESP クラスター上のデータのセキュリティ保護
次のコマンドを入力して、一定のサンプル データが含まれるテーブル
demoを作成します。create table demo (name string); INSERT INTO demo VALUES ('HDinsight'); INSERT INTO demo VALUES ('Microsoft'); INSERT INTO demo VALUES ('InteractiveQuery');次のコマンドを使用して、テーブルの内容を表示します。 ポリシーを適用する前、
demoテーブルにはすべての列が表示されます。hive.executeQuery("SELECT * FROM demo").show()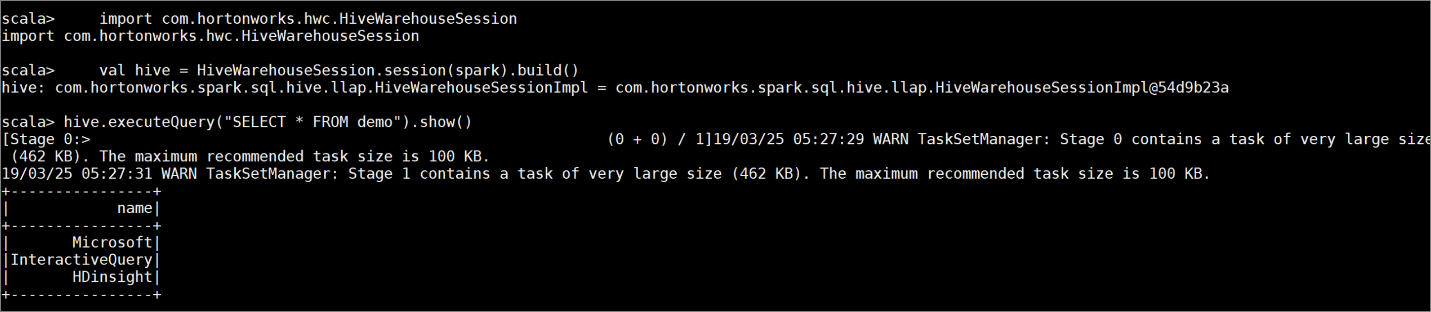
列の最後の 4 文字だけが表示される列マスク ポリシーを適用します。
https://LLAPCLUSTERNAME.azurehdinsight.net/ranger/で Ranger 管理 UI に移動します。[Hive] の下にある自分のクラスターの Hive サービスをクリックします。
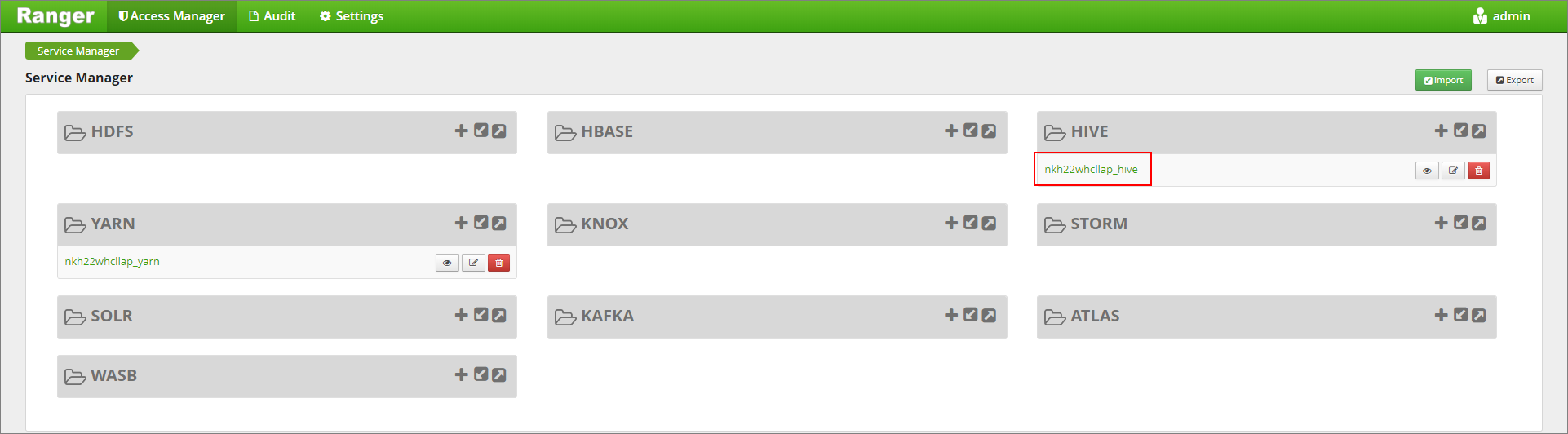
[Masking](マスク) タブをクリックし、 [Add New Policy](新しいポリシーの追加) をクリックします
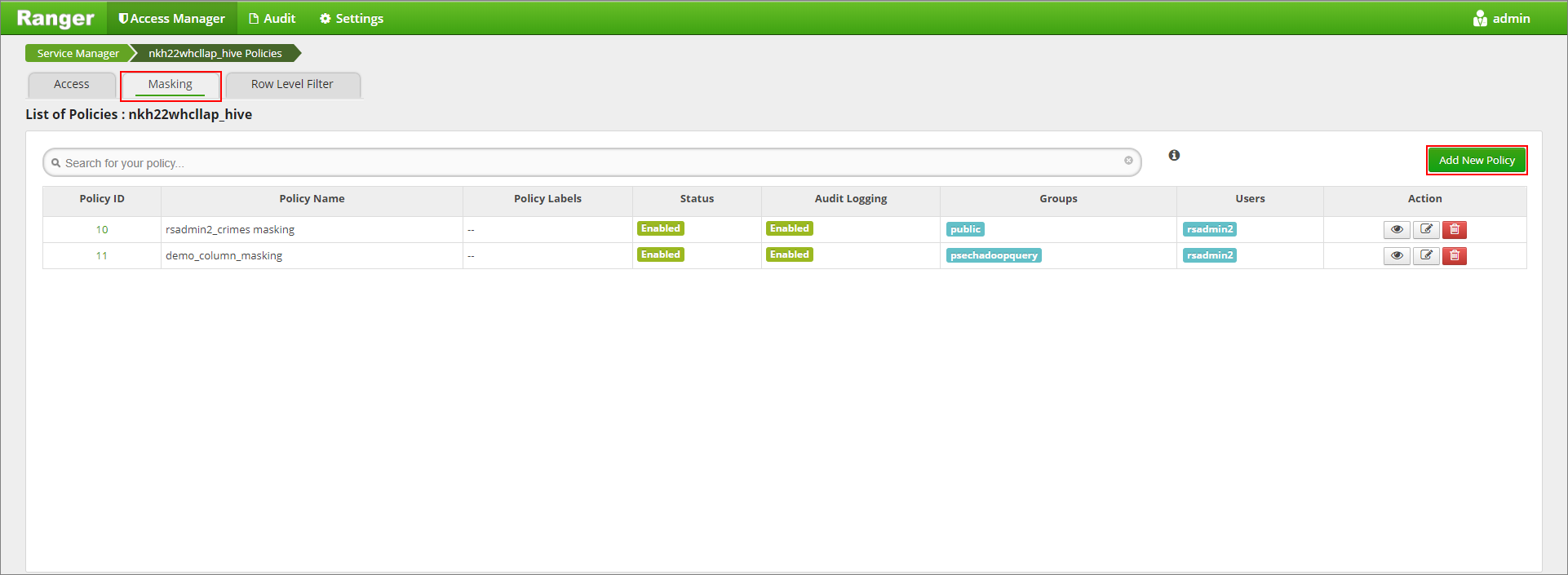
目的のポリシー名を入力します。 次のように選択します。データベース: default、Hive テーブル: demo、Hive 列: name、ユーザー: rsadmin2、アクセスの種類: select、 [Select Masking Option](マスク オプションの選択) メニュー: Partial mask: show last 4。 追加をクリックします。
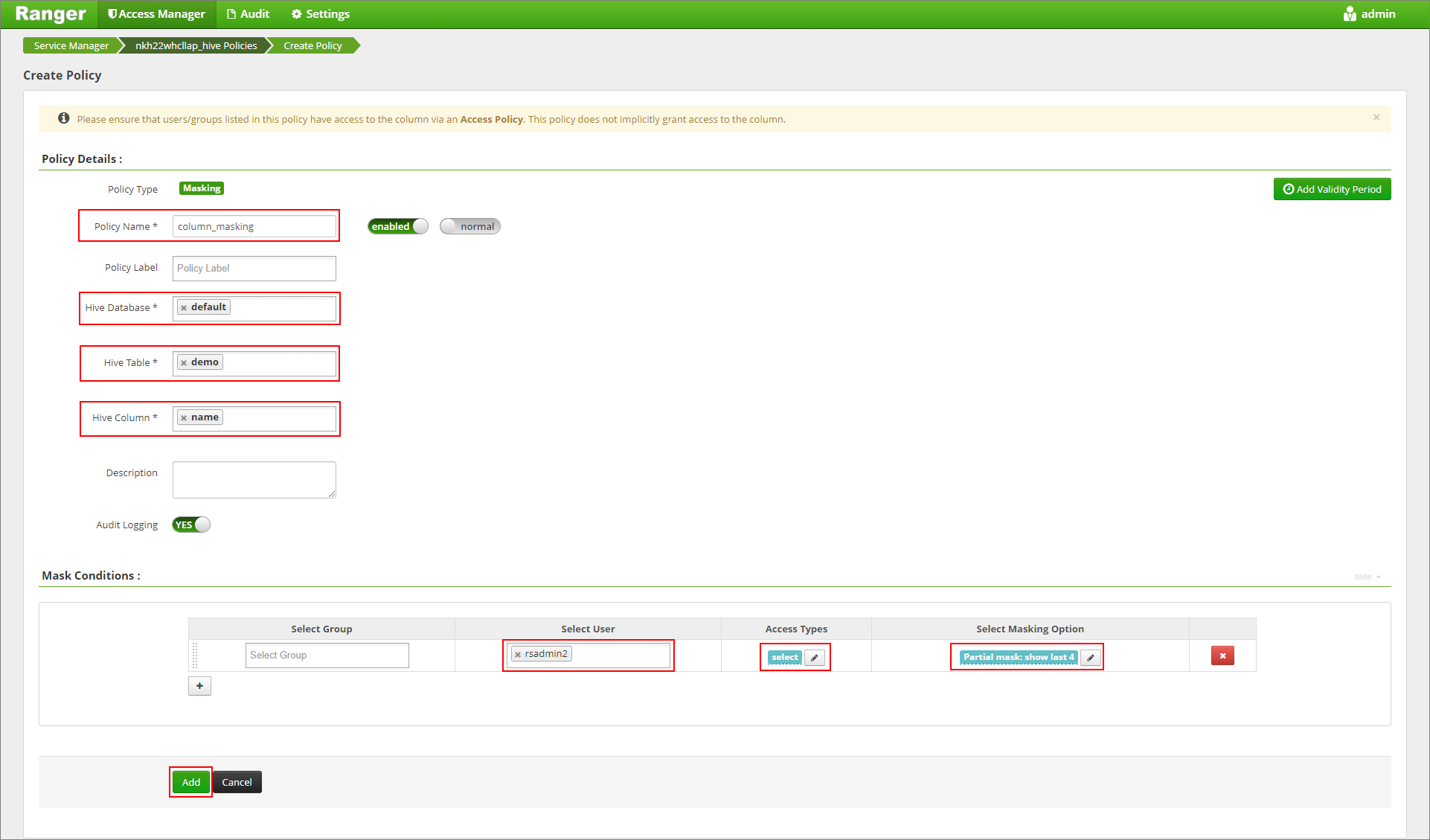
テーブルの内容をもう一度表示します。 Ranger ポリシーの適用後は、列の最後の 4 文字だけを確認できます。
