Azure HDInsight での信頼性
この記事では、Azure HDInsight の信頼性サポートについて説明し、可用性ゾーンとリージョン間のリカバリーおよび事業継続性を取り上げます。 Azure における信頼性の詳細については、Azure の信頼性に関するページを参照してください。
可用性ゾーンのサポート
可用性ゾーンとは、各 Azure リージョン内にある、物理的に分離されたデータセンターのグループです。 1 つのゾーンで障害が発生した際には、サービスを残りのゾーンのいずれかにフェールオーバーできます。
Azure の可用性ゾーンの詳細については、「可用性ゾーンとは」を参照してください。
Azure HDInsight では、 ゾーンデプロイ構成がサポートされています。 Azure HDInsight クラスター ノードは、選択したリージョンで選択した単一のゾーンに配置されます。 ゾーン HDInsight クラスターは、他のゾーンで発生した障害から隔離されています。 ただし、HDInsight クラスターに選ばれた特定のゾーンに障害の影響が及ぶ場合、クラスターは使用できなくなります。 このデプロイ モデルでは、クラスター内のネットワーク接続が低コストで待機時間も短くなります。 このデプロイ モデルを複数の可用性ゾーンにレプリケートすることで、より高いレベルの可用性でハードウェア障害からの保護を実現できます。
重要
ユーザーが特定のゾーンを指定しないデプロイの場合、ノードタイプはゾーンの回復性がなく、そのリージョン内の任意のゾーンで停止中にダウンタイムが発生する可能性があります。
前提条件
可用性ゾーンは、2023 年 6 月 15 日より後に作成されたクラスターでのみサポートされます。 可用性ゾーンの設定は、クラスターの作成後は更新できません。 また、可用性ゾーンを使用するために、既存の非可用性ゾーン クラスターを更新することはできません。
クラスターは、カスタム VNet の下で作成する必要があります。
独自の Ambari DB 用の SQL DB と外部メタストア (Hive メタストアなど) を持ち込んで、これらの DB を同じ可用性ゾーンに構成できるようにする必要があります。
HDInsight クラスターは、次のいずれかのリージョンで可用性ゾーン オプションを使用して作成する必要があります:
- オーストラリア東部
- ブラジル南部
- カナダ中部
- 米国中部
- 米国東部
- 米国東部 2
- フランス中部
- ドイツ中西部
- 東日本
- 韓国中部
- 北ヨーロッパ
- カタール中部
- 東南アジア
- 米国中南部
- 英国南部
- US Gov バージニア州
- 西ヨーロッパ
- 米国西部 2
可用性ゾーンを使用して HDInsight クラスターを作成する
Azure Resource Manager (ARM) テンプレートを使用して、指定された可用性ゾーンで HDInsight クラスターを起動できます。
リソース セクションで、'ゾーン' のセクションを追加し、このクラスターをどの可用性ゾーンにデプロイするかを指定する必要があります。
"resources": [
{
"type": "Microsoft.HDInsight/clusters",
"apiVersion": "2021-06-01",
"name": "[parameters('cluster name')]",
"location": "East US 2",
"zones": [
"1"
],
}
]
1 つの可用性ゾーンに入っているノードを複数のゾーンにわたって確認します
HDInsight クラスターの準備ができたら、場所を確認して、それらがどの可用性ゾーンにデプロイされているかを調べることができます。

Get API の応答
[
{
"location": "East US 2",
"zones": [
"1"
],
}
]
クラスターをスケールアップする
ワーカー ノードを追加して HDInsight クラスターをスケールアップできます。 新しく追加するワーカー ノードは、このクラスターの同じ可用性ゾーンに配置されます。
可用性ゾーンの移行
現在、Azure HDInsight クラスターでは、既存のクラスター インスタンスから可用性ゾーンのサポートへのインプレース移行はサポートされていません。 ただし、クラスターを再作成し、クラスターの作成時に別の可用性ゾーンまたはリージョンを選択することもできます。 ディザスター リカバリー シナリオでは、別のリージョンと別の可用性ゾーン内のセカンダリ スタンバイ クラスターを使用できます。
ゾーン ダウン エクスペリエンス
可用性ゾーンがダウンした場合:
- このクラスターに ssh 接続はできません。
- このクラスターの削除、スケールアップ、スケールダウンはできません。
- ジョブを送信したり、ジョブ履歴を表示したりできません。
- 別のリージョンで新しいクラスター作成要求を送信することは引き続き可能です。
リージョン間のディザスター リカバリーおよび事業継続
ディザスター リカバリー (DR) とは、ダウンタイムやデータ損失につながるような、影響の大きいイベント (自然災害やデプロイの失敗など) から復旧することです。 原因に関係なく、災害に対する最善の解決策は、明確に定義されテストされた DR プランと、DR を積極的にサポートするアプリケーション設計です。 ディザスター リカバリー計画の作成を検討する前に、「ディザスター リカバリー戦略の設計に関する推奨事項」を参照してください。
DR に関しては、Microsoft は共有責任モデルを使用します。 共有責任モデルでは、ベースライン インフラストラクチャとプラットフォーム サービスの可用性が Microsoft によって保証されます。 同時に、多くの Azure サービスでは、データのレプリケート、または障害が発生したリージョンから別の有効なリージョンにクロスレプリケートするフォールバックは、自動的には行われません。 それらのサービスに対して、ワークロードに適したディザスター リカバリー計画を設定する責任はユーザーにあります。 Azure PaaS (サービスとしてのプラットフォーム) オファリング上で実行されるほとんどのサービスには、DR をサポートするための機能とガイダンスが用意されており、お客様はサービス固有の機能を使って迅速な復旧をサポートでき、DR 計画の開発に役立ちます。
Azure HDInsight クラスターは、ストレージ、データベース、Active Directory、Active Directory Domain Services、ネットワーク、Key Vault などの多くの Azure サービスに依存しています。 適切に設計された、可用性の高いフォールト トレラントな分析アプリケーションは、これらのサービスの 1 つまたは複数でのリージョンまたはローカルにおける中断に耐えられるように、十分な冗長性を備えた設計にする必要があります。 このセクションでは、ビジネス継続性計画のベスト プラクティス、単一リージョンの可用性、および最適化オプションの概要について説明します。
複数リージョンの地域でのディザスター リカバリー
複数リージョンにまたがる高可用性ディザスター リカバリーを使用してビジネス継続性を向上させるには、さらに複雑でコストの高いアーキテクチャ設計が必要とされます。 次の表に、総保有コストが増える可能性のあるいくつかの技術的な領域について詳しく説明します。
コストの最適化
| 領域 | コスト上昇の原因 | 最適化の戦略 |
|---|---|---|
| データ ストレージ | セカンダリ リージョンでのプライマリ データおよびテーブルの複製 | 選別されたデータのみをレプリケートします |
| データ エグレス | 複数リージョンにまたがる送信データ転送は高くつきます。 帯域幅の料金ガイドラインを確認してください | 選別されたデータのみをレプリケートしてリージョンのエグレス フットプリントを削減します |
| クラスター コンピューティング | セカンダリ リージョンでの追加の HDInsight クラスター | プライマリの障害後にセカンダリ コンピューティングをデプロイするために、自動スクリプトを使用します。 セカンダリ クラスターのサイズを最小限に抑えるために、自動スケーリングを使用します。 低コストの VM SKU を使用します。 VM SKU が割引される可能性のあるリージョンにセカンダリを作成します。 |
| 認証 | セカンダリ リージョンのマルチユーザー シナリオの場合、追加の Microsoft Entra Domain Services セットアップが発生します | セカンダリ リージョンでのマルチユーザー設定は避けてください。 |
複雑さの最適化
| 領域 | 複雑さの上昇の原因 | 最適化の戦略 |
|---|---|---|
| 読み取り書き込みのパターン | プライマリとセカンダリの両方で読み取りと書き込みを有効にする必要がある | セカンダリを読み取り専用になるように設計します |
| ゼロ RPO および RTO | データ損失ゼロ (RPO = 0) とダウンタイム ゼロ (RTO = 0) にする必要がある | フェールオーバーする必要があるコンポーネントの数が減るように RPO と RTO を設計します。 RTO と RPO の詳細については、「ビジネス継続性、高可用性、ディザスター リカバリーとは」を参照してください。 |
| ビジネス機能 | セカンダリでプライマリの完全なビジネス機能が必要 | セカンダリのビジネス機能の最小限の重要なサブセットを使用して実行できるかどうかを評価します。 |
| 接続 | すべてのアップストリームおよびダウンストリーム システムがプライマリからセカンダリにも接続する必要がある | セカンダリ接続を最小限の重要なサブセットに制限します。 |
複数リージョンのディザスター リカバリープランを作成するときは、次の推奨事項を考慮してください:
障害が発生した場合に必要とする最小限のビジネス機能とその理由を決定します。 たとえば、データ変換層 (黄色で示されています) "および" データ サービス層 (青色で表示) にフェールオーバー機能が必要か、またはデータ サービス層にだけフェールオーバーが必要かを評価します。
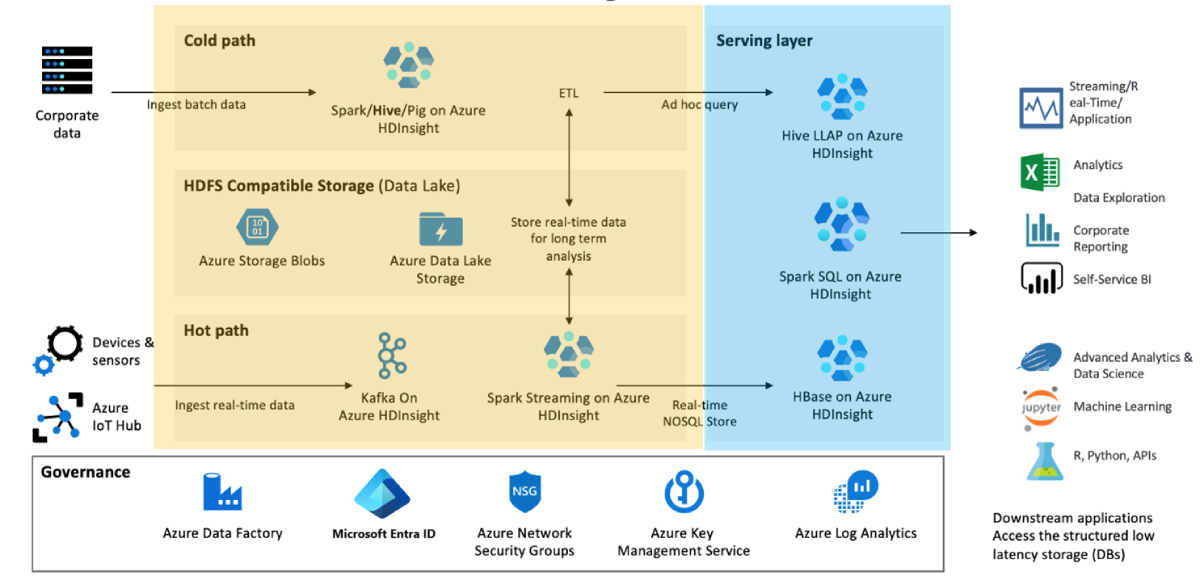
ワークロード、開発ライフサイクル、および部門に基づいてクラスターを分割します。 クラスターを複数にすることで、単一の大きな障害によって複数の異なるビジネス プロセスが影響を受ける可能性が減少します。
セカンダリ リージョンを読み取り専用にします。 フェールオーバー リージョンに読み取りと書き込みの両方の機能があると、アーキテクチャが複雑になる可能性があります。
障害が発生したとき、一時的なクラスターの方が管理が容易です。 クラスターの循環ができるように、また、状態がクラスターに保持されないように、ワークロードを設計します。
障害が発生し、新しいリージョンで再起動する必要がある場合、ワークロードが未完了のままになることがよくあります。 ワークロードを本質的にべき等になるように設計します。
障害が発生した場合に迅速かつ完全に自動化されたデプロイを実現するために、クラスターのデプロイ時に自動化を使用し、クラスター構成設定を可能な限りスクリプト化します。
停止の検出、通知、管理
HDInsight で Azure 監視ツールを使用して、クラスター内の異常な動作を検出し、対応するアラート通知を設定します。 特定のクラスターの種類についての重要なパフォーマンス メトリックを収集する、構成済みの HDInsight クラスター固有の管理ソリューションをデプロイできます。 詳細については、HDInsight 用の Azure Monitoring に関するページを参照してください。
Azure の正常性アラートをサブスクライブして、サービスの問題と計画メンテナンスについて、および、サブスクリプション、サービス、またはリージョンの正常性とセキュリティに関するアドバイザリについての通知を受け取ります。 問題の原因と確定 ETA を含む正常性の通知は、フェールオーバーとフェールバックをより適切に実行するのに役立ちます。 詳細については、Azure Service Health のドキュメントを参照してください。
単一リージョンの地域でのディザスター リカバリー
基本的な HDInsight システムの各コンポーネントには、独自の単一リージョンフォールト トレランス メカニズムがあります。 ビジネス機能に影響を与えるのは、必ずしも致命的なイベントが必要であるとは限りません。 1 つのリージョンにある次の 1 つ以上のサービスでのサービス インシデントによって、想定されているビジネス機能が失われる可能性もあります。
Compute (仮想マシン): Azure HDInsight クラスター。 HDInsight によって 99.9% の可用性 SLA が提供されます。 単一のデプロイで高可用性を実現するために、HDInsight には、既定で高可用性モードになっている多くのサービスが付属しています。 HDInsight のフォールト トレランス メカニズムは、Microsoft と Apache OSS エコシステムの両方の高可用性サービスによって提供されます。
次の インフラストラクチャ コンポーネントは、高可用性を実現するように設計されています:
- アクティブおよびスタンバイ ヘッドノード
- 複数のゲートウェイ ノード
- 3 つの Zookeeper Quorum ノード
- 障害と更新の各ドメイン別に分散されたワーカー ノード
次のサービスは、高可用性を実現するように設計されています:
- Apache Ambari Server
- YARN 用アプリケーション タイムライン サーバー
- Hadoop MapReduce 用ジョブ履歴サーバー
- Apache Livy
- HDFS
- YARN Resource Manager
- HBase Master
詳細については、「Azure HDInsight でサポートされている高可用性サービス」を参照してください。
メタストア: Azure SQL Database。 HDInsight には、99.99% の SLA を提供するメタストアとして Azure SQL Database が使用されています。 同期レプリケーションを使用して、1 つのデータ センター内にデータのレプリカが 3 つ保持されます。 1 つのレプリカが失われた場合、代替レプリカがシームレスに提供されます。 アクティブ geo レプリケーションは、最大 4 つのデータ センターで、すぐに使用できます。 手動またはデータ センターのいずれかのフェールオーバーが発生すると、階層内の最初のレプリカが自動的に読み取り書き込み可能になります。 詳細については、Azure SQL Database によるビジネス継続性に関する記事を参照してください。
Storage: Azure Data Lake Gen2 または Blob ストレージ。 HDInsight の基になるストレージ層として推奨されるのは、Azure Data Lake Storage Gen2 です。 Azure Data Lake Storage Gen2 を含め、Azure Storage によって 99.9% の SLA が提供されます。 HDInsight には、1 つのデータ センター内にデータのレプリカが 3 つ保持される LRS サービスが使用され、レプリケーションは同期的に行われます。 1 つのレプリカが失われた場合、1 つのレプリカがシームレスに提供されます。
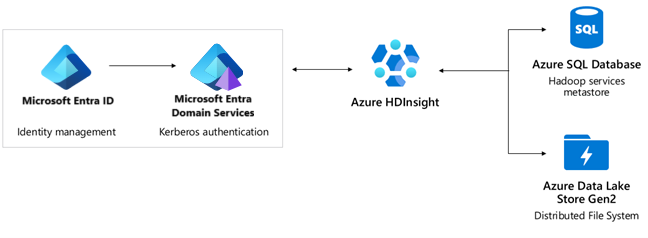
認証: Microsoft Entra ID、 Microsoft Entra Domain サービス、Enterprise セキュリティ パッケージ。
- Microsoft Entra ID は 99.9% の SLA を提供します。 Active Directory は、複数レベルの内部冗長性と自動回復性を備えたグローバル サービスです。 詳細については、「Microsoft Entra ID の信頼性を継続的に向上させている Microsoftの方法」をご覧ください。
- Microsoft Entra Domain Servicesは 99.9% の SLA を提供します。 Microsoft Entra Domain サービスは、グローバルに分散されたデータ センターでホストされる可用性の高いサービスです。 レプリカ セットは Microsoft Entra Domain サービスのプレビュー機能であり、Azure リージョンがオフラインになった場合に、地理的なディザスター リカバリーを実現します。 詳細については、「Microsoft Entra Domain サービスのレプリカ セットの概念と機能」を参照してください。
- Azure DNS によって 100% の SLA が提供されます。 HDInsight には、ドメイン名を解決するためにさまざまな場所で Azure DNS が使用されています。
Azure Key Vault と Azure Data Factory などのオプション サービス。