Azure Data Factory と Synapse Analytics のデータのコピー ツール
適用対象:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新しい試用版を開始する方法について説明します。
データのコピー ツールを使うと、通常はエンド ツー エンドのデータ統合シナリオの最初の手順である、Data Lake へのデータの取り込みプロセスが容易になり、最適化されます。 時間が短縮され、サービスを使って初めてデータ ソースからデータを取り込むときに特に効果があります。 このツールには次のような利点があります。
- データのコピー ツールを使うときに、リンクされたサービス、データセット、パイプライン、アクティビティ、トリガーのサービスでの定義を理解している必要はありません。
- データのコピー ツールでは、直感的にわかるフローでデータを Data Lake に読み込むことができます。 ツールでは、選んだコピー元データ ストアから選んだコピー先/シンク データ ストアにデータをコピーするために必要なすべてのリソースが自動的に作成されます。
- データのコピー ツールでは、作成時に取り込まれるデータを検証できるので、データ自体に最初からエラーが存在する可能性を回避するのに役立ちます。
- Data Lake にデータを読み込むために複雑なビジネス ロジックを実装する必要がある場合でも、UI でのアクティビティごとの作成を使って、データのコピー ツールによって作成されるリソースを編集できます。
次の表では、データのコピー ツールを使う場合と、UI のアクティビティごとの作成を使う場合の指針を示します。
| データのコピー ツール | アクティビティごと (コピー アクティビティ) の作成 |
|---|---|
| エンティティ (リンクされたサービス、データセット、パイプラインなど) について理解することなく、データ読み込みタスクを簡単に作成したい場合。 | Lake にデータを読み込むための複雑で柔軟性の高いロジックを実装したい場合。 |
| 大量のデータ アーティファクトを Data lake にすばやく読み込みたい場合。 | データのクレンジングや処理のためにコピー アクティビティを後続のアクティビティと連鎖させたい場合。 |
データのコピー ツールを起動するには、Data Factory または Synapse Studio UI のホーム ページで [取り込み] タイルをクリックします。
データのコピー ツールを起動すると、2 種類のタスクが表示されます。1 つは組み込みのコピー タスクで、もう 1 つはメタデータ駆動のコピー タスクです。 組み込みのコピー タスクを使用すると、5 分以内にパイプラインが作成され、エンティティについて学習しなくてもデータをレプリケートできます。 大量のオブジェクト (数千のテーブルなど) の大規模なコピーを管理するための、パラメーター化されたパイプラインと外部制御テーブルを簡単に作成できる、メタデータ駆動のコピー タスク。 詳細については、メタデータ駆動のデータのコピーに関する記事を参照してください。
Data lake にデータを読み込むための直感的なフロー
このツールを使うと、直感的なフローに従って、さまざまなコピー元からコピー先にデータを数分以内で簡単に移動することができます。
コピー元の設定を構成します。
コピー先の設定を構成します。
列のマッピング、パフォーマンスの設定、フォールト トレランスの設定など、コピー操作の詳細な設定を構成します。
データ読み込みタスクのスケジュールを指定します。
作成されるエンティティの概要を確認します。
必要に応じてパイプラインを編集し、コピー アクティビティの設定を更新します。
このツールは最初からビッグ データを考慮して設計されており、さまざまな種類のデータとオブジェクトをサポートしています。 何百ものフォルダー、ファイル、テーブルの移動に使うことができます。 このツールは、自動データ プレビュー、スキーマのキャプチャと自動マッピング、およびデータのフィルター処理にも対応しています。
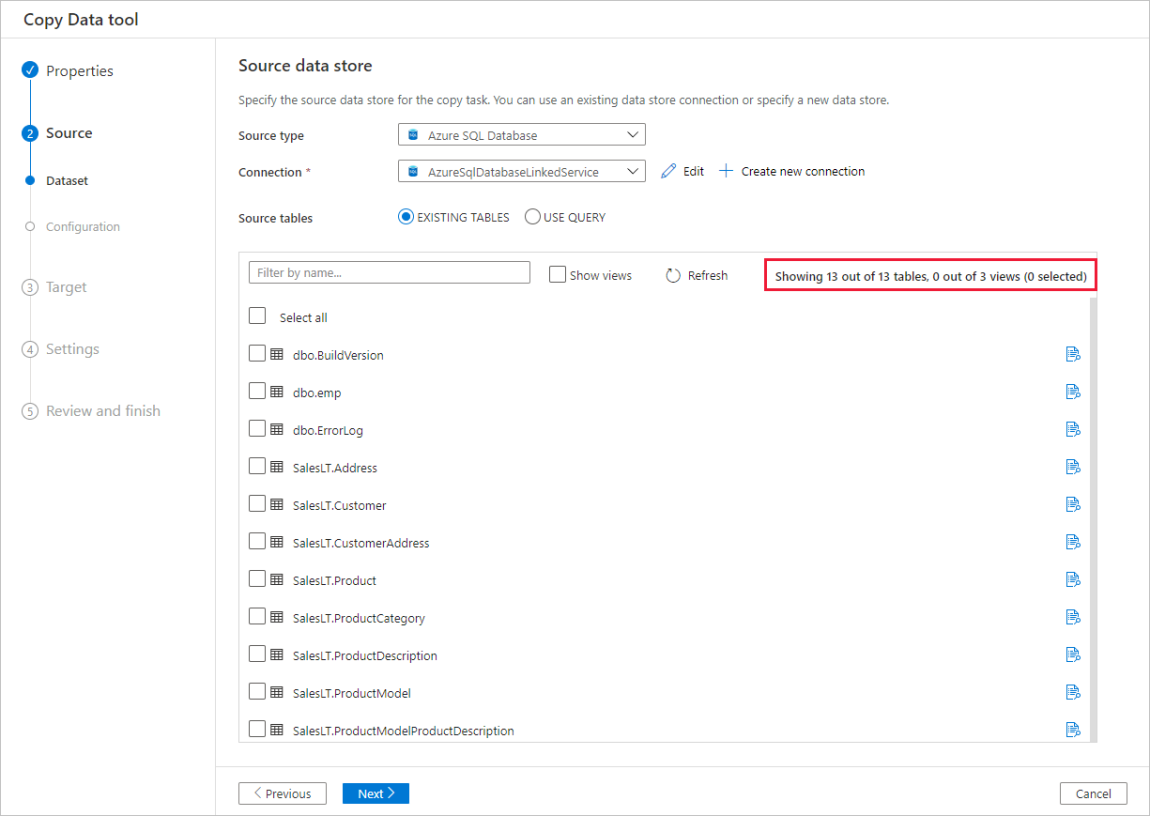
自動データ プレビュー
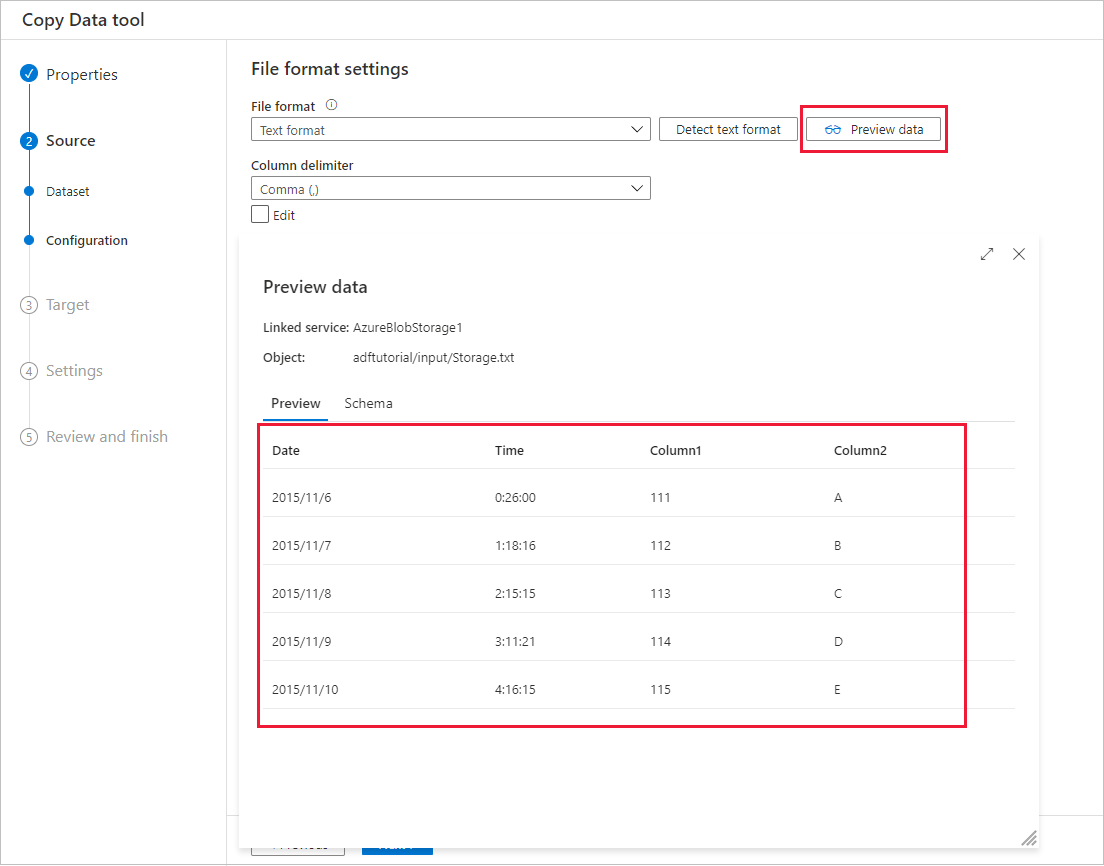
選んだコピー元データ ストアのデータの一部をプレビューすることができ、コピーされているデータを検証できます。 さらに、コピー元データがテキスト ファイル内にある場合は、データのコピー ツールによってテキスト ファイルが解析され、行および列の区切り記号とスキーマが自動的に検出されます。
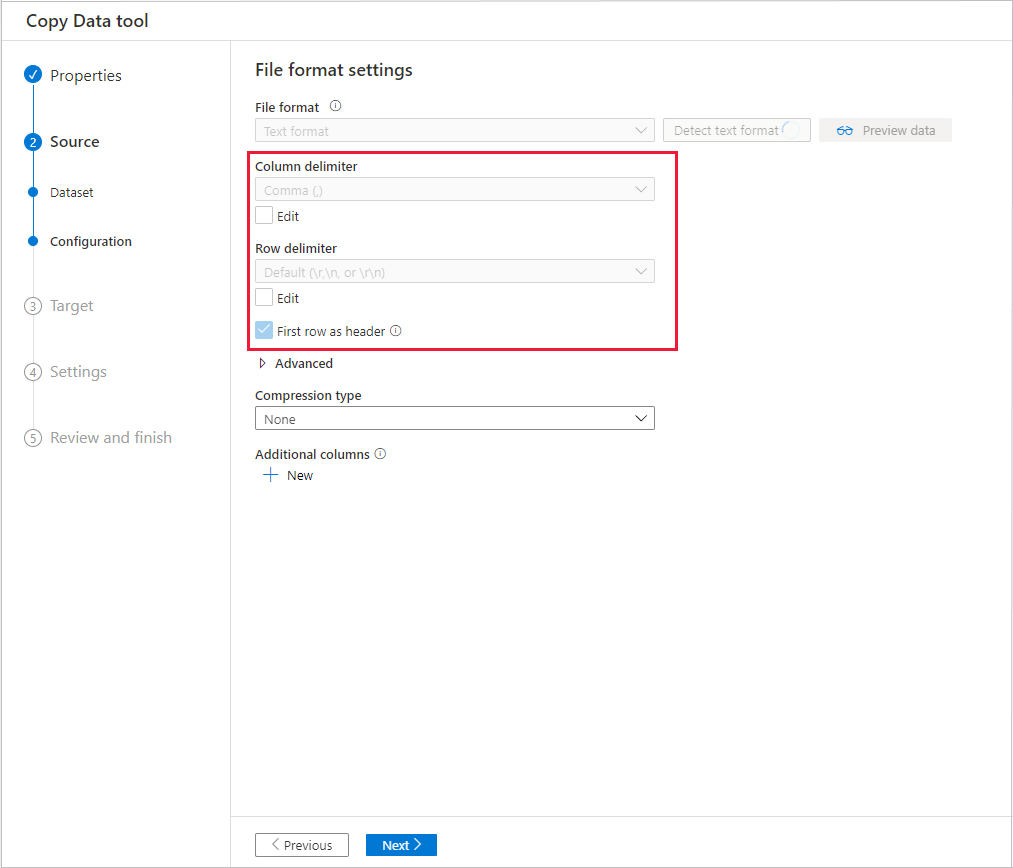
検出が完了したら、 [Preview data (データのプレビュー)] を選択します。
スキーマのキャプチャと自動マッピング
データ コピー元のスキーマがデータ コピー先のスキーマと異なることがよくあります。 このシナリオでは、ソース スキーマの列を宛先スキーマの列にマップする必要があります。
データのコピー ツールは、ユーザーがコピー元ストアとコピー先ストアの間で列をマッピングするときの操作を監視して学習します。 ユーザーがコピー元データ ストアから 1 つまたはいくつかの列を選び、それをコピー先スキーマにマップすると、データのコピー ツールはユーザーが両方の側で選んだ列ペアのパターンの分析を開始します。 その後、ツールは残りの列に同じパターンを適用します。 そのため、数クリックするだけで、すべての列が望ましい方法でコピー先にマップされることがわかります。 データのコピー ツールによって行われた列マッピングの選択に満足できない場合は、それを無視し、手動で列のマッピングを続けることができます。 その間もデータのコピー ツールはパターンの学習と更新を続けており、最終的にはユーザーが望む正しい列マッピングのパターンになります。
Note
SQL Server または Azure SQL Database から Azure Synapse Analytics にデータをコピーするとき、コピー先ストアにテーブルが存在しない場合、データのコピー ツールではコピー元のスキーマを使用したテーブルの自動作成がサポートされます。
データのフィルター処理
ソース データをフィルター処理して、シンク データ ストアにコピーする必要があるデータのみを選択できます。 フィルター処理によって、シンク データ ストアにコピーするデータの量が削減されるため、コピー操作のスループットが向上します。 データのコピー ツールは、SQL クエリ言語を使うことで、リレーショナル データベース内のデータまたは Azure Blob フォルダー内のファイルを、柔軟にフィルター処理できます。
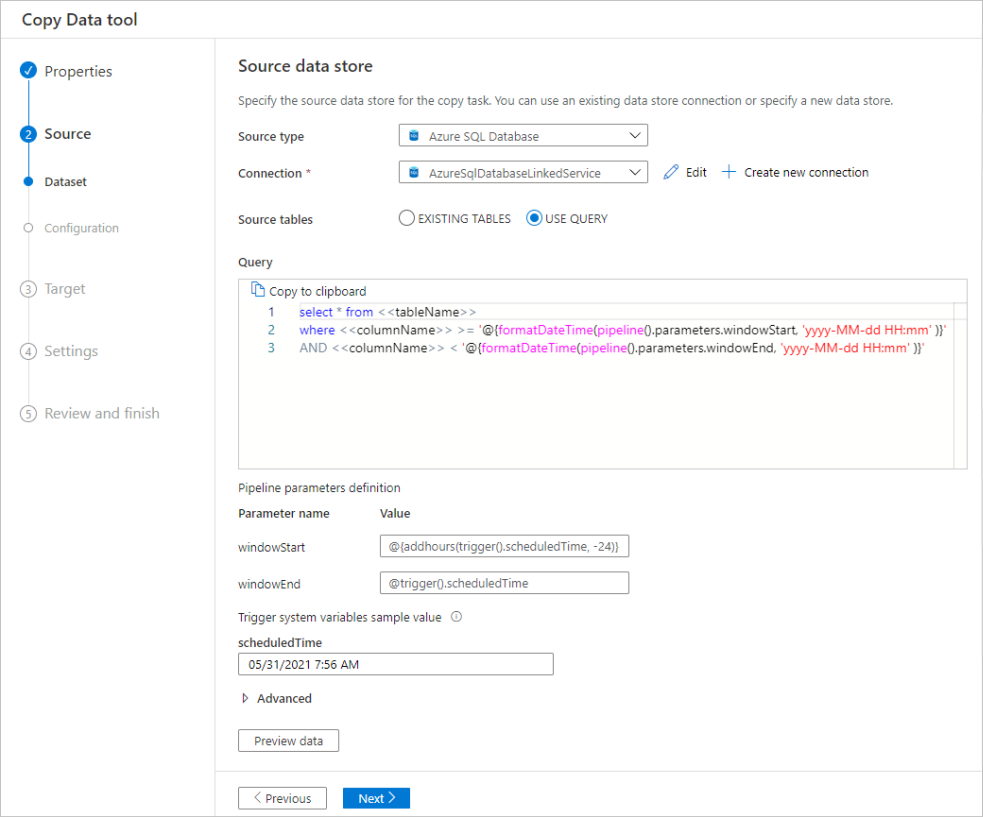
データベース内のデータのフィルター処理
次のスクリーンショットでは、データをフィルター処理する SQL クエリを示します。
Azure Blob フォルダー内のデータのフィルター処理
フォルダー パスに変数を使って、フォルダーからデータをコピーできます。 サポートされている変数は、 {year} 、 {month} 、 {day} 、 {hour} 、 {minute} です。 例: inputfolder/{year}/{month}/{day}。
次の形式の入力フォルダーがあるとします。
2016/03/01/01
2016/03/01/02
2016/03/01/03
...
[ファイルまたはフォルダー] の [参照] ボタンをクリックして、これらのフォルダーのいずれか (例: 2016->03->01->02) を参照し、[選択] をクリックします。 テキスト ボックスに 2016/03/01/02 と表示されます。
次に、2016 を {year} 、03 を {month} 、01 を {day} 、02 を {hour} にそれぞれ置き換え、Tab キーを押します。 ファイル読み込みの動作のセクションで増分読み込み: 時間的に分割されたフォルダ/ファイル名を選択し、プロパティ ページでスケジュールまたはタンブリング ウィンドウを選択すると、これら4つの変数の形式を選択するドロップダウン リストが表示されます。
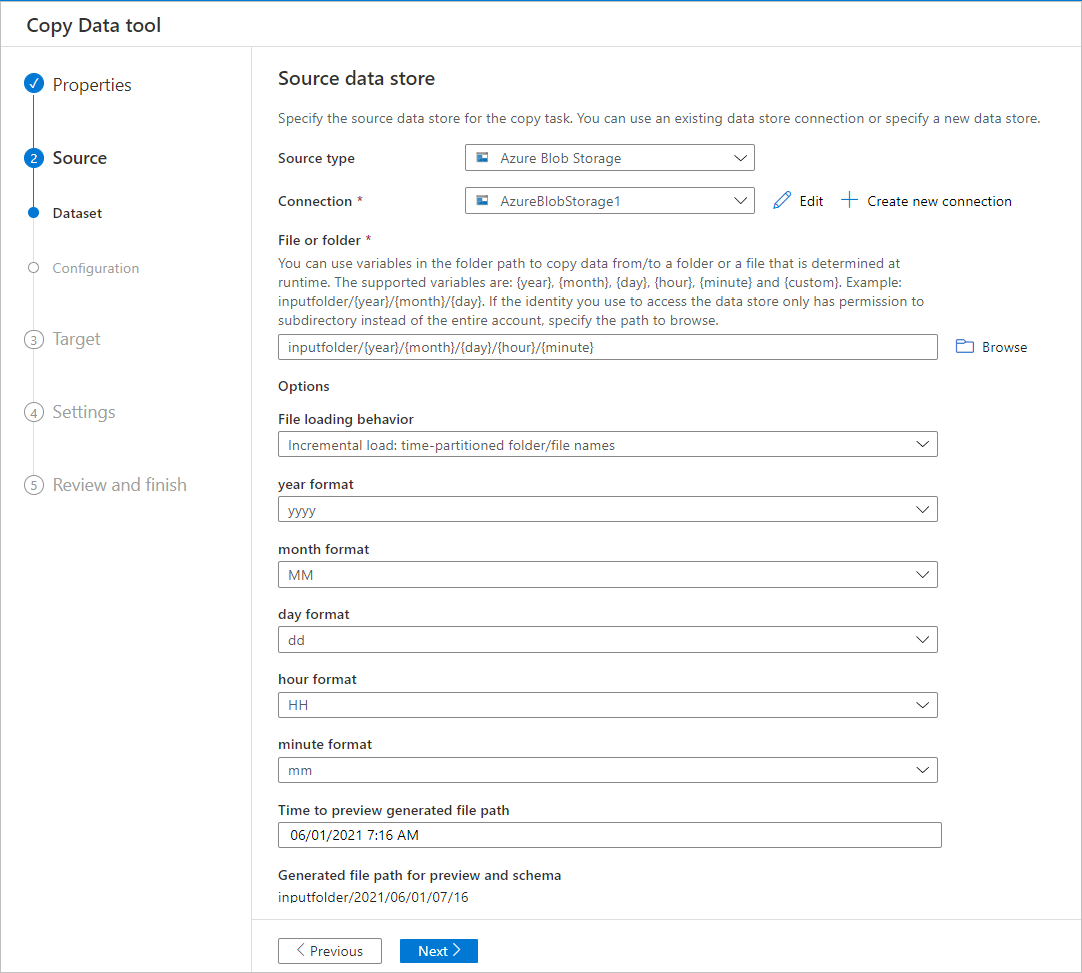
データのコピー ツールでは、式、関数、システム変数でパラメーターを生成し、パイプラインを作成するときにそれを使って {year}、{month}、{day}、{hour}、{minute} を表すことができます。
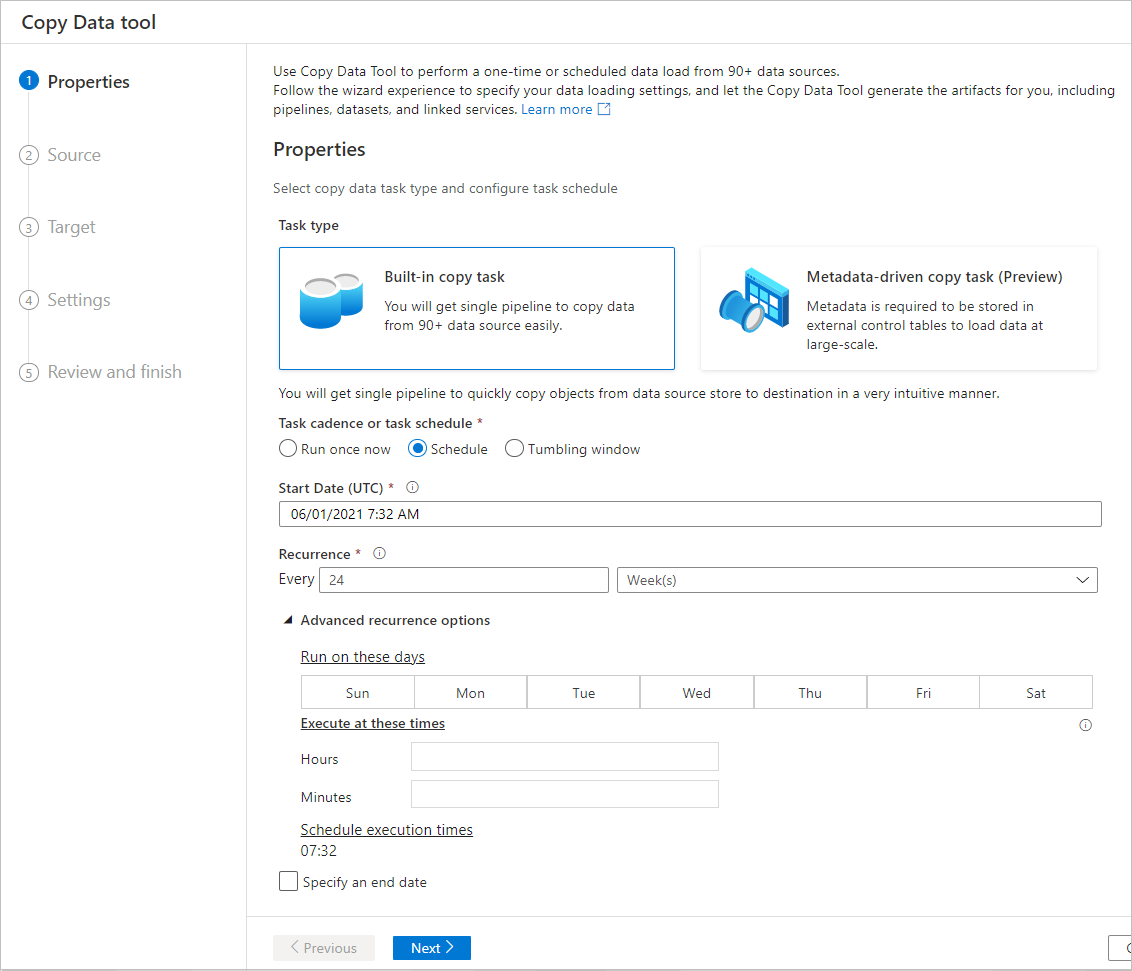
スケジュール オプション
コピー操作は 1 回だけ実行することも、スケジュールに従って (毎時、毎日など) 実行することもできます。 これらのオプションは、オンプレミス、クラウド、ローカル デスクトップといった異なる環境のコネクタに使うことができます。
1 回限りのコピー操作では、ソースからコピー先に 1 回だけデータを移動できます。 これは、サポートされている形式のあらゆるサイズのデータに適用されます。 スケジュールされたコピーでは、指定した繰り返しでデータをコピーできます。 豊富な設定 (再試行、タイムアウト、アラートなど) を使用して、スケジュールされたコピーを構成できます。
関連するコンテンツ
データのコピー ツールを使う以下のチュートリアルを試してください。