データのコピー ツールを使用して Azure Blob Storage から SQL データベースにデータをコピーする
適用対象:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新しい試用版を開始する方法について説明します。
このチュートリアルでは、Azure Portal を使用してデータ ファクトリを作成します。 次に、データのコピー ツールを使用して、Azure Blob Storage から SQL データベースにデータをコピーするパイプラインを作成します。
Note
Azure Data Factory を初めて使用する場合は、「Azure Data Factory の概要」を参照してください。
このチュートリアルでは、以下の手順を実行します。
- データ ファクトリを作成します。
- データのコピー ツールを使用してパイプラインを作成します。
- パイプラインとアクティビティの実行を監視します。
前提条件
- Azure サブスクリプション:Azure サブスクリプションをお持ちでない場合は、開始する前に 無料アカウント を作成してください。
- Microsoft Azure Storage アカウント:Blob Storage を "ソース" データ ストアとして使用します。 Azure ストレージ アカウントがない場合は、ストレージ アカウントの作成に関するページの手順を参照してください。
- Azure SQL Database:"シンク" データ ストアとして SQL データベースを使用します。 SQL データベースがない場合は、SQL データベースの作成に関するページの手順を参照してください。
SQL データベースを準備する
Azure サービスが Azure SQL Database の論理 SQL Server にアクセスできるようにします。
SQL データベースが実行されているサーバーの [Azure サービスおよびリソースにこのサーバーへのアクセスを許可する] 設定が有効になっていることを確認します。 この設定により、Data Factory はお使いのデータベース インスタンスにデータを書き込むことができます。 この設定を確認および有効にするには、論理 SQL サーバー > [セキュリティ] > [ファイアウォールと仮想ネットワーク] の順に移動し >[Azure サービスおよびリソースにこのサーバーへのアクセスを許可する] オプションを [オン] に設定します。
Note
[Azure サービスおよびリソースにこのサーバーへのアクセスを許可する] を選択すると、自分のサブスクリプション内のリソースに限らず、あらゆる Azure リソースから SQL Server にネットワークでアクセスできるようになります。 すべての環境に適しているわけではありませんが、この限定的なチュートリアルには適しています。 詳細については、Azure SQL Server のファイアウォール規則に関するページを参照してください。 代わりに、プライベート エンドポイントを使用して、パブリック IP を使用せずに、Azure PaaS サービスに接続することもできます。
BLOB と SQL テーブルを作成する
次の手順を実行して、チュートリアルで使用する Blob Storage と SQL データベースを準備します。
ソース BLOB を作成する
メモ帳を起動します。 次のテキストをコピーし、inputEmp.txt というファイル名でディスクに保存します。
FirstName|LastName John|Doe Jane|Doeadfv2tutorial という名前のコンテナーを作成し、そこに inputEmp.txt ファイルをアップロードします。 これらのタスクは、Azure portal または各種ツール (Azure Storage Explorer など) を使用して実行できます。
シンク SQL テーブルを作成する
次の SQL スクリプトを使って、SQL データベースに
dbo.empという名前のテーブルを作ります。CREATE TABLE dbo.emp ( ID int IDENTITY(1,1) NOT NULL, FirstName varchar(50), LastName varchar(50) ) GO CREATE CLUSTERED INDEX IX_emp_ID ON dbo.emp (ID);
Data Factory の作成
左側のメニューで、 [リソースの作成]>[統合]>[Data Factory] を選択します。
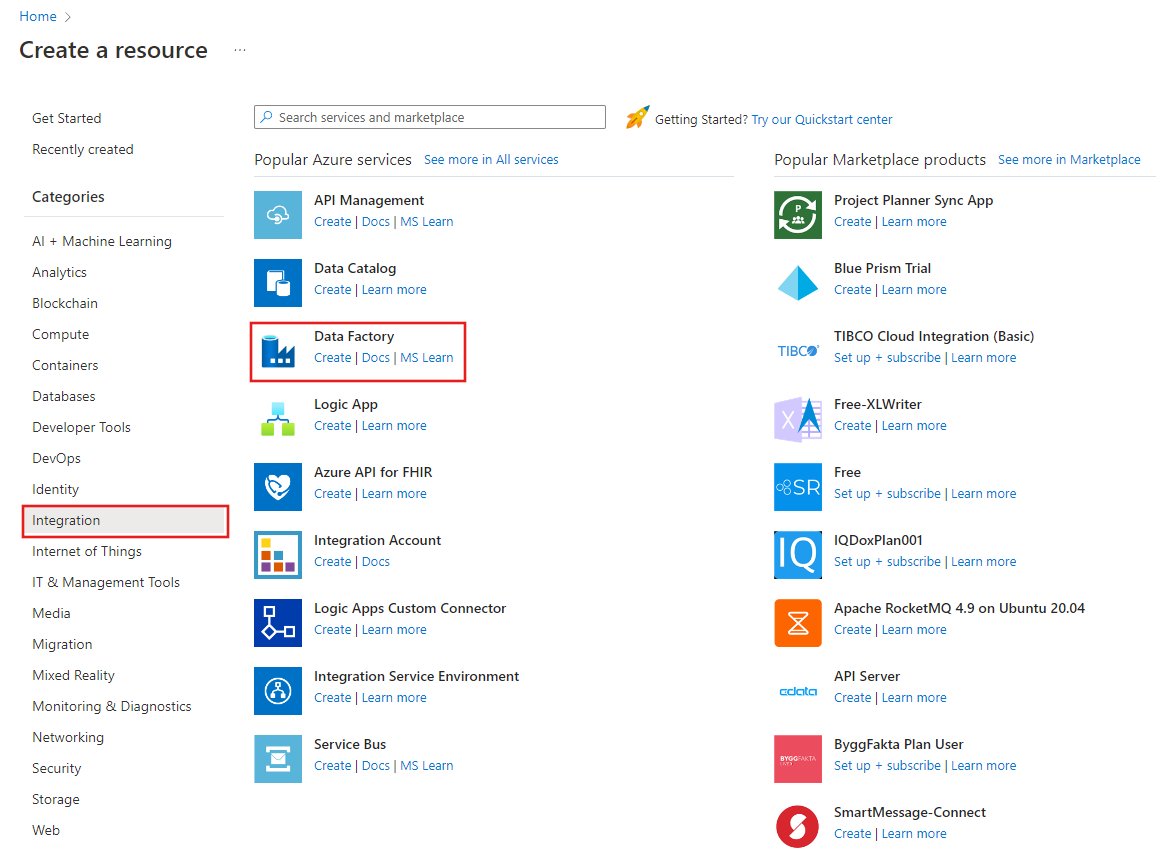
[新しいデータ ファクトリ] ページで、 [名前] に「ADFTutorialDataFactory」と入力します。
データ ファクトリの名前は "グローバルに一意" にする必要があります。 次のエラー メッセージが表示される場合があります。
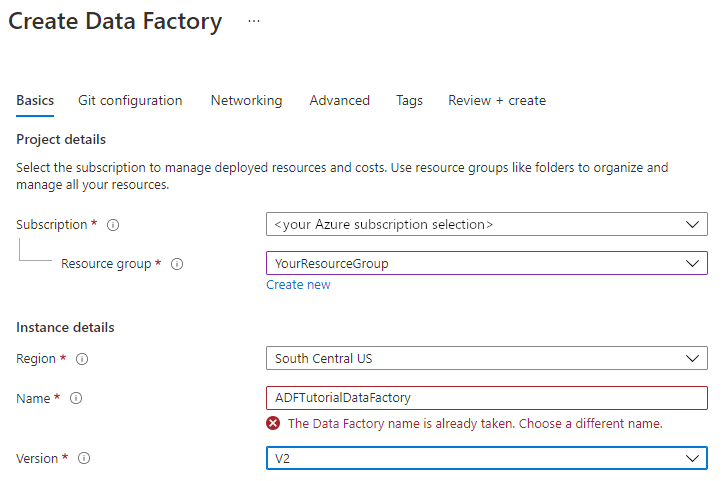
データ ファクトリの名前の値に関するエラー メッセージが表示された場合は、別の名前を入力してください。 たとえば、yournameADFTutorialDataFactory という名前を使用します。 Data Factory アーティファクトの名前付け規則については、Data Factory の名前付け規則に関する記事をご覧ください。
新しいデータ ファクトリの作成先となる Azure サブスクリプションを選択します。
[リソース グループ] で、次の手順のいずれかを行います。
a. [Use existing (既存のものを使用)] を選択し、ドロップダウン リストから既存のリソース グループを選択します。
b. [新規作成] を選択し、リソース グループの名前を入力します。
リソース グループの詳細については、リソース グループを使用した Azure のリソースの管理に関するページを参照してください。
[バージョン] で、バージョンとして [V2] を選択します。
[場所] で、データ ファクトリの場所を選択します。 サポートされている場所のみがドロップダウン リストに表示されます。 データ ファクトリによって使用されるデータ ストア (Azure Storage、SQL Database など) やコンピューティング (Azure HDInsight など) は、他の場所やリージョンに存在していてもかまいません。
[作成] を選択します
作成が完了すると、 [Data Factory] ホーム ページが表示されます。
![[Open Azure Data Factory Studio] タイルを含む、Azure Data Factory のホーム ページのスクリーンショット。](../reusable-content/ce-skilling/azure/media/data-factory/data-factory-home-page.png)
別のタブで Azure Data Factory ユーザー インターフェイス (UI) を起動するには、 [Open Azure Data Factory Studio]\(Azure Data Factory Studio を開く\) タイルで [開く] を選択します。
データのコピー ツールを使用してパイプラインを作成する
Azure Data Factory のホーム ページで、 [取り込み] タイルを選択し、データのコピー ツールを起動します。
データのコピー ツールの [プロパティ] ページで、 [タスクの種類] に [組み込みコピー タスク] を選択して、 [次へ] を選択します。
![[プロパティ] ページを示すスクリーンショット。](media/tutorial-copy-data-tool/copy-data-tool-properties-page.png)
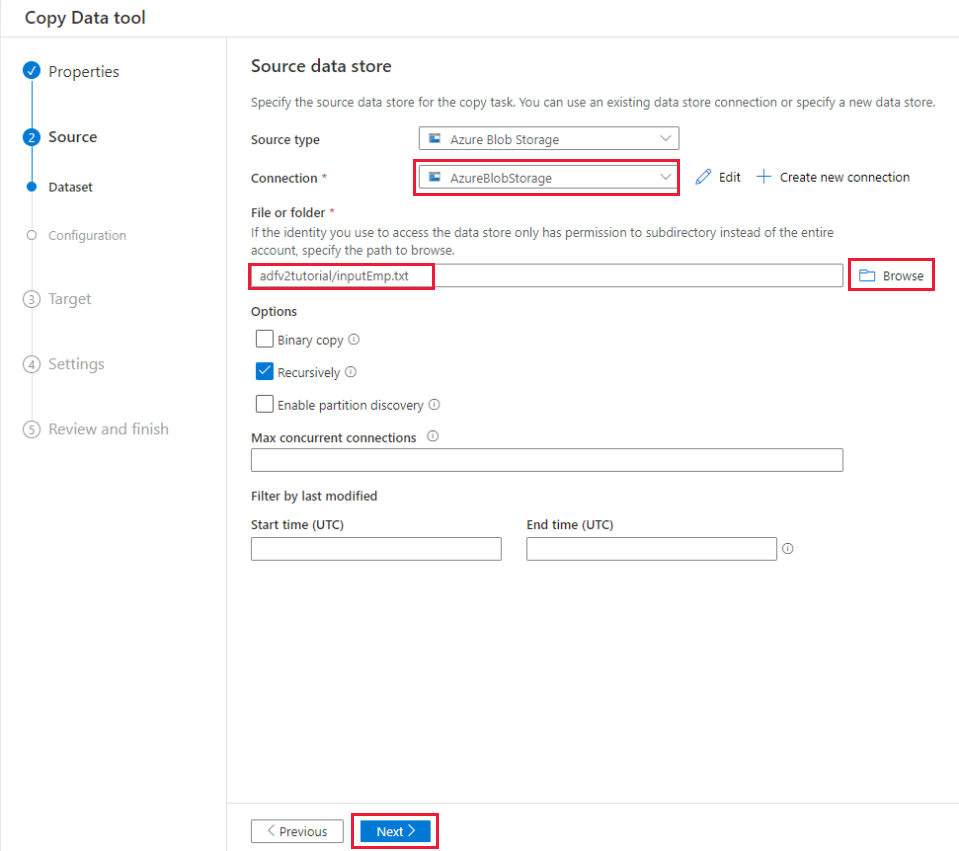
[ソース データ ストア] ページで、次の手順を実行します。
a. [+ 新しい接続の作成] を選択して、接続を追加します。
b. ギャラリーから [Azure Blob Storage] を選択し、 [続行] を選択します。
c. [新しい接続 (Azure Blob Storage)] ページで、 [Azure サブスクリプション] の一覧から Azure サブスクリプションを選択し、 [ストレージ アカウント名] の一覧からストレージ アカウントを選択します。 接続をテストし、 [作成] を選択します。
d. [接続] ブロックで、新しく作成したリンク サービスをソースとして選択します。
e. [ファイルまたはフォルダー] セクションで [参照] を選択して、adfv2tutorial フォルダーに移動します。inputEmp.txt ファイルを選択し、 [OK] を選択します。
f. [次へ] を選択して、次の手順に進みます。
[File format settings]\(ファイル形式設定\) ページで、 [First row as header]\(先頭の行をヘッダーにする\) のチェック ボックスをオンにします。 列と行の区切り記号が自動的に検出されることに注目してください。このページの [データのプレビュー] ボタンを選択すると、データをプレビューし、入力データのスキーマを表示できます。 [次へ] を選択します。
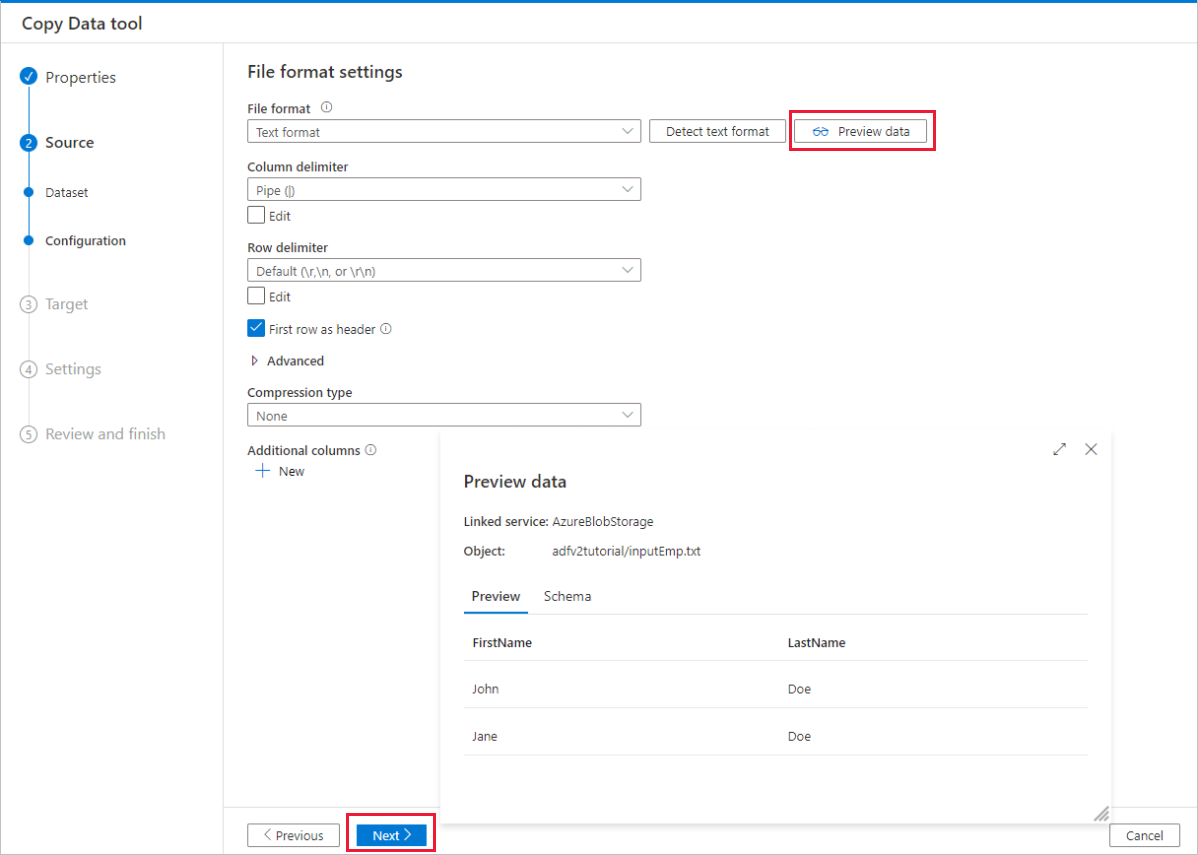
[ターゲット データ ストア] ページで、次の手順を実行します。
a. [+ 新しい接続の作成] を選択して、接続を追加します。
b. ギャラリーで [Azure SQL Database] を選択し、 [続行] を選択します。
c. [New connection (Azure SQL Database)]\(新しい接続 (Azure SQL Database)\) ページで、ドロップダウン リストから Azure サブスクリプション、サーバー名、データベース名を選択します。 次に、 [認証タイプ] で [SQL 認証] を選択し、ユーザー名とパスワードを指定します。 接続をテストし、 [作成] を選択します。
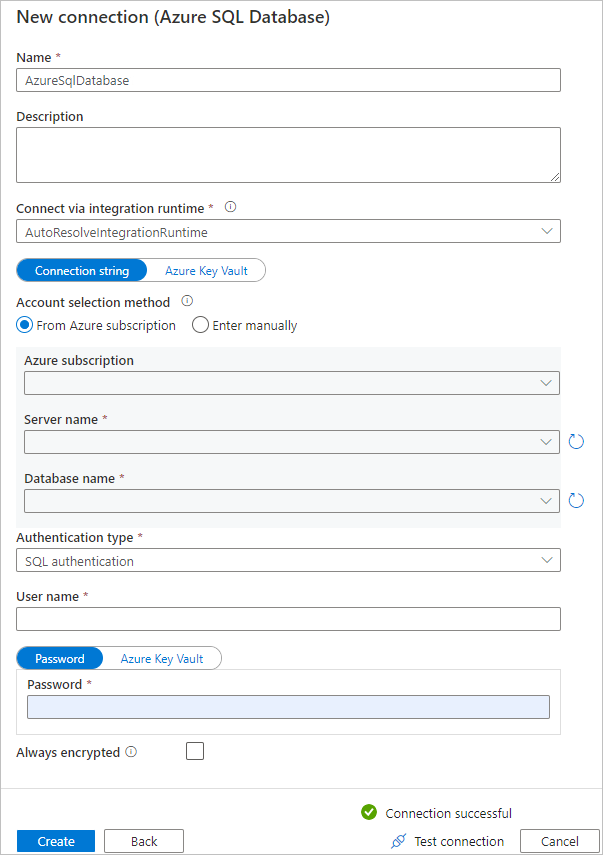
d. 新しく作成したリンクされたサービスをシンクとして選択し、 [次へ] を選択します。
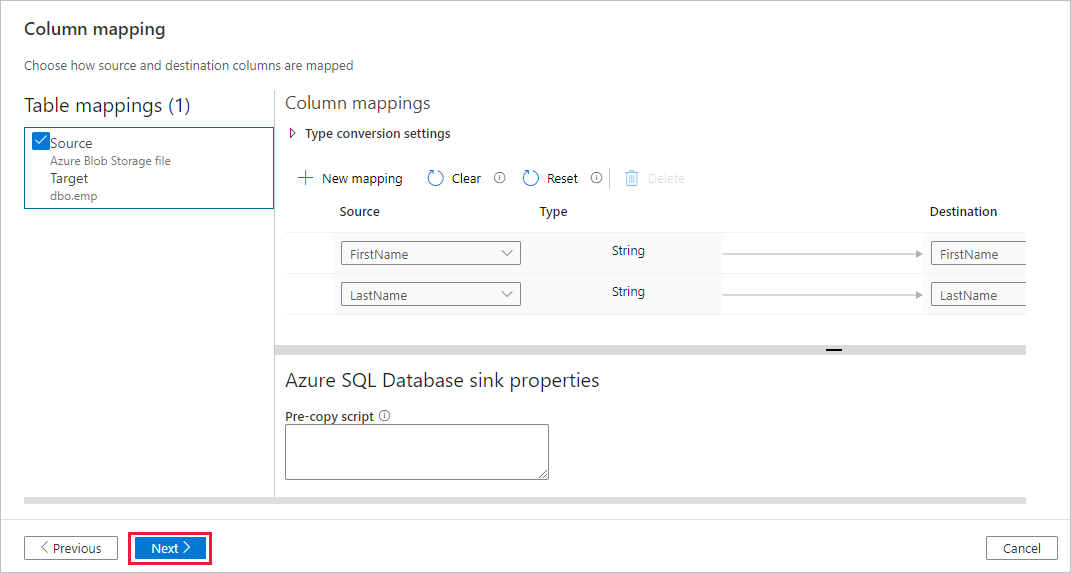
[配布先データ ストア] ページで [既存のテーブルを使用する] を選んで、
dbo.empテーブルを選びます。 [次へ] を選択します。[列マッピング] ページで、入力ファイルの 2 番目と 3 番目の列が emp テーブルの FirstName 列と LastName 列にマップされていることがわかります。 マッピングを調整して、エラーがないことを確認し、 [次へ] を選択します。
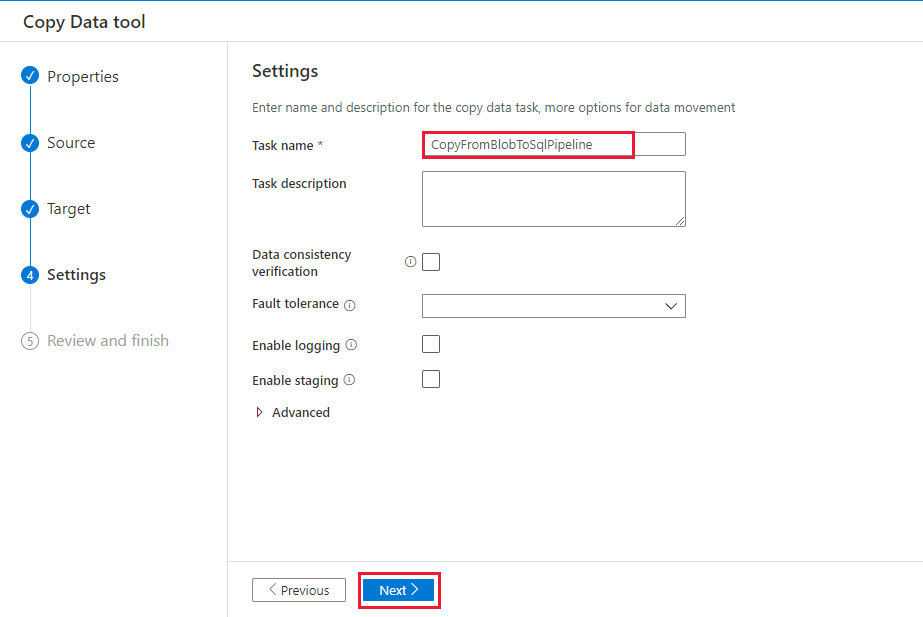
[設定] ページの [タスク名] に「CopyFromBlobToSqlPipeline」と入力し、 [次へ] を選択します。
[サマリー] ページで設定を確認し、 [次へ] を選択します。
[Deployment]\(デプロイ\) ページで [監視] を選択してパイプライン (タスク) を監視します。
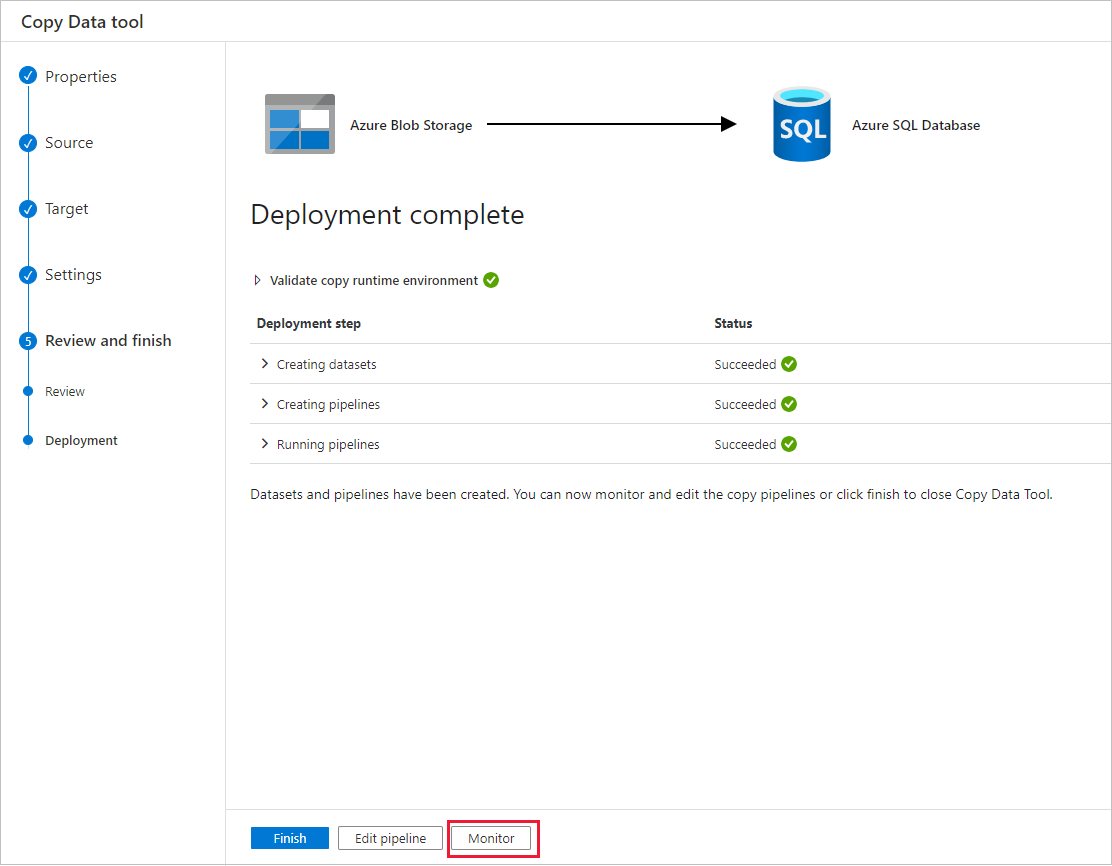
[パイプラインの実行] ページで、 [最新の情報に更新] を選択して一覧を更新します。 [パイプライン名] の下にあるリンクを選択して、アクティビティの実行の詳細を表示するか、パイプラインを再実行します。
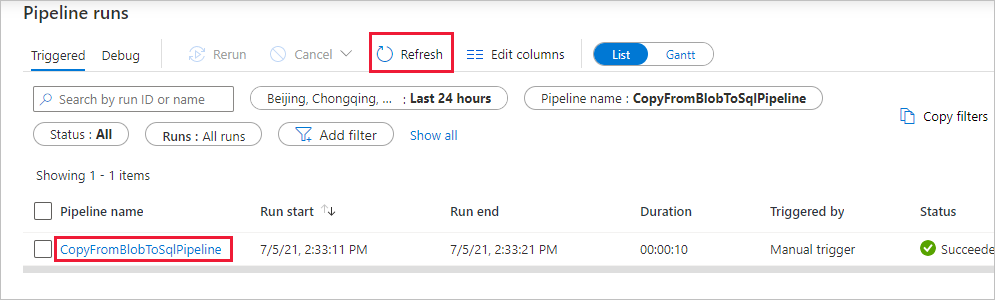
コピー操作の詳細については、[アクティビティの実行] ページで、 [アクティビティ名] 列の下にある [詳細] リンク (眼鏡アイコン) を選択します。 [パイプラインの実行] ビューに戻るには、階層リンク メニューの [すべてのパイプラインの実行] リンクを選択します。 表示を更新するには、 [最新の情報に更新] を選択します。
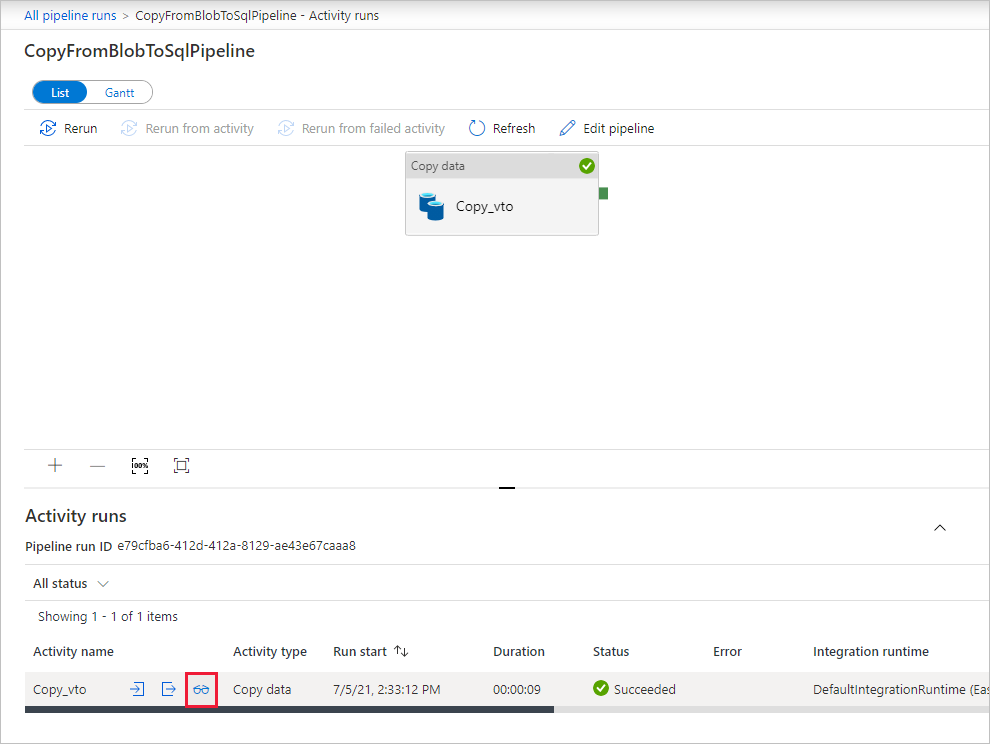
SQL データベースの dbo.emp テーブルにデータが挿入されたことを確認します。
左側の [作成者] タブを選択して、編集モードに切り替えます。 ツールによって作成されたリンクされたサービス、データセット、パイプラインをエディターで更新できます。 Data Factory UI におけるこれらのエンティティの編集について詳しくは、このチュートリアルの Azure Portal バージョンを参照してください。
![[作成者] タブの選択のスクリーンショット。](media/tutorial-copy-data-tool/author-tab.png)
関連するコンテンツ
このサンプルのパイプラインでは、Blob Storage から SQL データベースにデータがコピーされます。 以下の方法を学習しました。
- データ ファクトリを作成します。
- データのコピー ツールを使用してパイプラインを作成します。
- パイプラインとアクティビティの実行を監視します。
オンプレミスからクラウドにデータをコピーする方法について学習するには、次のチュートリアルに進んでください。