Azure Data Factory または Azure Synapse Analytics を使用して Azure Databricks Delta Lake との間でデータをコピーします
適用対象: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新しい試用版を開始する方法について説明します。
この記事では、Azure Data Factory および Azure Synapse のコピー アクティビティを使用して、Azure Databricks Delta Lake をコピー先またはコピー元としてデータをコピーする方法について説明します。 この記事は、コピー アクティビティの概要を示しているコピー アクティビティの記事に基づいています。
サポートされる機能
この Azure Databricks Delta Lake コネクタは、次の機能でサポートされます。
| サポートされる機能 | IR |
|---|---|
| Copy アクティビティ (ソース/シンク) | ① ② |
| マッピング データ フロー (ソース/シンク) | ① |
| Lookup アクティビティ | ① ② |
① Azure 統合ランタイム ② セルフホステッド統合ランタイム
一般に、このサービスは、さまざまなニーズを満たすために、次の機能を備えた Delta Lake をサポートしています。
- コピー アクティビティでは、サポートされている任意のソース データ ストアから Azure Databricks Delta Lake テーブル、および Delta Lake テーブルからサポートされている任意のシンク データ ストアにデータをコピーするために、Azure Databricks Delta Lake コネクタがサポートされています。 Databricks クラスターを活用してデータ移動を実行します。詳細については、「前提条件」セクションを参照してください。
- マッピング データ フローでは、ソースおよびシンクとして Azure Storage の汎用差分形式がサポートされています。これにより、コーディング不要の ETL の差分ファイルの読み取りと書き込みが可能になり、マネージド Azure Integration Runtime で実行されます。
- Databricks アクティビティでは、Delta Lake 上でコード中心の ETL または機械学習ワークロードを調整することがサポートされています。
前提条件
この Azure Databricks Delta Lake コネクタを使用するには、Azure Databricks でクラスターを設定する必要があります。
- Delta Lake にデータをコピーする場合、コピー アクティビティは Azure Databricks クラスターを呼び出して、Azure Storage からデータを読み取ります。これは元のソースまたはステージング領域で、サービスが組み込みのステージング コピーを介してソース データを最初に書き込みます。 詳細については、「シンクとしての Delta Lake」を参照してください。
- 同様に、Delta Lake からデータをコピーする場合、コピー アクティビティは Azure Databricks クラスターを呼び出して、Azure Storage にデータを書き込みます。これは元のシンクまたはステージング領域で、サービスが引き続き組み込みのステージング コピーを介して最終的なシンクにデータを書き込みます。 詳細については、「ソースとしての Delta Lake」を参照してください。
Databricks クラスターは、Azure Blob または Azure Data Lake Storage Gen2 アカウントにアクセスできる必要があります。これは、ソース/シンク/ステージングに使用されるストレージ コンテナー/ファイル システムと、Data Lake テーブルを書き込むコンテナー/ファイル システムの両方です。
Azure Data Lake Storage Gen2 を使用するために、Apache Spark 構成の一部として、Databricks クラスターでサービス プリンシパルを構成できます。 サービス プリンシパルを使用した直接アクセスに関する記事の手順に従います。
Azure Blob Storage を使用するには、Apache Spark 構成の一部として、Databricks クラスターでストレージ アカウント アクセス キーまたは SAS トークンを構成します。 「RDD API を使用した Azure Blob Storage へのアクセス」の手順に従います。
コピー アクティビティの実行中、構成したクラスターが終了した場合は、自動的に開始されます。 オーサリング UI を使用してパイプラインを作成する場合、データのプレビューなどの操作にはライブ クラスターが必要ですが、クラスターが起動されることはありません。
クラスター構成の指定
[クラスター モード] ドロップダウンで、 [標準] を選択します。
[Databricks Runtime のバージョン] ドロップダウンで、Databricks Runtime のバージョンを選択します。
Spark 構成に次のプロパティを追加して、自動最適化をオンにします。
spark.databricks.delta.optimizeWrite.enabled true spark.databricks.delta.autoCompact.enabled true統合とスケーリングのニーズに応じて、クラスターを構成します。
クラスター構成の詳細については、「クラスターの構成」を参照してください。
はじめに
パイプラインでコピー アクティビティを実行するには、次のいずれかのツールまたは SDK を使用します。
UI を使って Azure Databricks Delta Lake へのリンク サービスを作成する
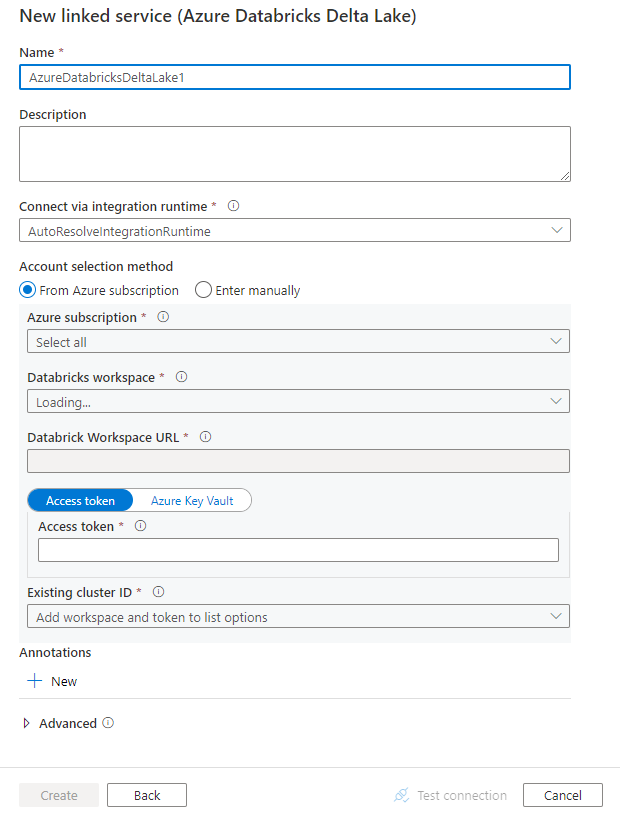
次の手順を使用して、Azure portal UI で Azure Databricks Delta Lake へのリンク サービスを作成します。
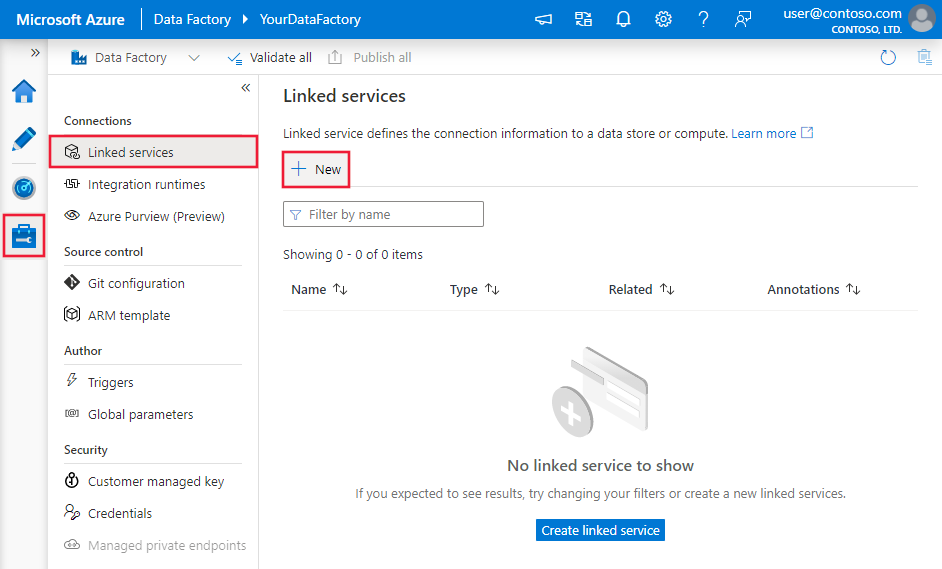
Azure Data Factory または Synapse ワークスペースの [管理] タブに移動し、[リンク サービス] を選択して、[新規] をクリックします。
デルタを検索し、Azure Databricks Delta Lake コネクタを選択します。

サービスの詳細を構成し、接続をテストして、新しいリンク サービスを作成します。
コネクタの構成の詳細
次のセクションでは、Azure Databricks Delta Lake コネクタに固有のエンティティを定義するプロパティについて詳しく説明します。
リンクされたサービスのプロパティ
この Azure Databricks Delta Lake コネクタは、次の種類の認証をサポートしています。 詳細については、対応するセクションをご覧ください。
アクセス トークン
Azure Databricks Delta Lake のリンクされたサービスでは、次のプロパティがサポートされています。
| プロパティ | 内容 | 必須 |
|---|---|---|
| type | type プロパティは、AzureDatabricksDeltaLake に設定する必要があります。 | はい |
| domain | Azure Databricks ワークスペースの URL を指定します (例: https://adb-xxxxxxxxx.xx.azuredatabricks.net)。 |
|
| clusterId | 既存のクラスターのクラスター ID を指定します。 これは作成済みの対話型クラスターでなければなりません。 対話型クラスターのクラスター ID は Databricks ワークスペース -> クラスター -> 対話型クラスター名 -> 構成 -> タグで見つけることができます。 詳細については、こちらを参照してください。 |
|
| accessToken | サービスの Azure Databricks の認証にはアクセス トークンが必要です。 アクセス トークンは、Databricks ワークスペースから生成する必要があります。 アクセス トークンを見つける詳細な手順については、こちらを参照してください。 | |
| connectVia | データ ストアに接続するために使用される統合ランタイム。 Azure 統合ランタイムまたはセルフホステッド統合ランタイムを使用できます (データ ストアがプライベート ネットワークにある場合)。 指定されていない場合は、既定の Azure 統合ランタイムが使用されます。 | いいえ |
例:
{
"name": "AzureDatabricksDeltaLakeLinkedService",
"properties": {
"type": "AzureDatabricksDeltaLake",
"typeProperties": {
"domain": "https://adb-xxxxxxxxx.xx.azuredatabricks.net",
"clusterId": "<cluster id>",
"accessToken": {
"type": "SecureString",
"value": "<access token>"
}
}
}
}
システム割り当てマネージド ID 認証
Azure リソースのシステム割り当てマネージド ID について詳しくは、Azure リソースのシステム割り当てマネージド ID に関する記事を参照してください。
システム割り当てマネージド ID 認証を使用するには、次の手順に従ってアクセス許可を付与します。
データ ファクトリまたは Synapse ワークスペースと共に生成されたマネージド ID オブジェクト ID の値をコピーして、マネージド ID 情報を取得します。
Azure Databricks でマネージド ID に適切なアクセス許可を付与します。 一般に、Azure Databricks のアクセス制御 (IAM) で、少なくとも共同作成者ロールをシステム割り当てマネージド ID に付与する必要があります。
Azure Databricks Delta Lake のリンクされたサービスでは、次のプロパティがサポートされています。
| プロパティ | 内容 | 必須 |
|---|---|---|
| type | type プロパティは、AzureDatabricksDeltaLake に設定する必要があります。 | はい |
| domain | Azure Databricks ワークスペースの URL を指定します (例: https://adb-xxxxxxxxx.xx.azuredatabricks.net)。 |
はい |
| clusterId | 既存のクラスターのクラスター ID を指定します。 これは作成済みの対話型クラスターでなければなりません。 対話型クラスターのクラスター ID は Databricks ワークスペース -> クラスター -> 対話型クラスター名 -> 構成 -> タグで見つけることができます。 詳細については、こちらを参照してください。 |
はい |
| workspaceResourceId | Azure Databricks のワークスペース リソース ID を指定します。 | はい |
| connectVia | データ ストアに接続するために使用される統合ランタイム。 Azure 統合ランタイムまたはセルフホステッド統合ランタイムを使用できます (データ ストアがプライベート ネットワークにある場合)。 指定されていない場合は、既定の Azure 統合ランタイムが使用されます。 | いいえ |
例:
{
"name": "AzureDatabricksDeltaLakeLinkedService",
"properties": {
"type": "AzureDatabricksDeltaLake",
"typeProperties": {
"domain": "https://adb-xxxxxxxxx.xx.azuredatabricks.net",
"clusterId": "<cluster id>",
"workspaceResourceId": "<workspace resource id>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
ユーザー割り当てマネージド ID 認証
Azure リソースのユーザー割り当てマネージド ID について詳しくは、ユーザー割り当てマネージド ID に関する記事を参照してください。
ユーザー割り当てマネージド ID 認証を使用するには、次の手順に従います。
1 つ以上のユーザー割り当てマネージド ID を作成して、Azure Databricks でアクセス許可を付与します。 一般に、Azure Databricks のアクセス制御 (IAM) で、少なくとも共同作成者ロールをユーザー割り当てマネージド ID に付与する必要があります。
1 つ以上のユーザー割り当てマネージド ID をデータ ファクトリまたは Synapse ワークスペースに割り当て、ユーザー割り当てマネージド ID ごとに資格情報を作成します。
Azure Databricks Delta Lake のリンクされたサービスでは、次のプロパティがサポートされています。
| プロパティ | 内容 | 必須 |
|---|---|---|
| type | type プロパティは、AzureDatabricksDeltaLake に設定する必要があります。 | はい |
| domain | Azure Databricks ワークスペースの URL を指定します (例: https://adb-xxxxxxxxx.xx.azuredatabricks.net)。 |
はい |
| clusterId | 既存のクラスターのクラスター ID を指定します。 これは作成済みの対話型クラスターでなければなりません。 対話型クラスターのクラスター ID は Databricks ワークスペース -> クラスター -> 対話型クラスター名 -> 構成 -> タグで見つけることができます。 詳細については、こちらを参照してください。 |
はい |
| 資格情報 | ユーザー割り当てマネージド ID を資格情報オブジェクトとして指定します。 | はい |
| workspaceResourceId | Azure Databricks のワークスペース リソース ID を指定します。 | はい |
| connectVia | データ ストアに接続するために使用される統合ランタイム。 Azure 統合ランタイムまたはセルフホステッド統合ランタイムを使用できます (データ ストアがプライベート ネットワークにある場合)。 指定されていない場合は、既定の Azure 統合ランタイムが使用されます。 | いいえ |
例:
{
"name": "AzureDatabricksDeltaLakeLinkedService",
"properties": {
"type": "AzureDatabricksDeltaLake",
"typeProperties": {
"domain": "https://adb-xxxxxxxxx.xx.azuredatabricks.net",
"clusterId": "<cluster id>",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
},
"workspaceResourceId": "<workspace resource id>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
データセットのプロパティ
データセットを定義するために使用できるセクションとプロパティの完全な一覧については、データセットに関する記事をご覧ください。
Azure Databricks Delta Lake データセットでは、次のプロパティがサポートされます。
| プロパティ | 内容 | 必須 |
|---|---|---|
| type | データセットの type プロパティには、AzureDatabricksDeltaLakeDataset を設定する必要があります。 | はい |
| database | データベースの名前です。 | ソースの場合はいいえ、シンクの場合ははい |
| table | デルタ テーブルの名前。 | ソースの場合はいいえ、シンクの場合ははい |
例:
{
"name": "AzureDatabricksDeltaLakeDataset",
"properties": {
"type": "AzureDatabricksDeltaLakeDataset",
"typeProperties": {
"database": "<database name>",
"table": "<delta table name>"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"linkedServiceName": {
"referenceName": "<name of linked service>",
"type": "LinkedServiceReference"
}
}
}
コピー アクティビティのプロパティ
アクティビティの定義に利用できるセクションとプロパティの完全な一覧については、パイプラインに関する記事を参照してください。 このセクションでは、Azure Databricks Delta Lake のソースとシンクでサポートされるプロパティの一覧を示します。
ソースとしての Delta Lake
Azure Databricks Delta Lake からデータをコピーするために、コピー アクティビティの source セクションでは次のプロパティがサポートされています。
| プロパティ | 内容 | 必須 |
|---|---|---|
| type | コピー アクティビティのソースの type プロパティは AzureDatabricksDeltaLakeSource を設定する必要があります。 | はい |
| query | データを読み取るための SQL クエリを指定します。 タイム トラベル制御については、次のパターンに従います。 - SELECT * FROM events TIMESTAMP AS OF timestamp_expression- SELECT * FROM events VERSION AS OF version |
いいえ |
| exportSettings | デルタ テーブルからデータを取得するために使用される詳細設定。 | いいえ |
exportSettings の下: |
||
| type | エクスポート コマンドの種類。AzureDatabricksDeltaLakeExportCommand に設定します。 | Yes |
| dateFormat | 日付型を日付形式の文字列に書式設定します。 カスタム日付形式は datetime パターンの形式に従います。 指定しない場合は、既定値の yyyy-MM-dd が使用されます。 |
いいえ |
| timestampFormat | タイムスタンプ型をタイムスタンプ形式の文字列に書式設定します。 カスタム日付形式は datetime パターンの形式に従います。 指定しない場合は、既定値の yyyy-MM-dd'T'HH:mm:ss[.SSS][XXX] が使用されます。 |
いいえ |
Delta Lake から直接コピーする
シンクのデータ ストアと形式がこのセクションで説明する基準を満たす場合は、コピー アクティビティを使用して、Azure Databricks Delta テーブルからシンクに直接コピーできます。 設定が確認され、次の条件が満たされない場合は、コピー アクティビティの実行が失敗します。
シンクのリンクされたサービスは、Azure Blob Storage または Azure Data Lake Storage Gen2 です。 アカウントの資格情報は Azure Databricks クラスター構成で事前に構成されている必要があります。詳細については、「前提条件」を参照してください。
シンク データ形式は、次のように構成された Parquet、区切りテキスト、または Avro であり、ファイルではなくフォルダーを指しています。
- Parquet 形式の場合は、圧縮コーデックが none、snappy、または gzip です。
-
区切りテキスト形式の場合:
-
rowDelimiterは任意の 1 文字です。 -
compressionには none、bzip2、gzip を指定できます。 -
encodingNameUTF-7 はサポートされていません。
-
- Avro 形式の場合は、圧縮コーデックが none、deflate、または snappy です。
コピー アクティビティ ソースでは、
additionalColumnsが指定されていません。区切りテキストにデータをコピーする場合、コピー アクティビティ シンクでは、
fileExtensionは ".csv" である必要があります。コピー アクティビティのマッピングで、型変換が有効になっていません。
例:
"activities":[
{
"name": "CopyFromDeltaLake",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delta lake input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzureDatabricksDeltaLakeSource",
"sqlReaderQuery": "SELECT * FROM events TIMESTAMP AS OF timestamp_expression"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Delta Lake からステージング コピーする
シンクのデータ ストアまたは形式が、前のセクションで説明した直接コピーの基準に適合しない場合は、中間の Azure Storage インスタンスを使用して組み込みのステージング コピーを有効にします。 ステージング コピー機能はスループットも優れています。 サービスが、Azure Databricks Delta Lake のデータをステージング ストレージにエクスポートしてから、データをシンクにコピーし、最後にステージング ストレージの一時データをクリーンアップします。 ステージングを使用したデータのコピーの詳細は、「ステージング コピー」を参照してください。
この機能を使うには、中間ステージングとしてストレージ アカウントを参照する Azure Blob Storage のリンクされたサービスまたは Azure Data Lake Storage Gen2 のリンクされたサービスを作成します。 次に、コピー アクティビティに enableStaging プロパティと stagingSettings プロパティを指定します。
注意
ステージング ストレージ アカウントの資格情報は Azure Databricks クラスター構成で事前に構成されている必要があります。詳細については、「前提条件」を参照してください。
例:
"activities":[
{
"name": "CopyFromDeltaLake",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delta lake input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzureDatabricksDeltaLakeSource",
"sqlReaderQuery": "SELECT * FROM events TIMESTAMP AS OF timestamp_expression"
},
"sink": {
"type": "<sink type>"
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingStorage",
"type": "LinkedServiceReference"
},
"path": "mystagingpath"
}
}
}
]
シンクとしての Delta Lake
Azure Databricks Delta Lake にデータをコピーするために、コピー アクティビティの sink セクションでは次のプロパティがサポートされています。
| プロパティ | 内容 | 必須 |
|---|---|---|
| type | コピー アクティビティのシンクの type プロパティ。AzureDatabricksDeltaLakeSink に設定します。 | はい |
| preCopyScript | コピー アクティビティの毎回の実行で、データを Databricks Delta テーブルに書き込む前に実行する SQL クエリを指定します。 例: VACUUM eventsTable DRY RUN このプロパティを使用して、事前に読み込まれたデータをクリーンアップしたり、TRUNCATE TABLE ステートメントまたは VACUUM ステートメントを追加したりできます。 |
いいえ |
| importSettings | デルタ テーブルにデータを書き込むために使用される詳細設定。 | いいえ |
importSettings の下: |
||
| type | インポート コマンドの種類。AzureDatabricksDeltaLakeImportCommand に設定します。 | Yes |
| dateFormat | 日付形式の文字列を日付型に書式設定します。 カスタム日付形式は datetime パターンの形式に従います。 指定しない場合は、既定値の yyyy-MM-dd が使用されます。 |
いいえ |
| timestampFormat | タイムスタンプ形式の文字列をタイムスタンプ型に書式設定します。 カスタム日付形式は datetime パターンの形式に従います。 指定しない場合は、既定値の yyyy-MM-dd'T'HH:mm:ss[.SSS][XXX] が使用されます。 |
いいえ |
Delta Lake に直接コピーする
ソースのデータ ストアと形式がこのセクションで説明する基準を満たす場合は、コピー アクティビティを使用して、ソースから Azure Databricks Delta Lake に直接コピーできます。 設定が確認され、次の条件が満たされない場合は、コピー アクティビティの実行が失敗します。
ソースのリンクされたサービスは、Azure Blob Storage または Azure Data Lake Storage Gen2 です。 アカウントの資格情報は Azure Databricks クラスター構成で事前に構成されている必要があります。詳細については、「前提条件」を参照してください。
ソース データ形式は、次のように構成された Parquet、区切りテキスト、または Avro であり、ファイルではなくフォルダーを指しています。
- Parquet 形式の場合は、圧縮コーデックが none、snappy、または gzip です。
-
区切りテキスト形式の場合:
-
rowDelimiterは既定値または任意の 1 文字です。 -
compressionには none、bzip2、gzip を指定できます。 -
encodingNameUTF-7 はサポートされていません。
-
- Avro 形式の場合は、圧縮コーデックが none、deflate、または snappy です。
コピー アクティビティ ソース内:
-
wildcardFileNameにワイルドカード*のみが含まれ、?は含まれず、wildcardFolderNameは指定されていません。 -
prefix、modifiedDateTimeStart、modifiedDateTimeEnd、およびenablePartitionDiscoveryが指定されていない。 -
additionalColumnsが指定されていません。
-
コピー アクティビティのマッピングで、型変換が有効になっていません。
例:
"activities":[
{
"name": "CopyToDeltaLake",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Delta lake output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureDatabricksDeltaLakeSink",
"sqlReaderQuery": "VACUUM eventsTable DRY RUN"
}
}
}
]
Delta Lake にステージング コピーする
ソースのデータ ストアまたは形式が、前のセクションで説明した直接コピーの基準に適合しない場合は、中間の Azure Storage インスタンスを使用して組み込みのステージング コピーを有効にします。 ステージング コピー機能はスループットも優れています。 サービスは、データ形式の要件を満たすようにデータをステージング ストレージに自動的に変換し、そこから Delta Lake にデータを読み込みます。 最後に、ストレージから一時データがクリーンアップされます。 ステージングを使用したデータのコピーの詳細は、「ステージング コピー」を参照してください。
この機能を使うには、中間ステージングとしてストレージ アカウントを参照する Azure Blob Storage のリンクされたサービスまたは Azure Data Lake Storage Gen2 のリンクされたサービスを作成します。 次に、コピー アクティビティに enableStaging プロパティと stagingSettings プロパティを指定します。
注意
ステージング ストレージ アカウントの資格情報は Azure Databricks クラスター構成で事前に構成されている必要があります。詳細については、「前提条件」を参照してください。
例:
"activities":[
{
"name": "CopyToDeltaLake",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Delta lake output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureDatabricksDeltaLakeSink"
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingBlob",
"type": "LinkedServiceReference"
},
"path": "mystagingpath"
}
}
}
]
監視
他のコネクタと同様に コピー アクティビティのモニタリング体験が提供されます。 さらに、Delta Lake との間のデータの読み込みが Azure Databricks クラスターで実行されているため、詳細なクラスター ログを表示したり、パフォーマンスを監視したりすることができます。
Lookup アクティビティのプロパティ
プロパティの詳細については、ルックアップ アクティビティに関する記事を参照してください。
ルックアップ アクティビティでは、最大 1,000 行を返すことができます。結果セットにそれを超えるレコードが含まれている場合は、最初の 1,000 行が返されます。
関連するコンテンツ
コピー アクティビティによってソース、シンクとしてサポートされるデータ ストアの一覧については、サポートされるデータ ストアと形式の表を参照してください。