Azure Data Factory を使用して Azure Data Explorer にデータをコピーする
重要
このコネクタは、Microsoft Fabric のリアルタイム インテリジェンスで使用できます。 次の例外を除き、この記事の手順を使用してください。
- 必要に応じて、「KQL データベースを作成する」の手順に従ってデータベースを作成する。
- 必要に応じて、「空のテーブルを作成する」の手順に従ってテーブルを作成する。
- 「URI をコピーする」の手順に従って、クエリまたはインジェスト URI を取得する。
- KQL クエリセットでクエリを実行する。
Azure Data Explorer は、フル マネージドの高速データ分析サービスです。 アプリケーション、Web サイト、IoT デバイスなど、さまざまなソースからストリーム配信される大量のデータをリアルタイムに分析することができます。 Azure Data Explorer を使用すると、データを繰り返し探査してパターンや異常を特定することにより、製品の改良、カスタマー エクスペリエンスの強化、デバイスの監視、操作の向上を実現できます。 これは、数分で新たな疑問を調査し、回答を得る際に役立ちます。
Azure Data Factory は、フル マネージドのクラウドベースのデータ統合サービスです。 これを使用して、既存のシステムから Azure Data Explorer データベースにデータを設定することができます。 分析ソリューションの構築にかかる時間を短縮する効果もあります。
Azure Data Explorer にデータを読み込むと、Data Factory には次の利点があります。
- 簡単なセットアップ:スクリプトを必要とせず、直感的な 5 ステップのウィザードを利用できます。
- 豊富なデータ ストアのサポート: オンプレミスとクラウド ベースのデータ ストアの豊富なセットに対する組み込みサポートを利用できます。 詳しい一覧については、サポートされるデータ ストアの表をご覧ください。
- セキュリティとコンプライアンスへの準拠: データは HTTPS または Azure ExpressRoute 経由で転送されます。 グローバル サービスの存在により、データが地理的な境界を越えることはありません。
- ハイ パフォーマンス: Azure Data Explorer へのデータ読み込み速度は最大 1 GB/秒 (GBps) です。 詳細については、コピー アクティビティのパフォーマンスを参照してください。
この記事では、Data Factory のデータ コピー ツールを使用して Amazon Simple Storage Service (S3) から Azure Data Explorer にデータを読み込みます。 同様のプロセスに従って、次のようなその他のデータ ストアからデータをコピーすることもできます。
前提条件
- Azure サブスクリプション。 無料の Azure アカウントを作成します。
- Azure Data Explorer クラスターとデータベース。 クラスターとデータベースを作成します。
- データのソース。
Data Factory の作成
Azure portal にサインインします。
左側のウィンドウで、[リソースの作成]>[分析]>[Data Factory] の順に選択します。

[新しいデータ ファクトリ] ウィンドウで、次の表にあるフィールドの値を指定します。
![[新しいデータ ファクトリ] ウィンドウ](media/data-factory-load-data/my-new-data-factory.png)
設定 入力する値 名前 このボックスには、実際のデータ ファクトリのグローバルに一意の名前を入力します。 "データ ファクトリ名 "LoadADXDemo" は利用できません" というエラーが発生する場合は、データ ファクトリ用に別の名前を入力します。 Data Factory アーティファクトの名前付けに関する規則については、Data Factory の名前付け規則に関する記事を参照してください。 サブスクリプション ドロップダウン リストで、データ ファクトリを作成する Azure サブスクリプションを選択します。 リソース グループ [新規作成] を選択し、新しいリソース グループの名前を入力します。 既にリソース グループがある場合は、[既存のものを使用する] を選択します。 Version ドロップダウン リストで、[V2] を選択します。 場所 ドロップダウン リストで、データ ファクトリの場所を選択します。 サポートされている場所のみがこのリストに表示されます。 データ ファクトリによって使用されるデータ ストアは、他の場所やリージョンにあってもかまいません。 [作成] を選択します
作成プロセスを監視するには、ツール バーの [通知] を選択します。 データ ファクトリの作成後、それを選択します。
[データ ファクトリ] ウィンドウが表示されます。
![[データ ファクトリ] ウィンドウ。](media/data-factory-load-data/data-factory-home-page.png)
このアプリケーションを別のウィンドウで開くには、[Author & Monitor]\(作成と監視\) タイルを選択します。
Azure Data Explorer へのデータの読み込み
多くの種類のデータ ストアから Azure Data Explorer にデータを読み込むことができます。 この記事では、Amazon S3 からデータを読み込む方法について説明します。
データは、次のいずれかの方法で読み込むことができます。
- Azure Data Factory のユーザー インターフェイスの左側のウィンドウで、[作成者] アイコンを選択します。 この方法は、「Azure Data Factory UI を使用してデータ ファクトリを作成する」の「Data Factory の作成」セクションで説明しています。
- Azure Data Factory のデータ コピー ツール (データ コピー ツールを使用したデータのコピーに関する記事を参照)。
Amazon S3 (コピー元) からデータをコピーする
[Let's get started]\(始めましょう\) ウィンドウで、[データ コピー] を選択してデータ コピー ツールを開きます。
![[データ コピー] ツール ボタン。](media/data-factory-load-data/copy-data-tool-tile.png)
[プロパティ] ウィンドウの [タスク名]ボックスで、名前を入力し、[次へ] を選択します。
![データ コピーの [プロパティ] ウィンドウ。](media/data-factory-load-data/copy-from-source.png)
[ソース データ ストア] ウィンドウで、[新しい接続の作成] を選択します。
![データ コピーの [ソース データ ストア] ウィンドウ](media/data-factory-load-data/source-create-connection.png)
[Amazon S3] を選択し、[続行] を選択します。
![[New Linked Service]\(新しいリンクされたサービス\) ウィンドウ。](media/data-factory-load-data/amazons3-select-new-linked-service.png)
[New Linked Service (Amazon S3)]\(新しいリンクされたサービス (Amazon S3)\) ページで、以下を実行します。
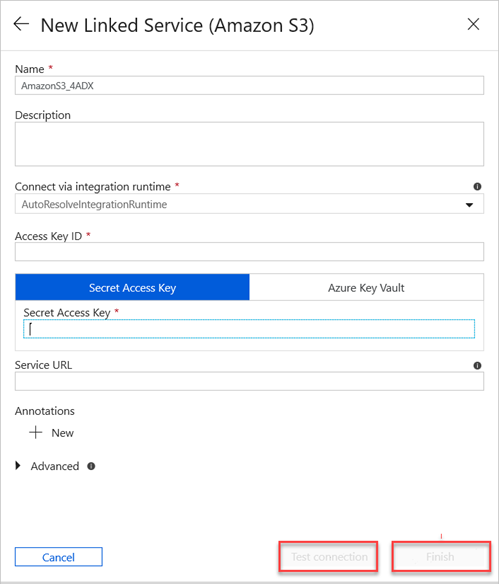
a. [名前] ボックスに、リンクされた新しいサービスの名前を入力します。
b. [Connect via integration runtime]\(統合ランタイム経由で接続\) ドロップダウン リストで値を選択します。
c. [Access Key ID]\(アクセス キー ID\) ボックスに値を入力します。
Note
Amazon S3 で、お使いのアクセス キーを見つけるには、ナビゲーション バーでご自身の Amazon ユーザー名を選択し、[My Security Credentials]\(自分のセキュリティ資格情報\) を選択します。
d. [Secret Access Key]\(シークレット アクセス キー\) ボックスに値を入力します。
e. リンクされたサービスの作成済みの接続をテストするには、[Test Connection]\(接続のテスト\) を選択します。
f. 完了 を選択します。
[ソース データ ストア] ウィンドウには、新しい AmazonS31 接続が表示されます。
[次へ] を選択します。
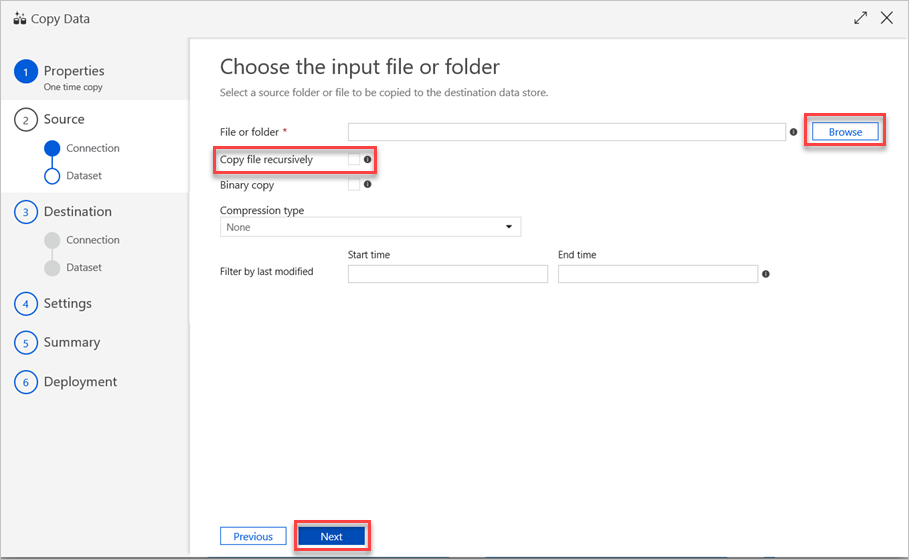
[Choose the input file or folder]\(入力ファイルまたはフォルダーの選択\) ウィンドウで、以下の手順を実行します。
a. コピーするファイルまたはフォルダーを参照し、それを選択します。
b. 目的のコピー動作を選択します。 [Binary copy]\(バイナリ コピー\) チェック ボックスがオフになっていることを確認します。
c. [次へ] を選択します。
[File format settings]\(ファイル形式設定\) ウィンドウで、対象のファイルの関連設定を選択します。 その後、 [次へ] を選択します。
![[File format settings]\(ファイル形式設定\) ウィンドウ](media/data-factory-load-data/source-file-format-settings.png)
Azure Data Explorer (コピー先) にデータをコピーする
このセクションで指定する Azure Data Explorer のコピー先テーブル (シンク) にデータをコピーするために、Azure Data Explorer のリンクされたサービスが新しく作成されます。
Note
Azure Data Factory コマンド アクティビティを使用して Azure Data Explorer 管理コマンドを実行し、いずれかのクエリからの取り込みコマンド (.set-or-replace など) を使用します。
Azure Data Explorer のリンクされたサービスを作成する
Azure Data Explorer のリンクされたサービスを作成するには、以下の手順を実行します。
既存のデータ ストア接続を使用したり、新しいデータ ストアを指定したりするには、[Destination data store]\(コピー先データ ストア\) ウィンドウで [新しい接続の作成] を選択します。
![[Destination data store]\(コピー先データ ストア\) ウィンドウ。](media/data-factory-load-data/destination-create-connection.png)
[New Linked Service]\(新しいリンクされたサービス\) ウィンドウで、[Azure Data Explorer] を選択し、[続行] を選択します。
![[New Linked Service]\(新しいリンクされたサービス\) ウィンドウ。](media/data-factory-load-data/adx-select-new-linked-service.png)
[New Linked Service (Azure Data Explorer)]\(新しいリンクされたサービス (Azure Data Explorer)\) ウィンドウで、以下の手順を実行します。
![Azure Data Explorer の [New Linked Service]\(新しいリンクされたサービス\) ウィンドウ。](media/data-factory-load-data/adx-new-linked-service.png)
[名前] ボックスに、Azure Data Explorer のリンクされたサービスの名前を入力します。
[認証方法] で、[システム割り当てマネージド ID] または [サービス プリンシパル] を選びます。
マネージド ID を使って認証するには、マネージド ID の名前またはマネージド ID のオブジェクト ID を使って、マネージド ID にデータベースへのアクセス権を付与します。
サービス プリンシパルを使って認証するには:
- [テナント] ボックスにテナント名を入力します。
- [サービス プリンシパル ID] ボックスに、サービス プリンシパル ID を入力します。
- [Service principal key]\(サービス プリンシパル キー\) を選択し、[Service principal key]\(サービス プリンシパル キー\) ボックスにキーの値を入力します。
Note
- このサービス プリンシパルは、Azure Data Explorer サービスにアクセスするために Azure Data Factory によって使用されます。 サービス プリンシパルを作成するには、Microsoft Entra サービス プリンシパルを作成するに移動します。
- マネージド ID またはサービス プリンシパルにアクセス許可を割り当てるには、アクセス許可の管理に関する記事をご覧ください。
- Azure Key Vault の方法またはユーザー割り当てマネージド ID は使わないでください。
[Account selection method]\(アカウントの選択方法\) で、次のいずれかのオプションを選択します。
[From Azure subscription]\(Azure サブスクリプションから\) を選択し、ドロップダウン リストでお使いの Azure サブスクリプションとクラスターを選択します。
Note
- [クラスター] ボックスの一覧には、お使いのサブスクリプションに関連付けられているクラスターのみが表示されます。
- 最高のパフォーマンスを得るために、クラスターには適切な SKU が必要です。
[手動で入力] を選択し、お使いのエンドポイントを入力します。
[データベース] ボックスの一覧で、お使いのデータベース名を選択します。 または、[編集] チェック ボックスをオンにし、データベース名を入力します。
リンクされたサービスの作成済みの接続をテストするには、[Test Connection]\(接続のテスト\) を選択します。 リンクされたサービスに接続できると、そのウィンドウには緑のチェックマークと "接続成功" メッセージが表示されます。
[作成] を選んで、リンク サービスの作成を完了します。
Azure Data Explorer データ接続を構成する
リンクされたサービスの接続を作成したら、[Destination data store]\(コピー先データ ストア\) ウィンドウが表示され、作成した接続が使用できるようになります。 この接続を構成するには、以下の手順を実行します。
[次へ] を選択します。
![Azure Data Explorer の [Destination data store]\(コピー先データ ストア\) ウィンドウ](media/data-factory-load-data/destination-data-store.png)
[テーブル マッピング] ウィンドウで、コピー先テーブル名を設定し、[次へ] を選択します。
![コピー先データセットの [テーブル マッピング] ウィンドウ](media/data-factory-load-data/destination-dataset-table-mapping.png)
[列マッピング] ウィンドウで、次のマッピングが行われます。
a. 最初のマッピングは、Azure Data Factory のスキーマ マッピングに関する記事に従って実行されます。 次の操作を行います。
Azure Data Factory のコピー先テーブルの [列マッピング] を設定します。 既定では、ソースから Azure Data Factory のコピー先テーブルへのマッピングが表示されます。
列マッピングを定義する必要がない列の選択はキャンセルします。
b. 2 つ目のマッピングは、Azure Data Explorer にこの表形式データが取り込まれたときに行われます。 マッピングは CSV のマッピング規則に従って実行されます。 ソース データが CSV 形式でない場合でも、Azure Data Factory ではそのデータが表形式に変換されます。 したがって、この段階では、CSV マッピングは唯一の関連のあるマッピングになります。 次の操作を行います。
(省略可能) [Azure Data Explorer (Kusto) sink properties]\(Azure Data Explorer (Kusto) シンク プロパティ\) で、列マッピングを使用できるように、関連する [Ingestion mapping name]\(インジェスト マッピング名\) を追加します。
[Ingestion mapping name]\(インジェスト マッピング名\) が指定されていない場合は、[列マッピング] セクションで定義されている by-name マッピング順序が使用されます。 by-name マッピングが失敗すると、Azure Data Explorer では、by-column position 順 (つまり、既定では位置によるマップ) でデータの取り込みが試行されます。
[次へ] を選択します。
![コピー先データセットの [列マッピング] ウィンドウ](media/data-factory-load-data/destination-dataset-column-mapping.png)
[設定] ウィンドウで、以下の手順を実行します。
a. [Fault tolerance settings]\(フォールト トレランスの設定\) で、関連する設定を入力します。
b. [Performance settings]\(パフォーマンスの設定\) で、[Enable staging]\(ステージングの有効化\) が適用されていないため、[詳細設定] にはコストに関する考慮事項が含まれます。 特定の要件がない場合は、これらの設定はそのままにしておきます。
c. [次へ] を選択します。
![データ コピーの [設定] ウィンドウ](media/data-factory-load-data/copy-data-settings.png)
[Summary]\(概要\) ウィンドウで設定を確認し、[次へ] を選択します。
![データ コピーの [Summary]\(概要\) ウィンドウ](media/data-factory-load-data/copy-data-summary.png)
[Deployment complete]\(デプロイ完了\) ウィンドウで、以下を実行します。
a. [監視] タブに切り替えてパイプラインの状態 (つまり、進行状況、エラー、データ フロー) を確認するには、[監視] を選択します。
b. リンクされたサービス、データセット、パイプラインを編集するには、[パイプラインの編集] を選択します。
c. [完了] を選択してデータ コピー タスクを完了します。
![[Deployment complete]\(デプロイ完了\) ウィンドウ](media/data-factory-load-data/deployment.png)
関連するコンテンツ
- Azure Data Factory の Azure Data Explorer コネクタについて学習する。
- Data Factory UI でリンクされたサービス、データセット、およびパイプラインを編集する。
- Azure Data Explorer の Web UI でデータのクエリを実行する。