コピー アクティビティのパフォーマンスとスケーラビリティに関するガイド
適用対象:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新しい試用版を開始する方法について説明します。
データ レイクまたはエンタープライズ データ ウェアハウス (EDW) から Azure への大規模なデータ移行を実行することが必要な場合があります。 また、ビッグ データ分析用に各種ソースから Azure に大量のデータを取り込むことが必要な場合があります。 いずれの場合も、最適なパフォーマンスとスケーラビリティを実現することが不可欠です。
Azure Data Factory パイプラインおよび Azure Synapse Analytics パイプラインには、データを取り込むためのメカニズムが用意されています。これには次のような利点があります。
- 大量のデータを処理する
- パフォーマンスが高い
- コスト効率に優れている
これらの利点により、パフォーマンスの高いスケーラブルなデータ インジェスト パイプラインを構築したいデータ エンジニアに最適です。
この記事を読むと、次の質問に回答できるようになります。
- データ移行シナリオとデータ インジェスト シナリオでコピー アクティビティを使用すると、どのレベルのパフォーマンスとスケーラビリティを実現できますか。
- コピー アクティビティのパフォーマンスを調整するには、どのような手順を実行する必要がありますか。
- 1 回のコピー アクティビティの実行には、どのようなパフォーマンスの最適化を利用できますか。
- コピーのパフォーマンスを最適化するときに考慮する外的要因には何がありますか。
注意
コピー アクティビティ全般に慣れていない場合は、この記事を読む前に、コピー アクティビティの概要に関するページを参照してください。
Azure Data Factory パイプラインおよび Azure Synapse Analytics パイプラインを使用して実現可能なコピー パフォーマンスとスケーラビリティ
Azure Data Factory パイプラインおよび Azure Synapse Analytics パイプラインは、さまざまなレベルで並列処理を可能にするサーバーレス アーキテクチャを提供します。
このアーキテクチャを使用すると、お使いの環境のデータ移動スループットを最大化するパイプラインを開発できます。 これらのパイプラインは、次のリソースを完全に利用します。
- ソースとコピー先のデータ ストア間のネットワーク帯域幅
- ソースとコピー先のデータストアの 1 秒あたりの入力/出力操作数 (IOPS) と帯域幅
この完全な利用は、次のリソースで使用可能な最小スループットを測定することで、全体のスループットを推定できることを意味します。
- ソース データ ストア
- コピー先データ ストア
- ソースとコピー先のデータストア間のネットワーク帯域幅
次の表は、データ移動時間を計算したものです。 各セルの期間は、特定のネットワークおよびデータ ストアの帯域幅と、特定のデータ ペイロード サイズに基づいて計算されます。
注意
以下に示す期間は、ForEach を使用したパーティションの作成や複数の同時コピー アクティビティの生成など、「コピー パフォーマンス最適化機能」で説明されている 1 つ以上のパフォーマンス最適化手法を使用して、エンドツーエンドのデータ統合ソリューションで達成可能なパフォーマンスを表すためのものです。 特定のデータセットとシステム構成のコピー パフォーマンスを最適化するには、パフォーマンス チューニングの手順に記載されている手順に従うことをお勧めします。 パフォーマンス チューニング テストで取得した数値は、運用環境デプロイ計画、容量計画、および請求プロジェクションに使用する必要があります。
| データ サイズ/ bandwidth |
50 Mbps | 100 Mbps | 500 Mbps | 1 Gbps | 5 Gbps | 10 Gbps | 50 Gbps |
|---|---|---|---|---|---|---|---|
| 1 GB | 2.7 分 | 1.4 分 | 0.3 分 | 0.1 分 | 0.03 分 | 0.01 分 | 0.0 分 |
| 10 GB | 27.3 分 | 13.7 分 | 2.7 分 | 1.3 分 | 0.3 分 | 0.1 分 | 0.03 分 |
| 100 GB | 4.6 時間 | 2.3 時間 | 0.5 時間 | 0.2 時間 | 0.05 時間 | 0.02 時間 | 0.0 時間 |
| 1 TB (テラバイト) | 46.6 時間 | 23.3 時間 | 4.7 時間 | 2.3 時間 | 0.5 時間 | 0.2 時間 | 0.05 時間 |
| 10 TB | 19.4 日 | 9.7 日 | 1.9 日 | 0.9 日 | 0.2 日 | 0.1 日 | 0.02 日 |
| 100 TB | 194.2 日 | 97.1 日 | 19.4 日 | 9.7 日 | 1.9 日 | 1 日 | 0.2 日 |
| 1 PB | 64.7 か月 | 32.4 か月 | 6.5 か月 | 3.2 か月 | 0.6 か月 | 0.3 か月 | 0.06 か月 |
| 10 PB | 647.3 か月 | 323.6 か月 | 64.7 か月 | 31.6 か月 | 6.5 か月 | 3.2 か月 | 0.6 か月 |
コピーはさまざまなレベルでスケーラブルです。
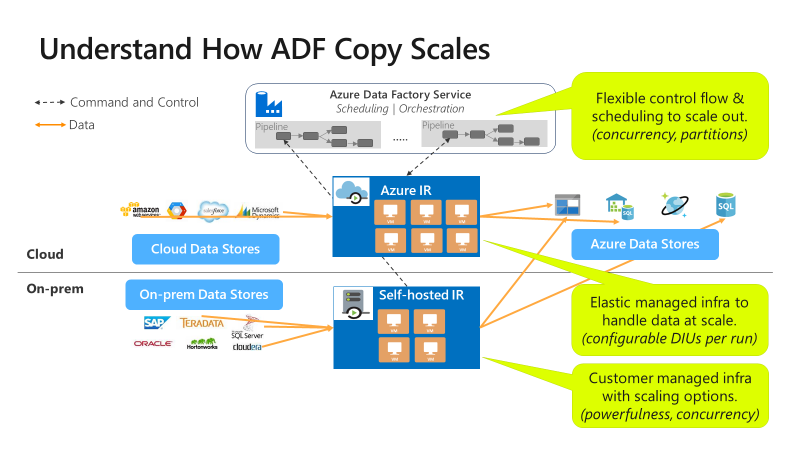
制御フローでは、複数のコピー アクティビティを並列して開始できます。たとえば、For Each ループを使用します。
1 回のコピー アクティビティで、スケーラブルなコンピューティング リソースを利用できます。
- Azure 統合ランタイム (IR) を使用すると、各コピー アクティビティに対して最大 256 データ統合単位 (DIU) をサーバーレス方式で指定できます。
- セルフホステッド IR を使用する場合は、次のいずれかの方法を使用できます。
- マシンを手動でスケールアップします。
- 複数のマシン (最大 4 ノード) にスケールアウトします。すると、1 回のコピー アクティビティによって、そのファイル セットがすべてのノードにわたってパーティション分割されます。
1 回のコピー アクティビティで、複数のスレッドを使用したデータ ストアの読み取りと書き込みが並列で行われます。
パフォーマンス チューニングの手順
コピー アクティビティを伴うサービスのパフォーマンスをチューニングするには、次の手順を実行します。
テスト データセットを選択し、ベースラインを確立します。
開発中は、代表的なデータ サンプルに対してコピー アクティビティを使用して、パイプラインをテストします。 選択するデータセットは、次の属性に従って一般的なデータ パターンを表す必要があります。
- フォルダー構造
- ファイル パターン
- データ スキーマ
また、データセットは、コピーのパフォーマンス評価に十分な大きさである必要があります。 十分なサイズにすると、コピー アクティビティの完了に少なくとも 10 分かかります。 コピー アクティビティの監視の後に、実行の詳細とパフォーマンス特性を収集します。
1 回のコピー アクティビティのパフォーマンスを最大化する方法:
まず、1 回のコピー アクティビティの使用におけるパフォーマンスを最大化することをお勧めします。
コピー アクティビティが Azure 統合ランタイムで実行される場合:
データ統合単位 (DIU) と並列コピーの設定の既定値から始めます。
コピー アクティビティが "セルフホステッド" 統合ランタイムで実行される場合:
専用のマシンを使用して IR をホストすることをお勧めします。 このマシンは、データ ストアをホストするサーバーとは別にする必要があります。 並列コピー設定の既定値とセルフホステッド IR 用の単一のノードの使用から始めます。
パフォーマンス テストの実行を行います。 達成されたパフォーマンスをメモしておきます。 使用した実際の値 (DIU や 並列コピーなど) を含めます。 実行結果と使用されたパフォーマンス設定を収集する方法については、コピー アクティビティの監視に関する記事を参照してください。 ボトルネックを特定して解決するために、コピー アクティビティのパフォーマンスのトラブルシューティングを行う方法を学習します。
トラブルシューティングとチューニング ガイダンスに従って、追加のパフォーマンス テストの実行を繰り返します。 1 回のコピー アクティビティの実行でスループットの向上を実現できなければ、複数のコピーを同時に実行することで合計スループットを最大化できるかどうか検討してください。 このオプションについては、次の番号付きの箇条書きで説明します。
複数のコピーを同時に実行することで合計スループットを最大化する方法:
ここまでで、1 回のコピー アクティビティのパフォーマンスを最大化しました。 お使いの環境のスループットの上限にまだ達していない場合は、複数のコピー アクティビティを並行して実行できます。 制御フロー コンストラクトを使用することで、並列で実行できます。 このようなコンストラクトの 1 つは、For Each ループです。 詳細については、ソリューション テンプレートに関する次の記事を参照してください。
構成をデータセット全体まで拡張します。
実行の結果とパフォーマンスに問題がなければ、データセット全体を網羅するよう、定義とパイプラインを拡張できます。
コピー アクティビティのパフォーマンスのトラブルシューティング
パフォーマンス チューニングの手順 に従って、シナリオのパフォーマンステストを計画および実施します。 また、「コピー アクティビティのパフォーマンスのトラブルシューティング」で、各回のコピー アクティビティの実行のパフォーマンスに関する問題をトラブルシューティングする方法を確認します。
コピー パフォーマンス最適化機能
このサービスには、次のパフォーマンス最適化機能があります。
データ統合単位
データ統合単位 (DIU) は、Azure Data Factory パイプラインおよび Azure Synapse Analytics パイプラインで 1 つの単位の能力を表す尺度です。 能力は、CPU、メモリ、およびネットワーク リソース割り当てを組み合わせたものです。 DIU は Azure 統合ランタイムにのみ適用されます。 DIU はセルフホステッド統合ランタイムには適用されません。 こちらを参照してください。
セルフホステッド統合ランタイムのスケーラビリティ
増加する同時実行ワークロードをホストすることもできます。 または、現在のワークロード レベルでパフォーマンスを向上させることもできます。 次の方法で、処理のスケーリングを強化できます。
- 1 つのノードで実行できる同時実行ジョブの数を増やすことで、セルフホステッド IR をスケール "アップ" できます。
スケールアップは、ノードのプロセッサとメモリが完全に使用されていない場合にのみ機能します。 - ノード (マシン) をさらに追加することで、セルフホステッド IR をスケール "アウト" できます。
詳細については、次を参照してください。
並列コピー
parallelCopies プロパティを設定して、コピー アクティビティで使用する並列処理を指定できます。 このプロパティは、コピー アクティビティ内のスレッドの最大数と考えてください。 スレッドは並行して動作します。 スレッドは、ソースから読み取るか、シンク データ ストアに書き込みます。 詳細については、こちらを参照してください。
ステージング コピー
データ コピー操作では、データを "直接" シンク データ ストアに送信できます。 または、BLOB ストレージを "中間ステージング" ストアとして使用することもできます。 詳細情報。
関連するコンテンツ
コピー アクティビティの他の記事を参照してください。