Prepararsi all'uso di Apache Spark
Apache Spark è un framework di elaborazione dati distribuito che consente l'analisi dei dati su larga scala coordinando il lavoro su più nodi di elaborazione in un cluster, noto in Microsoft Fabric come pool di Spark. Più semplicemente, Spark usa un approccio "divide et impera" per elaborare rapidamente grandi volumi di dati, distribuendo il lavoro su più computer. Il processo di distribuzione delle attività e di raccolta dei risultati viene gestito automaticamente da Spark.
Spark può eseguire codice scritto in un'ampia gamma di linguaggi, tra cui Java, Scala (un linguaggio di scripting basato su Java), Spark R, Spark SQL e PySpark (una variante di Python specifica per Spark). Nella pratica, la maggior parte dei carichi di lavoro di analisi e ingegneria dati viene eseguita usando una combinazione di PySpark e Spark SQL.
Pool di Spark
Un pool di Spark è costituito da nodi di calcolo che distribuiscono le attività di elaborazione dati. L'architettura generale è illustrata nel diagramma seguente.
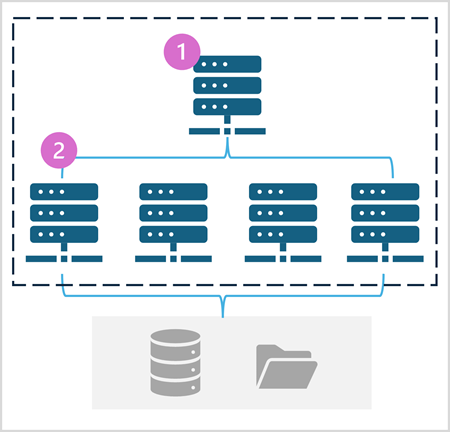
Come illustrato nel diagramma, un pool di Spark contiene due tipi di nodo:
- Un nodo head in un pool di Spark coordina i processi distribuiti tramite un programma driver.
- Il pool include più nodi di lavoro in cui i processi executor eseguono le effettive attività di elaborazione dei dati.
Il pool di Spark usa questa architettura di calcolo distribuita per accedere ai dati ed elaborarli in un archivio dati compatibile, ad esempio un data lakehouse basato su OneLake.
Pool di Spark in Microsoft Fabric
Microsoft Fabric offre un pool di avvio in ogni area di lavoro, che consente l'avvio e l'esecuzione rapidi dei processi Spark con configurazione e configurazione minime. È possibile configurare il pool di avvio per ottimizzare i nodi che contiene in base alle specifiche esigenze del carico di lavoro o ai vincoli di costo.
È anche possibile creare pool di Spark personalizzati con configurazioni di nodo specifiche che supportano le proprie specifiche esigenze di elaborazione dei dati.
Nota
La possibilità di personalizzare le impostazioni del pool di Spark può essere disabilitata dagli amministratori di Fabric a livello di capacità di Fabric. Per altre informazioni, vedere Impostazioni di amministrazione della capacità per ingegneria dei dati e data science nella documentazione di Fabric.
È possibile gestire le impostazioni per il pool di avvio e creare nuovi pool di Spark nella sezione Ingegneria dei dati/Data Science delle impostazioni dell'area di lavoro.
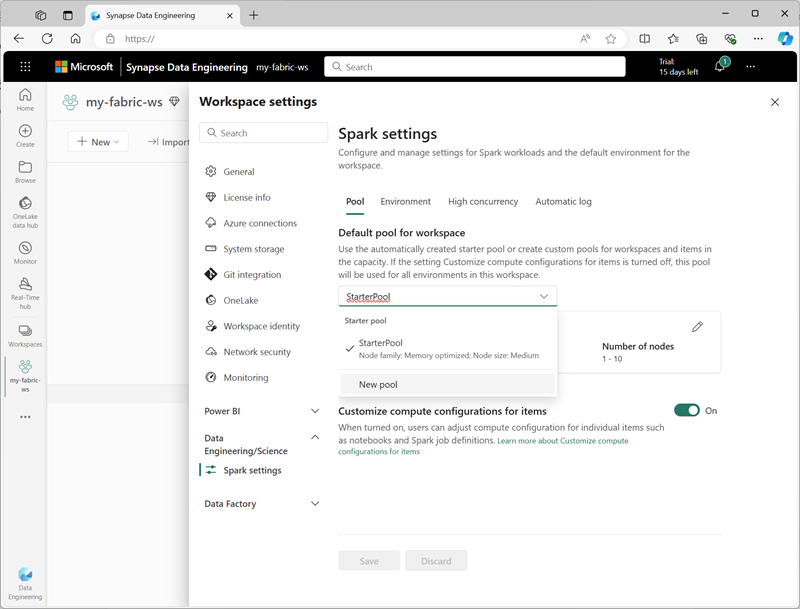
Le impostazioni di configurazione specifiche per i pool di Spark includono:
- Famiglia di nodi: il tipo di macchine virtuali usate per i nodi del cluster Spark. Nella maggior parte dei casi, i nodi ottimizzati per la memoria offrono prestazioni ottimali.
- Scalabilità automatica: indica se effettuare automaticamente il provisioning dei nodi in base alle esigenze e, in tal caso, il numero iniziale e massimo di nodi da allocare al pool.
- Allocazione dinamica: indica se allocare o meno in modo dinamico i processi executor nei nodi di lavoro in base ai volumi di dati.
Se si creano uno o più pool di Spark personalizzati in un'area di lavoro, è possibile impostarne uno (o il pool di avvio) come pool predefinito da usare se non viene indicato un pool specifico per un determinato processo Spark.
Suggerimento
Per altre informazioni sulla gestione dei pool di Spark in Microsoft Fabric, vedere Configurazione dei pool di avvio in Microsoft Fabrice Come creare pool di Spark personalizzati in Microsoft Fabric nella documentazione di Microsoft Fabric.
Runtime e ambienti
L'ecosistema open source Spark include più versioni del runtime Spark, che determina la versione di Apache Spark, Delta Lake, Python e altri componenti software di base installati. Inoltre, all'interno di un runtime è possibile installare e usare un'ampia selezione di librerie di codice per attività comuni (e talvolta molto specializzate). Poiché gran parte dell'elaborazione di Spark viene eseguita con PySpark, l'ampia gamma di librerie Python garantisce che, qualunque sia l’attività da eseguire, è probabile che esista un'apposita libreria.
In alcuni casi, le organizzazioni potrebbero dover definire più ambienti per supportare un'ampia gamma di attività di elaborazione dati. Ogni ambiente definisce una versione di runtime specifica, nonché le librerie che devono essere installate per eseguire operazioni specifiche. Gli ingegneri dei dati e gli scienziati dei dati possono quindi selezionare l'ambiente da usare con un pool di Spark per una determinata attività.
Runtime Spark in Microsoft Fabric
Microsoft Fabric supporta più runtime Spark e continuerà ad aggiungere il supporto per i nuovi runtime non appena vengono rilasciati. È possibile usare l'interfaccia delle impostazioni dell'area di lavoro per specificare il runtime Spark usato dall'ambiente predefinito all'avvio di un pool di Spark.
Suggerimento
Per altre informazioni sui runtime Spark in Microsoft Fabric, vedere Runtime Apache Spark in Fabric nella documentazione di Microsoft Fabric.
Ambienti in Microsoft Fabric
È possibile creare ambienti personalizzati in un'area di lavoro di Fabric. Questo consente di usare specifici runtime, librerie e impostazioni di configurazione di Spark per diverse operazioni di elaborazione dei dati.
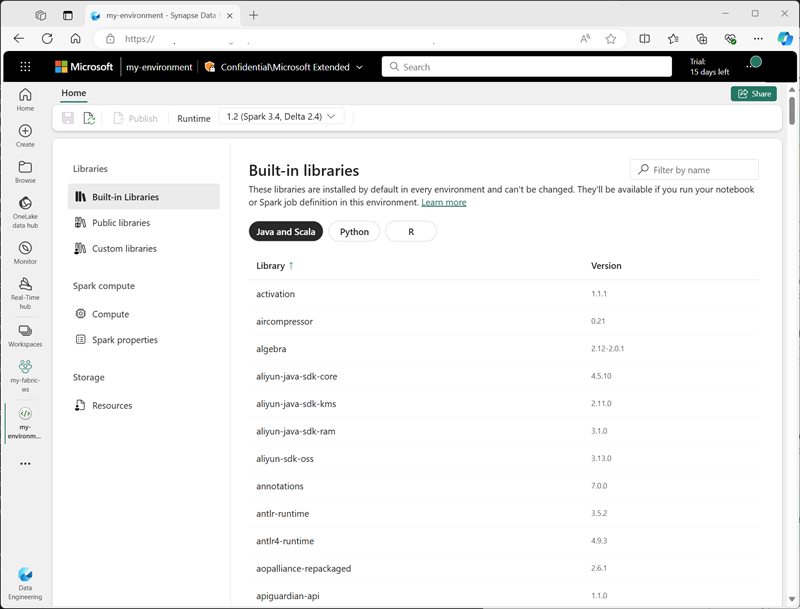
Quando si crea un ambiente, è possibile:
- Specificare il runtime Spark da usare.
- Visualizzare le librerie predefinite installate in ogni ambiente.
- Installare librerie pubbliche specifiche dall'indice dei pacchetti Python (PyPI).
- Installare librerie personalizzate caricando un file di pacchetto.
- Specificare il pool di Spark che deve essere usato dall'ambiente.
- Specificare le proprietà di configurazione di Spark per eseguire l'override del comportamento predefinito.
- Caricare i file di risorse che devono essere disponibili nell'ambiente.
Dopo aver creato almeno un ambiente personalizzato, è possibile specificarlo come ambiente predefinito nelle impostazioni dell'area di lavoro.
Suggerimento
Per altre informazioni sull'uso di ambienti personalizzati in Microsoft Fabric, vedere Creare, configurare e usare un ambiente in Microsoft Fabric nella documentazione di Microsoft Fabric.
Opzioni di configurazione di Spark aggiuntive
La gestione di ambienti e pool di Spark è il modo principale in cui è possibile gestire l'elaborazione Spark in un'area di lavoro di Fabric. Esistono tuttavia alcune opzioni aggiuntive che è possibile usare per apportare ulteriori ottimizzazioni.
Motore di esecuzione nativo
Il motore di esecuzione nativo in Microsoft Fabric è un motore di elaborazione vettorializzato che esegue le operazioni Spark direttamente nell'infrastruttura lakehouse. L'uso del motore di esecuzione nativo può migliorare significativamente le prestazioni delle query quando si usano set di dati di grandi dimensioni in formati di file Parquet o Delta.
Per usare il motore di esecuzione nativo, è possibile abilitarlo a livello di ambiente o all'interno di un singolo notebook. Per abilitare il motore di esecuzione nativo a livello di ambiente, impostare le proprietà di Spark seguenti nella configurazione dell'ambiente:
- spark.native.enabled: true
- spark.shuffle.manager: org.apache.spark.shuffle.sort.ColumnarShuffleManager
Per abilitare il motore di esecuzione nativo per uno script o un notebook specifico, è possibile impostare queste proprietà di configurazione all'inizio del codice, come illustrato di seguito:
%%configure
{
"conf": {
"spark.native.enabled": "true",
"spark.shuffle.manager": "org.apache.spark.shuffle.sort.ColumnarShuffleManager"
}
}
Suggerimento
Per altre informazioni sul motore di esecuzione nativo, vedere Motore di esecuzione nativo per Fabric Spark nella documentazione di Microsoft Fabric.
Modalità di concorrenza elevata
Quando si esegue codice Spark in Microsoft Fabric, viene avviata una sessione di Spark. È possibile ottimizzare l'efficienza dell'utilizzo delle risorse Spark usando la modalità di concorrenza elevata per condividere sessioni di Spark tra più utenti o processi simultanei. Quando la modalità di concorrenza elevata è abilitata per i notebook, più utenti possono eseguire codice nei notebook che usano la stessa sessione di Spark, garantendo al tempo stesso l'isolamento del codice per evitare che le variabili in un notebook siano interessate dal codice in un altro notebook. È anche possibile abilitare la modalità di concorrenza elevata per i processi Spark. Questo permette di ottenere un'efficienza simile per l'esecuzione simultanea di script Spark non interattivi.
Per abilitare la modalità di concorrenza elevata nella sezione Ingegneria dati/Data Science dell'interfaccia delle impostazioni dell'area di lavoro.
Suggerimento
Per altre informazioni sulla modalità du concorrenza elevata, vedere Modalità di concorrenza elevata in Apache Spark per Fabric nella documentazione di Microsoft Fabric.
Registrazione automatica di MLFlow
MLFlow è una libreria open source usata nei carichi di lavoro di data science per gestire il training e la distribuzione di modelli di Machine Learning. Una funzionalità chiave di MLFlow è la possibilità di registrare le operazioni di training e gestione del modello. Per impostazione predefinita, Microsoft Fabric usa MLFlow per registrare in modo implicito l'attività dell'esperimento di Machine Learning senza bisogno che lo scienziato dei dati includa codice esplicito. È possibile disabilitare questa funzionalità nelle impostazioni dell'area di lavoro.
Amministrazione di Spark per una capacità di Fabric
Gli amministratori possono gestire le impostazioni di Spark a livello di capacità di Fabric. Questo consente di limitare ed eseguire l'override delle impostazioni di Spark nelle aree di lavoro all'interno di un'organizzazione.
Suggerimento
Per altre informazioni sulla gestione della configurazione di Spark a livello di capacità di Fabric, vedere Configurare e gestire le impostazioni di data science e ingegneria dei dati per le capacità di Fabric nella documentazione di Microsoft Fabric.