Come creare pool di Spark personalizzati in Microsoft Fabric
In questo documento, viene illustrato come creare pool di Apache Spark personalizzati in Microsoft Fabric per i carichi di lavoro di analisi. I pool di Apache Spark consentono agli utenti di creare ambienti di calcolo su misura in base ai loro requisiti specifici, garantendo un utilizzo delle risorse e prestazioni ottimali.
Specificare i nodi minimi e massimi per la scalabilità automatica. In base a questi valori, il sistema acquisisce e ritira dinamicamente i nodi man mano che cambiano i requisiti di calcolo del processo, il che determina una scalabilità efficiente e prestazioni migliorate. L'allocazione dinamica degli executor nei pool di Spark riduce anche la necessità di una configurazione manuale dell'executor. Il sistema regola invece il numero di executor in funzione del volume di dati e delle esigenze di calcolo a livello di processo. Questo processo consente di concentrarsi sui carichi di lavoro senza doversi preoccupare dell'ottimizzazione delle prestazioni e della gestione delle risorse.
Nota
Per creare un pool di Spark personalizzato, è necessario l'accesso da amministratore all'area di lavoro. L'amministratore della capacità deve abilitare l'opzione Pool di aree di lavoro personalizzati nella sezione Calcolo Spark delle Impostazioni di amministrazione della capacità. Per altre informazioni, vedere Impostazioni di calcolo Spark per le capacità di Fabric.
Creare pool di Spark personalizzati
Per creare o gestire il pool di Spark associato all'area di lavoro:
Andare all'area di lavoro e selezionare Impostazioni dell'area di lavoro.
Selezionare l'opzione Data Engineering/Science per espandere il menu, quindi selezionare Impostazioni Spark.
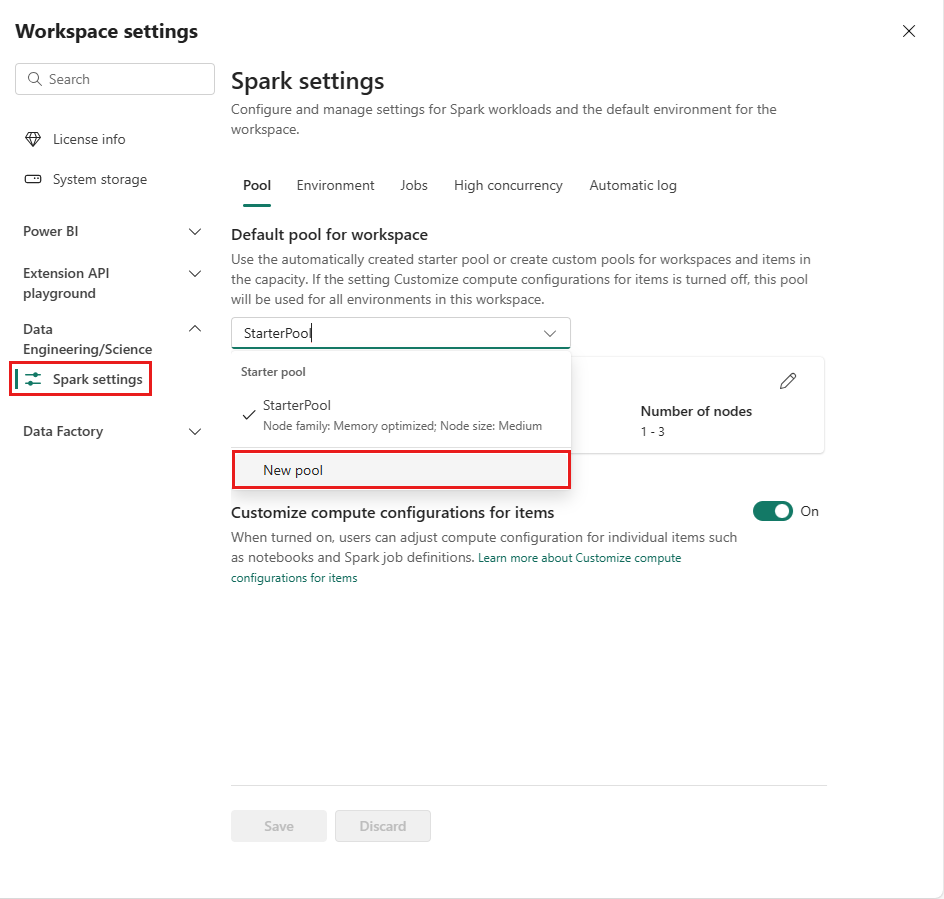
Selezionare l'opzione Nuovo pool. Nella schermata Crea pool, assegnare un nome al pool di Spark. Scegliere anche la famiglia di nodi e selezionare una dimensione del nodo dalle dimensioni disponibili (Piccolo, Medio, Grande, Grandissimo ed Enorme) in base ai requisiti di calcolo per i carichi di lavoro.
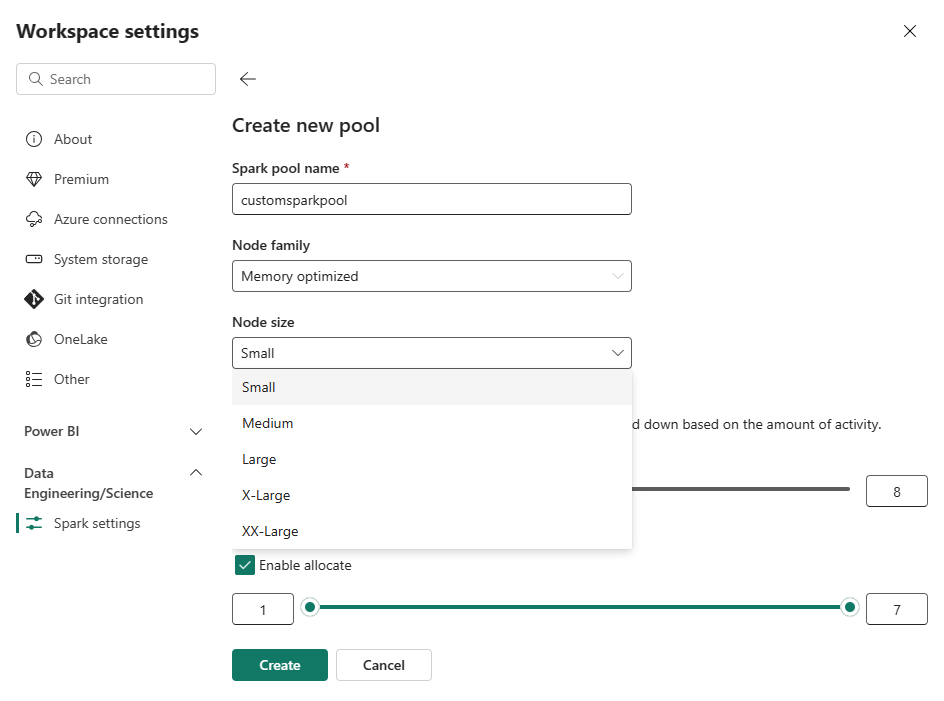
È possibile impostare la configurazione minima dei nodi per i pool personalizzati su 1. Poiché Fabric Spark offre disponibilità ripristinabile per i cluster con un singolo nodo, non è necessario preoccuparsi degli errori dei processi, della perdita di sessione durante gli errori o del pagamento in base al calcolo per processi Spark più piccoli.
È possibile abilitare o disabilitare la scalabilità automatica per i pool di Spark personalizzati. Quando la scalabilità automatica è abilitata, il pool acquisirà in modo dinamico nuovi nodi entro il limite massimo specificato dall'utente e poi li ritira dopo l'esecuzione del processo. Questa funzionalità garantisce prestazioni migliori adattando le risorse in base ai requisiti del processo. È possibile ridimensionare i nodi, che rientrano nelle unità di capacità acquistate come parte dello SKU della capacità di Fabric.
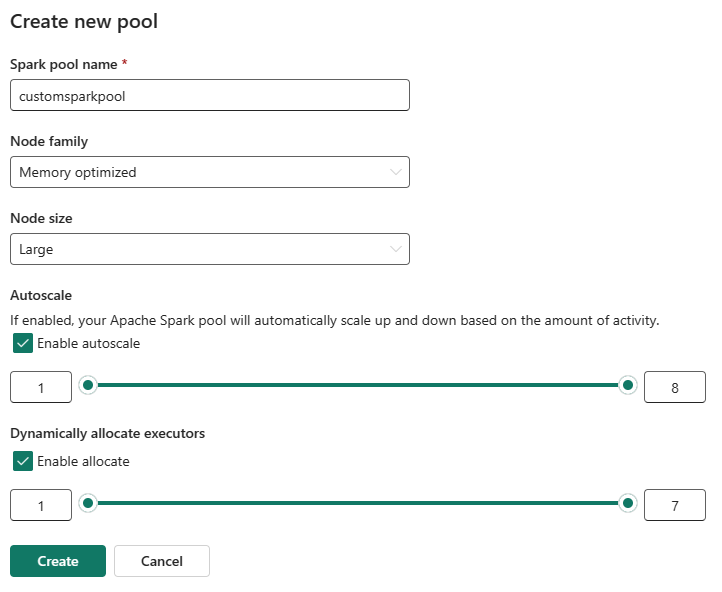
È anche possibile scegliere di abilitare l'allocazione dinamica dell'executor per il pool di Spark, che determina automaticamente il numero ottimale di executor entro il limite massimo specificato dall'utente. Questa funzionalità adatta il numero di executor in base al volume dei dati, con conseguente miglioramento delle prestazioni e dell'utilizzo delle risorse.

Questi pool personalizzati hanno una durata predefinita di sospensione automatica di 2 minuti. Una volta raggiunta la durata della sospensione automatica, la sessione scade e i cluster non vengono allocati. Verrà effettuato l'addebito in base al numero di nodi e alla durata per cui vengono usati i pool di Spark personalizzati.
Contenuto correlato
- Per ulteriori informazioni, consultare la documentazione pubblica di Apache Spark.
- Introduzione alle impostazioni di amministrazione dell'area di lavoro di Spark in Microsoft Fabric.