Configurare e gestire le impostazioni di ingegneria dei dati e data science per le capacità di Fabric
Si applica a:✅ ingegneria dei dati e data science in Microsoft Fabric
Quando si crea Microsoft Fabric dal portale di Azure, questo viene aggiunto automaticamente al tenant di Fabric associato alla sottoscrizione usata per creare la capacità. Con la configurazione semplificata in Microsoft Fabric, non è necessario collegare la capacità al tenant di Fabric. Ciò è possibile dal momento che la capacità appena creata verrà elencata nel riquadro delle impostazioni di amministrazione. Questa configurazione offre un'esperienza più rapida affinché gli amministratori inizino a configurare la capacità per i loro team di analisi aziendale.
Per apportare modifiche alle impostazioni di ingegneria dei dati/data science in una capacità, è necessario disporre del ruolo di amministratore per tale capacità. Per ulteriori informazioni sui ruoli che è possibile assegnare agli utenti in una capacità, vedere Ruoli nelle capacità.
Per gestire le impostazioni di ingegneria dei dati/data science per la capacità di Microsoft Fabric, seguire la procedura seguente:
Selezionare l'opzione Impostazioni per aprire il riquadro delle impostazioni per il proprio account Fabric. Selezionare Portale amministrazione nella sezione Governance e informazioni dettagliate
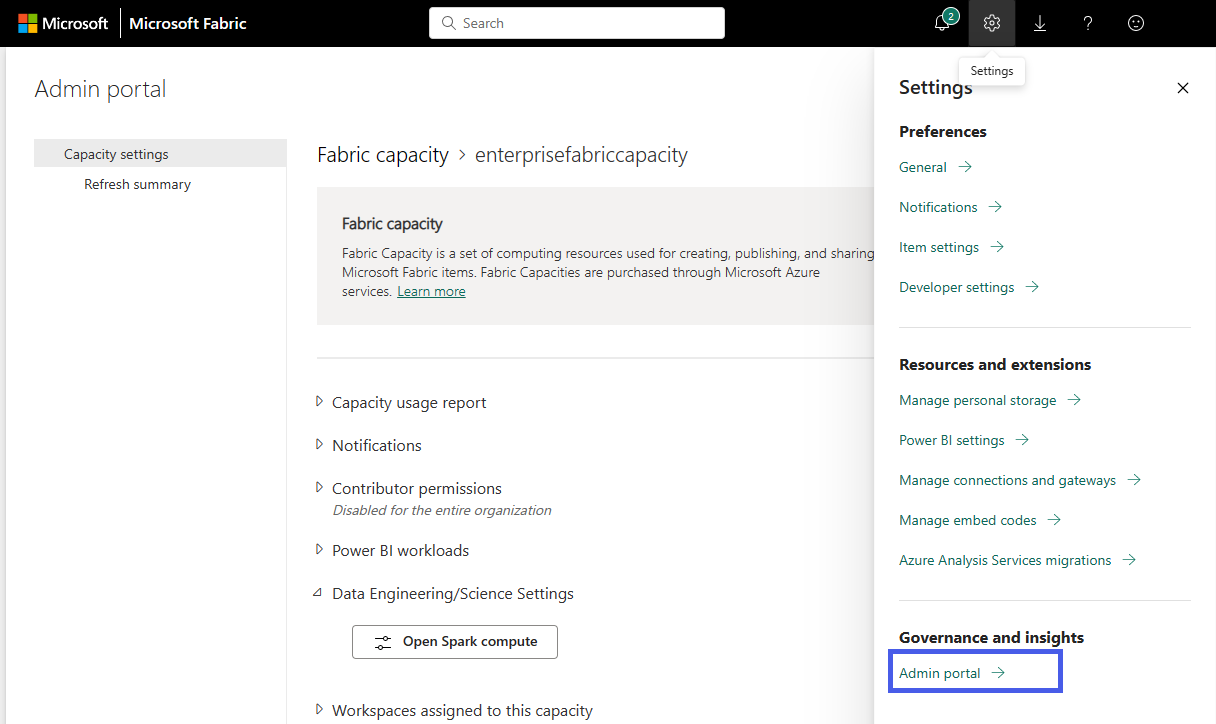
Scegliere l'opzione Impostazioni capacità per espandere il menu e selezionare la scheda Capacità Fabric. Qui, vengono visualizzate le capacità create nel tenant. Scegliere la capacità da configurare.
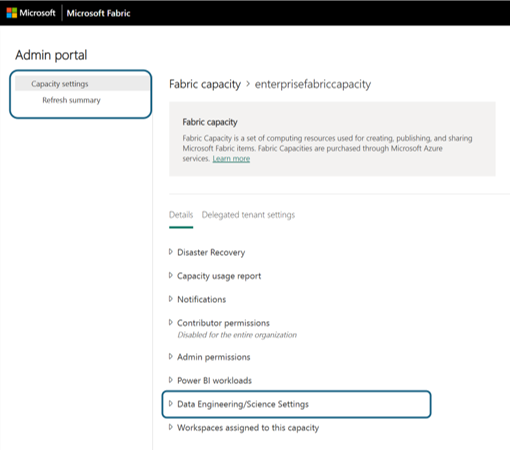
Si viene indirizzati al riquadro dei dettagli della capacità, in cui è possibile visualizzare l'utilizzo e altri controlli di amministrazione per la tua capacità. Passare alla sezione Impostazioni ingegneria dei dati/data science e selezionare Apri calcolo Spark. Configurare i parametri seguenti:
Nota
Almeno un'area di lavoro deve essere collegata alla capacità Fabric per esplorare le impostazioni di ingegneria/scienza dei dati dal portale di amministrazione della capacità Fabric.
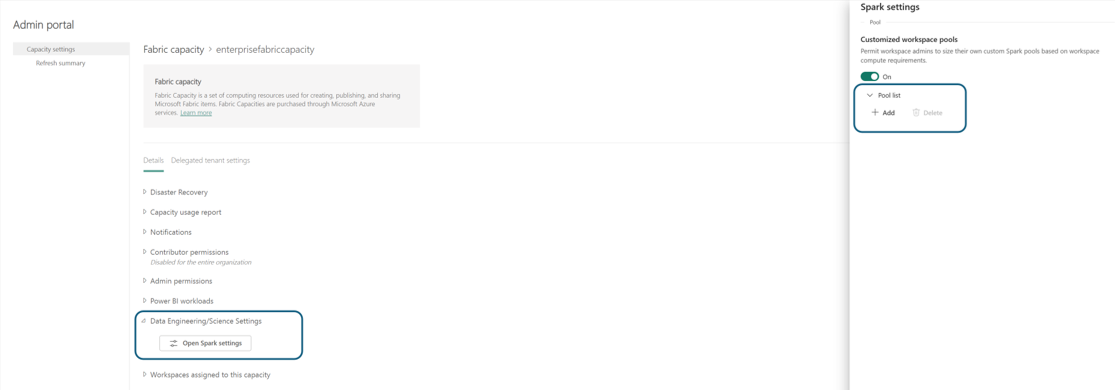
- Pool di aree di lavoro personalizzati: è possibile limitare o democratizzare la personalizzazione del calcolo agli amministratori dell'area di lavoro, abilitando o disabilitando questa opzione. L'abilitazione di questa opzione consente agli amministratori dell'area di lavoro di creare, aggiornare o eliminare pool di Spark personalizzati a livello di area di lavoro. Inoltre, consente di ridimensionarli in base ai requisiti di calcolo entro il limite massimo di core di una capacità.
Pool di capacità per ingegneria dei dati e data science in Microsoft Fabric,anteprima pubblica
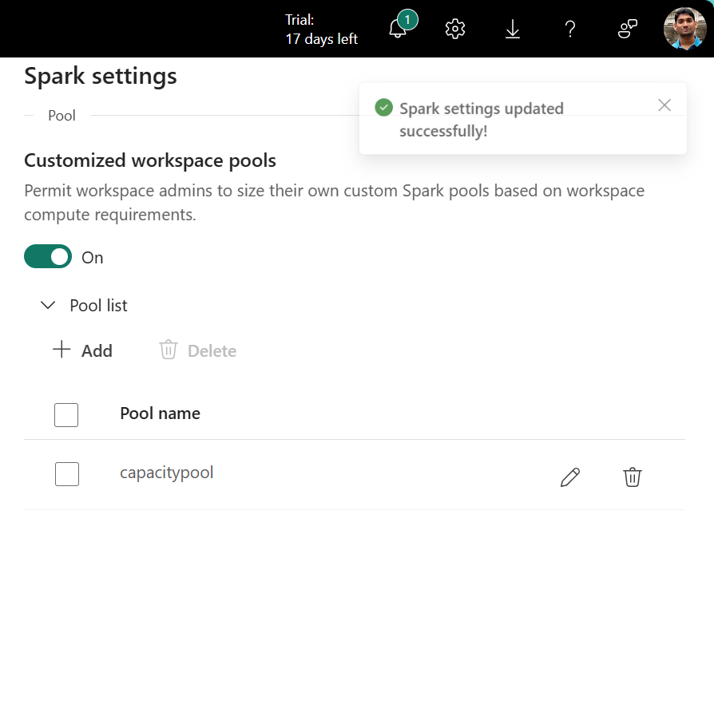
Nella sezione Elenco pool di Impostazioni Spark, fare clic sull'opzioneAggiungi per creare un Pool personalizzato per la capacità Fabric.
Si passa alla sezione Creazione pool, in cui si specifica il nome del pool, la famiglia di nodi, selezionare le dimensioni del nodo e impostare i nodi Min e Max per il pool personalizzato, abilitare/disabilitare la scalabilità automatica e l'allocazione dinamica degli executor.
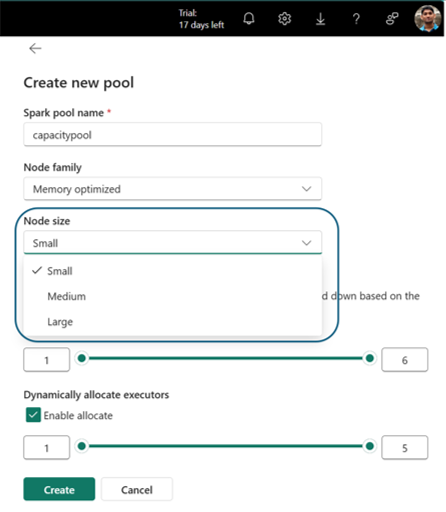
Selezionare Crea e salvare le impostazioni.

Nota
I pool personalizzati creati nelle impostazioni di capacità hanno una latenza di avvio della sessione da 2 minuti a 3 minuti, perché si tratta di sessioni su richiesta a differenza delle sessioni gestite tramite i pool di avvio.
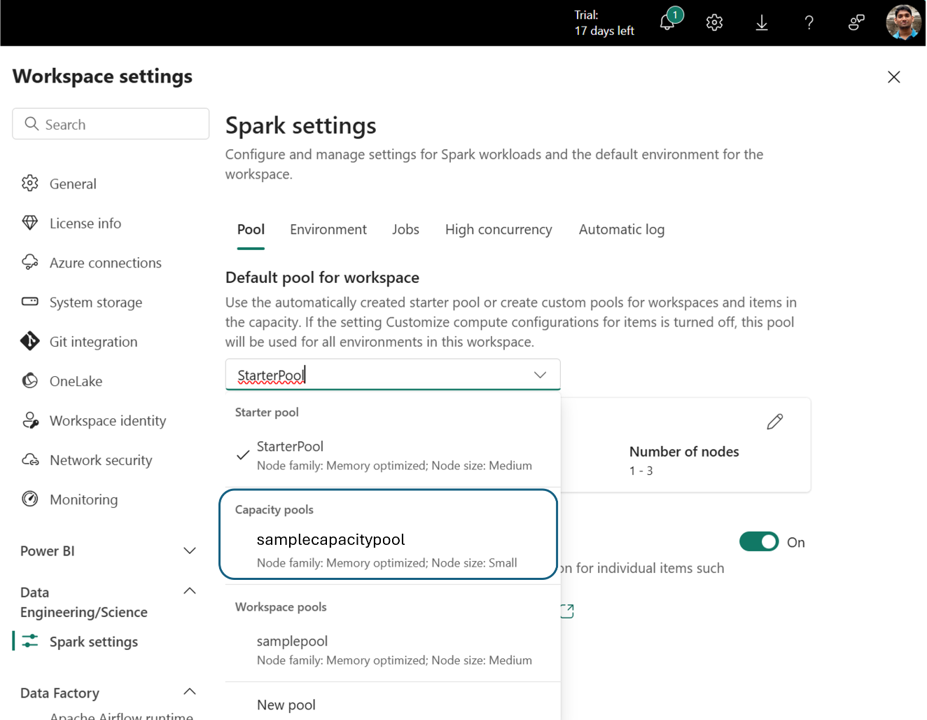
Il pool di Capacità appena creato è ora disponibile come opzione Calcolo nel menu Selezione pool in tutte le aree di lavoro collegate a questa capacità Fabric.
È anche possibile visualizzare il pool di capacità creato come opzione di calcolo nell'elemento dell'ambiente all'interno delle aree di lavoro.
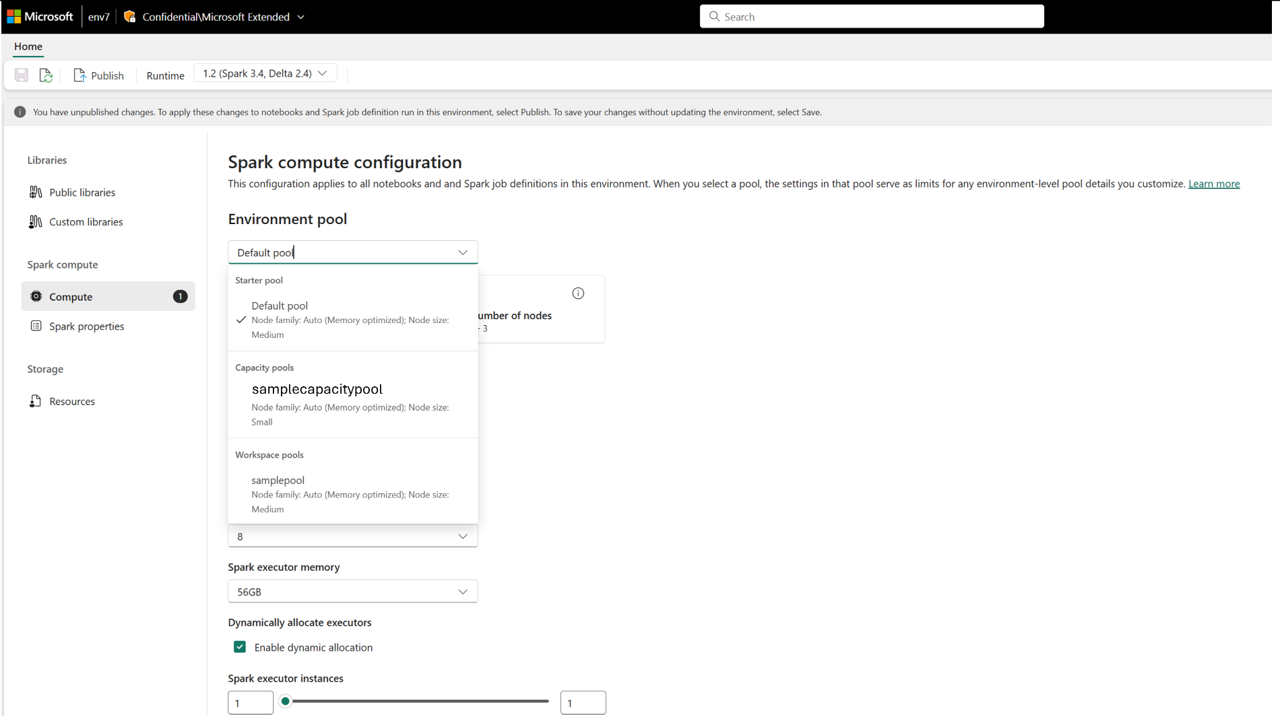
In questo modo, sono disponibili altri controlli amministrativi per gestire la governance del calcolo Spark in Microsoft Fabric. In qualità di amministratore della capacità, è possibile creare Pool per le aree di lavoro e disabilitare la personalizzazione a livello di area di lavoro, il che impedirebbe agli amministratori dell'area di lavoro di creare pool personalizzati.