Motore di esecuzione nativo per Apache Spark
Il motore di esecuzione nativo costituisce un miglioramento eccezionale per le esecuzioni di processi di Apache Spark in Microsoft Fabric. Questo motore vettorializzato ottimizza le prestazioni e l'efficienza delle query Spark eseguendole direttamente nell'infrastruttura Lakehouse. Grazie alla totale integrazione del motore, non sono necessarie modifiche del codice e si evitano accordi esclusivi con i fornitori. Supporta le API Apache Spark ed è compatibile con Runtime 1.3 (Apache Spark 3.5) e funziona con entrambi i formati Parquet e Delta. Indipendentemente dalla posizione dei dati all'interno di OneLake o se si accede ai dati tramite collegamenti, il motore di esecuzione nativo ottimizza l'efficienza e le prestazioni.
Il motore di esecuzione nativo aumenta significativamente le prestazioni delle query riducendo al minimo i costi operativi. Offre un notevole miglioramento della velocità, ottenendo prestazioni fino a quattro volte più veloci rispetto a Spark OSS (software open source) tradizionale, come dimostrato dal benchmark TPC-DS 1 TB. Il motore consente di gestire un'ampia gamma di scenari di elaborazione dati, dall'inserimento di dati di routine, processi batch e attività ETL (estrazione, trasformazione, caricamento) fino a complesse analisi di data science e query interattive reattive. Gli utenti traggono vantaggio dall’accelerazione dei tempi di elaborazione, dall’aumento della velocità effettiva e dall'uso ottimizzato delle risorse.
Il motore di esecuzione nativo si basa su due componenti OSS chiave: Velox, una libreria di accelerazione del database C++ introdotta da Meta, e Apache Glutine (incubating), un livello intermedio responsabile dell'offload dell'esecuzione di motori SQL basati su JVM in motori nativi introdotti da Intel.
Nota
Il motore di esecuzione nativo attualmente è disponibile in anteprima pubblica. Per altre informazioni, vedere le limitazioni correnti. È consigliabile abilitare il motore di esecuzione nativo nei carichi di lavoro senza costi aggiuntivi. Si trarrà vantaggio dall'esecuzione più rapida dei processi senza pagare di più, in modo efficace, si paga meno per lo stesso lavoro.
Quando usare il motore di esecuzione nativo
Il motore di esecuzione nativo offre una soluzione per l'esecuzione di query su set di dati su larga scala; ottimizza le prestazioni usando le funzionalità native delle origini dati sottostanti e riducendo al minimo il sovraccarico tipicamente associato allo spostamento e alla serializzazione dei dati in ambienti Spark tradizionali. Il motore supporta vari operatori e tipi di dati, tra cui l'aggregazione hash rollup, join a cicli annidati broadcast (BNLJ) e i formati di timestamp precisi. Tuttavia, per sfruttare appieno le funzionalità del motore, è consigliabile considerare i casi d'uso ottimali:
- Il motore è efficace quando si lavora con i dati in formati Parquet e Delta, che possono essere elaborati in modo nativo ed efficiente.
- Le query che comportano trasformazioni e aggregazioni complesse traggono notevoli vantaggi dalle funzionalità di elaborazione e vettorizzazione colonnare del motore.
- Il miglioramento delle prestazioni è particolarmente importante negli scenari in cui le query non attivano il meccanismo di fallback evitando funzionalità o espressioni non supportate.
- Il motore è particolarmente adatto per le query che richiedono un utilizzo intensivo delle risorse di calcolo, invece che semplici o associate a I/O.
Per informazioni sugli operatori e sulle funzioni supportate dal motore di esecuzione nativo, vedere la Documentazione di Apache Gluten.
Abilitare il motore di esecuzione nativo
Per usare le funzionalità complete del motore di esecuzione nativo durante la fase di anteprima, sono necessarie configurazioni specifiche. Le procedure seguenti illustrano come attivare questa funzionalità per notebook, definizioni processo e interi ambienti Spark.
Importante
Il motore di esecuzione nativo supporta la versione più recente del runtime ga, ovvero Runtime 1.3 (Apache Spark 3.5, Delta Lake 3.2). Con il rilascio del motore di esecuzione nativo in Runtime 1.3, il supporto per la versione precedente( Runtime 1.2 (Apache Spark 3.4, Delta Lake 2.4) è stato sospeso. Si consiglia a tutti i clienti di eseguire l'aggiornamento alla versione più recente di Runtime 1.3. Se si usa il motore di esecuzione nativo in Runtime 1.2, l'accelerazione nativa verrà presto disabilitata.
Abilitare a livello di ambiente
Per garantire un miglioramento uniforme delle prestazioni, abilitare il motore di esecuzione nativo in tutti i processi e i notebook associati all'ambiente:
Spostarsi nelle impostazioni dell'ambiente.
Passare a Calcolo Spark.
Passare alla scheda Accelerazione .
Selezionare la casella Abilita motore di esecuzione nativo.
Salvare e pubblicare le modifiche.
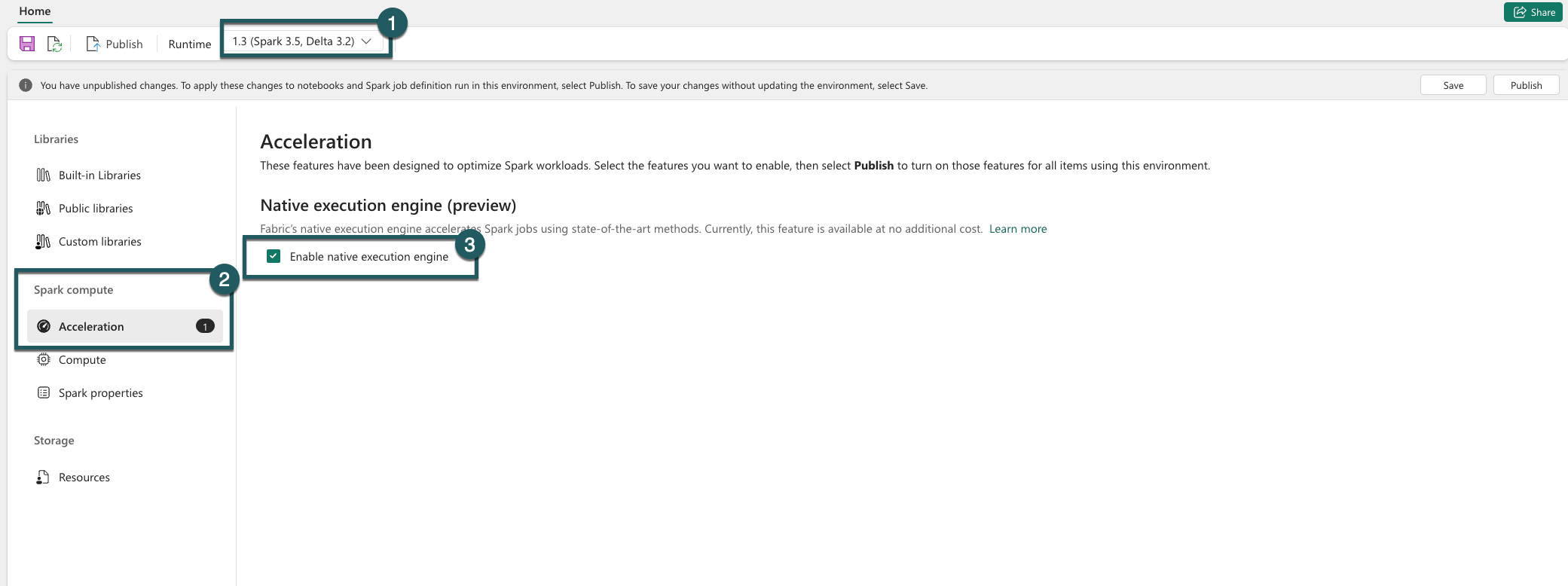

Se abilitato a livello di ambiente, tutti i processi e i notebook successivi ereditano l'impostazione. Questa ereditarietà garantisce che qualsiasi nuova sessione o risorsa creata nell'ambiente sfrutti automaticamente le funzionalità di esecuzione avanzate.
Importante
In precedenza, il motore di esecuzione nativo è stato abilitato tramite le impostazioni di Spark all'interno della configurazione dell'ambiente. Con l'aggiornamento più recente (implementazione in corso), questa operazione è stata semplificata introducendo un interruttore nella scheda Accelerazione delle impostazioni dell'ambiente. Riabilitare il motore di esecuzione nativo usando il nuovo interruttore: per continuare a usare il motore di esecuzione nativo, passare alla scheda Accelerazione nelle impostazioni dell'ambiente e abilitarla tramite l'interruttore. La nuova impostazione di attivazione/disattivazione nell'interfaccia utente ora assume la priorità rispetto alle configurazioni delle proprietà Spark precedenti. Se in precedenza è stato abilitato il motore di esecuzione nativo tramite le impostazioni di Spark, questo viene disabilitato fino a quando non viene riabilitato tramite l'interruttore dell'interfaccia utente.
In linea con i criteri di blocco della distribuzione di Microsoft Azure durante le festività del Ringraziamento e del Venerdì nero, l'implementazione per l'area Stati Uniti centro-settentrionali (NCUS) è stata riprogrammata al 6 dicembre e all'area Stati Uniti orientali al 9 dicembre. Apprezziamo la vostra comprensione e la pazienza durante questo tempo occupato.
Abilitare per un notebook o una definizione processo Spark
Per abilitare il motore di esecuzione nativo per un singolo notebook o una definizione processo Spark, è necessario incorporare le configurazioni necessarie all'inizio dello script di esecuzione:
%%configure
{
"conf": {
"spark.native.enabled": "true",
}
}
Per i notebook, inserire i comandi di configurazione necessari nella prima cella. Per le definizioni processo Spark, includere le configurazioni in prima linea nella definizione processo Spark. Il motore di esecuzione nativo è integrato con i pool live, quindi, dopo aver abilitato la funzionalità, diventa effettivo immediatamente senza richiedere l'avvio di una nuova sessione.
Importante
La configurazione del motore di esecuzione nativo deve essere eseguita prima dell'avvio della sessione Spark. Dopo l'avvio della sessione Spark, l'impostazione spark.shuffle.manager diventa immutabile e non può essere modificata. Assicurarsi che queste configurazioni siano impostate all'interno del blocco %%configure nei notebook o nel generatore di sessioni Spark per le definizioni processo Spark.
Controllo a livello di query
I meccanismi per abilitare il motore di esecuzione nativo a livello di tenant, area di lavoro e ambiente, perfettamente integrato con l'interfaccia utente, sono in fase di sviluppo attivo. Nel frattempo, è possibile disabilitare il motore di esecuzione nativo per query specifiche, in particolare se coinvolgono operatori che attualmente non sono supportati (vedere le limitazioni). Per disabilitare, impostare la configurazione Spark spark.native.enabled su false per la cella specifica contenente la query.
%%sql
SET spark.native.enabled=FALSE;

Dopo aver eseguito la query in cui il motore di esecuzione nativo è disabilitato, è necessario riabilitarlo per le celle successive impostando spark.native.enabled su true. Questo passaggio è necessario perché Spark esegue le celle di codice in sequenza.
%%sql
SET spark.native.enabled=TRUE;
Identificare le operazioni eseguite dal motore
Esistono diversi metodi per determinare se un operatore nel processo Apache Spark è stato elaborato usando il motore di esecuzione nativo.
Interfaccia utente di Spark e server cronologia di Spark
Accedere all'interfaccia utente di Spark o al server cronologia di Spark per individuare la query da esaminare. Per accedere all'interfaccia utente Web Spark, navigare alla definizione del job Spark ed eseguirla. Nella scheda

Nel piano di query visualizzato nell'interfaccia utente di Spark, si devono cercare i nomi di nodo che terminano con il suffisso Transformer, *NativeFileScan, o VeloxColumnarToRowExec. Il suffisso indica che il motore di esecuzione nativo ha eseguito l'operazione. Ad esempio, i nodi possono essere etichettati come RollUpHashAggregateTransformer, ProjectExecTransformer, BroadcastHashJoinExecTransformer, ShuffledHashJoinExecTransformer o BroadcastNestedLoopJoinExecTransformer.

Spiegazione del DataFrame
In alternativa, è possibile eseguire il comando df.explain() nel notebook per visualizzare il piano di esecuzione. All'interno dell'output, cercare i medesimi suffissi di Transformer, *NativeFileScan o VeloxColumnarToRowExec. Questo metodo consente di verificare rapidamente se le operazioni specifiche sono gestite dal motore di esecuzione nativo.

Meccanismo di fallback
In alcuni casi, il motore di esecuzione nativo potrebbe non riuscire a eseguire una query a causa di motivi come funzionalità non supportate. In questi casi, l'operazione esegue il fallback al motore Spark tradizionale. Questo meccanismo di fallback automatico garantisce che non vi sia alcuna interruzione del flusso di lavoro.


Monitorare query e dataframe eseguiti dal motore
Per comprendere meglio il modo in cui il motore di esecuzione nativa viene applicato alle query SQL e alle operazioni del dataframe e per eseguire il drill-down ai livelli di fase e operatore, è possibile fare riferimento all'interfaccia utente spark e al server cronologia Spark per informazioni più dettagliate sull'esecuzione del motore nativo.
Scheda Motore di esecuzione nativo
È possibile passare alla nuova scheda "Glutine SQL/DataFrame" per visualizzare le informazioni sulla compilazione glutine e i dettagli di esecuzione delle query. La tabella Query fornisce informazioni dettagliate sul numero di nodi in esecuzione nel motore nativo e quelli che rientrano nella JVM per ogni query.

Grafico esecuzione query
È anche possibile selezionare la descrizione della query per visualizzare il piano di esecuzione delle query Apache Spark. Il grafico dell'esecuzione fornisce dettagli di esecuzione nativi nelle fasi e nelle rispettive operazioni. I colori di sfondo differenziano i motori di esecuzione: il verde rappresenta il motore di esecuzione nativo, mentre il blu chiaro indica che l'operazione è in esecuzione nel motore JVM predefinito.

Limiti
Anche se il motore di esecuzione nativo migliora le prestazioni per i processi Apache Spark, tenere presente le limitazioni correnti.
- Alcune operazioni specifiche di Delta non sono supportate (ancora, poiché ci stiamo lavorando attivamente), tra cui operazioni di merge, analisi dei checkpoint e vettori di cancellazione.
- Determinate funzionalità ed espressioni Spark non sono compatibili con il motore di esecuzione nativo, ad esempio funzioni definite dall'utente (UDF) e la funzione
array_contains, nonché Spark Structured Streaming. L'utilizzo di queste operazioni o funzioni incompatibili come parte di una libreria importata causerà anche il fallback al motore Spark. - Le scansioni provenienti da soluzioni di archiviazione che utilizzano endpoint privati non sono ancora supportate, ma ci stiamo lavorando attivamente.
- Il motore non supporta la modalità ANSI, quindi esegue la ricerca e una volta abilitata la modalità ANSI, viene eseguito automaticamente il fallback a vanilla Spark.
Quando si usano filtri di data nelle query, è essenziale assicurarsi che i tipi di dati su entrambi i lati del confronto corrispondano per evitare problemi di prestazioni. Tipi di dati non corrispondenti potrebbero non accelerare l’esecuzione delle query e potrebbero richiedere il casting esplicito. Assicurarsi sempre che i tipi di dati del lato sinistro (LHS) e del lato destro (RHS) di un confronto siano identici, poiché i tipi non corrispondenti non saranno sempre convertiti automaticamente. Se una mancata corrispondenza del tipo è inevitabile, usare il casting esplicito per trovare le corrispondenze con i tipi di dati, ad esempio CAST(order_date AS DATE) = '2024-05-20'. Le query con tipi di dati non corrispondenti che richiedono il cast non verranno accelerate dal motore di esecuzione nativo, quindi garantire la coerenza dei tipi è fondamentale per mantenere le prestazioni. Ad esempio, anziché order_date = '2024-05-20' dove order_date è DATETIME e la stringa è DATE, eseguire il casting esplicito di order_date in DATE per garantire tipi di dati coerenti e per migliorare le prestazioni.