Importazione guidata dati nel portale di Azure
Ricerca di intelligenza artificiale di Azure include due procedure guidate di importazione che automatizzano l'indicizzazione e la creazione di oggetti in modo da poter iniziare immediatamente a eseguire query. Se non si ha familiarità con Azure AI Search, queste procedure guidate sono una delle funzionalità più potenti a disposizione. Con il minimo sforzo, è possibile creare una pipeline di indicizzazione o arricchimento che esercita la maggior parte delle funzionalità di Azure AI Search.
La procedura guidata Importa dati supporta flussi di lavoro non di controllo. È possibile estrarre testo e numeri da documenti non elaborati. È anche possibile configurare l'intelligenza artificiale applicata e le competenze predefinite che deducono la struttura e generano contenuto ricercabile in testo dai file di immagine e dai dati non strutturati.
La creazione guidata importazione e vettorizzazione dei dati aggiunge la suddivisione in blocchi e la vettorizzazione. È necessario specificare una distribuzione esistente di un modello di incorporamento, ma la procedura guidata effettua la connessione, formula la richiesta e gestisce la risposta. Genera contenuto vettoriale dal contenuto di testo o immagine.
Se si utilizza la procedura guidata per i test di verifica, questo articolo illustra il funzionamento interno delle procedure guidate in modo da poterle utilizzare in modo più efficace.
Questo articolo non è un passaggio dettagliato. Per informazioni sull'uso della procedura guidata con dati di esempio, vedere:
- Avvio rapido: Creare un indice di ricerca
- Avvio rapido: Creare un set di competenze di testo ed entità
- Avvio rapido: Creare un indice vettoriale
- Avvio rapido: Ricerca immagini (vettori)
Origini dati e scenari supportati
Le procedure guidate supportano la maggior parte delle origini dati supportate dagli indicizzatori.
| Dati | Procedura guidata di importazione dei dati | Procedura guidata di importazione e vettorizzazione dei dati |
|---|---|---|
| ADLS Gen2 | ✅ | ✅ |
| Archiviazione BLOB di Azure | ✅ | ✅ |
| Archiviazione file di Azure | ❌ | ❌ |
| Archiviazione tabelle di Azure | ✅ | ✅ |
| Database SQL di Azure e istanza gestita | ✅ | ✅ |
| Cosmos DB per NoSQL | ✅ | ✅ |
| Cosmos DB per MongoDB | ✅ | ✅ |
| Cosmos DB per Apache Gremlin | ✅ | ✅ |
| MySQL | ❌ | ❌ |
| OneLake | ✅ | ✅ |
| SharePoint Online | ❌ | ❌ |
| SQL Server in macchine virtuali | ✅ | ✅ |
Dati di esempio
Microsoft ospita dati di esempio in modo che sia possibile omettere un passaggio di configurazione dell'origine dati in un flusso di lavoro della procedura guidata.
| Dati di esempio | Procedura guidata di importazione dei dati | Procedura guidata di importazione e vettorizzazione dei dati |
|---|---|---|
| hotels | ✅ | ❌ |
| real estate | ✅ | ❌ |
Competenze
Questa sezione elenca le competenze che potrebbero essere visualizzate in un set di competenze generato da una procedura guidata. Le procedure guidate generano un set di competenze e mapping dei campi di output in base alle opzioni selezionate. Dopo aver creato il set di competenze, è possibile modificare la relativa definizione JSON per aggiungere altre competenze.
Ecco alcuni punti da tenere presenti sulle competenze nell'elenco seguente:
- Le opzioni di analisi delle immagini e OCR sono disponibili per i BLOB in Archiviazione di Azure e file in OneLake, presupponendo la modalità di analisi predefinita. Le immagini sono un tipo di contenuto immagine (ad esempio PNG o JPG) o un'immagine incorporata in un file dell'applicazione (ad esempio PDF).
- Shaper viene aggiunto se si configura un archivio conoscenze.
- La suddivisione del testo e l'unione testo vengono aggiunte per la suddivisione in blocchi di dati se si sceglie un modello di incorporamento. Vengono aggiunte per altre competenze non incorporate se la granularità del campo di origine è impostata su pagine o frasi.
| Competenze | Procedura guidata di importazione dei dati | Procedura guidata di importazione e vettorizzazione dei dati |
|---|---|---|
| Vision di intelligenza artificiale ( multi-visione artificiale) | ❌ | ✅ |
| Incorporamento di Azure OpenAI | ❌ | ✅ |
| Azure Machine Learning (catalogo dei modelli di Azure AI Foundry) | ❌ | ✅ |
| Layout documento | ❌ | ✅ |
| Riconoscimento delle entità | ✅ | ❌ |
| Analisi delle immagini (si applica ai BLOB, analisi predefinita, indicizzazione di file interi | ✅ | ❌ |
| Estrazione di parole chiave | ✅ | ❌ |
| Rilevamento lingua | ✅ | ❌ |
| Traduzione testo | ✅ | ❌ |
| OCR (si applica ai BLOB, analisi predefinita, indicizzazione di file interi) | ✅ | ✅ |
| Rilevamento di informazioni personali | ✅ | ❌ |
| Analisi valutazione | ✅ | ❌ |
| Shaper (si applica all'archivio conoscenze) | ✅ | ❌ |
| Suddivisione del testo | ✅ | ✅ |
| Fusione di testi | ✅ | ✅ |
Archivio conoscenze
È possibile generare un archivio conoscenze per l'archiviazione secondaria di contenuto arricchito (generato da competenze). Potrebbe essere necessario un archivio conoscenze per i flussi di lavoro di recupero delle informazioni che non richiedono un motore di ricerca.
| Archivio conoscenze | Procedura guidata di importazione dei dati | Procedura guidata di importazione e vettorizzazione dei dati |
|---|---|---|
| storage | ✅ | ❌ |
Creazione delle procedure guidate
Le procedure guidate di importazione creano gli oggetti descritti nella tabella seguente. Dopo aver creato gli oggetti, è possibile esaminare le relative definizioni JSON nel portale di Azure o chiamarle dal codice.
Per visualizzare questi oggetti dopo l'esecuzione della procedura guidata:
Accedere al portale di Azure e trovare il servizio di ricerca.
Selezionare Gestione ricerca nel menu per trovare pagine per indici, indicizzatori, origini dati e set di competenze.
| Oggetto | Descrizione |
|---|---|
| Indicizzatore | Oggetto di configurazione che specifica un'origine dati, un indice di destinazione, un set di competenze facoltativo, una pianificazione facoltativa e impostazioni di configurazione facoltative per la gestione degli errori e la codifica base 64. |
| Origine dati | Rende persistenti le informazioni di connessione a un'origine dati supportata in Azure. Un oggetto di origine dati viene usato esclusivamente con gli indicizzatori. |
| Indice | Struttura dei dati fisici usata per la ricerca full-text e altre query. |
| Skillset | Facoltativo. Set completo di istruzioni per la modifica, la trasformazione e la modellazione del contenuto, tra cui l'analisi e l'estrazione di informazioni dai file di immagine. I set di competenze vengono usati anche per la vettorializzazione integrata. A meno che il volume di lavoro non sia inferiore al limite di 20 transazioni al giorno per indicizzatore, il set di competenze deve includere un riferimento a una risorsa multiservizio di Azure per intelligenza artificiale che fornisce l'arricchimento. Per la vettorializzazione integrata, è possibile usare Visione artificiale di Azure o un modello di incorporamento nel catalogo dei modelli di Azure AI Foundry. |
| Archivio conoscenze | Facoltativo. Disponibile solo nella procedura guidata Importa dati . Archivia l'output del set di competenze arricchito da in tabelle e BLOB in Archiviazione di Azure per l'analisi indipendente o l'elaborazione downstream in scenari non di ricerca. |
Vantaggi
Prima di scrivere qualunque codice, è possibile usare le procedure guidate per la creazione di prototipi e il test di verifica. Le procedure guidate si connettono a origini dati esterne, campionano i dati per creare un indice iniziale e quindi importano e facoltativamente eseguire la vettorizzazione i dati come documenti JSON in un indice in Azure AI Search.
Se si valutano set di competenze, la procedura guidata gestisce i mapping dei campi di output e aggiunge funzioni helper per creare oggetti utilizzabili. La suddivisione del testo viene aggiunta se si specifica una modalità di analisi. L'unione testo viene aggiunta se si sceglie l'analisi delle immagini in modo che la procedura guidata possa riunire le descrizioni di testo con il contenuto dell'immagine. Le competenze del shaper vengono aggiunte per supportare proiezioni valide se si sceglie l'opzione dell'archivio conoscenze. Tutte le attività precedenti sono dotate di una curva di apprendimento. Se non si ha familiarità con l'arricchimento, la possibilità di gestire questi passaggi consente di misurare il valore di una competenza senza dover investire molto tempo e fatica.
Il campionamento è il processo in base al quale viene dedotto uno schema di indice e presenta alcune limitazioni. Quando viene creata l'origine dati, la procedura guidata seleziona un campione casuale di documenti per decidere quali colonne fanno parte dell'origine dati. Non tutti i file vengono letti, perché ciò potrebbe richiedere ore per origini dati molto grandi. Dato una selezione di documenti, metadati di origine, ad esempio nome di campo o tipo, viene usato per creare una raccolta di campi in uno schema di indice. A seconda della complessità dei dati di origine, potrebbe essere necessario modificare lo schema iniziale per l'accuratezza o estenderlo per completezza. È possibile apportare le modifiche inline nella pagina di definizione dell'indice.
In generale, i vantaggi dell'uso della procedura guidata sono chiari: purché i requisiti siano soddisfatti, è possibile creare un indice disponibile per query entro pochi minuti. Alcune delle complessità dell'indicizzazione, ad esempio la serializzazione dei dati come documenti JSON, vengono gestite dalle procedure guidate.
Limiti
Le procedure guidate di importazione non sono senza limitazioni. I vincoli sono riepilogati nel modo seguente:
Le procedure guidate non supportano l'iterazione o il riutilizzo. Ogni passaggio della procedura guidata crea un nuovo indice, un set di competenze e una configurazione dell'indicizzatore. Solo le origini dati possono essere mantenute e riutilizzate all'interno della procedura guidata. Per modificare o perfezionare altri oggetti, eliminare gli oggetti e ricominciare oppure usare le API REST o .NET SDK per modificare le strutture.
Il contenuto di origine deve risiedere in un'origine dati supportata.
Il campionamento viene eseguito su un subset di dati di origine. Per le origini dati di grandi dimensioni, è possibile che la procedura guidata non riesca a visualizzare i campi. Potrebbe essere necessario estendere lo schema o correggere i tipi di dati dedotti, se il campionamento non è sufficiente.
L'arricchimento tramite intelligenza artificiale, come esposto nella portale di Azure, è limitato a un subset di competenze predefinite.
Un archivio conoscenze, che può essere creato dalla procedura guidata Importa dati , è limitato a poche proiezioni predefinite e usa una convenzione di denominazione predefinita. Per personalizzare nomi o proiezioni, è necessario creare l'archivio conoscenze tramite l'API REST o gli SDK.
Connessioni sicure
Le procedure guidate di importazione effettuano connessioni in uscita usando il controller di portale di Azure e gli endpoint pubblici. Non è possibile usare le procedure guidate se si accede alle risorse di Azure tramite una connessione privata o tramite un collegamento privato condiviso.
È possibile usare le procedure guidate su connessioni pubbliche limitate, ma non tutte le funzionalità sono disponibili.
In un servizio di ricerca l'importazione dei dati di esempio predefiniti richiede un endpoint pubblico e nessuna regola del firewall.
I dati di esempio sono ospitati da Microsoft in risorse di Azure specifiche. il controller portale di Azure si connette a tali risorse tramite un endpoint pubblico. Se si inserisce il servizio di ricerca dietro un firewall, viene visualizzato questo errore quando si tenta di recuperare i dati di esempio predefiniti:
Import configuration failed, error creating Data Source, seguito da"An error has occured.".Nelle origini dati di Azure supportate protette da firewall, è possibile recuperare i dati se sono presenti le regole del firewall corrette.
La risorsa di Azure deve ammettere le richieste di rete dall'indirizzo IP del dispositivo usato nella connessione. È anche consigliabile elencare Azure AI Search come servizio attendibile nella configurazione di rete della risorsa. Ad esempio, in Archiviazione di Azure è possibile elencare
Microsoft.Search/searchServicescome servizio attendibile.Nelle connessioni a un account multiservizio di Intelligenza artificiale di Azure fornito o sulle connessioni ai modelli di incorporamento distribuiti nel portale di Azure AI Foundry o in Azure OpenAI, l'accesso a Internet pubblico deve essere abilitato a meno che il servizio di ricerca non soddisfi i requisiti di data di creazione, livello e area per le connessioni private. Per altre informazioni su questi requisiti, vedere Stabilire connessioni in uscita tramite un collegamento privato condiviso.
Le connessioni al multiservizio di Intelligenza artificiale di Azure sono destinate alla fatturazione. La fatturazione si verifica quando le chiamate API superano il numero di transazioni gratuite (20 per esecuzione indicizzatore) per le competenze predefinite chiamate dalla procedura guidata Importa dati o vettorizzazione integrata nella procedura guidata Importa e vettorizza dati .
Se Ricerca intelligenza artificiale di Azure non è in grado di connettersi:
Nella procedura guidata Importare ed eseguire la vettorizzazione dei dati l'errore è
"Access denied due to Virtual Network/Firewall rules."Nella procedura guidata Importa dati non viene visualizzato alcun errore, ma il set di competenze non verrà creato.
Se le impostazioni del firewall impediscono la riuscita dei flussi di lavoro della procedura guidata, prendere in considerazione gli approcci script o programmatici.
Workflow
La procedura guidata è organizzata in quattro passaggi principali:
Connettersi a un'origine dati di Azure supportata.
Creare uno schema di indice, dedotto dai dati di origine di campionamento.
Facoltativamente, aggiunge competenze per estrarre o generare contenuto e struttura. Gli input per la creazione di un archivio conoscenze vengono raccolti in questo passaggio.
Eseguire la procedura guidata per creare oggetti, facoltativamente eseguire la vettorizzazione dei dati, caricare i dati in un indice, impostare una pianificazione e altre opzioni di configurazione.
Il flusso di lavoro è una pipeline, quindi è a senso unico. Non è possibile usare la procedura guidata per modificare gli oggetti creati, ma è possibile usare altri strumenti del portale, ad esempio la finestra di progettazione dell'indice o dell'indicizzatore o gli editor JSON, per gli aggiornamenti consentiti.
Avvio delle procedure guidate
Ecco come avviare le procedure guidate.
Nel portale di Azure aprire la pagina per la ricerca dei servizi dal dashboard o trovare il servizio nell'elenco.
Nella pagina di panoramica del servizio nella parte superiore selezionare Importare dati o Importare e eseguire la vettorizzazione i dati.
Le procedure guidate vengono aperte completamente espanse nella finestra del browser in modo da avere più spazio per lavorare.
Se è stata selezionata l'opzione Importa dati, è possibile selezionare l'opzione Esempi per indicizzare un set di dati ospitato da Microsoft da un'origine dati supportata.
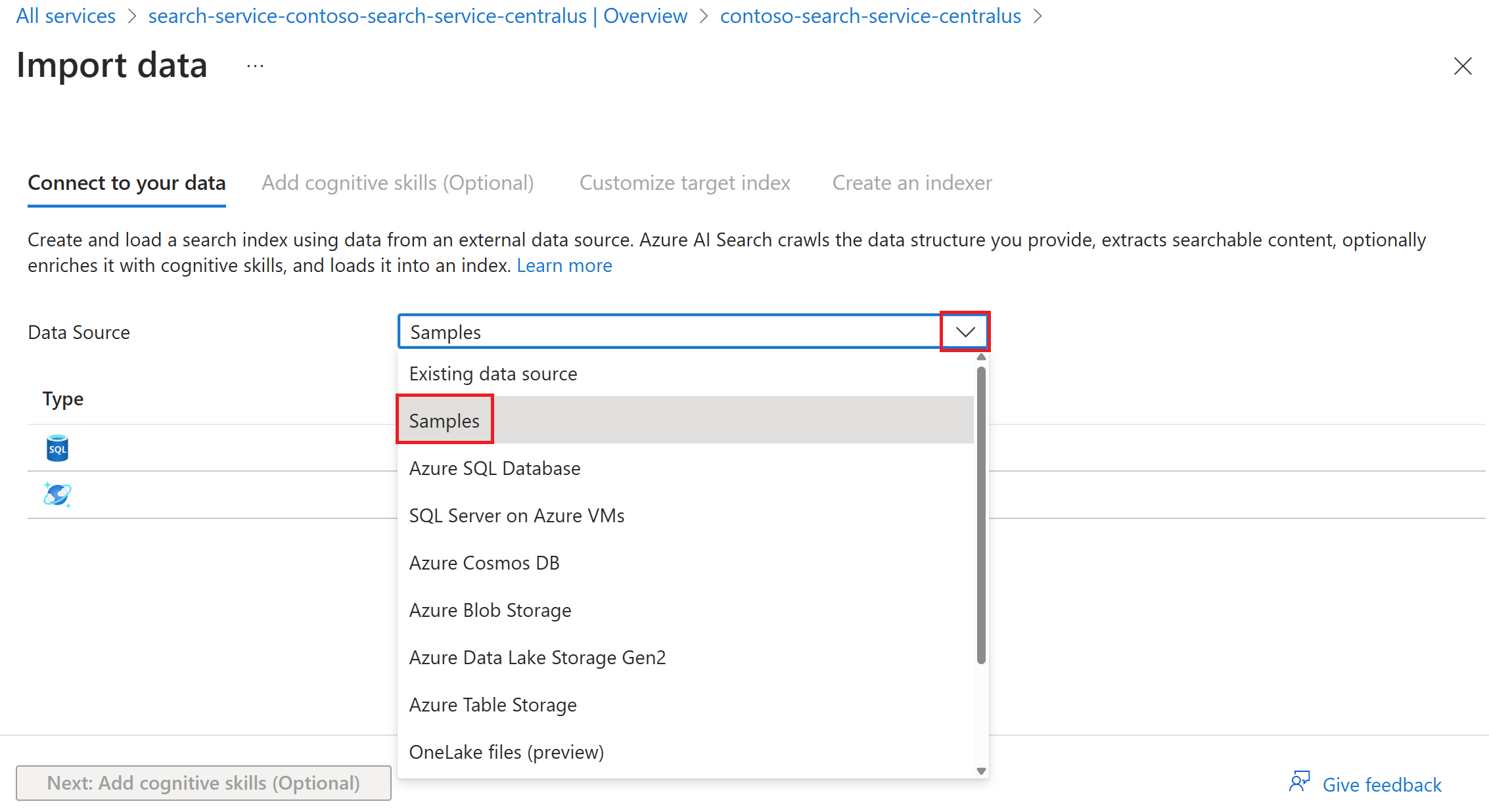
Seguire i passaggi rimanenti della procedura guidata per creare l'indice e l'indicizzatore.
È anche possibile avviare Importa dati da altri servizi di Azure, inclusi Azure Cosmos DB, database SQL di Azure, Istanza gestita di SQL e Archiviazione Blob di Azure. Cercare Aggiungi Azure AI Search nel riquadro di spostamento a sinistra nella pagina di panoramica del servizio.
Configurazione dell'origine dati nella procedura guidata
Le procedure guidate si connettono a un'origine dati esterna supportata usando la logica interna fornita dagli indicizzatori di Azure AI Search, che sono dotati di campionare l'origine, leggere i metadati, violare i documenti per leggere il contenuto e la struttura e serializzare il contenuto come JSON per l'importazione successiva in Azure AI Search.
È possibile incollare una connessione a un'origine dati supportata in una sottoscrizione o un'area diversa, ma la selezione Scegliere una connessione esistente è limitato alla sottoscrizione attiva.
Non tutte le origini dati di anteprima sono sicuramente disponibili nella procedura guidata. Poiché ogni origine dati ha il potenziale per introdurre altre modifiche downstream, un'origine dati di anteprima verrà aggiunta solo all'elenco delle origini dati se supporta completamente tutte le esperienze della procedura guidata, ad esempio la definizione del set di competenze e l'inferenza dello schema dell'indice.
È possibile importare solo da una singola tabella, una vista di database o una struttura di dati equivalente, ma la struttura può includere sottostruttura gerarchiche o annidate. Per altre informazioni, vedere Come modellare tipi complessi.
Configurazione del set di competenze nella procedura guidata
La configurazione del set di competenze viene eseguita dopo la definizione dell'origine dati, perché il tipo di origine dati informa la disponibilità di alcune competenze predefinite. In particolare, se si esegue l'indicizzazione dei file dall'archivio BLOB, la scelta della modalità di analisi di tali file determina se l'analisi del sentiment è disponibile.
La procedura guidata aggiunge le competenze scelte. Aggiunge anche altre competenze necessarie per ottenere un risultato positivo. Ad esempio, se si specifica un archivio conoscenze, la procedura guidata aggiunge una competenza Shaper per supportare proiezioni (o strutture di dati fisiche).
I set di competenze sono facoltativi ed è presente un pulsante nella parte inferiore della pagina per andare avanti se non si vuole l'arricchimento tramite intelligenza artificiale.
Configurazione dello schema di indice nella procedura guidata
Le procedure guidate analizzano l'origine dati per rilevare i campi e il tipo di campo. A seconda dell'origine dati, potrebbe anche offrire campi per l'indicizzazione dei metadati.
Poiché il campionamento è un esercizio impreciso, è necessario rivedere l'indice per le seguenti considerazioni:
L'elenco dei campi è accurato? Se l'origine dati contiene campi che non sono stati prelevati nel campionamento, è possibile aggiungere manualmente tutti i nuovi campi che il campionamento non è stato eseguito e rimuovere tutti gli elementi che non aggiungono valore a un'esperienza di ricerca o che non verranno usati in un'espressione di filtro o profilo di punteggio.
Il tipo di dati è appropriato per i dati in ingresso? Azure AI Search supporta i tipi di dati entity data model (EDM). Per i dati SQL di Azure, è disponibile grafico di mapping che definisce i valori equivalenti. Per altre informazioni, vedere Mapping e trasformazioni dei campi.
Si dispone di un campo che può fungere da chiave? Questo campo deve essere Edm.string e deve identificare in modo univoco un documento. Per i dati relazionali, è possibile che venga eseguito il mapping a una chiave primaria. Per i BLOB, potrebbe trattarsi del
metadata-storage-path. Se i valori dei campi includono spazi o trattini, è necessario impostare l'opzione Chiavi di codifica Base 64 nel passaggio Crea un indicizzatore, in Opzioni avanzate, per evitare il controllo di convalida per questi caratteri.Impostare gli attributi per determinare la modalità di utilizzo di tale campo in un indice.
Dedicare tempo a questo passaggio perché gli attributi determinano l'espressione fisica dei campi nell'indice. Se si desidera modificare gli attributi in un secondo momento, anche a livello di codice, sarà quasi sempre necessario eliminare e ricompilare l'indice. Gli attributi principali, ad esempio Searchable e Retrievable, hanno un effetto trascurabile sull'archiviazione. L'abilitazione dei filtri e l'uso di suggerimenti aumentano i requisiti di archiviazione.
Ricercabile abilita la ricerca full-text. Ogni campo usato nelle query in formato libero o nelle espressioni di query deve contenere questo attributo. Per ogni campo contrassegnato come Ricercabile vengono creati indici invertiti.
Recuperabile restituisce il campo nei risultati della ricerca. Ogni campo che fornisce contenuto ai risultati della ricerca deve avere questo attributo. L'impostazione di questo campo non influisce significativamente sulle dimensioni dell'indice.
Filtrabile consente di fare riferimento al campo nelle espressioni di filtro. Ogni campo usato in un'espressione $filter deve avere questo attributo. Le espressioni di filtro sono per le corrispondenze esatte. Poiché le stringhe di testo rimangono inalterate, è necessario ulteriore spazio di archiviazione per ospitare il contenuto verbatim.
Con facet abilita il campo per l'esplorazione in base a facet. Solo i campi contrassegnati anche come Filtrabile possono essere contrassegnati come Con facet.
Ordinabile consente di usare il campo in un ordinamento. Ogni campo usato in un'espressione $Orderby deve avere questo attributo.
È necessaria un’analisi lessicale? Per i campi Edm.string Ricercabili, è possibile impostare un Analizzatore se si desidera eseguire le query e l’indicizzazione avanzata del linguaggio.
Il valore predefinito è Standard - Lucene ma è possibile scegliere Inglese - Microsoft se si vuole usare l'analizzatore Microsoft per l'elaborazione lessicale avanzata, ad esempio per la risoluzione di forme verbali o nominali irregolari. Solo gli analizzatori del linguaggio possono essere specificati nella portale di Azure. Se si usa un analizzatore personalizzato o un analizzatore non linguistico, ad esempio Keyword, Pattern e così via, è necessario crearlo a livello di codice. Per altre informazioni sugli analizzatori, vedere Aggiungere analizzatori del linguaggio.
Sono necessarie funzionalità typeahead sotto forma di completamento automatico o risultati suggeriti? Selezionare la casella di controllo Suggester per abilitare i suggerimenti di query typeahead e completamento automatico nei campi selezionati. I suggerimenti aggiungono al numero di termini con token nell'indice e quindi usano più spazio di archiviazione.
Configurazione dell'indicizzatore nella procedura guidata
L'ultima pagina della procedura guidata raccoglie gli input utente per la configurazione dell'indicizzatore. È possibile specificare una pianificazione e impostare altre opzioni che variano in base al tipo di origine dati.
Internamente, la procedura guidata imposta anche le seguenti definizioni, che non sono visibili nell'indicizzatore se non dopo la sua creazione:
- Mapping dei campi tra l'origine dati e l'indice
- Mapping dei campi di output tra l'output della competenza e un indice
Provare le procedure guidate
Il modo migliore per comprendere i vantaggi e le limitazioni della procedura guidata consiste nell'eseguirne il passaggio. Ecco alcuni argomenti di avvio rapido basati sulla procedura guidata.