Indicizzare i dati da file e collegamenti di OneLake
Questo articolo illustra come configurare un indicizzatore di file OneLake per estrarre dati e metadati ricercabili da una lakehouse su OneLake.
Per configurare ed eseguire l'indicizzatore, è possibile usare:
- API REST di anteprima 2024-05-01 o un'API REST di anteprima più recente.
- Pacchetto beta di Azure SDK che fornisce la funzionalità.
- Importazione guidata dati nel portale di Azure.
- Importare e vettorializzare i dati nella portale di Azure.
Questo articolo usa le API REST per illustrare ogni passaggio.
Prerequisiti
Un’area di lavoro Infrastruttura Seguire questa esercitazione per creare un'area di lavoro Infrastruttura.
Un lakehouse in un'area di lavoro Infrastruttura. Seguire questa esercitazione per creare un lakehouse.
Dati testuali. Se si dispone di dati binari, è possibile usare l'analisi delle immagini di arricchimento tramite intelligenza artificiale per estrarre testo o generare descrizioni delle immagini. Il contenuto del file non può superare i limiti dell'indicizzatore per il livello di servizio di ricerca.
Contenuto nella posizione File del lakehouse. È possibile aggiungere dati in base a:
- Caricare direttamente in un lakehouse
- Usare le pipeline di dati di Microsoft Fabric
- Aggiungere collegamenti da origini dati esterne, ad esempio Amazon S3 o Google Cloud Storage.
Servizio di ricerca IA configurato per un'identità gestita di sistema o un'identità gestita assegnata dall'utente. Il servizio di ricerca IA deve trovarsi nello stesso tenant dell'area di lavoro di Microsoft Fabric.
Assegnazione del ruolo di Collaboratore nell'area di lavoro di Microsoft Fabric in cui si trova il lakehouse. I passaggi sono descritti nella sezione Concedi autorizzazioni di questo articolo.
Un client REST per formulare chiamate REST analoghe a quelle illustrate in questo articolo.
Attività supportate
È possibile usare questo indicizzatore per le attività seguenti:
- Indicizzazione dei dati e indicizzazione incrementale: l'indicizzatore può indicizzare i file e i metadati associati dai percorsi dei dati all'interno di un lakehouse. Rileva i file e i metadati nuovi e aggiornati tramite il rilevamento delle modifiche predefinito. È possibile configurare l'aggiornamento dei dati in base a una pianificazione oppure su richiesta.
- Rilevamento eliminazione: l'indicizzatore può rilevare le eliminazioni tramite metadati personalizzati per la maggior parte dei file e dei collegamenti. Ciò richiede l'aggiunta di metadati ai file per indicare che sono stati "eliminati in modo soft", abilitando la rimozione dall'indice di ricerca. Attualmente non è possibile rilevare le eliminazioni nei file di collegamento di Google Cloud Storage o Amazon S3 perché i metadati personalizzati non sono supportati per tali origini dati.
- Intelligenza artificiale applicata tramite skillsets:Skillsets è completamente supportata dall'indicizzatore di file OneLake. Sono incluse funzionalità chiave come la vettorizzazione integrata che aggiunge passaggi di incorporamento e suddivisione in blocchi di dati.
- Modalità di analisi: l'indicizzatore supporta le modalità di analisi JSON se si vogliono analizzare matrici o righe JSON in singoli documenti di ricerca. Supporta anche la modalità di analisi Markdown.
- Compatibilità con altre funzionalità: l'indicizzatore OneLake è progettato per funzionare senza problemi con altre funzionalità dell'indicizzatore, ad esempio le sessioni di debug, la cache dell'indicizzatore per gli arricchimenti incrementali e l’archivio conoscenze.
Formati di documento supportati
L'indicizzatore dei file OneLake può estrarre il testo dai formati di documento seguenti:
- CSV (vedere Indicizzazione di BLOB CSV)
- EML
- EPUB
- GZ
- HTML
- JSON (vedere Indicizzazione di BLOB JSON)
- KML (XML per le rappresentazioni geografiche)
- Formati di Microsoft Office: DOCX/DOC/DOCM, XLSX/XLS/XLSM, PPTX/PPTM, MSG (messaggi di posta elettronica di Outlook), XML (sia 2003 che 2006 WORD XML)
- Formati di documento aperti: ODT, ODS, ODP
- File di testo normale (vedere anche Indicizzazione di testo normale)
- RTF
- XML
- ZIP
Collegamenti supportati
I collegamenti OneLake seguenti sono supportati dall'indicizzatore di file OneLake:
Collegamento a OneLake (collegamento a un'altra istanza di OneLake)
Limitazioni in questa anteprima
I tipi di file Parquet (inclusi i delta parquet) non sono attualmente supportati.
L'eliminazione di file non è supportata per i collegamenti ad Amazon S3 e Google Cloud Storage.
Questo indicizzatore non supporta il contenuto della posizione tabella dell'area di lavoro OneLake.
Questo indicizzatore non supporta le query SQL, ma la query usata nella configurazione dell'origine dati è esclusivamente quella di aggiungere facoltativamente la cartella o il collegamento per accedere.
Non è disponibile alcun supporto per l'inserimento di file dall'area di lavoro My Workspace in OneLake perché si tratta di un repository personale per utente.
Preparare i dati per l'indicizzazione
Prima di configurare l'indicizzazione, esaminare i dati di origine per stabilire se devono essere apportate in anticipo eventuali modifiche. Un indicizzatore può indicizzare il contenuto da un contenitore alla volta. Per impostazione predefinita, tutti i file nel contenitore vengono elaborati. Sono disponibili diverse opzioni per un'elaborazione più selettiva:
Inserire i file in una cartella virtuale. Una definizione di origine dati dell'indicizzatore include un parametro "query" che può essere una sottocartella lakehouse oppure un collegamento. Se tale valore viene specificato, vengono indicizzati solo i file nella sottocartella o il collegamento all'interno del lakehouse.
Includere o escludere file in base al tipo di file. L'elenco dei formati di documento supportati consente di determinare quali file vanno esclusi. Ad esempio, è possibile escludere file immagine o audio che non forniscono testo ricercabile. Questa funzionalità viene controllata tramite le impostazioni di configurazione nell'indicizzatore.
Includere o escludere file arbitrari. Se per un qualsiasi motivo si vuole ignorare un file specifico, è possibile aggiungere proprietà e valori di metadati ai file nel lakehouse di OneLake. Quando un indicizzatore rileva tale proprietà, ignora il file o il relativo contenuto nell'esecuzione dell'indicizzazione.
L'inclusione e l'esclusione dei file sono descritte nel passaggio di configurazione dell'indicizzatore. Se non si impostano criteri, l'indicizzatore segnala un file non idoneo come errore e prosegue. Se si verificano abbastanza errori, l'elaborazione potrebbe interrompersi. È possibile specificare la tolleranza di errore nelle impostazioni di configurazione dell'indicizzatore.
Un indicizzatore crea in genere un documento di ricerca per ogni file, in cui il contenuto di testo e i metadati vengono acquisiti come campi ricercabili all’interno di un indice. Se i file sono interi, è possibile analizzarli in più documenti di ricerca. Ad esempio, è possibile analizzare le righe in un file CSV per creare un documento di ricerca per ciascuna riga. Se è necessario suddividere un singolo documento in passaggi più piccoli per vettorizzare i dati, è consigliabile usare la vettorizzazione integrata.
Indicizzazione dei metadati dei file
Anche i metadati dei file possono essere indicizzati e questa è un’operazione utile se si ritiene che una delle proprietà dei metadati standard o personalizzate possa risultare vantaggiosa nei filtri e nelle query.
Le proprietà dei metadati specificate dall'utente vengono estratte letteralmente. Per ricevere i valori, è necessario definire il campo nell'indice di ricerca di tipo Edm.String, con lo stesso nome della chiave di metadati del BLOB. Ad esempio, se un BLOB ha una chiave di metadati di Priority con valore High, è necessario definire un campo denominato Priority nell'indice di ricerca, che verrà popolato con il valore High.
Le proprietà dei metadati dei file standard possono essere estratte in campi denominati e tipizzati in modo analogo, come indicato di seguito. L'indicizzatore di file OneLake crea automaticamente mapping di campi interni per queste proprietà di metadati, convertendo il nome sillabato originale ("metadata-storage-name") in un nome equivalente con caratteri underscore ("metadata_storage_name").
È comunque necessario aggiungere i campi con caratteri underscore alla definizione dell'indice, ma è possibile omettere i mapping dei campi dell'indicizzatore perché l'indicizzatore fa l'associazione in modo automatico.
metadata_storage_name (
Edm.String): nome del file. Se, ad esempio, è presente un file/mydatalake/my-folder/subfolder/resume.pdf, il valore di questo campo èresume.pdf.metadata_storage_path (
Edm.String): URI completo del BLOB, incluso l'account di archiviazione. Ad esempio,https://myaccount.blob.core.windows.net/my-container/my-folder/subfolder/resume.pdfmetadata_storage_content_type (
Edm.String): tipo di contenuto specificato dal codice utilizzato per caricare il BLOB. Ad esempio:application/octet-stream.metadata_storage_last_modified (
Edm.DateTimeOffset): timestamp dell'ultima modifica per il BLOB. Azure AI Search usa questo timestamp per identificare i BLOB modificati, in modo da evitare di reindicizzare tutto dopo l'indicizzazione iniziale.metadata_storage_size (
Edm.Int64): dimensioni del BLOB in byte.metadata_storage_content_md5 (
Edm.String): hash MD5 del contenuto del BLOB, se disponibile.
Infine, tutte le proprietà dei metadati specifiche del formato documento dei file indicizzati possono essere rappresentate anche nello schema dell'indice. Per altre informazioni sui metadati specifici del contenuto, vedere Proprietà dei metadati del contenuto.
È importante sottolineare che non è necessario definire i campi per tutte le proprietà precedenti nell'indice di ricerca, ma solo acquisire le proprietà necessarie per l'applicazione.
Concedere le autorizzazioni
L'indicizzatore OneLake usa l'autenticazione dei token e l'accesso basato sui ruoli per le connessioni a OneLake. Le autorizzazioni vengono assegnate in OneLake. Non sono previsti requisiti di autorizzazione per gli archivi dati fisici che eseguono il backup dei collegamenti. Ad esempio, se si esegue l'indicizzazione da AWS, non è necessario concedere le autorizzazioni del servizio di ricerca in AWS.
L'assegnazione di ruolo minima per l'identità del servizio di ricerca è Collaboratore.
Configurare un'identità gestita dal sistema o dall'utente per il servizio di ricerca IA.
Lo screenshot seguente mostra un'identità gestita dal sistema per un servizio di ricerca denominato "onelake-demo".
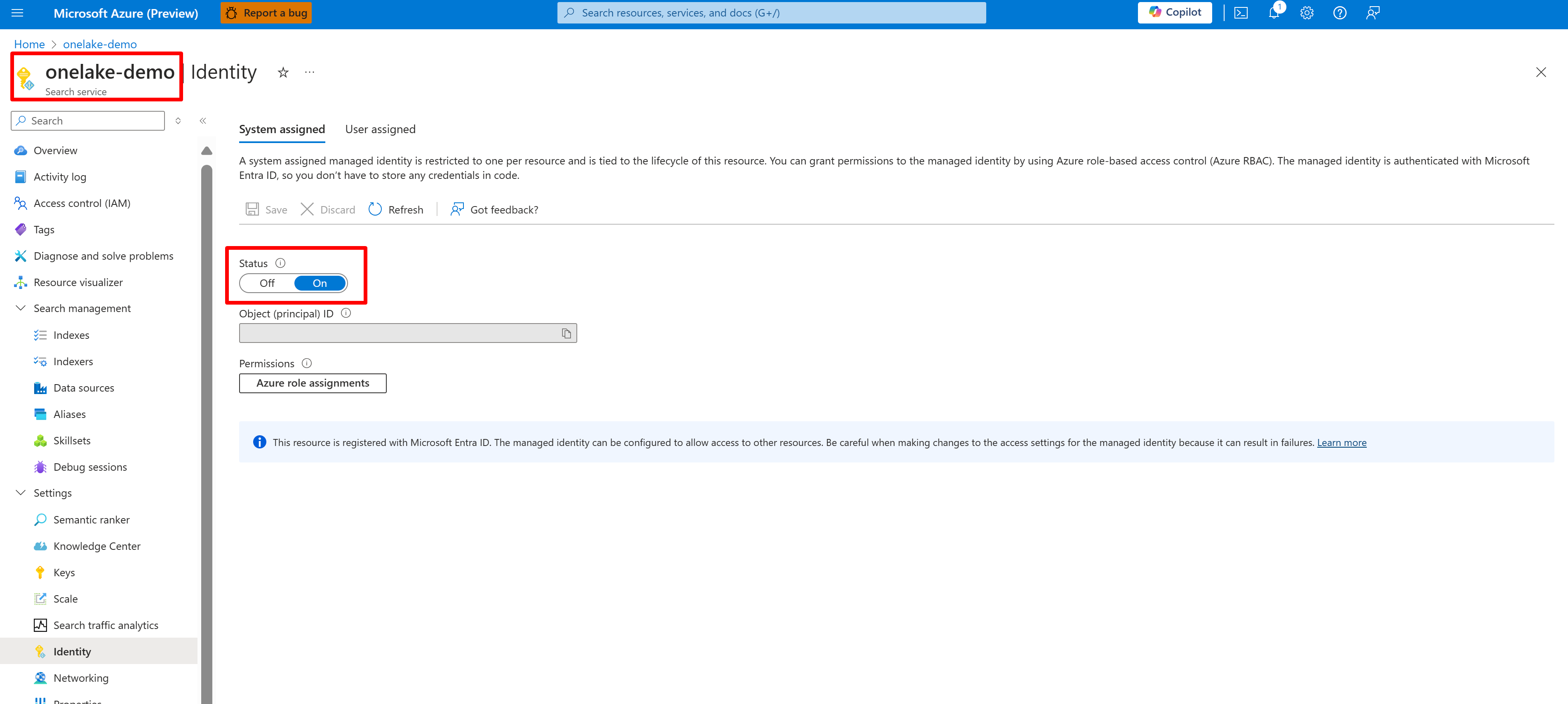
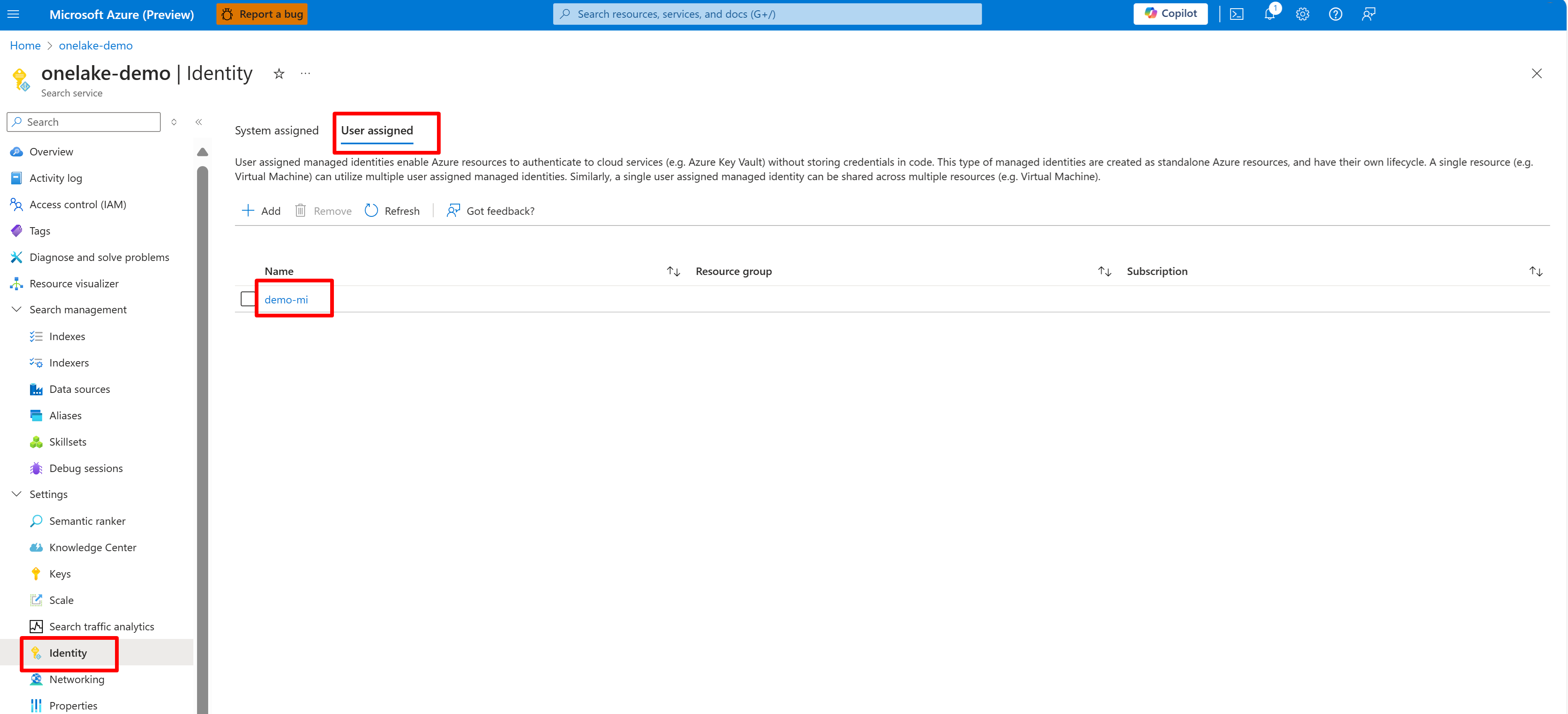
Questo screenshot mostra un'identità gestita dall'utente per lo stesso servizio di ricerca.
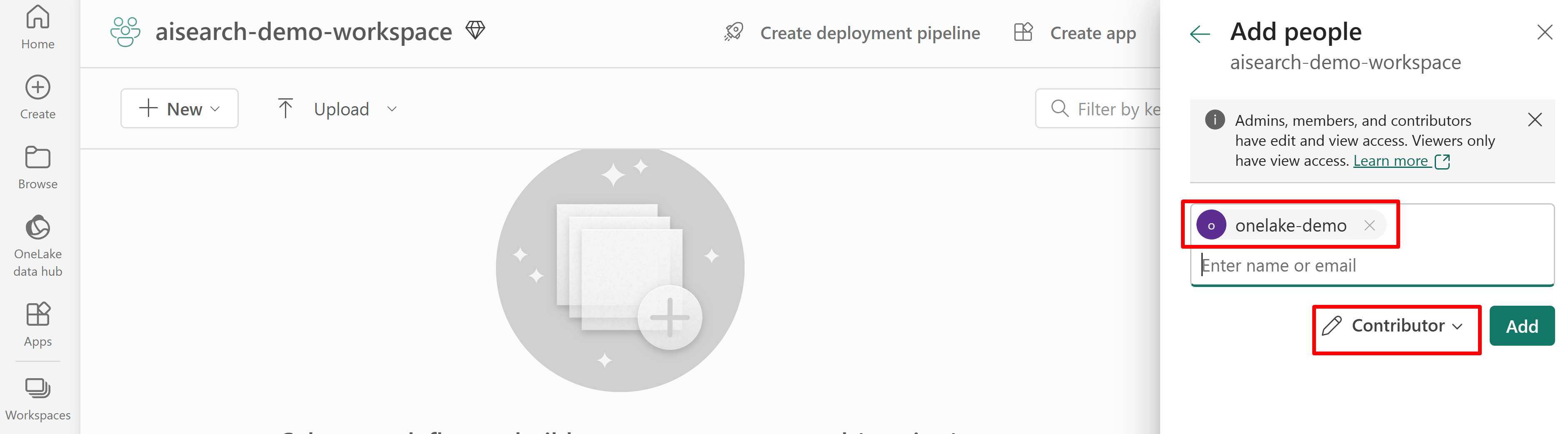
Concedere l'autorizzazione per l'accesso al servizio di ricerca all'area di lavoro Infrastruttura. Il servizio di ricerca effettua la connessione per conto dell'indicizzatore.
Se si usa un'identità gestita assegnata dal sistema, cercare il nome del servizio di ricerca IA. Per un'identità gestita assegnata dall'utente, cercare il nome della risorsa identità.
Lo screenshot seguente mostra un'assegnazione di ruolo Collaboratore usando un'identità gestita dal sistema.
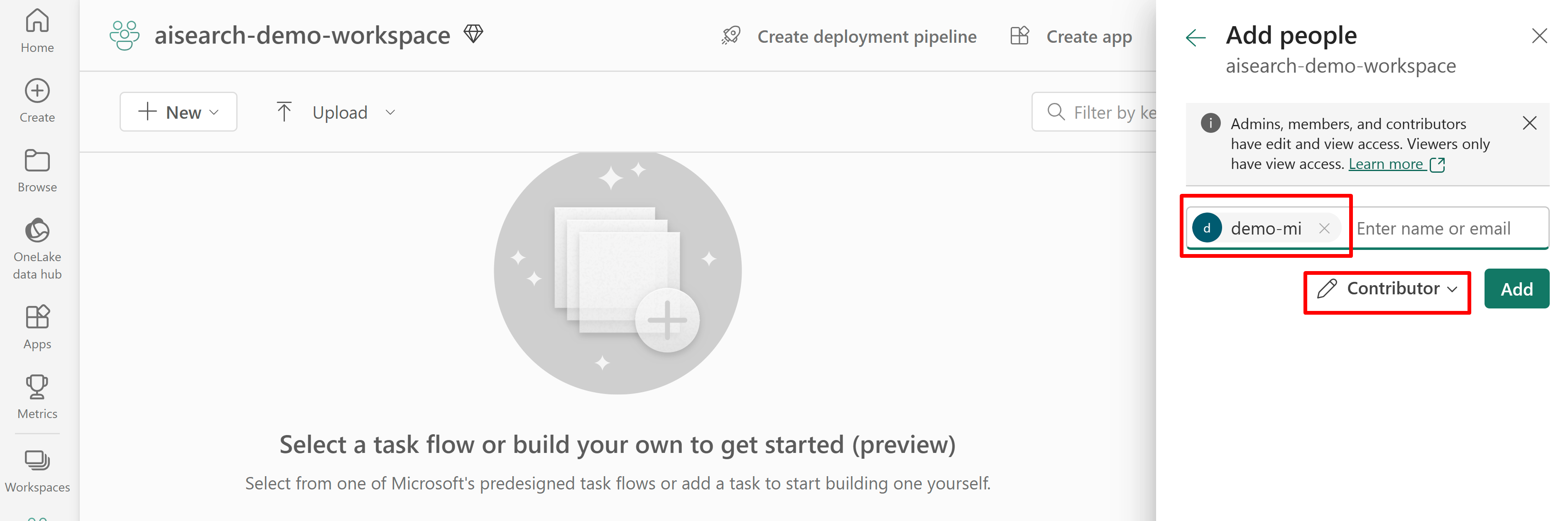
Questo screenshot mostra un'assegnazione di ruolo Collaboratore usando un'identità gestita assegnata dall'utente:




Definire l'origine dati
Un’origine dati è definita come risorsa indipendente affinché possa essere usata da più indicizzatori. Per creare l'origine dati è necessario usare l'API REST 2024-05-01-preview.
Usare l'API REST Crea o aggiorna un'origine dati per impostarne la definizione. Questi sono i passaggi più significativi della definizione.
Impostare
"type"su"onelake"(obbligatorio).Ottenere il GUID dell'area di lavoro di Microsoft Fabric e il GUID del lakehouse:
Andare all’URL del lakehouse dal quale si vuole importare i dati. Dovrebbe avere un aspetto simile a questo esempio: "https://msit.powerbi.com/groups/00000000-0000-0000-0000-000000000000/lakehouses/11111111-1111-1111-1111-111111111111?experience=power-bi". Copiare i valori seguenti che vengono utilizzati nella definizione dell'origine dati:
Copiare il GUID dell'area di lavoro, che chiameremo
{FabricWorkspaceGuid}, che viene elencato subito dopo "gruppi" nell'URL. In questo esempio, è 00000000-0000-0000-0000-000000000000.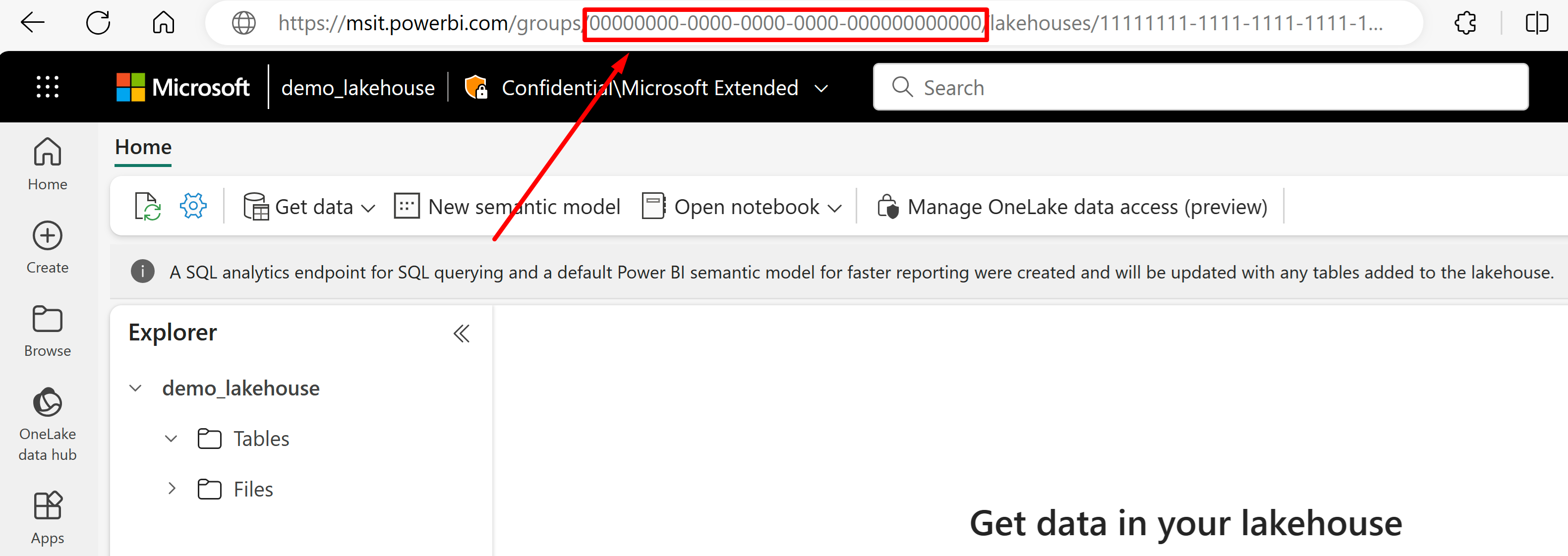
Copiare il GUID del lakehouse, che chiameremo
{lakehouseGuid}, che è elencato subito dopo "lakehouses" nell'URL. In questo esempio, è 11111111-1111-1111-1111-111111111111.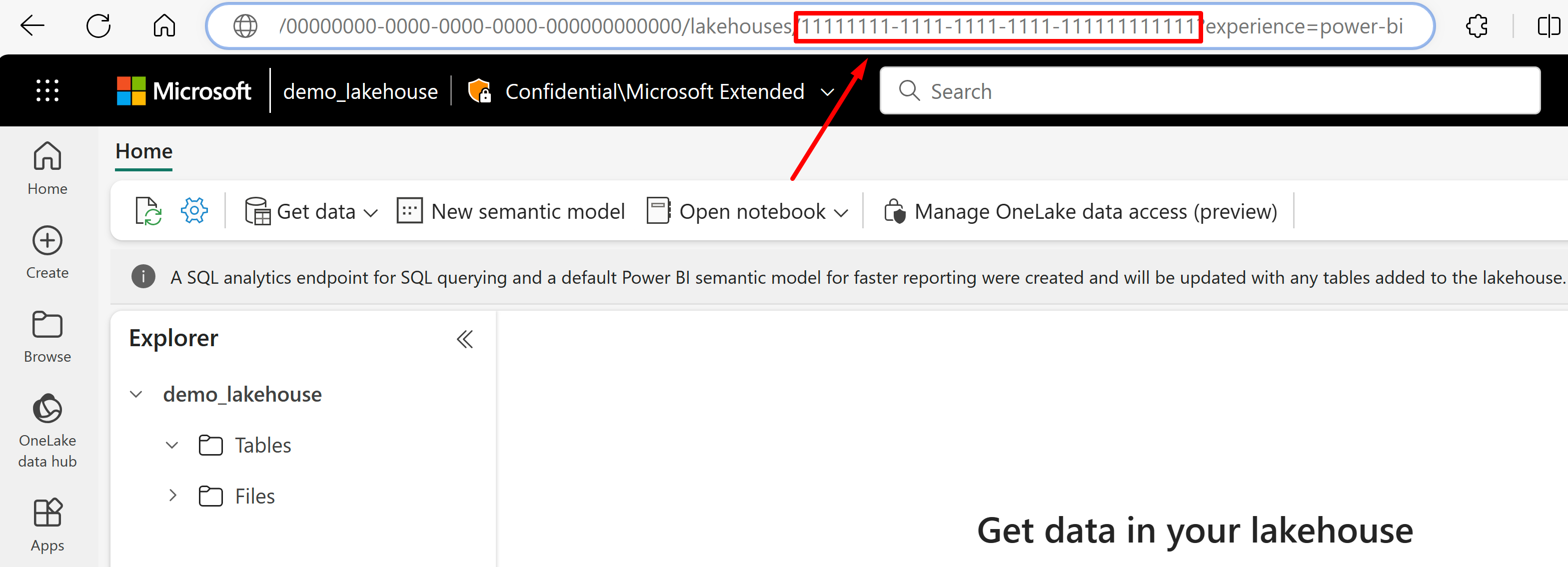
Impostare
"credentials"sul GUID dell'area di lavoro di Microsoft Fabric sostituendo{FabricWorkspaceGuid}con il valore copiato nel passaggio precedente. Si tratta del OneLake per accedere all'identità gestita che verrà configurata più avanti in questa guida."credentials": { "connectionString": "ResourceId={FabricWorkspaceGuid}" }Impostare
"container.name"sul GUID del lakehouse, sostituendo{lakehouseGuid}con il valore copiato nel passaggio precedente. Usare"query"per specificare facoltativamente una sottocartella o un collegamento lakehouse."container": { "name": "{lakehouseGuid}", "query": "{optionalLakehouseFolderOrShortcut}" }Impostare il metodo di autenticazione usando l'identità gestita assegnata dall'utente oppure andare al passaggio successivo per l'identità gestita dal sistema.
{ "name": "{dataSourceName}", "description": "description", "type": "onelake", "credentials": { "connectionString": "ResourceId={FabricWorkspaceGuid}" }, "container": { "name": "{lakehouseGuid}", "query": "{optionalLakehouseFolderOrShortcut}" }, "identity": { "@odata.type": "Microsoft.Azure.Search.DataUserAssignedIdentity", "userAssignedIdentity": "{userAssignedManagedIdentity}" } }Il valore
userAssignedIdentityè reperibile accedendo alla risorsa{userAssignedManagedIdentity}, in Proprietà, ed è denominatoId.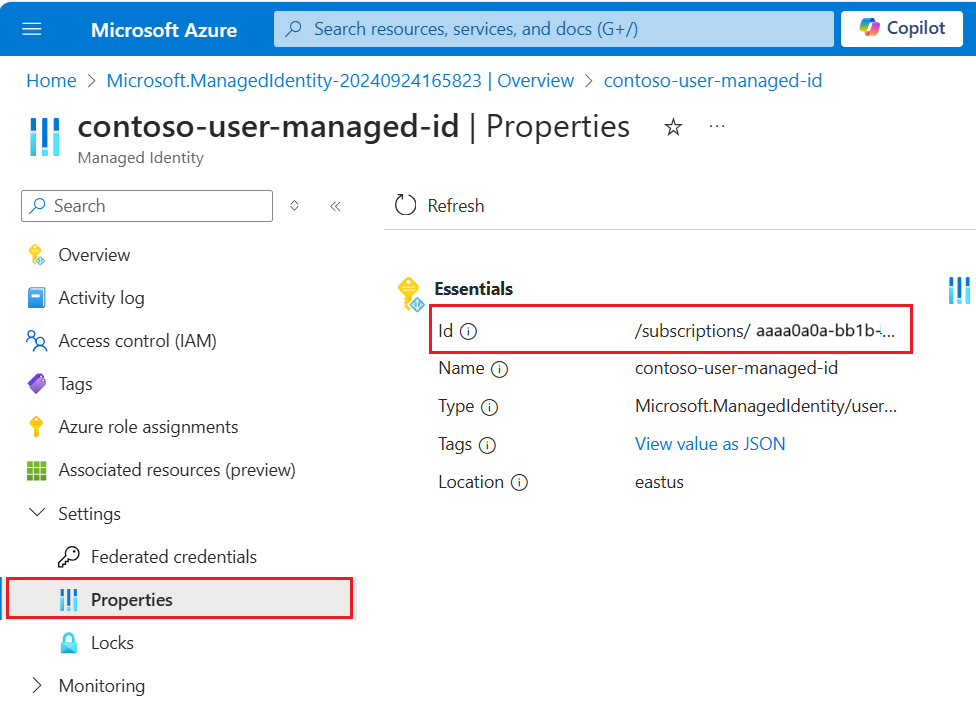
Esempio:
{ "name": "mydatasource", "description": "description", "type": "onelake", "credentials": { "connectionString": "ResourceId=a0a0a0a0-bbbb-cccc-dddd-e1e1e1e1e1e1" }, "container": { "name": "11111111-1111-1111-1111-111111111111", "query": "folder_name" }, "identity": { "@odata.type": "Microsoft.Azure.Search.DataUserAssignedIdentity", "userAssignedIdentity": "/subscriptions/333333-3333-3333-3333-33333333/resourcegroups/myresourcegroup/providers/Microsoft.ManagedIdentity/userAssignedIdentities/demo-mi" } }Facoltativamente, usare al suo posto un'identità gestita assegnata dal sistema. L'“identità” viene rimossa dalla definizione se si usa l'identità gestita assegnata dal sistema.
{ "name": "{dataSourceName}", "description": "description", "type": "onelake", "credentials": { "connectionString": "ResourceId={FabricWorkspaceGuid}" }, "container": { "name": "{lakehouseGuid}", "query": "{optionalLakehouseFolderOrShortcut}" } }Esempio:
{ "name": "mydatasource", "description": "description", "type": "onelake", "credentials": { "connectionString": "ResourceId=a0a0a0a0-bbbb-cccc-dddd-e1e1e1e1e1e1" }, "container": { "name": "11111111-1111-1111-1111-111111111111", "query": "folder_name" } }



Rilevare le eliminazioni tramite i metadati personalizzati
La definizione dell'origine dati dell'indicizzatore di file OneLake può includere criteri di eliminazione temporanea nel caso si desideri che l'indicizzatore elimini un documento di ricerca quando il documento di origine viene contrassegnato come da eliminare.
Per abilitare l'eliminazione automatica dei file, usare i metadati personalizzati per indicare se un documento di ricerca deve essere rimosso dall'indice.
Il flusso di lavoro richiede tre azioni separate:
- "Eliminazione temporanea" del file in OneLake
- L'indicizzatore elimina il documento di ricerca nell'indice
- "Eliminazione definitiva" del file in OneLake
"Eliminazione temporanea" indica all'indicizzatore cosa fare (eliminare il documento di ricerca). Se si elimina prima il file fisico in OneLake, l'indicizzatore non potrà leggere nulla e il documento di ricerca corrispondente nell'indice rimarrà orfano.
Esistono passaggi da seguire sia in OneLake che in Azure AI Search, ma non esistono altre dipendenze dalle funzionalità.
Nel file lakehouse aggiungere una coppia chiave-valore di metadati personalizzata al file a indicare che il file è contrassegnato per l'eliminazione. Ad esempio, è possibile denominare la proprietà "IsDeleted" impostata su false. Quando si desidera eliminare il file, modificarlo in true.
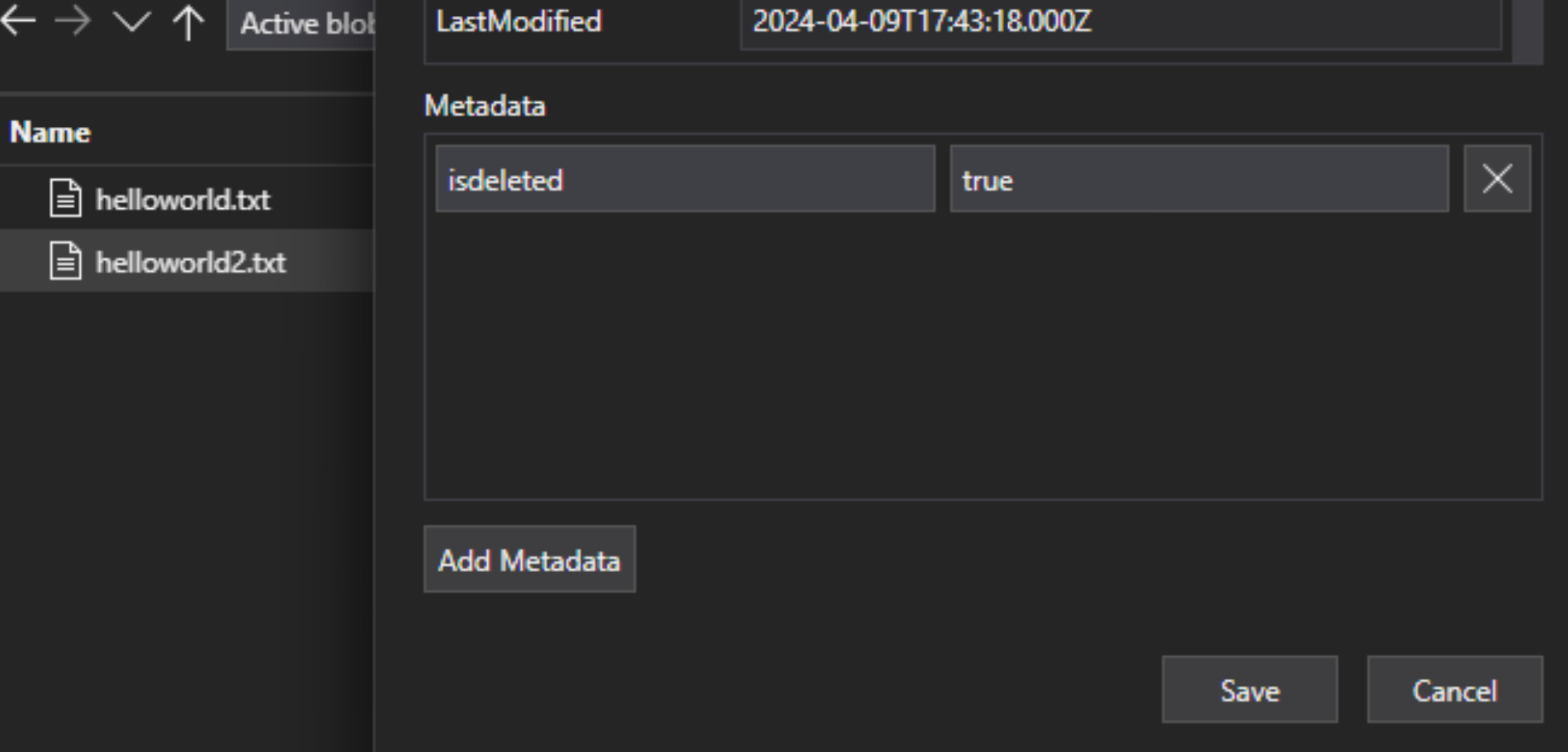
In Azure AI Search modificare la definizione dell'origine dati per includere una proprietà "dataDeletionDetectionPolicy". Il criterio illustrato sotto, ad esempio, considera l'eliminazione di un file se ha una proprietà di metadati "IsDeleted" con il valore true:
PUT https://[service name].search.windows.net/datasources/file-datasource?api-version=2024-05-01-preview { "name" : "onelake-datasource", "type" : "onelake", "credentials": { "connectionString": "ResourceId={FabricWorkspaceGuid}" }, "container": { "name": "{lakehouseGuid}", "query": "{optionalLakehouseFolderOrShortcut}" }, "dataDeletionDetectionPolicy" : { "@odata.type" :"#Microsoft.Azure.Search.SoftDeleteColumnDeletionDetectionPolicy", "softDeleteColumnName" : "IsDeleted", "softDeleteMarkerValue" : "true" } }

Dopo l'esecuzione dell'indicizzatore e l'eliminazione del documento dall'indice di ricerca, è possibile eliminare il file fisico nel data lake.
Alcuni punti chiave includono:
La pianificazione di un'esecuzione dell'indicizzatore consente di automatizzare questo processo. È consigliabile pianificare tutti gli scenari di indicizzazione incrementale.
Se i criteri di rilevamento dell'eliminazione non sono stati impostati nella prima esecuzione dell'indicizzatore, è necessario reimpostare l'indicizzatore in modo che sia in grado di leggere la configurazione aggiornata.
Tenere presente che il rilevamento dell'eliminazione non è supportato per i collegamenti ad Amazon S3 e Google Cloud Storage a causa della dipendenza dai metadati personalizzati.
Aggiungere campi di ricerca a un indice
In un indice di ricerca aggiungere campi per accettare il contenuto e i metadati dei file data lake di OneLake.
Creare o aggiornare un indice per definire i campi di ricerca che conservano il contenuto e i metadati dei file:
{ "name" : "my-search-index", "fields": [ { "name": "ID", "type": "Edm.String", "key": true, "searchable": false }, { "name": "content", "type": "Edm.String", "searchable": true, "filterable": false }, { "name": "metadata_storage_name", "type": "Edm.String", "searchable": false, "filterable": true, "sortable": true }, { "name": "metadata_storage_size", "type": "Edm.Int64", "searchable": false, "filterable": true, "sortable": true }, { "name": "metadata_storage_content_type", "type": "Edm.String", "searchable": false, "filterable": true, "sortable": true } ] }Creare un campo chiave documento ("chiave": true). Per il contenuto dei file, i candidati migliori sono le proprietà dei metadati.
metadata_storage_path(impostazione predefinita) percorso completo dell'oggetto o del file. Il campo chiave ("ID" in questo esempio) viene popolato con valori di metadata_storage_path perché è l'impostazione predefinita.metadata_storage_name, utilizzabile solo se i nomi sono univoci. Se si vuole usare questo campo come chiave, trasferire"key": truea questa definizione di campo.Proprietà dei metadati personalizzata aggiunta ai file. Questa opzione richiede che il processo di caricamento dei file aggiunga la proprietà dei metadati a tutti i BLOB. Poiché la chiave è una proprietà obbligatoria, tutti i file che mancano di un valore non possono essere indicizzati. Se si usa una proprietà di metadati personalizzata come chiave, evitare di apportare modifiche a tale proprietà. Gli indicizzatori aggiungono documenti duplicati per lo stesso file se la proprietà della chiave viene modificata.
Le proprietà dei metadati includono spesso caratteri, ad esempio
/e-, non validi per le chiavi del documento. Essendo dotato di una proprietà "base64EncodeKeys" (true per impostazione predefinita), l’indicizzatore codifica automaticamente la proprietà dei metadati, senza che sia richiesta alcuna configurazione o mapping dei campi.Aggiungere un campo "content" per archiviare il testo estratto da ogni file tramite la proprietà "content" del file. Non è necessario usare questo nome, ma in questo modo è possibile sfruttare i mapping dei campi impliciti.
Aggiungere campi per le proprietà dei metadati standard. L'indicizzatore può leggere le proprietà dei metadati personalizzate, le proprietà dei metadati standard e le proprietà dei metadati specifiche del contenuto.
Configurare ed eseguire l'indicizzatore di file OneLake
Una volta creato l'indice e l'origine dati, è possibile creare l'indicizzatore: La configurazione dell'indicizzatore specifica gli input, i parametri e le proprietà che controllano i comportamenti della fase di esecuzione. È inoltre possibile specificare le parti di un BLOB da indicizzare.
Creare o aggiornare l'indicizzatore assegnandogli un nome e il riferimento all’origine dati e all'indice di destinazione:
{ "name" : "my-onelake-indexer", "dataSourceName" : "my-onelake-datasource", "targetIndexName" : "my-search-index", "parameters": { "batchSize": null, "maxFailedItems": null, "maxFailedItemsPerBatch": null, "base64EncodeKeys": null, "configuration": { "indexedFileNameExtensions" : ".pdf,.docx", "excludedFileNameExtensions" : ".png,.jpeg", "dataToExtract": "contentAndMetadata", "parsingMode": "default" } }, "schedule" : { }, "fieldMappings" : [ ] }Impostare "batchSize" se il valore predefinito (10 documenti) è sottoutilizzato o sovraccarica le risorse disponibili. Le dimensioni batch predefinite sono specifiche dell'origine dati. L’indicizzazione dei file limita le dimensioni dei batch a 10 documenti in considerazione delle dimensioni medie superiori dei documenti.
In "configurazione", controllare quali file vengono indicizzati in base al tipo di file oppure lasciare non specificato per recuperare tutti i file.
Per
"indexedFileNameExtensions", specificare un elenco di estensioni di file delimitato da virgole (precedute da un punto). Eseguire la stessa operazione per"excludedFileNameExtensions"a indicare quali estensioni devono essere ignorate. Se la stessa estensione si trova in entrambi gli elenchi, questa viene esclusa dall'indicizzazione.In "configurazione", impostare "dataToExtract" per controllare quali parti dei file sono indicizzate:
"contentAndMetadata" è l'impostazione predefinita. Specifica che vengono indicizzati tutti i metadati e il contenuto di testo estratti dal file.
"storageMetadata" specifica che vengono indicizzati solo i metadati specificati dall'utente e le proprietà BLOB standard. Anche se le proprietà sono documentate per i BLOB di Azure, le proprietà del file sono uguali per OneLake, ad eccezione dei metadati correlati alla firma di accesso condiviso.
"allMetadata" specifica che le proprietà dei file standard e i metadati per i tipi di contenuto trovati vengono estratti dal contenuto del file e indicizzati.
In "configurazione", impostare "parsingMode" se i file devono essere mappati a più documenti di ricerca o se sono costituiti da file di testo normale, documenti JSON o CSV.
Specificare i mapping dei campi se sono presenti differenze nel nome o nel tipo di campo oppure se sono necessarie più versioni di un campo di origine nell'indice di ricerca.
Nell'indicizzazione dei file è spesso possibile omettere i mapping dei campi perché l'indicizzatore dispone del supporto predefinito per il mapping delle proprietà dei metadati e del "contenuto" ai campi denominati e tipizzati in modo analogo in un indice. Per le proprietà dei metadati, l'indicizzatore sostituisce automaticamente i trattini
-con caratteri underscore nell'indice di ricerca.
Per ulteriori informazioni sulle altre proprietà, vedere Creare un indicizzatore. Per l'elenco completo delle descrizioni dei parametri, vedere Creare un indicizzatore (REST) nell’API REST. I parametri sono gli stessi di OneLake.
Per impostazione predefinita, un indicizzatore viene eseguito automaticamente nel momento della sua creazione. È possibile modificare tale comportamento impostando "disattivato" su true. Per controllare l'esecuzione dell'indicizzatore, eseguire un indicizzatore su richiesta o inserirlo in una pianificazione.
Controllare lo stato dell'indicizzatore
Informazioni sui diversi approcci per monitorare lo stato dell'indicizzatore e la cronologia di esecuzione sono disponibili qui.
Gestione degli errori
Gli errori che si verificano in genere durante l'indicizzazione includono tipi di contenuto non supportati, contenuto mancante o file sovradimensionati. Per impostazione predefinita, l'indicizzatore di file OneLake si arresta non appena rileva un file con un tipo di contenuto non supportato. Tuttavia, potrebbe essere necessario procedere con l'indicizzazione anche se si verificano errori e quindi eseguire il debug di singoli documenti in un secondo momento.
Gli errori temporanei sono comuni per le soluzioni che coinvolgono più piattaforme e prodotti. Tuttavia, se si mantiene l'esecuzione dell’indicizzatore all’interno di una pianificazione (ad esempio ogni 5 minuti), l'indicizzatore deve essere in grado di eseguire il ripristino da tali errori nell'esecuzione successiva.
Esistono cinque proprietà dell'indicizzatore che controllano la risposta dell'indicizzatore quando si verificano errori.
{
"parameters" : {
"maxFailedItems" : 10,
"maxFailedItemsPerBatch" : 10,
"configuration" : {
"failOnUnsupportedContentType" : false,
"failOnUnprocessableDocument" : false,
"indexStorageMetadataOnlyForOversizedDocuments": false
}
}
}
| Parametro | Valori validi | Descrizione |
|---|---|---|
| "maxFailedItems" | -1, null o 0, numero intero positivo | Continuare l'indicizzazione se si verificano errori in qualsiasi momento dell'elaborazione, durante l'analisi dei BLOB o durante l'aggiunta di documenti a un indice. Impostare queste proprietà sul numero di errori accettabili. Un valore -1 consente l'elaborazione indipendentemente dal numero di errori che si verificano. Altrimenti, il valore è un numero intero positivo. |
| "maxFailedItemsPerBatch" | -1, null o 0, numero intero positivo | Come sopra, ma usato per l'indicizzazione batch. |
| "failOnUnsupportedContentType" | true o false | Se l'indicizzatore non è in grado di determinare il tipo di contenuto, specificare se continuare o non eseguire il processo. |
| "failOnUnprocessableDocument" | true o false | Se l'indicizzatore non è in grado di elaborare un documento con un tipo di contenuto altrimenti supportato, specificare se continuare o non eseguire il processo. |
| "indexStorageMetadataOnlyForOversizedDocuments" | true o false | I BLOB sovradimensionati vengono gestiti come errori per impostazione predefinita. Se si imposta questo parametro su true, l'indicizzatore tenta di indicizzare i metadati anche se il contenuto non può essere indicizzato. Per informazioni sulle limitazione delle dimensioni dei BLOB, vedere Limiti del servizio. |
Passaggi successivi
Verificare il funzionamento della procedura guidata Importare e vettorializzare i dati e provarla per questo indicizzatore. È possibile usare la vettorizzazione integrata per effettuare la suddivisione in blocchi e creare embedding per la ricerca vettoriale o ibrida usando uno schema predefinito.