Che cos'è DLT?
Nota
DLT richiede il piano Premium . Contatta il tuo team dell'account Databricks per ulteriori informazioni.
DLT è un framework dichiarativo progettato per semplificare la creazione di pipeline di estrazione, trasformazione e caricamento affidabili e gestibili. Si specificano i dati da inserire e come trasformarli e DLT automatizza gli aspetti chiave della gestione della pipeline di dati, tra cui orchestrazione, gestione del calcolo, monitoraggio, applicazione della qualità dei dati e gestione degli errori.
DLT è basato su Apache Spark, ma invece di definire le pipeline di dati usando una serie di attività Apache Spark separate, si definiscono tabelle di streaming e viste materializzate che il sistema deve creare e le query necessarie per popolare e aggiornare tali tabelle di streaming e viste materializzate.
Per altre informazioni sui vantaggi della creazione e dell'esecuzione delle pipeline ETL con DLT, vedere la pagina del prodotto DLT.
vantaggi di DLT rispetto ad Apache Spark
Apache Spark è un motore di analisi unificata open source versatile, incluso ETL. DLT si basa su Spark per gestire attività di elaborazione ETL specifiche e comuni. DLT può accelerare significativamente il percorso di produzione quando i requisiti includono queste attività di elaborazione, tra cui:
- Acquisizione di dati da fonti tipiche.
- Trasformazione incrementale dei dati.
- Esecuzione di Change Data Capture (CDC).
Tuttavia, DLT non è adatto per l'implementazione di alcuni tipi di logica procedurale. Ad esempio, i requisiti di elaborazione, ad esempio la scrittura in una tabella esterna o l'inclusione di un'istruzione condizionale che opera su archiviazione file esterna o tabelle di database, non possono essere eseguiti all'interno del codice che definisce un set di dati DLT. Per implementare l'elaborazione non supportata da DLT, Databricks consiglia di usare Apache Spark o includere la pipeline in un processo di Databricks che esegue l'elaborazione in un'attività di processo separata. Vedere attività della pipeline DLT per i processi.
La tabella seguente confronta DLT con Apache Spark:
| Capacità | DLT | Apache Spark |
|---|---|---|
| Trasformazioni dei dati | È possibile trasformare i dati usando SQL o Python. | È possibile trasformare i dati usando SQL, Python, Scala o R. |
| Elaborazione incrementale dei dati | Molte trasformazioni dei dati vengono elaborate automaticamente in modo incrementale. | È necessario determinare quali dati sono nuovi in modo da poterli elaborare in modo incrementale. |
| Orchestrazione | Le trasformazioni vengono orchestrate automaticamente nell'ordine corretto. | È necessario assicurarsi che le diverse trasformazioni vengano eseguite nell'ordine corretto. |
| Parallelismo | Tutte le trasformazioni vengono eseguite con il livello di parallelismo corretto. | È necessario usare thread o un agente di orchestrazione esterno per eseguire trasformazioni non correlate in parallelo. |
| Gestione degli errori | Gli errori vengono ritentati automaticamente. | È necessario decidere come gestire gli errori e i tentativi. |
| Monitoraggio | Le metriche e gli eventi vengono registrati automaticamente. | È necessario scrivere codice per raccogliere le metriche relative all'esecuzione o alla qualità dei dati. |
concetti chiave di DLT
La figura seguente illustra i componenti importanti di una pipeline DLT, seguita da una spiegazione di ognuna.
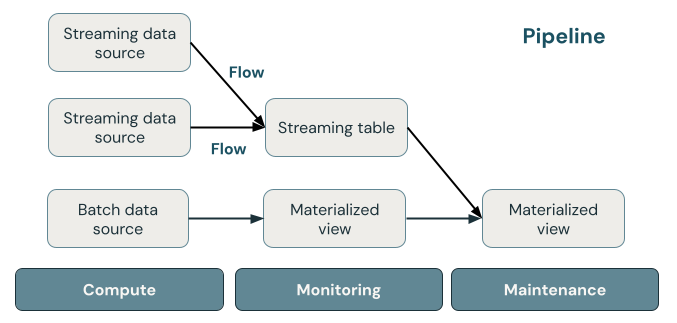
tabella di streaming
Una tabella di streaming è una tabella Delta con uno o più flussi che scrivono in esso. Le tabelle di streaming vengono comunemente usate per l'inserimento perché elaborano i dati di input esattamente una volta e possono elaborare grandi volumi di dati che possono solo essere aggiunti. Le tabelle di streaming sono utili anche per la trasformazione a bassa latenza di flussi di dati con volumi elevati.
Vista materializzata
Una vista materializzata è una vista che contiene dati precomputati in base alla query che la definisce. I record nella vista materializzata vengono mantenuti automaticamente aggiornati da DLT in base alla programmazione degli aggiornamenti o ai trigger della pipeline. Ogni volta che viene aggiornata una vista materializzata, è garantito che abbiano gli stessi risultati dell'esecuzione della query di definizione sui dati più recenti disponibili. Tuttavia, questa operazione viene spesso eseguita senza ricompilare il risultato completo da zero, usando aggiornamento incrementale. Le viste materializzate vengono comunemente usate per le trasformazioni.
Visualizzazioni
Tutte le visualizzazioni nei risultati di calcolo di Azure Databricks provengono dai set di dati di origine, sfruttando le ottimizzazioni della memorizzazione nella cache quando disponibili. DLT non pubblica le viste nel catalogo, quindi è possibile fare riferimento alle viste solo nella pipeline in cui sono definite. Le viste sono utili come query intermedie che non devono essere esposte a utenti o sistemi finali. Databricks consiglia di usare le viste per applicare vincoli di qualità dei dati o trasformare e arricchire i set di dati che determinano più query downstream.
Oleodotto
Una pipeline è una raccolta di tabelle di streaming e viste materializzate aggiornate insieme. Queste tabelle di streaming e le viste materializzate vengono dichiarate nei file di origine Python o SQL. Una pipeline include anche una configurazione che definisce il calcolo usato per aggiornare le tabelle di streaming e le viste materializzate durante l'esecuzione della pipeline. Analogamente al modo in cui un modello Terraform definisce l'infrastruttura nell'account cloud, una pipeline DLT definisce i set di dati e le trasformazioni per l'elaborazione dei dati.
Come i set di dati DLT elaborano i dati?
Nella tabella seguente viene descritto il modo in cui le viste materializzate, le tabelle di streaming e le viste elaborano i dati:
| Tipo di set di dati | Come vengono elaborati i record tramite query definite? |
|---|---|
| Tabella di streaming | Ogni record viene elaborato esattamente una volta. Si presuppone un'origine di sola appensione. |
| Vista materializzata | I record vengono elaborati in base alle esigenze per restituire risultati accurati per lo stato dei dati corrente. Le viste materializzate devono essere usate per le attività di elaborazione dei dati, ad esempio trasformazioni, aggregazioni o pre-elaborazione di query lente e calcoli usati di frequente. |
| Visualizza | I record vengono elaborati ogni volta che la vista viene interrogata. Usare le viste per trasformazioni intermedie e controlli di qualità dei dati che non devono essere pubblicati nei set di dati pubblici. |
Dichiarare i primi set di dati in DLT
DLT introduce una nuova sintassi per Python e SQL. Per informazioni sulle nozioni di base della sintassi della pipeline, vedere Sviluppare codice della pipeline con Python e Sviluppare codice della pipeline con SQL.
Nota
DLT separa le definizioni dei set di dati dall'elaborazione degli aggiornamenti e i notebook DLT non sono destinati all'esecuzione interattiva.
Come si configurano le pipeline DLT?
Le impostazioni per le pipeline DLT rientrano in due categorie generali:
- Configurazioni che definiscono una raccolta di notebook o file (noti come codice sorgente) che usano la sintassi DLT per dichiarare i set di dati.
- Configurazioni che controllano l'infrastruttura della pipeline, la gestione delle dipendenze, la modalità di elaborazione degli aggiornamenti e la modalità di salvataggio delle tabelle nell'area di lavoro.
La maggior parte delle configurazioni è facoltativa, ma alcune richiedono un'attenzione attenta, soprattutto quando si configurano pipeline di produzione. Di seguito sono riportati i seguenti:
- Per rendere disponibili i dati all'esterno della pipeline, è necessario dichiarare uno schema di destinazione per la pubblicazione nel metastore Hive o un catalogo di destinazione e uno schema di destinazione per la pubblicazione nel catalogo Unity.
- Le autorizzazioni di accesso ai dati vengono configurate tramite il cluster usato per l'esecuzione. Verificare che il cluster disponga delle autorizzazioni appropriate configurate per le origini dati e il percorso di archiviazione di destinazione, se specificato.
Per informazioni dettagliate sull'uso di Python e SQL per scrivere codice sorgente per le pipeline, vedere informazioni di riferimento sul linguaggio SQL DLT e riferimento al linguaggio Python DLT.
Per altre informazioni sulle impostazioni e le configurazioni della pipeline, vedere Configurare una pipeline DLT.
Distribuisci la tua prima pipeline e attiva gli aggiornamenti
Prima di elaborare i dati con DLT, è necessario configurare una pipeline. Dopo aver configurato una pipeline, è possibile attivare un aggiornamento per calcolare i risultati per ogni set di dati nella pipeline. Per iniziare a usare le pipeline DLT, vedere Esercitazione: Esegui la tua prima pipeline DLT.
Che cos'è un aggiornamento della pipeline?
Le pipeline implementano l'infrastruttura e ricalcolano lo stato dei dati quando si avvia un aggiornamento . Un aggiornamento esegue le operazioni seguenti:
- Avvia un cluster con la configurazione corretta.
- Individua tutte le tabelle e le viste definite e verifica la presenza di eventuali errori di analisi, ad esempio nomi di colonna non validi, dipendenze mancanti ed errori di sintassi.
- Crea o aggiorna tabelle e viste con i dati più recenti disponibili.
Le pipeline possono essere eseguite in modo continuo o in base a una pianificazione a seconda dei requisiti di costo e latenza del caso d'uso. Consulta Esegui un aggiornamento di una pipeline DLT.
Inserire dati con DLT
DLT supporta tutte le origini dati disponibili in Azure Databricks.
Databricks consiglia di utilizzare le tabelle di streaming per la maggior parte dei casi d'uso di inserimento dati. Per i file in arrivo nell'archiviazione di oggetti cloud, Databricks consiglia il caricatore automatico. È possibile acquisire direttamente i dati con DLT dalla maggior parte dei bus di messaggi.
Per altre informazioni sulla configurazione dell'accesso all'archiviazione cloud, vedere configurazione dell'archiviazione cloud.
Per i formati non supportati dal caricatore automatico, è possibile usare Python o SQL per eseguire query su qualsiasi formato supportato da Apache Spark. Vedere Caricare dati con DLT.
Monitorare e applicare la qualità dei dati
È possibile usare aspettative per specificare i controlli di qualità dei dati sul contenuto di un set di dati. A differenza di un vincolo CHECK in un database tradizionale che impedisce l'aggiunta di record che non soddisfano il vincolo, le aspettative offrono flessibilità durante l'elaborazione dei dati che non soddisfano i requisiti di qualità dei dati. Questa flessibilità consente di elaborare e archiviare i dati che si prevede siano disordinati e che devono soddisfare requisiti di qualità rigorosi. Consultare Gestione della qualità dei dati con le aspettative della pipeline.
Come sono correlati DLT e Delta Lake?
DLT estende la funzionalità di Delta Lake. Poiché le tabelle create e gestite da DLT sono tabelle Delta, hanno le stesse garanzie e funzionalità fornite da Delta Lake. Vedere Che cos'è Delta Lake?.
DLT aggiunge diverse proprietà della tabella oltre alle numerose proprietà della tabella che possono essere impostate in Delta Lake. Vedere riferimento alle proprietà DLT e riferimento alle proprietà della tabella Delta.
Modalità di creazione e gestione delle tabelle da parte di DLT
Azure Databricks gestisce automaticamente le tabelle create con DLT, determinando la modalità di elaborazione degli aggiornamenti per calcolare correttamente lo stato corrente di una tabella ed eseguendo diverse attività di manutenzione e ottimizzazione.
Per la maggior parte delle operazioni, è consigliabile consentire a DLT di elaborare tutti gli aggiornamenti, gli inserimenti e le eliminazioni in una tabella di destinazione. Per informazioni dettagliate e limitazioni, vedere Mantenere le eliminazioni manuali o gli aggiornamenti.
attività di manutenzione eseguite da DLT
DLT esegue attività di manutenzione entro 24 ore dall'aggiornamento di una tabella. La manutenzione può migliorare le prestazioni delle query e ridurre i costi rimuovendo le versioni precedenti delle tabelle. Per impostazione predefinita, il sistema esegue un'operazione di OPTIMIZE completa seguita da VACUUM. È possibile disabilitare OPTIMIZE per una tabella impostando pipelines.autoOptimize.managed = false nelle proprietà della tabella per la tabella. Le attività di manutenzione vengono eseguite solo se un aggiornamento della pipeline è stato eseguito nelle 24 ore prima della pianificazione delle attività di manutenzione.
Le tabelle Delta Live sono ora DLT
Il prodotto precedentemente noto come Tabelle Live Delta è ora DLT.
Limitazioni
Per un elenco delle limitazioni, vedere Limitazioni DLT.
Per un elenco dei requisiti e delle limitazioni specifici per l'uso di DLT con Unity Catalog, vedere Usare il catalogo Unity con le pipeline DLT
Risorse aggiuntive
- DLT offre il supporto completo nell'API REST di Databricks. Vedere API DLT.
- Per le impostazioni della pipeline e della tabella, vedere il riferimento alle proprietà DLT .
- riferimento al linguaggio SQL DLT.
- riferimento al linguaggio Python DLT.