Sviluppare codice della pipeline con Python
DLT introduce diversi nuovi costrutti di codice Python per la definizione di viste materializzate e tabelle di streaming nelle pipeline. Il supporto python per lo sviluppo di pipeline si basa sulle nozioni di base del dataframe PySpark e delle API di streaming strutturato.
Per gli utenti che non hanno familiarità con Python e i dataframe, Databricks consiglia di usare l'interfaccia SQL. Consultare Sviluppare il codice della pipeline con SQL.
Per un riferimento completo alla sintassi del linguaggio Python DLT, vedere riferimento al linguaggio Python DLT.
Nozioni di base su Python per lo sviluppo di pipeline
Il codice Python che crea set di dati DLT deve restituire dataframe.
Tutte le API Python DLT vengono implementate nel modulo dlt. Il codice della pipeline DLT implementato con Python deve importare in modo esplicito il modulo dlt all'inizio di notebook e file Python.
Legge e scrive il valore predefinito nel catalogo e nello schema specificato durante la configurazione della pipeline. Vedere Impostare il catalogo di destinazione e lo schema.
Il codice Python specifico di DLT differisce da altri tipi di codice Python in un modo critico: il codice della pipeline Python non chiama direttamente le funzioni che eseguono l'inserimento e la trasformazione dei dati per creare set di dati DLT. DLT interpreta invece le funzioni decorator del modulo dlt in tutti i file di codice sorgente configurati in una pipeline e compila un grafico del flusso di dati.
Importante
Per evitare comportamenti imprevisti durante l'esecuzione della pipeline, non includere codice che potrebbe avere effetti collaterali nelle funzioni che definiscono i set di dati. Per ulteriori informazioni, consultare il riferimento Python .
Creare una vista materializzata o una tabella di streaming con Python
L'@dlt.table decorator indica a DLT di creare una vista materializzata o una tabella di streaming in base ai risultati restituiti da una funzione. I risultati di una lettura batch creano una vista materializzata, mentre i risultati di una lettura in streaming creano una tabella di streaming.
Per impostazione predefinita, i nomi della vista materializzata e della tabella di streaming sono derivati dai nomi delle funzioni. L'esempio di codice seguente illustra la sintassi di base per la creazione di una vista materializzata e di una tabella di streaming:
Nota
Entrambe le funzioni fanno riferimento alla stessa tabella nel catalogo samples e usano la stessa funzione decoratore. Questi esempi evidenziano che l'unica differenza nella sintassi di base per le viste materializzate e le tabelle di streaming consiste nell'usare spark.read rispetto a spark.readStream.
Non tutte le origini dati supportano le letture in streaming. Alcune origini dati devono essere sempre elaborate con la semantica di streaming.
import dlt
@dlt.table()
def basic_mv():
return spark.read.table("samples.nyctaxi.trips")
@dlt.table()
def basic_st():
return spark.readStream.table("samples.nyctaxi.trips")
Opzionalmente, è possibile specificare il nome della tabella utilizzando l'argomento name nel decoratore @dlt.table. L'esempio seguente illustra questo modello per una vista materializzata e una tabella di streaming:
import dlt
@dlt.table(name = "trips_mv")
def basic_mv():
return spark.read.table("samples.nyctaxi.trips")
@dlt.table(name = "trips_st")
def basic_st():
return spark.readStream.table("samples.nyctaxi.trips")
Caricare dati dall'archivio oggetti
DLT supporta il caricamento di dati da tutti i formati supportati da Azure Databricks. Vedere Opzioni di formato dati.
Nota
Questi esempi utilizzano i dati disponibili su /databricks-datasets, montato automaticamente nell'area di lavoro. Databricks consiglia di usare i percorsi del volume o gli URI cloud per fare riferimento ai dati archiviati nell'archiviazione di oggetti cloud. Consulta Che cosa sono i volumi di Unity Catalog?.
Databricks consiglia di usare il caricatore automatico e le tabelle di streaming quando si configurano carichi di lavoro di inserimento incrementali sui dati archiviati nell'archiviazione di oggetti cloud. Consulta Che cos'è Auto Loader?.
L'esempio seguente crea una tabella di streaming da file JSON usando il caricatore automatico:
import dlt
@dlt.table()
def ingestion_st():
return (spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.load("/databricks-datasets/retail-org/sales_orders")
)
L'esempio seguente usa la semantica batch per leggere una directory JSON e creare una vista materializzata:
import dlt
@dlt.table()
def batch_mv():
return spark.read.format("json").load("/databricks-datasets/retail-org/sales_orders")
Convalidare i dati con le aspettative
È possibile usare le aspettative per impostare e applicare vincoli di qualità dei dati. Consulta per gestire la qualità dei dati con le aspettative della pipeline.
Il codice seguente usa @dlt.expect_or_drop per definire un'aspettativa denominata valid_data che elimina i record null durante l'inserimento dati:
import dlt
@dlt.table()
@dlt.expect_or_drop("valid_date", "order_datetime IS NOT NULL AND length(order_datetime) > 0")
def orders_valid():
return (spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.load("/databricks-datasets/retail-org/sales_orders")
)
Eseguire query su viste materializzate e tabelle di streaming definite nella pipeline
L'esempio seguente definisce quattro set di dati:
- Tabella di streaming denominata
ordersche carica i dati JSON. - Vista materializzata denominata
customersche carica i dati CSV. - Vista materializzata denominata
customer_ordersche unisce i record dai set di datiordersecustomers, trasforma il timestamp dell'ordine in una data e seleziona i campicustomer_id,order_number,stateeorder_date. - Vista materializzata denominata
daily_orders_by_stateche aggrega il conteggio giornaliero degli ordini per ogni stato.
Nota
Quando si eseguono query su viste o tabelle nella pipeline, è possibile specificare direttamente il catalogo e lo schema oppure usare le impostazioni predefinite configurate nella pipeline. In questo esempio, le tabelle orders, customerse customer_orders vengono scritte e lette dal catalogo e dallo schema predefiniti configurati per la pipeline.
La modalità di pubblicazione legacy usa lo schema LIVE per eseguire query su altre viste materializzate e tabelle di streaming definite nella pipeline. Nelle nuove pipeline la sintassi dello schema LIVE viene ignorata automaticamente. Visualizza lo schema LIVE (legacy).
import dlt
from pyspark.sql.functions import col
@dlt.table()
@dlt.expect_or_drop("valid_date", "order_datetime IS NOT NULL AND length(order_datetime) > 0")
def orders():
return (spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.load("/databricks-datasets/retail-org/sales_orders")
)
@dlt.table()
def customers():
return spark.read.format("csv").option("header", True).load("/databricks-datasets/retail-org/customers")
@dlt.table()
def customer_orders():
return (spark.read.table("orders")
.join(spark.read.table("customers"), "customer_id")
.select("customer_id",
"order_number",
"state",
col("order_datetime").cast("int").cast("timestamp").cast("date").alias("order_date"),
)
)
@dlt.table()
def daily_orders_by_state():
return (spark.read.table("customer_orders")
.groupBy("state", "order_date")
.count().withColumnRenamed("count", "order_count")
)
Creare tabelle in un ciclo di for
È possibile usare cicli di for Python per creare più tabelle a livello di codice. Ciò può essere utile quando si hanno molte origini dati o set di dati di destinazione che variano in base solo a pochi parametri, con conseguente minore quantità di codice totale per mantenere e diminuire la ridondanza del codice.
Il ciclo for valuta la logica in ordine seriale, ma una volta completata la pianificazione per i set di dati, la pipeline esegue la logica in parallelo.
Importante
Quando si usa questo modello per definire i set di dati, assicurarsi che l'elenco di valori passati al ciclo for sia sempre aggiuntivo. Se un set di dati definito in precedenza in una pipeline viene omesso da un'esecuzione futura della pipeline, tale set di dati viene eliminato automaticamente dallo schema di destinazione.
Nell'esempio seguente vengono create cinque tabelle che filtrano gli ordini dei clienti in base all'area. In questo caso, il nome dell'area viene usato per impostare il nome delle viste materializzate di destinazione e per filtrare i dati di origine. Le viste temporanee vengono usate per definire i join dalle tabelle di origine impiegate per creare le viste materializzate finali.
import dlt
from pyspark.sql.functions import collect_list, col
@dlt.view()
def customer_orders():
orders = spark.read.table("samples.tpch.orders")
customer = spark.read.table("samples.tpch.customer")
return (orders.join(customer, orders.o_custkey == customer.c_custkey)
.select(
col("c_custkey").alias("custkey"),
col("c_name").alias("name"),
col("c_nationkey").alias("nationkey"),
col("c_phone").alias("phone"),
col("o_orderkey").alias("orderkey"),
col("o_orderstatus").alias("orderstatus"),
col("o_totalprice").alias("totalprice"),
col("o_orderdate").alias("orderdate"))
)
@dlt.view()
def nation_region():
nation = spark.read.table("samples.tpch.nation")
region = spark.read.table("samples.tpch.region")
return (nation.join(region, nation.n_regionkey == region.r_regionkey)
.select(
col("n_name").alias("nation"),
col("r_name").alias("region"),
col("n_nationkey").alias("nationkey")
)
)
# Extract region names from region table
region_list = spark.read.table("samples.tpch.region").select(collect_list("r_name")).collect()[0][0]
# Iterate through region names to create new region-specific materialized views
for region in region_list:
@dlt.table(name=f"{region.lower().replace(' ', '_')}_customer_orders")
def regional_customer_orders(region_filter=region):
customer_orders = spark.read.table("customer_orders")
nation_region = spark.read.table("nation_region")
return (customer_orders.join(nation_region, customer_orders.nationkey == nation_region.nationkey)
.select(
col("custkey"),
col("name"),
col("phone"),
col("nation"),
col("region"),
col("orderkey"),
col("orderstatus"),
col("totalprice"),
col("orderdate")
).filter(f"region = '{region_filter}'")
)
Di seguito è riportato un esempio del grafico del flusso di dati per questa pipeline:
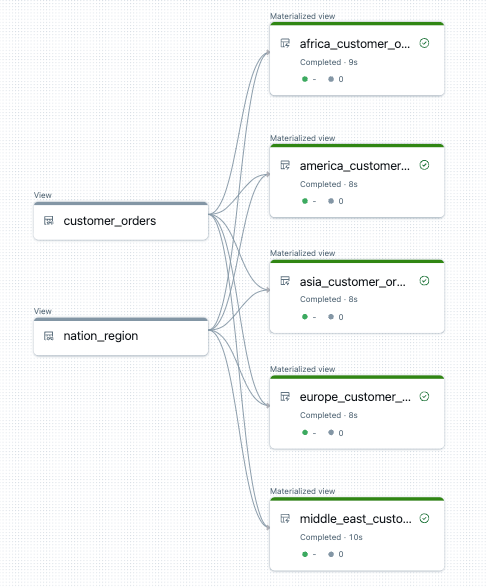
Risoluzione dei problemi: for ciclo crea molte tabelle con gli stessi valori
Il modello di esecuzione differita usato dalle pipeline per valutare il codice Python richiede che la logica faccia riferimento direttamente ai singoli valori quando viene richiamata la funzione decorata da @dlt.table().
Nell'esempio seguente vengono illustrati due approcci corretti per definire le tabelle con un ciclo for. In entrambi gli esempi, a ogni nome di tabella dell'elenco tables viene fatto riferimento in modo esplicito all'interno della funzione decorata da @dlt.table().
import dlt
# Create a parent function to set local variables
def create_table(table_name):
@dlt.table(name=table_name)
def t():
return spark.read.table(table_name)
tables = ["t1", "t2", "t3"]
for t_name in tables:
create_table(t_name)
# Call `@dlt.table()` within a for loop and pass values as variables
tables = ["t1", "t2", "t3"]
for t_name in tables:
@dlt.table(name=t_name)
def create_table(table_name=t_name):
return spark.read.table(table_name)
Nell'esempio seguente non valori di riferimento correttamente. Questo esempio crea tabelle con nomi distinti, ma tutte le tabelle caricano i dati dall'ultimo valore nel ciclo for:
import dlt
# Don't do this!
tables = ["t1", "t2", "t3"]
for t_name in tables:
@dlt.table(name=t_name)
def create_table():
return spark.read.table(t_name)