Gestire la qualità dei dati con le aspettative del flusso di lavoro
Usare le aspettative per applicare vincoli di qualità che convalidano i dati durante il flusso attraverso le pipeline ETL. Le aspettative offrono maggiori informazioni sulle metriche sulla qualità dei dati e consentono di non aggiornare o eliminare record quando si rilevano record non validi.
Questo articolo offre una panoramica delle aspettative, inclusi esempi di sintassi e opzioni di comportamento. Per i casi d'uso più avanzati e le procedure consigliate, vedere Raccomandazioni sulle aspettative e modelli avanzati.
Che cosa sono le aspettative?
Le aspettative sono clausole facoltative nella vista materializzata della pipeline, nella tabella di streaming o nelle istruzioni di creazione di viste che applicano controlli qualitativi dei dati per ogni record che passa attraverso una query. Le aspettative usano istruzioni booleane SQL standard per specificare i vincoli. È possibile combinare più aspettative per un singolo set di dati e impostare le aspettative in tutte le dichiarazioni di set di dati in una pipeline.
Le sezioni seguenti presentano i tre componenti di un'aspettativa e forniscono esempi di sintassi.
Nome delle aspettative
Ogni aspettativa deve avere un nome, che viene usato come identificatore per tenere traccia e monitorare le aspettative. Scegliere un nome che comunichi le metriche da convalidare. L'esempio seguente definisce l'aspettativa valid_customer_age per verificare che l'età sia compresa tra 0 e 120 anni:
Importante
Il nome di un'aspettativa deve essere univoco per un determinato set di dati. È possibile riutilizzare le aspettative in più set di dati in una pipeline. Vedere aspettative portabili e riutilizzabili.
Python
@dlt.table
@dlt.expect("valid_customer_age", "age BETWEEN 0 AND 120")
def customers():
return spark.readStream.table("datasets.samples.raw_customers")
SQL
CREATE OR REFRESH STREAMING TABLE customers(
CONSTRAINT valid_customer_age EXPECT (age BETWEEN 0 AND 120)
) AS SELECT * FROM STREAM(datasets.samples.raw_customers);
Vincolo da valutare
La clausola constraint è un'istruzione condizionale SQL che deve restituire true o false per ogni record. Il vincolo contiene la logica effettiva per ciò che viene convalidato. Quando un record non soddisfa questa condizione, l'aspettativa viene attivata.
I vincoli devono usare una sintassi SQL valida e non possono contenere quanto segue:
- Funzioni Python personalizzate
- Chiamate al servizio esterno
- Sottoquery che fanno riferimento ad altre tabelle
Di seguito sono riportati alcuni esempi di vincoli che possono essere aggiunti alle istruzioni di creazione del set di dati:
Python
# Simple constraint
@dlt.expect("non_negative_price", "price >= 0")
# SQL functions
@dlt.expect("valid_date", "year(transaction_date) >= 2020")
# CASE statements
@dlt.expect("valid_order_status", """
CASE
WHEN type = 'ORDER' THEN status IN ('PENDING', 'COMPLETED', 'CANCELLED')
WHEN type = 'REFUND' THEN status IN ('PENDING', 'APPROVED', 'REJECTED')
ELSE false
END
""")
# Multiple constraints
@dlt.expect("non_negative_price", "price >= 0")
@dlt.expect("valid_purchase_date", "date <= current_date()")
# Complex business logic
@dlt.expect(
"valid_subscription_dates",
"""start_date <= end_date
AND end_date <= current_date()
AND start_date >= '2020-01-01'"""
)
# Complex boolean logic
@dlt.expect("valid_order_state", """
(status = 'ACTIVE' AND balance > 0)
OR (status = 'PENDING' AND created_date > current_date() - INTERVAL 7 DAYS)
""")
SQL
-- Simple constraint
CONSTRAINT non_negative_price EXPECT (price >= 0)
-- SQL functions
CONSTRAINT valid_date EXPECT (year(transaction_date) >= 2020)
-- CASE statements
CONSTRAINT valid_order_status EXPECT (
CASE
WHEN type = 'ORDER' THEN status IN ('PENDING', 'COMPLETED', 'CANCELLED')
WHEN type = 'REFUND' THEN status IN ('PENDING', 'APPROVED', 'REJECTED')
ELSE false
END
)
-- Multiple constraints
CONSTRAINT non_negative_price EXPECT (price >= 0)
CONSTRAINT valid_purchase_date EXPECT (date <= current_date())
-- Complex business logic
CONSTRAINT valid_subscription_dates EXPECT (
start_date <= end_date
AND end_date <= current_date()
AND start_date >= '2020-01-01'
)
-- Complex boolean logic
CONSTRAINT valid_order_state EXPECT (
(status = 'ACTIVE' AND balance > 0)
OR (status = 'PENDING' AND created_date > current_date() - INTERVAL 7 DAYS)
)
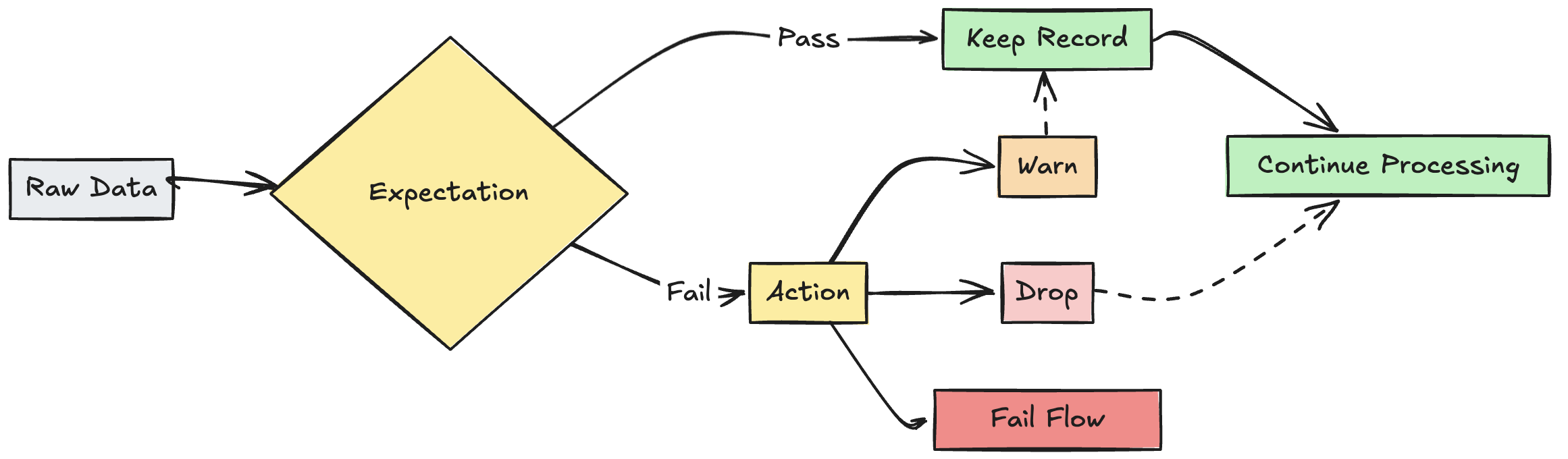
Azione sul record non valido
È necessario specificare un'azione per determinare cosa accade quando un record non supera il controllo di convalida. Nella tabella seguente vengono descritte le azioni disponibili:
| Azione | Sintassi SQL | Sintassi Python | Risultato |
|---|---|---|---|
| warn (impostazione predefinita) | EXPECT |
dlt.expect |
I record non validi vengono scritti nella destinazione finale. Il numero di record validi e non validi viene registrato insieme ad altre metriche del set di dati. |
| drop | EXPECT ... ON VIOLATION DROP ROW |
dlt.expect_or_drop |
I record non validi vengono eliminati prima che i dati vengano scritti nella destinazione. Il conteggio dei record eliminati viene registrato insieme ad altre metriche del set di dati. |
| fail | EXPECT ... ON VIOLATION FAIL UPDATE |
dlt.expect_or_fail |
I record non validi impediscono l'esito positivo dell'aggiornamento. L'intervento manuale è necessario prima della rielaborazione. Questa aspettativa causa il fallimento di un singolo flusso e non provoca il fallimento di altri flussi nella pipeline. |
È anche possibile implementare la logica avanzata per mettere in quarantena i record non validi senza causare errori né eliminare i dati. Vedere Mettere in quarantena i record non validi.
metriche di monitoraggio delle aspettative
È possibile visualizzare metriche di monitoraggio per le azioni warn o drop dall'interfaccia utente della pipeline. Poiché fail causa l'esito negativo dell'aggiornamento quando viene rilevato un record non valido, le metriche non vengono registrate.
Per visualizzare le metriche delle aspettative, completare i passaggi seguenti:
- Fare clic su Tabelle Delta live nella barra laterale.
- Fare clic sul Nome della pipeline.
- Fare clic su un set di dati con un'aspettativa definita.
- Selezionare la scheda qualità dei dati nella barra laterale destra.
È possibile visualizzare le metriche relative alla qualità dei dati eseguendo una query sul registro eventi delle tabelle live Delta. Vedere Qualità dei dati di query dal registro eventi.
Conservare record non validi
La conservazione di record non validi è il comportamento predefinito per le aspettative. Usare l'operatore expect quando si desidera mantenere i record che violano le aspettative, ma al contempo raccogliere le metriche sul numero di record che soddisfano o meno un vincolo. I record che violano le aspettative vengono aggiunti al set di dati di destinazione insieme ai record validi:
Python
@dlt.expect("valid timestamp", "timestamp > '2012-01-01'")
SQL
CONSTRAINT valid_timestamp EXPECT (timestamp > '2012-01-01')
Eliminare record non validi
Utilizzare l'operatore expect_or_drop per impedire un'ulteriore elaborazione di record non validi. I record che violano le aspettative vengono eliminati dal set di dati di destinazione:
Python
@dlt.expect_or_drop("valid_current_page", "current_page_id IS NOT NULL AND current_page_title IS NOT NULL")
SQL
CONSTRAINT valid_current_page EXPECT (current_page_id IS NOT NULL and current_page_title IS NOT NULL) ON VIOLATION DROP ROW
Errore nei record non validi
Se i record non validi non sono accettabili, usare l'operatore per arrestare immediatamente l'esecuzione expect_or_fail quando un record non riesce la convalida. Se l'operazione è un aggiornamento della tabella, il sistema esegue il rollback della transazione in modo atomico:
Python
@dlt.expect_or_fail("valid_count", "count > 0")
SQL
CONSTRAINT valid_count EXPECT (count > 0) ON VIOLATION FAIL UPDATE
Importante
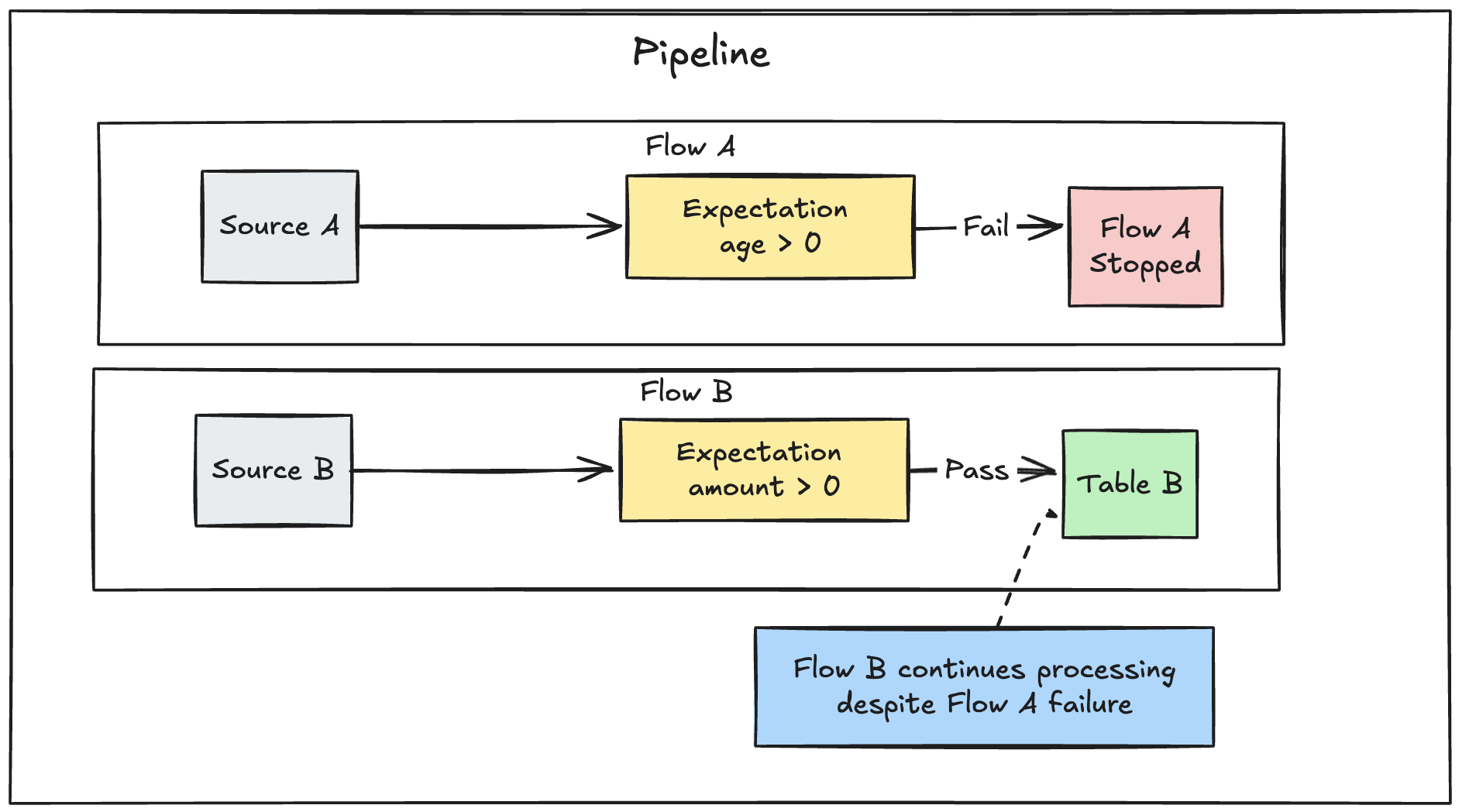
Se in una pipeline sono definiti più flussi paralleli, l'errore di un singolo flusso non causa l'esito negativo di altri flussi.
Risoluzione dei problemi degli aggiornamenti che non hanno soddisfatto le aspettative
Quando una pipeline ha esito negativo a causa di una violazione delle aspettative, è necessario correggere il codice della pipeline per gestire correttamente i dati non validi prima di eseguire nuovamente la pipeline.
Le aspettative configurate per l'esito negativo delle pipeline modificano il piano di query Spark delle trasformazioni per tenere traccia delle informazioni necessarie per rilevare e segnalare le violazioni. È possibile usare queste informazioni per identificare il record di input che ha generato la violazione per molte query. Di seguito è riportato un esempio di aspettativa:
Expectation Violated:
{
"flowName": "sensor-pipeline",
"verboseInfo": {
"expectationsViolated": [
"temperature_in_valid_range"
],
"inputData": {
"id": "TEMP_001",
"temperature": -500,
"timestamp_ms": "1710498600"
},
"outputRecord": {
"sensor_id": "TEMP_001",
"temperature": -500,
"change_time": "2024-03-15 10:30:00"
},
"missingInputData": false
}
}
gestione di più aspettative
Nota
Anche se SQL e Python supportano più aspettative all'interno di un singolo set di dati, solo Python consente di raggruppare più aspettative separate e specificare azioni collettive.
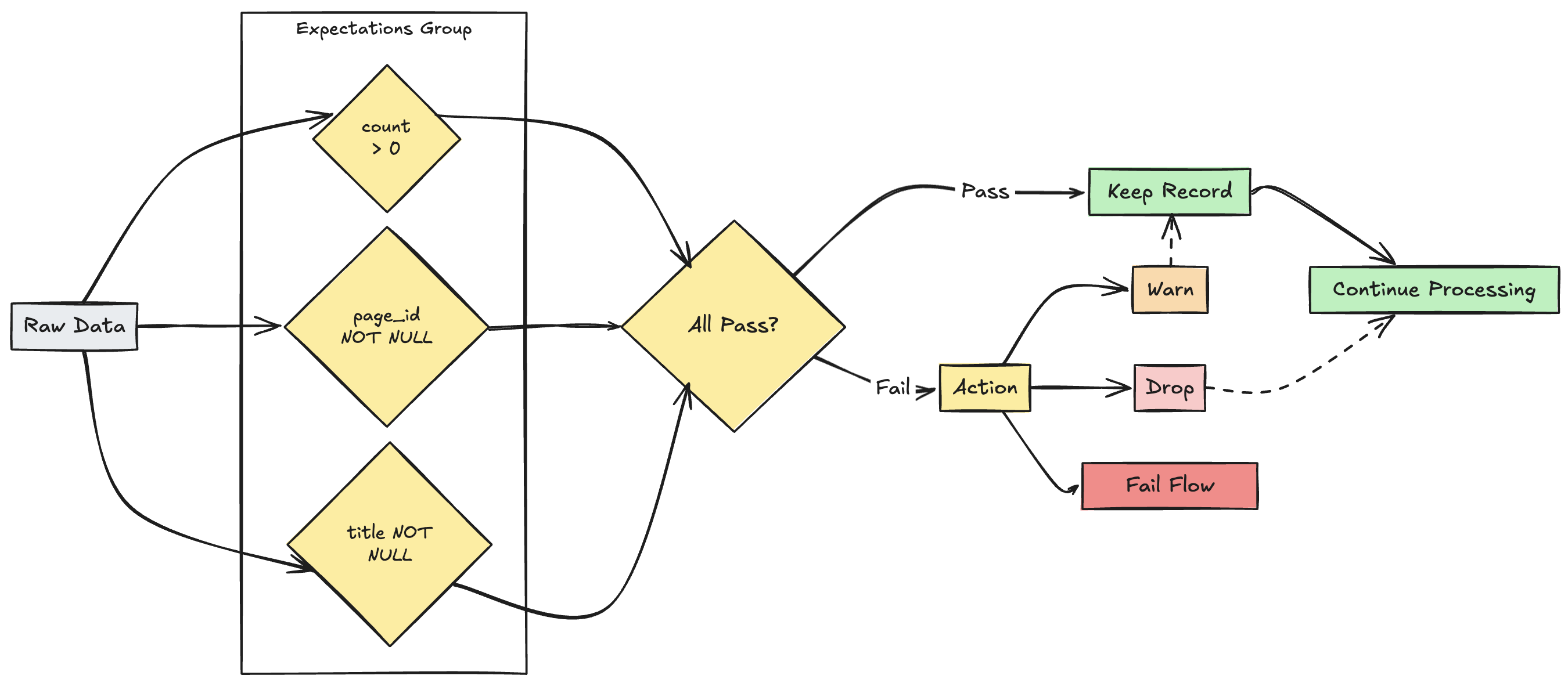
È possibile raggruppare più aspettative e specificare azioni collettive usando le funzioni expect_all, expect_all_or_drope expect_all_or_fail.
Questi decorator accettano un dizionario Python come argomento, dove la chiave è il nome dell'aspettativa e il valore è il vincolo dell'aspettativa. È possibile riutilizzare lo stesso set di aspettative in più set di dati nella pipeline. Di seguito sono riportati esempi di ognuno degli operatori Python expect_all:
valid_pages = {"valid_count": "count > 0", "valid_current_page": "current_page_id IS NOT NULL AND current_page_title IS NOT NULL"}
@dlt.table
@dlt.expect_all(valid_pages)
def raw_data():
# Create a raw dataset
@dlt.table
@dlt.expect_all_or_drop(valid_pages)
def prepared_data():
# Create a cleaned and prepared dataset
@dlt.table
@dlt.expect_all_or_fail(valid_pages)
def customer_facing_data():
# Create cleaned and prepared to share the dataset